炸裂的ChatGPT-4:能看图画图又会说话

炸裂的ChatGPT-4:能看图画图又会说话

MavenTalker
发布于 2023-10-19 16:30:37
发布于 2023-10-19 16:30:37
ChatGPT-4V的出现,再一次让ChatGPT腾飞,除了原有的生成式对话、语意理解、代码生成等等,现在又可以画图、读图、语音对话能力。可以说是又是一次质的飞跃,我们离AGI又近了一些。

说话
ChatGPT合成的语音,不仅可以囊括了声调、语气、停顿断句等,甚至人说话时的口水吞咽、呼气都能听得很清楚,打开下面的视频来感受一下(这是一位网友的中文对话过程)。你还能分辨是真人还是假人吗?
(视频来源于即友)
考虑到网络延迟问题,会有略微的卡顿,都是正常现象。也有爱玩的网友,把两个ChatGPT放一起对话,就这么一问一答,直到天荒地老。
看图
早期开放的ChatGPT还是基于大语言模型,也是单模态技术,只能处理文字请求。目前的ChatGPT 4已经具备了多模态能力,能够针对图片内容进行解析,分析图中的内容。
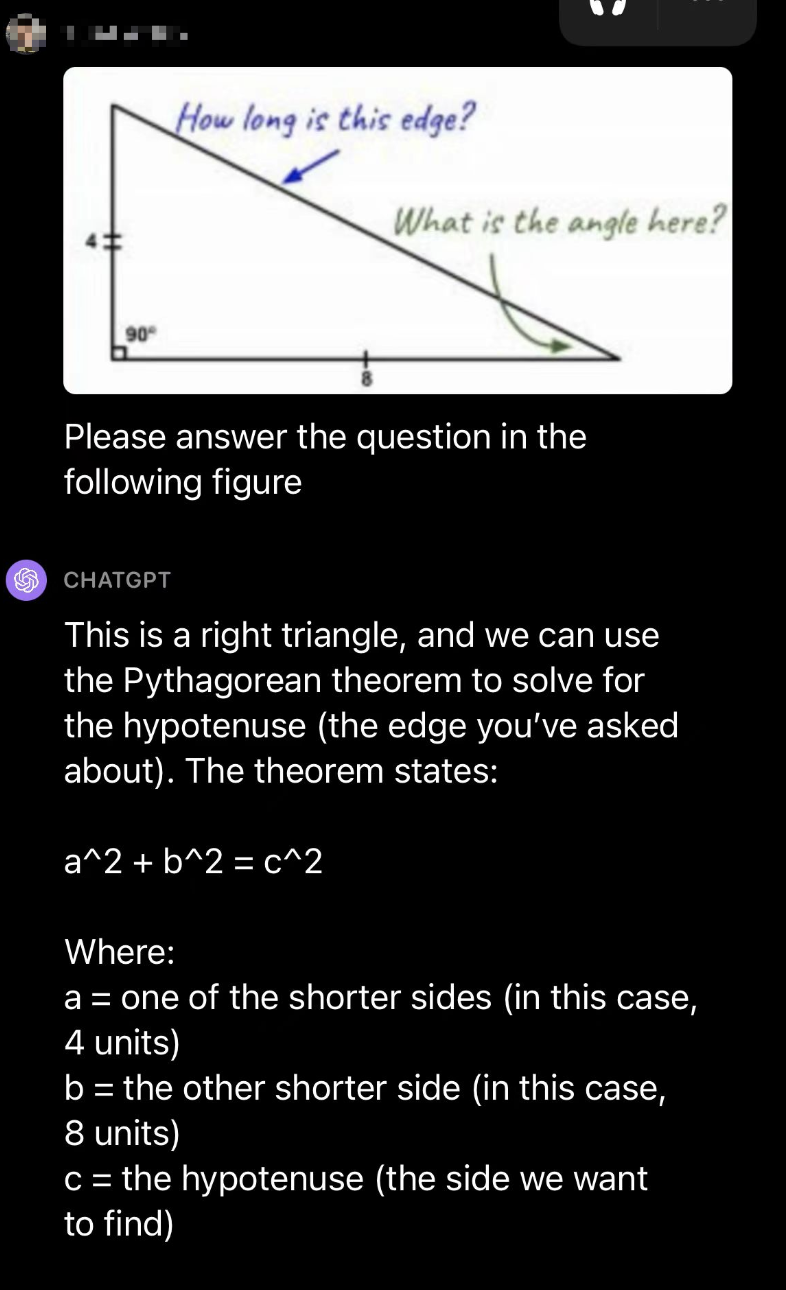
识图可以做什么?很多图都要需要专业能力的解读,普通人拥有了识图能力,也可以看的懂医学影像、高分子结构、机械设计原理、集成电路图等等,知识门槛将进一步降低,这算不算知识平权的一个体现?
生图
再看看成图的能力,整合了自家 DALL.E 3 产品的AI生成图能力,把文生图和 ChatGPT 做了结合,在与ChatGPT对话的过程中就可以直接生成图片,嵌套在对话过程中。除了原有的生成图片的质量提升之外,当然跟Midjourney上还是有些差距,好处在于不用输入很精细的Prompt提示词,就可以生成相当惊艳的图片(提示词完善这部分由GPT去替用户完成)。

从创始人分享的一个宣传视频看出,制作绘本的难度被大大降低,故事编写、插图生成,完全可以在ChatGPT里完成,插图、绘本这个小细分领域又要被ChatGPT重构了。
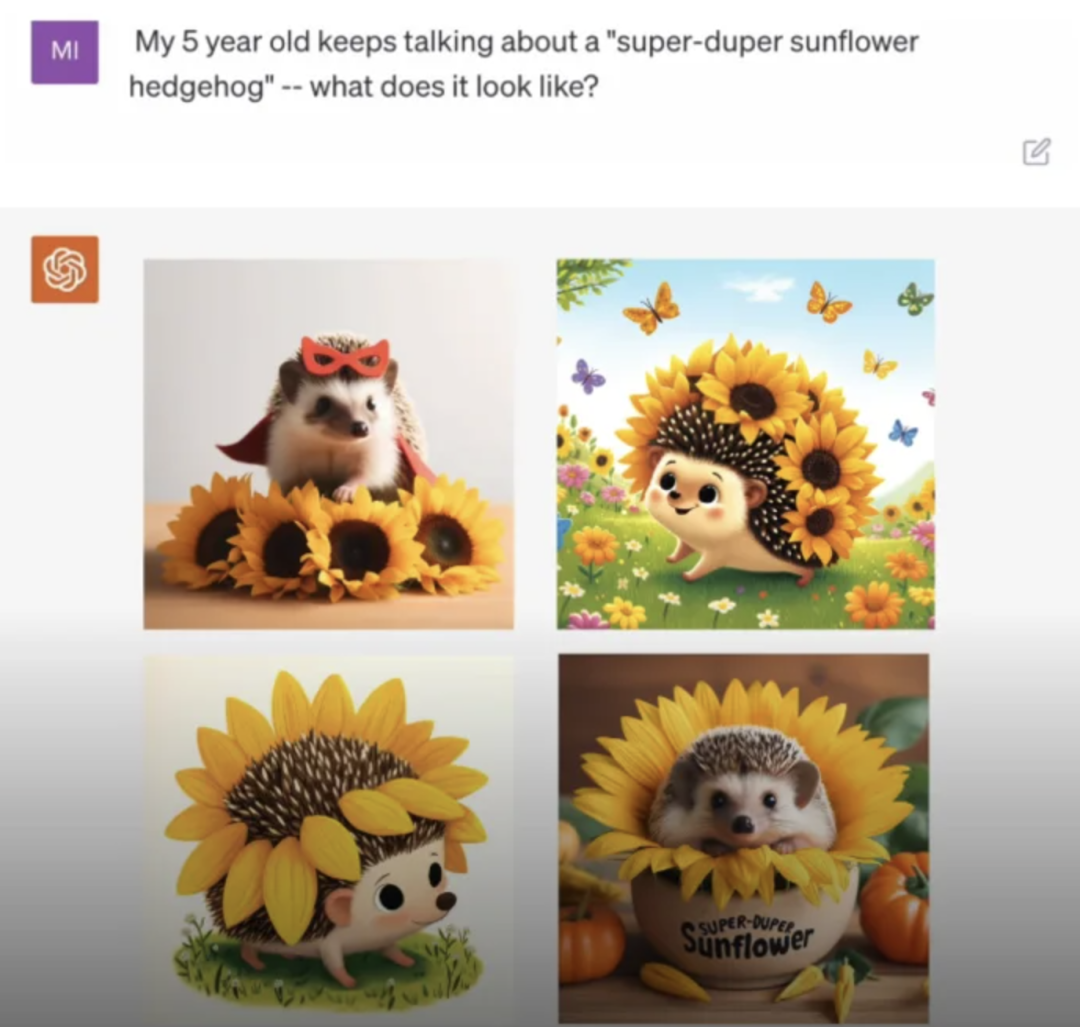
在某多、某宝的商品链接里,已经有很多商家在这么运作了。
ChatGPT PLus
上面讲了这么多,为什么我的账号里没有这些功能?因为上述所说的这一切都是基于Plus版本,普通的ChatGPT版本并没有这些强大的能力。大家经常说大语言模型的训练成本高、推理成本更高,简单理解就是研发成本高,使用成本更高,如此高成本的压力下,普通版自然是无法享受这一些特性功能。
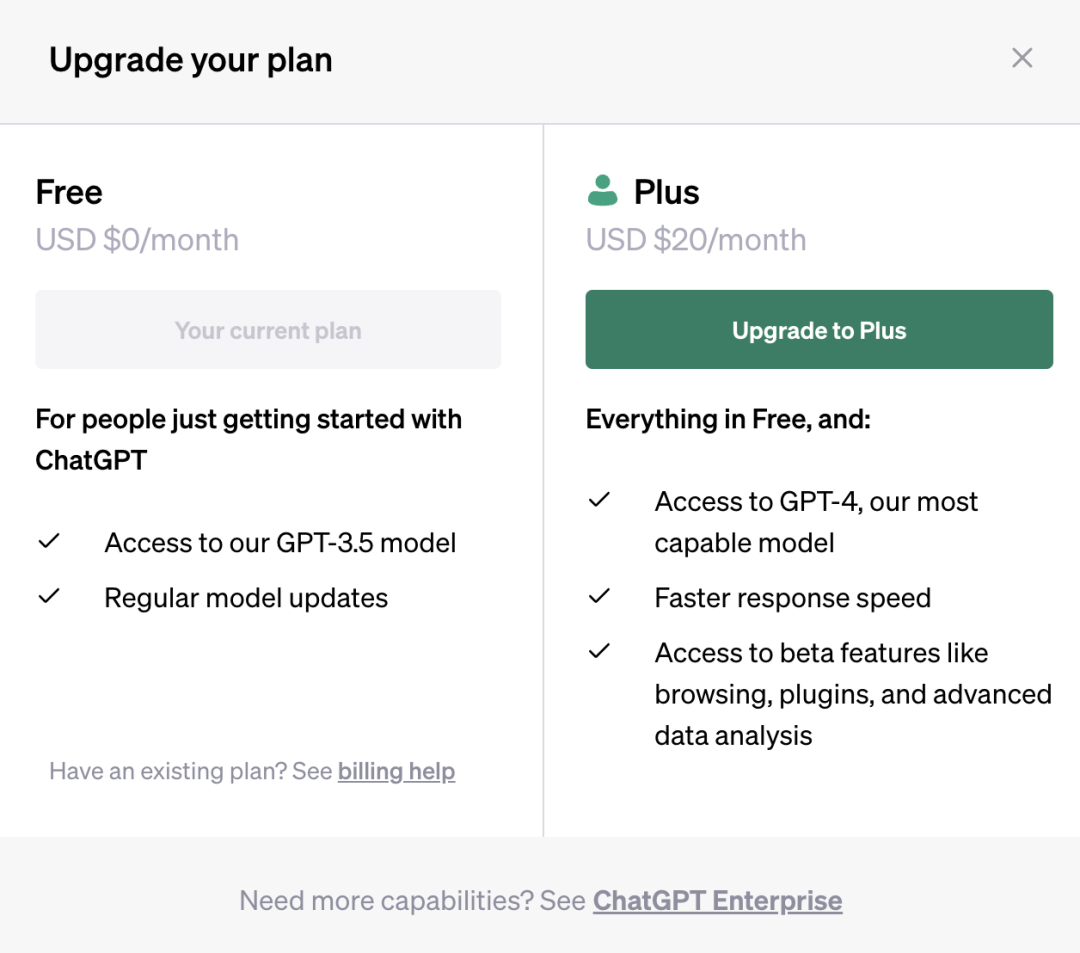
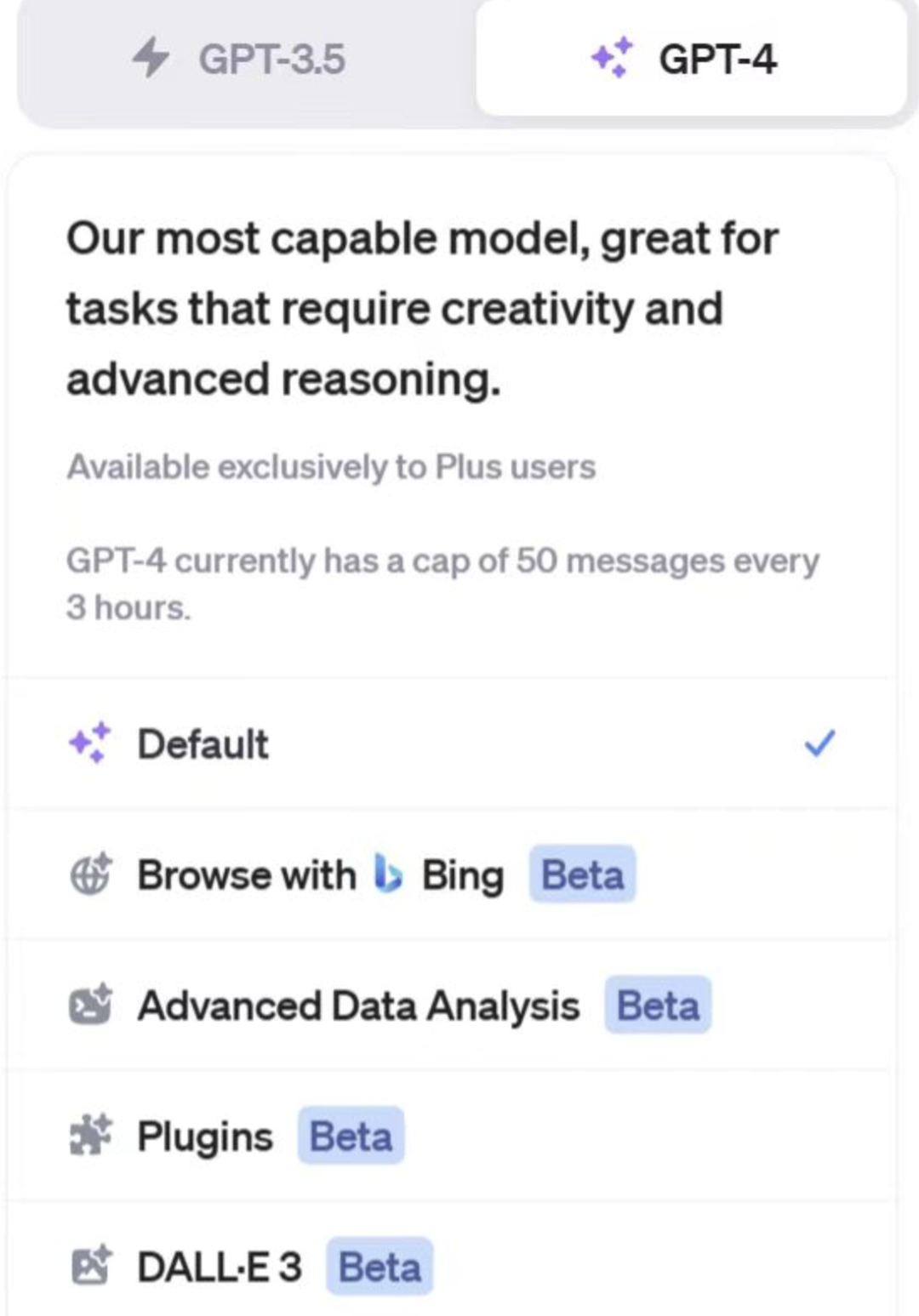
未来
音、视频
除了上面提到的语音合成技术,下一步的多模态能力应该是针对音频生成、视频生成方向拓展,集齐文字、图片、音频、视频等能力后,多模态能力才算完整,也基本覆盖当下数字文件的几大类型。
GPT5-6
GPT更高版本的推出毫无悬念,如果像GPT3.5到GPT4这种能力的跃迁,GPT6的能力简直无法想像,也许已经实现了AGI,明年?后年?静静期待吧!
智能硬件
据 The Information 报道,著名的前苹果产品设计师 Jony Ive 正在与 OpenAI CEO Sam Altman 就人工智能硬件项目进行商讨。Ive是谁你可能你比较陌生,但作为苹果公司前首席设计官,Jony Ive曾经领导了苹果许多最具标志性的硬件设计,从iMac到iPhone,从iPad到Apple Watch,是Jobs重要的合作伙伴,可以说没有Ive,苹果今天可能会是另外一个样子。
未来的人工智能硬件会是什么样,很值得期待,兴许会开启一个新时代,如iPhone般惊艳。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-10-13,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号