DDIA:数据库导出就变成了流


DDIA 读书分享会,会逐章进行分享,结合我在工业界分布式存储和数据库的一些经验,补充一些细节。每两周左右分享一次,欢迎加入,Schedule 在这里[1]。我们有个对应的分布式&数据库讨论群,每次分享前会在群里通知。如想加入,可以加我的微信号:qtmuniao,简单自我介绍下,并注明:分布式系统群。
我们已经对比了消息代理和数据库的诸多方面。在传统上,他们被认为是两个完全不同类别的系统,但在之前小节的分析我们看到,基于日志的消息系统中成功地从数据库中借鉴了许多经验。其实,我们也可以有另外一条路,从消息系统中借鉴一些思想,应用到数据库中。
我们在之前提到过,事件(event)是对某个时间点发生的事情记录。事件可以是一个用户行为(如,一次搜索),可以是传感器数值,但其实也可以是写入数据库(write to a database)。写入数据库这个事情本身也可以被当做一个事件被捕获、存储和处理。我们通过这个连接可以发现,硬盘上的日志只是数据库和流数据之间最基本的牵连,其更深层次的关联远不止于此。
事实上,复制日志(在日志复制小节中讨论过)就是数据库主节点在处理事务时产生的一系列写入事件。从节点将这些写入事件按顺序应用到本地数据库副本上,就会得到一样的数据库副本。复制日志中的这些事件完整描述了数据库中的所有数据变更。
我们在全序广播也提到过状态机的复制(state machine replication)原则:如果将所有数据库的更改都表达为事件,且每个数据库副本都按照同样的顺序处理这些事件,则所有的数据库副本最终会具有相同的状态。(当然这里的前提是,所有事件都是确定性的操作。)这里状态机的复制正是事件流的一种典型例子。
在本节中,我们首先看下异构数据系统中的一些问题,然后探索下如何从消息系统中借鉴一些思想来解决数据库中的这些问题。
跨系统数据同步
从贯穿全书的思想可以看出,没有任何单一系统能够满足所有的数据存储、查询和处理需求。在实际中,大部分的问题场景都是由不同的技术组合来解决的:如,使用 OLTP 数据库来服务用户请求,使用缓存来加速常见查询,使用全文索引来处理用户搜索,使用数据仓库来进行数据分析。所有这些系统都保有一份为其服务场景优化的专用形式的数据副本。
当同一份数据以不同形式出现在多个数据系统中时,就需要某种手段来保持其同步:如数据库中数据条目更新后,也需要同时在缓存、搜索引擎和数据库仓库中进行同步更新。对于数据仓库来说,我们通常将该过程称之为:ETL。ETL 通常会拿到数据库中的所有数据、进行变换然后一次性载入数仓中。可以看出 ETL 通常是一个批处理的过程。类似的,在批处理工作流的输出一节中我们提到过,如何用批处理来构建搜索引擎、推荐系统和其他衍生数据系统的过程。
如果你觉得定期全量同步数据太慢了,另一种替代方法是“双写”(dual writes):当有数据变动时,应用层代码会显示的更新所有系统,如写入数据的同时更新搜索引擎、让缓存失效等等。双写本质上一中推的方式,“推”的方式的一大特点就是及时性好,但容错性差。
然而,双写的方式有一些严重的问题,其中的一个就是竞态条件(race condition),如下图所示。在这个例子中,两个客户端想并发的更新数据条目 X:client 1 想将 X 设为 A,与此同时 client 2 想将其设为 B。两个客户端都会先写数据库、再写搜索引擎。但在通信时两者的请求不幸地交错到一块了:数据库先接到 client 1 请求将 X 设为 A,继而接到 client 2 请求将 X 设为 B,则最终数据库中 X 的值是 B。但对于搜索引擎来说,却是先看到了 client 2 的请求,再看到 client 1 的请求,则搜索引擎中 X 最终的值为 A。在这种并发且交错的情况下,即使没有发生任何出错,但这两个系统却出现了永久的数据不一致。
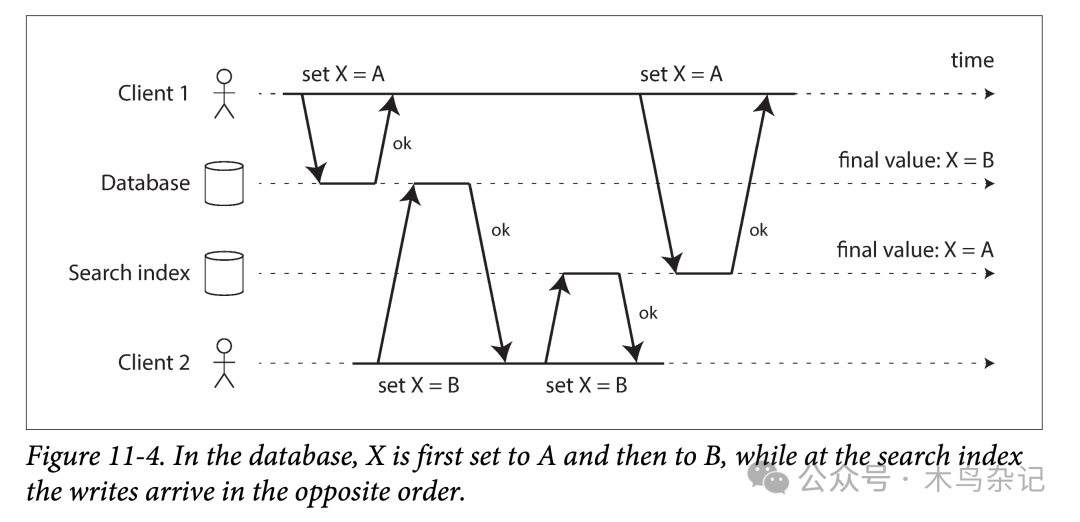
多写造成的系统不一致
除非你使用了某些并发检测机制(参见并发写入检测),否则你可能根本注意不到并发写的发生——一个值就这样悄悄的被其他值覆盖了。
双写的另一个重要问题是:一个系统中的写入成功了而往另外一个系统中的写入却失败了。当然,这本质上是一个容错问题而非并发写问题,但仍然会导致两个数据系统处于不一致的状态。想要保证两个系统的写入“要么都成功、要么都失败”是一个原子提交问题(参见原子提交和两阶段提交),解决这个问题的代价十分高昂(两阶段提交代价很大)。
在使用单主模型的数据库中,主节点会决定写入的顺序,从节点会跟随主节点,最终数据库中所有节点的状态机都会收敛到相同的状态。但在上图中,并没有一个跨系统的、全局的主节点:数据库和搜索引擎都会独立地接受写入(主节点本质上就是一个对外的数据接收点,而如果有多个写入接收点,本质上是多主),而互不跟随,因此很容易发生冲突(参见多主模型)。
如果我们对于多个系统真正的只有一个主节点,让其他系统跟随这个主节点,这种情况才会被解决。比如,在上面的例子中,让数据库充当主节点,让存储引擎成为数据库的从节点,跟随其写入。但在实践中,这可能吗?
数据变更捕获
其中一个主要问题是,充当主从复制机制中关键角色的复制日志(replication log),是数据库的一个内部实现模块,而非一个公共服务。客户端对数据库查询时,只能通过基于数据模型、使用相应的查询语言,走查询引擎。而不能直接读取复制日志,并从其中解析数据。
数十年来,大多数的数据库实现都没有选择将相关日志作为服务开放出来,并用文档详细阐明日志记录数据库变更的机制。出于此,我们很难将数据库的日志模块拿出来,作为复制中介,同步给外部系统(如存储引擎、缓存和数仓)。
近些年(本书出版于 2017),CDC(change data capture,数据变更捕获)受到越来越多的关注。CDC 是一种捕获数据库中数据变更,并且以某种方式将其导出,供其他外部系统使用的技术。如果我们将 CDC 进行流式的导出,事情将会变得更有意思。
例如,你可以跟踪数据库中的变更,将其持续导出,应用到搜索引擎中。如果对于所有的修改日志按同样的顺序进行应用,则你可以期望搜索引擎中的数据是和数据库中的一致的。从消息系统的角度看,搜索引擎和其他的衍生数据系统都是数据变更流的消费者。如下图所示:
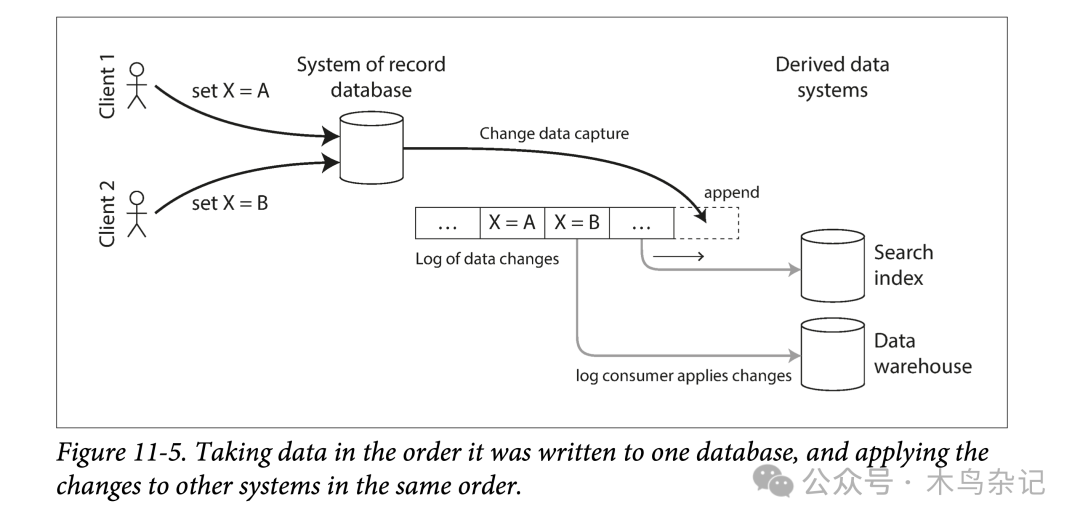
将写入数据库的事件按顺序应用到其他系统
CDC 的实现
如本书第三部分的标题,我们可以将 CDC 数据的消费者当做是衍生数据系统(derived data system):存储引擎和数据仓库中的数据本质上是数据库中同一份数据的不同视图。CDC 是一种将所有数据中变更精确同步给所有数据视图的手段。
本质上,CDC 实现了我们上面提到的,让数据库成为领导者(事件捕获的源头),让其他系统成为跟随者。由于对消息的保序性,基于日志的消息代理非常适合将 CDC 的事件流导给其他数据系统。
数据库的触发器可以用来实现 CDC(参考基于触发器的复制)。具体来说,可以注册一些触发器来监听所有数据库表的变更,然后将变更统一写入 changelog 表。然而,这种方式容错性很低且有性能问题。需要用比较鲁棒的方式来解析复制日志,尽管可能会遇到一些问题,比如处理模式变更。
在工业界中,LinkedIn 的 Databus,Facebook 的 Wormhole 和 Yahoo 的 Sherpa 就大规模的使用了这种思想。Bottled Water 依托解析 PostgreSQL 的 WAL 实现了 CDC,Maxwell 和 Debezium 通过解析 MySQL 的 binlog 实现的 CDC,Mongoriver 通过读取 MongoDB 的 oplog 实现 CDC,GoldenGate 也针对 Oracle 实现了类似的功能。
和日志代理一样,CDC 通常是异步的:数据库在导出事件流时通常不会等待消费者应用完成后才提交。这种设计的优点是给 CDC 增加慢的消费者并不会对源系统造成影响;但缺点就是不同系统间可能会存在日志应用滞后。(参见 复制滞后问题)
初始快照
如果你有数据库从开始以来的所有日志,你可以通过重放来恢复数据库的整个状态机。但,在大多数情况下,保存所有变更日志非常占用硬盘空间,恢复的时候重放也非常耗时。为此,我们必须定期对老日志进行截断。
构建全文索引需要一份数据库中的全量数据,只使用包含最近变动的日志是不够的,因为丢失之前的一些数据。因此,如果你没有全量的日志记录,也可以从某个一致性的快照开始,应用该快照对应时间点之后的所有日志,也可以得到一份全量状态。我们在新增副本一节中讨论过这个问题。
要达到上述目的,就需要数据库的快照能够和变更日志中的某个下标对应上,这样我们在从快照中恢复之后,才能知道从哪个变更日志开始回放。有些 CDC 工具直接集成了快照功能,但有的就需要自己手动做快照。
日志压缩
如果我们只能保存很少的历史日志,则在每次添加新的衍生系统时,都需要加载快照。而,日志压缩提供了另一种可能性。
我们在哈希索引一节中,在日志结构的存储引擎的上下文中讨论过日志压缩。其原理很简单:存储引擎定期扫描所有日志记录,找到具有相同 key 的数据,丢掉老的日志,只留下最新的。这个压缩、合并的过程会在后台一直默默执行。
在日志结构的存储引擎中,会使用一个特殊空标记(一个墓碑标记,tombstone)来标识某个 key 被删掉了,最终在后台压缩的时候,会据此真正的去删除所有日志中的相关 key。从另一方面来说,只要一个 key 没有被覆写或者删除,他就会一直留在日志中。这样,只要压缩的足够快和彻底,一个压缩后的日志所占的硬盘空间就只与数据库中的内容(即 key 的数量)有关,而和数据库接收了多少个写入事件无关。如果某个 key 被频繁的覆写,该 key 之前的所有修改日志最终都会被压回收掉,只剩下最后该 key 相关的一个日志。
同样的原理也可以应用到基于日志的消息代理和 CDC 中。如我们给每条变更日志关联一个主键(primary key),且可以保证同一个 key 后面的变更会覆盖之前变更,则我们可以基于此对日志进行压缩,对于每个 primary key 只保存最后一个变更日志即可。
在这种设定下,当我们想基于现有变更日志构建一个新的衍生系统时(如搜索引擎),就可以启动一个新的消费者从下标 0 开始对压缩后的日志进行顺序消费,直到扫描完所有的日志。使用压缩日志,你就不再需要额外的快照了,因为这种日志包含你恢复数据库状态所需要的所有 key。
Apache Kafka 就支持这种日志压缩的方式。我们在本章稍后会看到,这种特性让消息代理不仅可用于暂时的消息传递,而且可用于持久化的存储。
变更流的 API 支持
越来越多的数据库支持将数据变更流(change streams)接口作为第一等公民,而不需要用户去修改底层代码以 hack 的方式支持 CDC。例如,RethinkDB 允许通过查询订阅结果集变更;Firebase 和 CouchDB 基于变更流进行数据同步,且将其开放给了应用层使用;Meteor 使用 MongoDB 的操作日志(oplog)来订阅数据变更,并更新用户接口。
VoltDB 允许将表以流的形式导出(可参考其文档)。数据库将关系数据模型中的输出流表示为一个数据库表,可以通过事务向其中插入元组,但不能对该表进行查询。于是,该导出流中就会包含所有已提交事务的元组,外部消费者(以 connector 的形式)就可以异步的消费这些日志,并将更新应用到衍生数据系统中。
Kafka Connect 是一个可以将数据库 CDC 导出的流接入 Kafka 的工具。一旦事件流导入进了 Kafka,下游衍生系统就可以按需进行消费,生成倒排索引、打入流式系统中等等。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-04-11,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号