大模型背景下软件工程的机遇与挑战

大模型背景下软件工程的机遇与挑战

腾讯云 CODING
发布于 2023-10-19 15:27:17
发布于 2023-10-19 15:27:17

本文作者:汪晟杰 导语:AISE(AI Software Engineering)有人说是软件工程 3.0,即基于大模型(LLM - Large Language Model)时代下的软件工程。那么究竟什么是 AISE,他的发展历程对软件工程产生怎样的变化。本次主题文章会分为五大部分: 1、软件工程 3.0 与 AISE 2、基于 LLM 的代码生成 3、应用形态思考 4、机遇与挑战 5、小结
软件工程 3.0 与 AISE
AI 时代下的软件工程
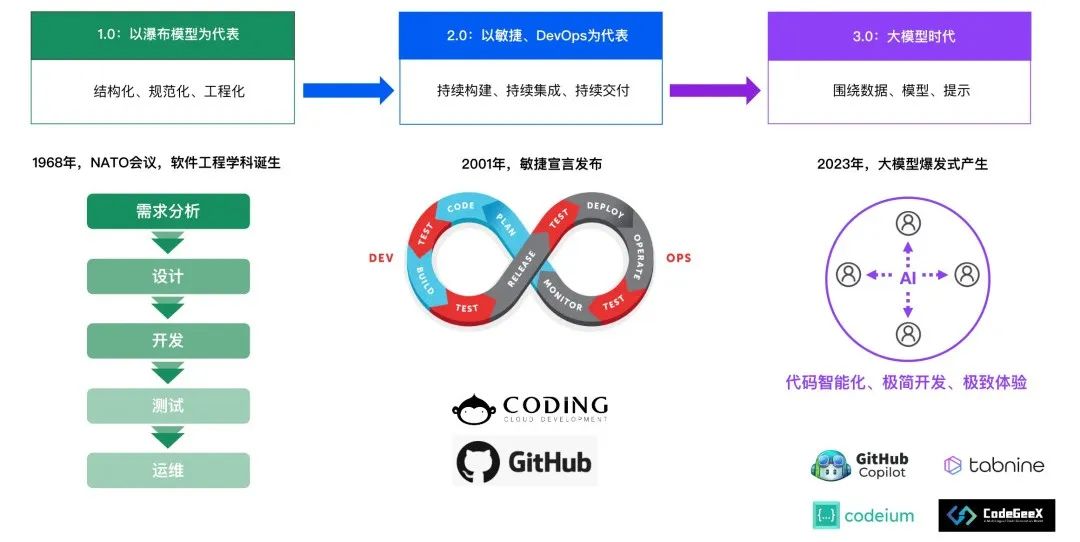
软件工程的发展可以分为三个阶段:软件工程 1.0、软件工程 2.0 和软件工程 3.0。在这三个阶段中,AI for SE(人工智能在软件工程中的应用)的发展历程如下:
软件工程 1.0
在这个阶段,软件工程主要关注结构化编程、模块化设计和数据结构。主要集中在基于规则的 MIS 专家系统、模式识别、平台型工具等方面。当时如 Borland、Sybase 等产品,我在 05 年加入 Sybase PowerBuilder 和 PowerDesigner 产品组,负责过建模工具、MIS 系统开发平台、UEP 移动开发平台工具集(后面贡献给到了 eclipse 开源组织)。这些产品当时试图解决软件工程下复杂应用投入产出高的问题,后来推出面向组件开发范式(OOC:面向组件编程)来提高开发效率,快速发布上线,那个时候还不能称为 IDE,我们还是称 RAD(Rapid Application Development)。当时我们也探索过 Big Code 的语义搜索能力也逐步开始研究等,但受限于当时的计算能力和 AI 技术水平,效果有限。
软件工程 2.0
软件工程逐渐从结构化编程转向面向对象编程。AI for SE 的应用范围和技术水平得到了进一步发展。例如,基于遗传算法的优化技术被用于软件设计和测试;神经网络技术NLP被用于软件缺陷预测;自然语言处理技术被用于需求分析和知识表示等。此外,软件工程 2.0 更聚焦于流程统一,例如一些产品如 CODING DevOps、Gitlab 等。
软件工程 3.0
在这个阶段,软件工程的关注点从面向对象编程转向云计算和 AI。随着 AIGC 技术的这一年的高速发展,以 LLM 为首的面向大模型的软件工程体系也被国内外提出,如 GitLab Duo、Github Copilot X 等,使得 AI for SE 的应用前景变得更加广泛。例如,深度学习技术被用于代码生成和补全、缺陷检测和自动修复;数据挖掘技术被用于软件过程改进;自然语言处理技术被用于需求分析、代码审查和文档生成等。
总之,从软件工程 1.0 到软件工程 3.0,AI for SE 的发展历程可以概括为从初步尝试到逐渐成熟,再到广泛应用。随着 AI 技术的不断进步,AI for SE 将在未来的软件工程领域发挥更加重要的作用。
AI for SE 和 SE for AI
AISE,我先用中文「智能化软件工程」来定义,实际上他有两个方向:一个是 AI for SE,另外一个方向是 SE for AI。
这两个区别,我们先问下 ChatGPT,看看 AI 是怎么解答的:
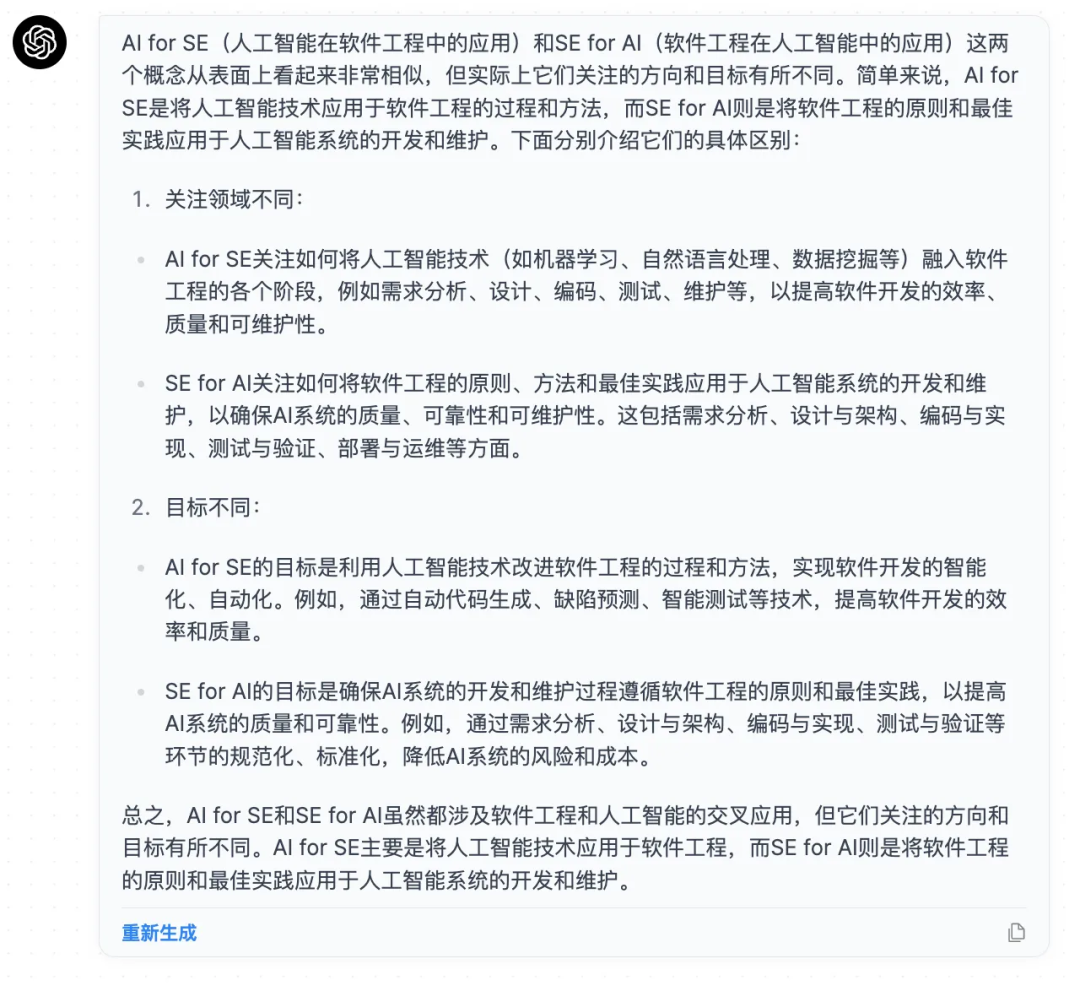
可见,软件工程 3.0 就是 AI for SE,解决软件工程 2.0 流程中的 AI 化,促使效率提升,流程化简,让 AI 在关键节点赋能开发。
SE for AI 是另一个维度,即思考软件工程流程体系怎么来实现智能化软件应用,例如 ML-Ops 流程化 AI 应用研发。
这里我们先围绕 AI for SE 进行展开,至于智能化应用系统,如最近很火的面向AI的 Mojo 语言、更面向 AI 化的应用框架等等,我们以后再进行阐述。

基于 LLM 的代码生成
大型代码语言模型(Code LLM)的兴起。其中一个用在软件工程任务里面的最基本的一个问题,就是代码生成。
从 Codex 讲起
在 2021 年 7 月 OpenAI 发布出 Codex 论文《Evaluating Large Language Models Trained on Code》,这个论文当时可能并没有太大的反响,虽然他们发布了 HumanEval 的数据集,效果也不错,但是在众多文章中并没有得到太多的关注。论文里提到了 3 个模型,一个是基于 GPT-3 在代码上微调来通过文本描述生成代码的 Codex 模型(非监督学习);另一个是进行监督训练,通过文本描述生成代码的 Codex-S 模型;最后一个是通过代码生成代码文本描述的 Codex-D 模型.
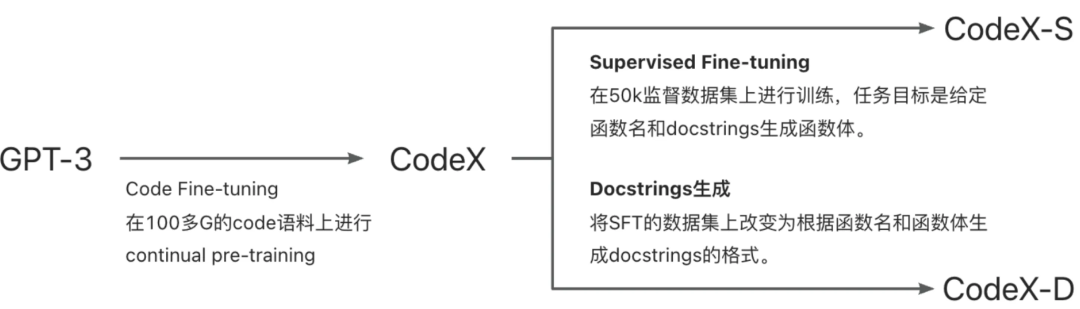
代码微调Codex
利用 GitHub 上面的 5400 万个公开仓库,代码是在 2020 年 5 月从 GitHub 上搜集的,每个 Python 文件是 1MB 以下的。最终我们的数据集是 159GB。
GitHub Copilot

2022 年 Github Copilot 正式上线对外公测,它是基于 Codex 的模型的训练,背靠 Github 仓库集,通过精调训练的一套面向开发者的代码补全产品。
代码补全的产品价值
2021 年 10 月 29 日 OpenAI 发布 Copilot 后,大家去试用有一个很深切的感受,确实是很震撼,它的能力比起之前的技术提升了一大步。

根据 DeveloperSuvey,受访者认为人工智能编码助理将如何改变他们明年的工作,其中编写代码占了 82.55%,70% 的受访者正在或计划在开发过程中使用人工智能工具,并且学习者比专业人士更有可能使用它们。
下图为腾讯云 AI 代码助手针对怎样达成高用户价值的思考框架。我们通过代码模型精调训练,在代码补全、技术对话上给开发者提高效率。这点也已在内部进行了多次论证:当产品处于非常好的体验的时候,会获得非常高的用户留存率。这里提到的代码生成的体验,更关注在补全性能、产品交互、以及用户开发习惯等方面。
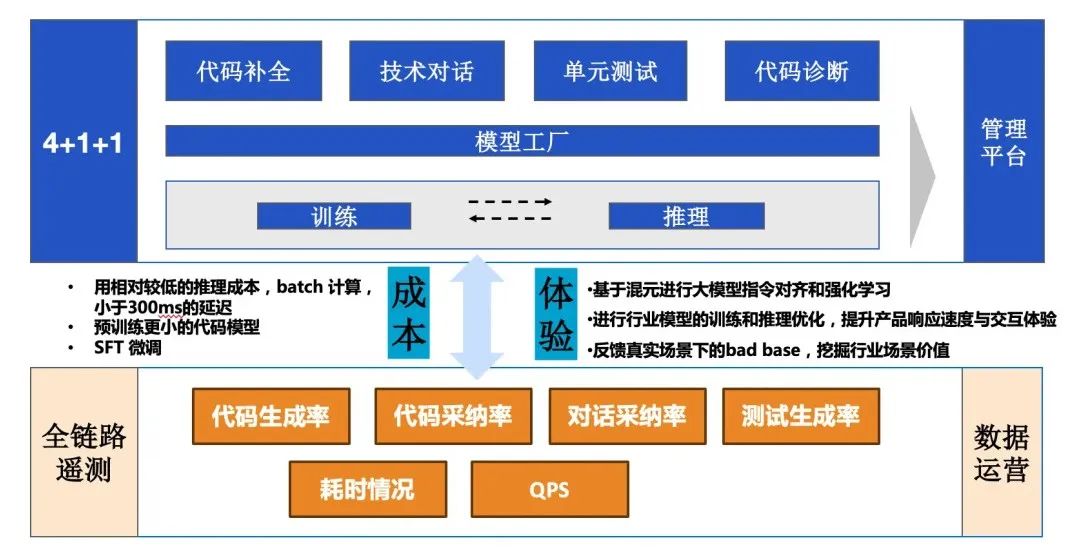
在高留存率目标驱动的同时,还必须控制优化好成本,防止高频访问导致速度下降与成本上升、从而劣化产品体验。需要重视 bad case 反馈与处理闭环、针对性专题性能调优、采取批量计算等策略;通过用户看板观察总结模型版本升级带来的能力增益。最终通过一系列平衡手段,实现 AI 代码助手在补全场景下的产品价值。
应用形态思考
面向开发者的编程提效
开发者有两大群体,一类是专业的开发人员,就是软件工程师,那么产品目的就是为了提高开发人员的开发效率,把程序员从简单重复的劳动中解放出来,从而关注架构、设计等复杂任务。现实场景中,用户使用代码生成特性时,通常会尝试读生成的代码,从而决定是否采用或修改生成的代码段。这是对 AI 项目理解能力的批判性思维,因此我们认为目前的代码生成/补全还是在为 AI 辅助生成建议、生成相似逻辑。
实战中,在腾讯云 AI 代码助手的配合下,我举三个高频使用的场景:
- 按 Entity 对象完善 getter/setter,甚至是关联对象。
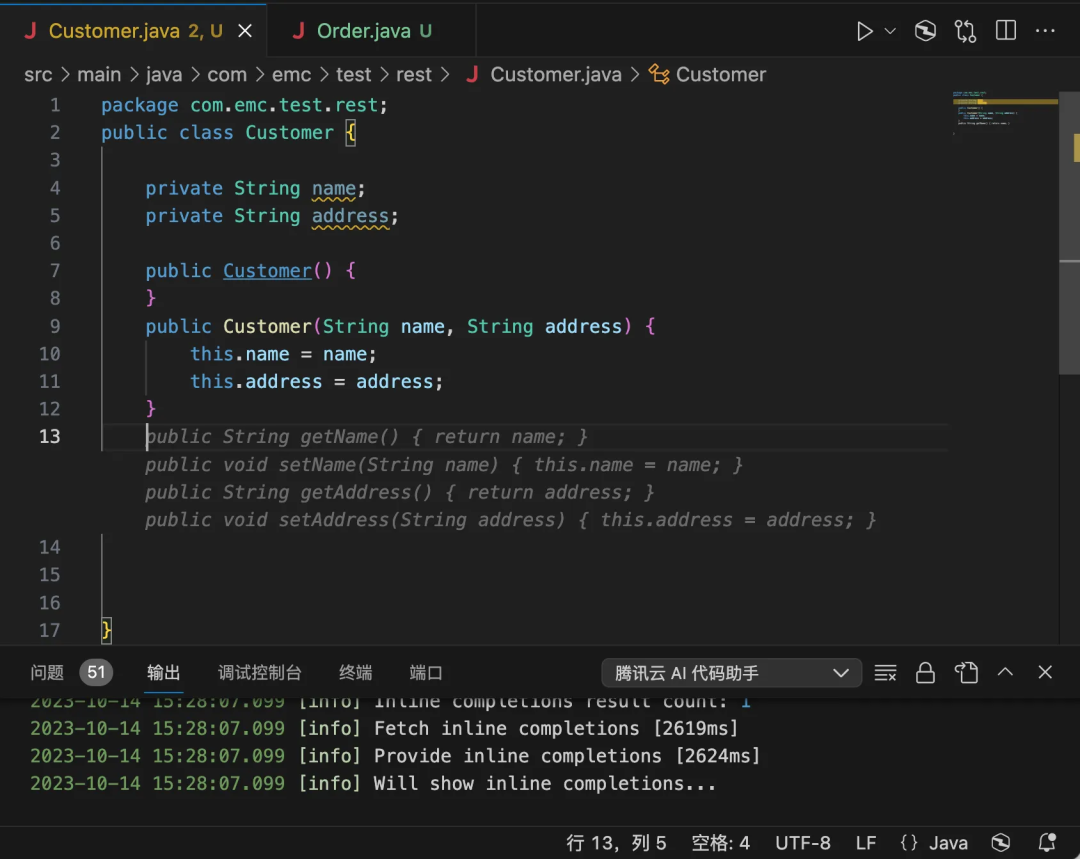
- 通过结构体,自动生成 SQL 及 DAO 对象。
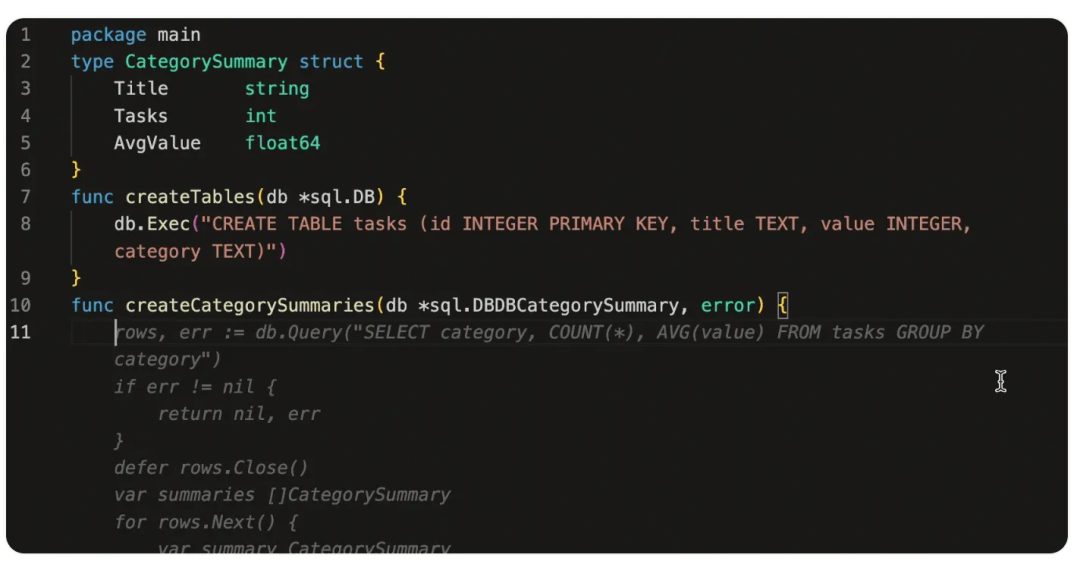
第二类是代码钻研者、寻求代码相关解答的开发者。这类用户有什么特性呢?他们执著于代码本身,如算法,特定问题的解答,特定描述下的代码生成(代码建议后的试错)。这类开发者的目的是:创建小的、即时使用的任务型应用程序,比如函数计算程序、支持用户快速完成日程的任务。当然也有代码学习者,对于代码不是很熟悉的,可以通过代码对话对代码进行解读,在对话中进行有效提问。
技术对话和代码补全在实战下是相辅相成的,为了做到更好体验,技术对话会采用更大规模的模型来获得更好的推理能力,而代码生成场景下则会采用更小的代码模型来获得更好的写代码的体验感。
高粘性的编程体验
- Fill in Middle 技术
模型只知道光标之前的代码,还不能够精确生成代码,它还需要光标下文的代码。解决办法就是输入中间填充的技术 (Fill in Middle)。OpenAI 去年在一篇论文中介绍了 FIM 论文,它允许语言模型在训练过程中纳入光标后面的上下文。 论文地址:https://arxiv.org/pdf/2207.14255.pdf
- Fill in Middle的原理简介:
假设我们有一个如下所示的训练示例:
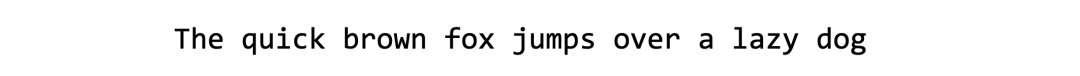
我们希望模型学习 jumps over 从前缀 The quick brown fox 和后缀预测中间文本 over a lazy dog。首先,我们进行两次切割来分隔这些部分,引入新的标记<PRE>、<MID>、<SUF>和<EOM>

然后我们简单地转置中间和后缀:

现在,我们的训练与之前完全相同,jumps over 从之前的文本预测接下来的文本。 The quick brown fox a lazy dog。该模型自动学习特殊标记的含义,并了解到它应该生成在前缀之后但在后缀之前有意义的文本!在推理时,如果我们尝试填充如下所示的文档:
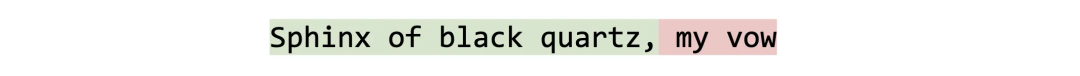
我们可以将其呈现为:
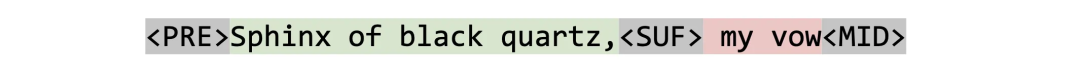
到模型并请求字符,直到模型发出令牌,此时它已成功将前缀与后缀连接起来。
下面几张截图是 AI 代码助手通过 FIM 技术,实现通过光标上下文快速填补中间片段。在真实场景下,非常适合做成对出现的代码函数,比如:加解密函数、通过 CR 自动生成 U(pdate)D(elete) 函数等。

- 更小的代码补全模型
代码补全的触发时机是真正伴随在日常开发中的,无时无刻去根据上文生成下文代码,如下图所示。所以这里的模型更应该是小模型。在 AI 代码助手下,我们将其定义为补全小模型,带来的性能收益是巨大的。GitHub Copilot 也尝试在端上内置更小的微模型,让成本、速度优先作为补全产品的前提。

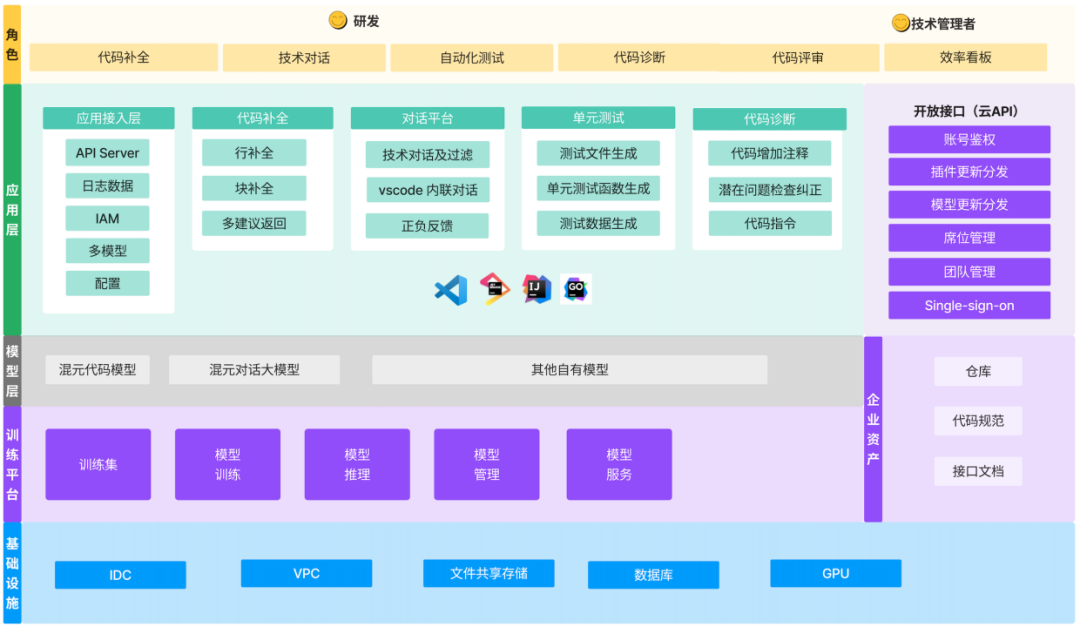
基于混元大模型的 AI 代码助手的行业产品
未来基于混元会对外推出公测版本,结合小模型提供可商业化、可私有化、可共创合作,为行业客户的研发 AI 赋能。
目前支持 Python、JavaScript/TypeScript、Java、C/C++、Go、Rust、swift、SQL 等主流语言,并支持各大主流 IDE 平台。

AI 代码助手的产品从开发者的频次最高的场景作为切入,以代码补全作为优先行业落地的能力,以技术对话模型共创成对话平台,并计划接入测试和诊断能力。
机遇与挑战
面向行业开发的 SMAF 机遇
代码模型落地企业会遇到很多挑战。像海外的企业,对于使用 Copilot,ChatGPT 没有太多的顾虑,但是在国内绝大部分的软件企业或研发软件机构,自己企业或机构内部的代码是不能够流传至外网的,需要私有化部署。私有部署往往需要性能强大的 GPU 集群,全面开发给大型软件研发团队使用成本很高;以及企业内网环境使用的的库或框架无法使用开源项目代码比如 GitHub 等,怎么能够支撑好这些场景都需要考虑如何解决。
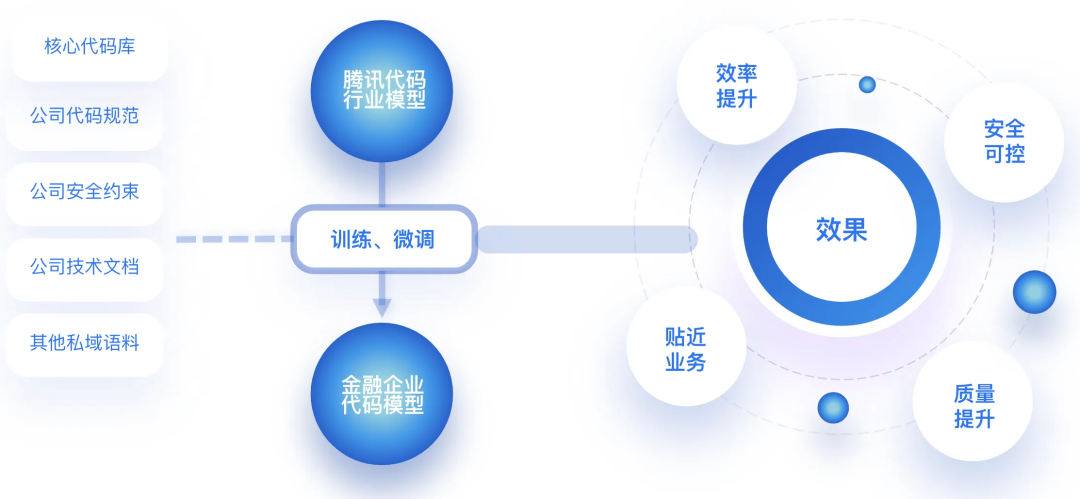
腾讯自研的代码模型也充分考虑到企业内部数据资产监管所面临的各项挑战和实际诉求,让受管控企业也可以在一个受控的环境内将 AI 代码助手使用起来,并且希望能够支持全场景。让项目经理、市场人员、设计、开发及测试人员都可以有自己的实现场景,这是我们主要的目标。
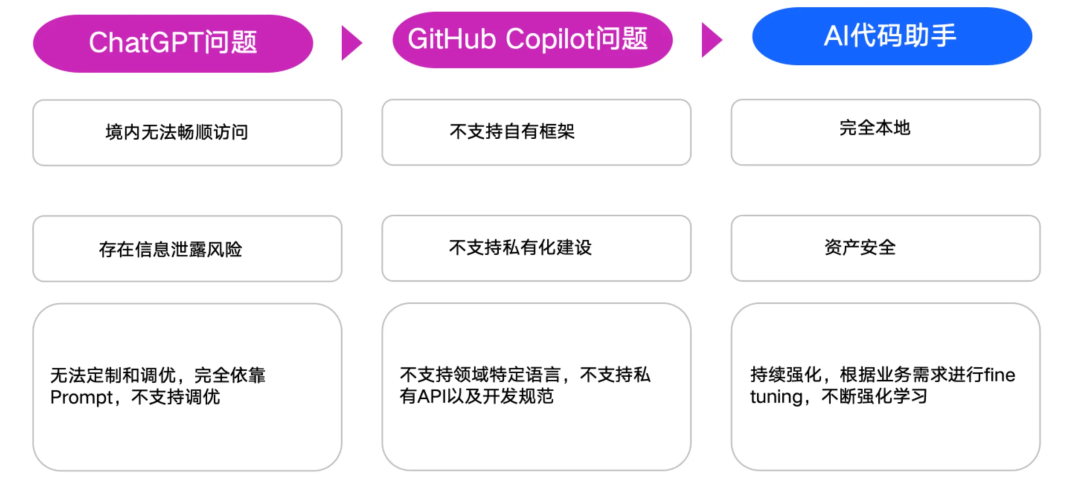
- 什么是SMAF?
SMAF 包含以下内容:
Security:AISE 产品部署在私有云环境。业务代码内网托管,通过内部训练模型,构建集成 IDE 环境,通过自定义逻辑集成业务代码与模型输入/输出,杜绝引入外部安全漏洞;
MaaS:具备多模型统一管理能力。引入多个行业模型,基于不同业务特性和团队习惯进行二次训练,从而得到专属的企业模型;
Analysis:具备指标可观测看板。定义关键指标,对于企业管理者,可以有效观察团队使用代码助手对团队的提升效果。
Full:覆盖全开发流程。AI 代码助手应该覆盖沟通、编码、排错、评审、调优等必要场景。并优先关注编码,沟通环节注重行业深度落地。
我们在内部进行了长期持续的生产内测,正向反馈逐步增加,统计数数据也证明了产品具备相当的价值,这使我们对产品的进一步优化更有信心。

又如在某外部金融企业客户的实测中,我们基于多模平台导入私有化行业模型,基于内部安全合规的语料进行二次训练和微调,重点打磨代码补全、技术对话特性,逐步推广内部试用,完善产品体验,取得了令人初步满意的成效。
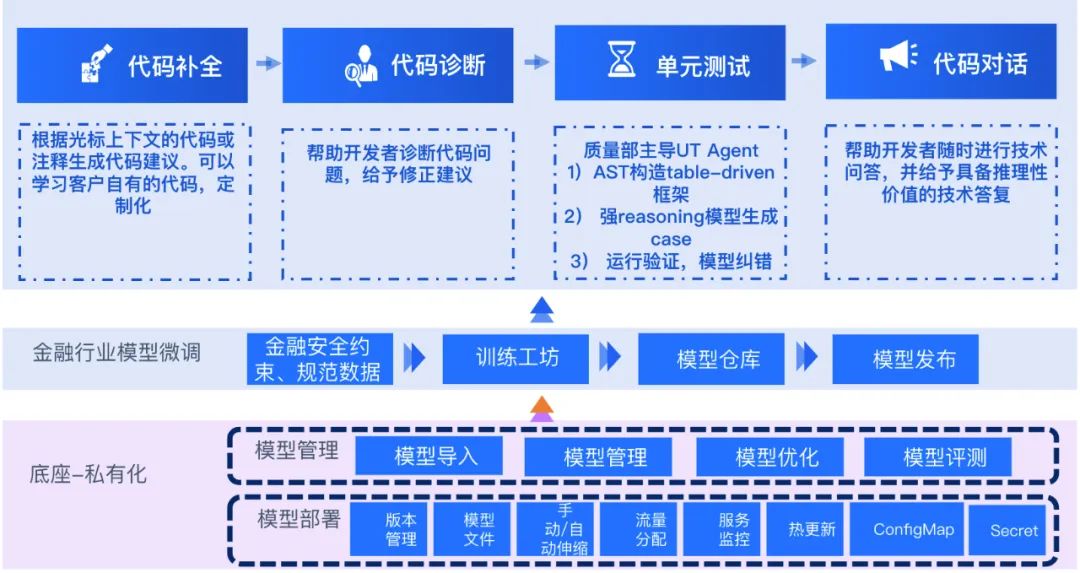
橄榄型产品设计和多模型接入
企业内部可能会存在多种代码模型,不同团队可能会使用不同的模型。而应用侧的产品交互体验,到数据效率报表,这两端则变化不大。于是我们提出了“橄榄型”的应用设想。什么是“橄榄型”呢,就是两端非常的统一,一端是应用交互、执行策略、Prompt设计等高度一致,另一端是数据统计的逻辑,监控和配置平台等高度一致,实现可管理可插拔。中间鼓出来的部分就是多模型接入。用户可以根据不同的业务属性,按需加载不同模型,也可以通过 MaaS 平台为企业按需训练模型,并发布到中间平台里,通过配置下发,自动更新端上配置,即可满足业务对于模型版本的升级。

大模型的“可信”挑战
现在不管是基于大模型的代码生成还是其他场景,怎么样确保可信非常关键。生成的代码或其他场景的产物不见得 100% 正确。有一些场景比如说娱乐、生图或者视频合成,只是在娱乐行业或者广告行业,没有严格意义上对错的场景,这些比较好理解,落地还是比较顺利的。但是在有确定对错的场景,如果万一错了,造成的后果较大,怎么去应对如果没有解决好可能会成问题的。
我们认为一个值得信赖的代码生成模型,应该具备:
- 准确率高;
- 鲁棒性高、稳定性高;
- 不生成危险代码,如不安全的代码、可能产生社会歧视的代码、可能泄漏隐私的代码;
- 行为可预测可控。
模型“评测”挑战
关于代码大模型的能力提升,这也是我们需要持续去应对的。程序语言和自然语言有很大不同,如何针对代码特性设计模型结构和训练方式是值得探索和推进的方向。只将静态代码输入给大模型会由于输入信息量不足而导致大模型对程序的理解不够,如何构造让模型更容易学习和理解的输入数据,比如增加动态执行信息,通过程序语义等价性生成额外的等价程序,会有助于大模型做到程序理解。

如今大家都采用 HumanEval 进行准确度评测,百分比不断提升,可能百分之七八十在特定的数据集上。但竞赛题是比较自包含的,没有太大的耦合度和环境,怎么在真实的代码场景里能做到更好也是一个开放性的课题,需要大家一起往前推进。
今年年初,还没有 HumanEval 的时候,我们非常头疼,怎么来验证模型的正确性和可靠性。我们采用了国外的一个开源框架,思路很简单:用 GPT4 做老师出题,题目从网上搜刮得来,通过 GPT4 搜索和清洗。然后进行模型的两两对比。对比打分的也是 GPT4,打分标准依据代码的五大维度,即:代码语法、可读性、运行结果、复杂度、完整性。示例 prompt 如下:
sys_prompt = "你是检查代码答案质量的有用而精确的助手。你的任务是评估两位助手的编码能力。他们被要求编写一个代码程序来解决给定的问题。请查看他们提交的代码,密切关注他们解决问题的方法、代码结构、可读性。请确保助手提交的代码:1. 根据问题写出正确逻辑的代码。2. 包含准确高效的代码。3. 遵守正确的编码标准和最佳做法。"
sys_prompt1 = "你是检查代码答案质量的有用而精确的助手。你的任务是评估两位助手的编码能力。他们被要求根据一段不完整的代码进行代码补全。请查看他们提交的代码,密切关注他们解决问题的方法、代码结构、可读性。请确保助手提交的代码:1. 根据问题写出正确逻辑的代码。2. 包含准确高效的代码。3. 遵守正确的编码标准和最佳做法。"
default_prompt = "在你根据问题仔细审查了这两个提交后,请提供有关其优点和缺点的详细反馈,以及任何改进建议。您应该首先在第一行输出,其中包含助手 1 和助手 2 的 0-10 分(0: 回答错误;1:无代码/无意义;10:完美)的两个分数,例如“9 8”。然后从下一行开始给出额外的评论。"
default_ques = "我的问题是:\n"
default_ques1 = "需要补全的代码是:\n"这样我们得到了很多国内外的评测结果。后来和 humaneval 测试结果进行比对,也具备一定的可参考性。
软件工程 AISE 全流程覆盖的挑战
另一个挑战是代码大模型下游任务的生态建设,包括测试、调试等更多下游任务及应用细分领域的拓展,辅助解决更多的工程任务;以及更多支撑上下游任务的工具链,包括需求分解、测试用例生成、调试/修复等工具,以更好地支撑智能化软件工程任务。

我们目前只定位在开发工程师角度,其他流程下的不同角色还没有探索,也不能仅凭我们来定义。这类人群有着自己的领域知识、实践流程等等。
LLM 的规模也许会越来越大,也会有各色的专业垂直 LLM 问世,扎深特定的方向,做透一个点,找到产品和商业价值,并与流程中的其他垂直人群正交。
AISE 不仅覆盖开发者。即便是开发域,国内外的研发差异也不同,定义面向国内开发者的研发流程的 AI for SE,需要通过我们对于行业的理解,不断深入思考并不断试错。
小结
整体来讲,AI for SE 以及软件工程 3.0,是我们需要拥抱的能够让我们振奋人心的方向,但是我们也要冷静的思考,AI 和 LLM 是手段,提高效率降本增效是诉求。如何利用好大模型的落地,控制好 LLM 的计算成本,找到行业内研发流程的核心问题,通过 AI 和 LLM 手段去解决,把最高最紧急的痛点去落地解决。由于大模型的挑战和特殊性,企业也必须冷静思考,推行安全可信的模型验证工作,把 AISE 的流程的每个核心场景做透做扎实。

本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-10-18,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号