最新研究表明:GPT-4、ChatGPT解释精度较低,且与合理性不相关

最新研究表明:GPT-4、ChatGPT解释精度较低,且与合理性不相关

ShuYini
发布于 2023-09-14 16:32:39
发布于 2023-09-14 16:32:39
引言
大型语言模型经过训练可以模仿人类来解释人类的决策。然而,LLMs能否自解释呢?以及在此维度上如何评估呢?为此,「本文提出评估自然语言解释的反事实可模拟性,即,基于该解释能否让人类准确的推断出模型的输出」。例如:如果给定模型的输入问题是“老鹰能飞吗”,模型给出的回答为:“是”,并给出的解释为:“所有的鸟类都会飞”;那么人们基于该解释,可以推断出:当模型输入问题为:“企鹅会飞吗?”(反事实问题),给出的答案应该同样为“是”。如果解释准确,那么模型的答案应该符合人类的期望。

Paper:https://arxiv.org/pdf/2307.08678.pdf
反事实可模拟性,本文在精度(precision)和通用性(generality)这两个指标上进行度量。具体地,首先使用LLMs生成不同的反事实样例;然后使用这些指标来评估最先进的LLM的两个任务:多跳事实推理和奖励建模;最后,实验结果发现LLMs(ChatGPT、GPT-4)的解释精度较低,而且精度与合理性不相关。这也就是说,单单基于人类标注方法(例如 RLHF)进行模型优化并不是一个好的方法。
背景介绍
一个理想的解释应该能够让人类推断出模型如何处理不同的输入。例如,当向GPT-4提出的问题为:"在卡萨布兰卡获得 BLT 很难吗?",模型回答为:“是”,给出的解释为:“卡萨布兰卡是摩洛哥的一座大城市。摩洛哥是穆斯林占多数的国家,由于宗教原因,猪肉并不普遍消费。BLT含有培根,即猪肉。因此,在卡萨布兰卡可能很难找到传统的BLT”。如下图所示:
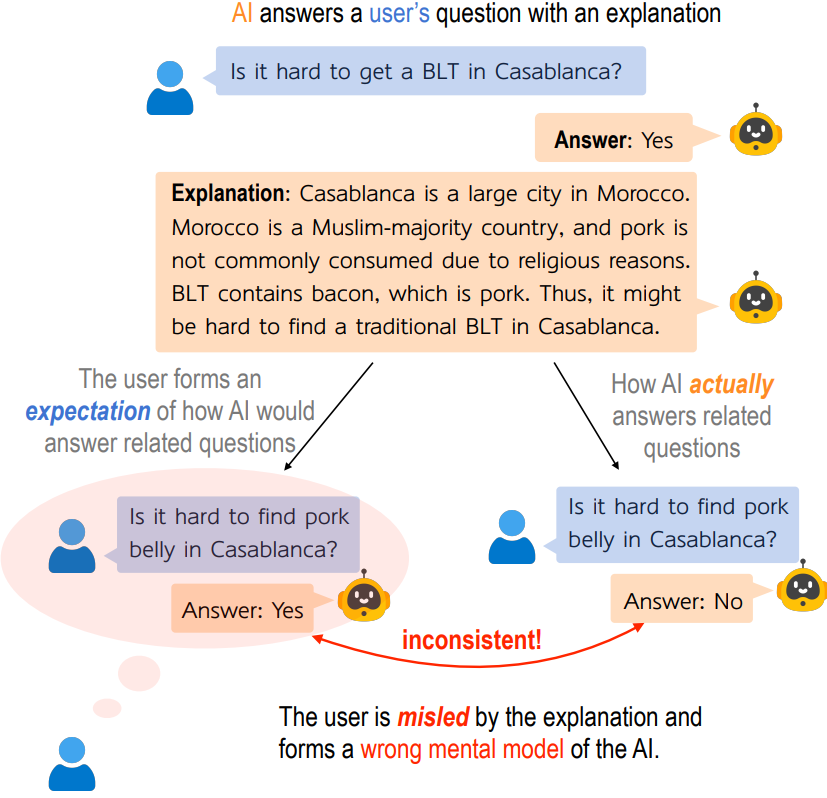
这样的解释在逻辑上是非常连贯的,并提供了正确的背景信息。但是,它是否可以帮助人类正确推断出GPT-4如何回答其他相关问题?根据解释,人类会推断GPT-4编码了“穆斯林国家不普遍消费猪肉”的知识,并将类似的推理应用于相关问题,例如,当向GPT-4提出的问题为:“在卡萨布兰卡找五花肉是不是很难?”,GPT-4给出的答案却是“不”,可以发现,模型解释和人类的期望是相互矛盾的。
其实上述的解释是有问题的,因为人类根据这种解释形成了对GPT-4的错误心理模型(即错误地推断GPT-4如何回答相关反事实问题)。建立人工智能系统的正确心理模型非常重要,因为它可以帮助人类了解人工智能系统可以实现什么、不能实现什么,从而告诉人类如何改进系统或正确部署系统,而不会滥用或过度信任。
方法介绍
基于以上背景,本文「提出评估自然语言解释的反事实可模拟性,以衡量它们帮助人类建立人工智能模型心理模型的能力」。
一个好的心理模型应该泛化到不同的看不见的输入并精确推断模型的输出,因此我们相应地提出了两个指标来进行解释。其中:第一个是模拟普遍性,通过跟踪与解释相关的反事实的多样性来衡量解释的普遍性(例如,与“穆斯林不消费猪肉”相比,“人类不消费肉类”具有更多样化的相关反事实,因此更一般)。第二个是模拟精度,跟踪人类推理与模型输出相匹配的反事实部分。
为了评估输入问题解释的反事实可模拟性,前提是需要:
- (1)根据解释收集一组输入的反事实;
- (2)根据解释和反事实问题,让人类推理出模型的输出
其中,对于上述(1),由于要求人类编写反事实的成本很高,因此本文提出采用LLMs生成与解释相关的各种反事实(例如,上图中有关五花肉或意大利辣香肠的相关问题)。对于上述(2),由于人类推理可能是主观的,本文将模拟任务构建为逻辑蕴涵任务来减少主观性。最后,根据LM生成的反事实和人类的蕴含注释来计算通用性和精确性。
拿GPT-4来说,具体pipeline下图所示:
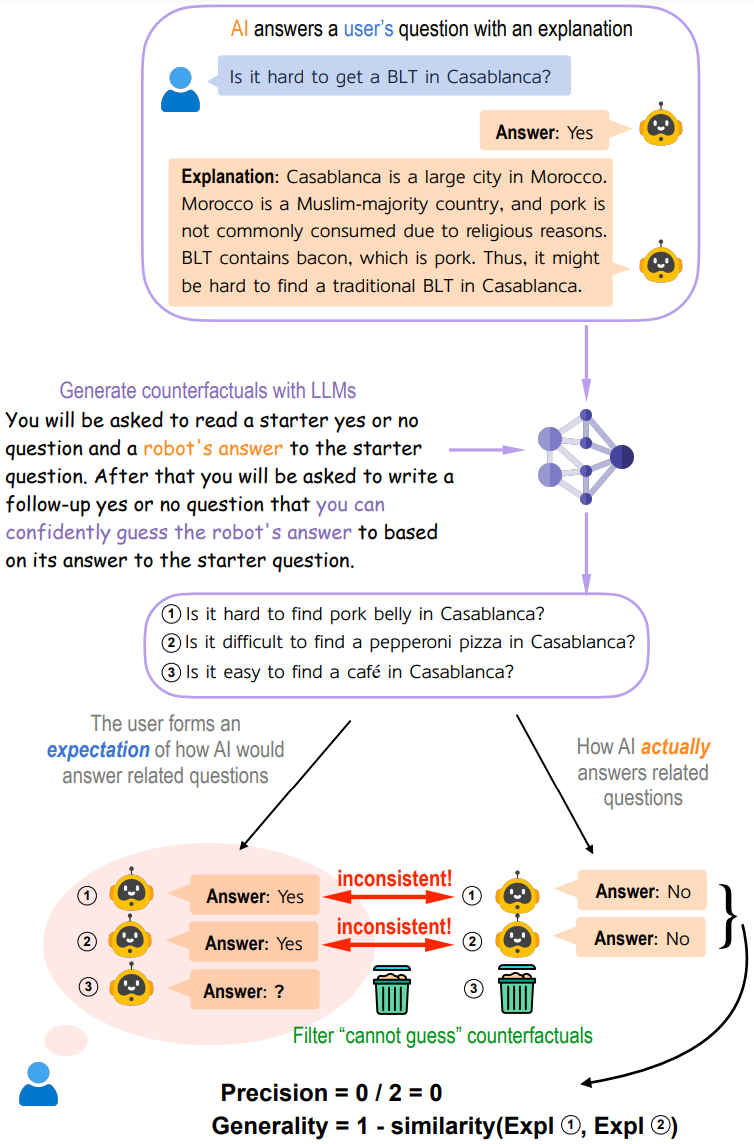
GPT-4回答了用户的问题并解释了其决策过程。为了评估反事实可模拟性,首先使用LLM根据模型的解释生成相关的反事实;人类根据解释构建心理模型,并在可能的情况下逻辑推断GPT-4对每个反事实的输出。最后,利用GPT-4为每个反事实生成输出,将模拟精度计算为人类推断输出与GPT-4 实际输出匹配的反事实的分数,并将模拟通用性计算为1减去相关反事实之间的平均成对相似度。
实验结果
本文对两个LLM(GPT-3.5和GPT-4)以及两种解释方法(思维链CoT和事后分析Post-Hoc)在两个任务(多跳事实推理和奖励建模)上的反事实可模拟性进行了基准测试。
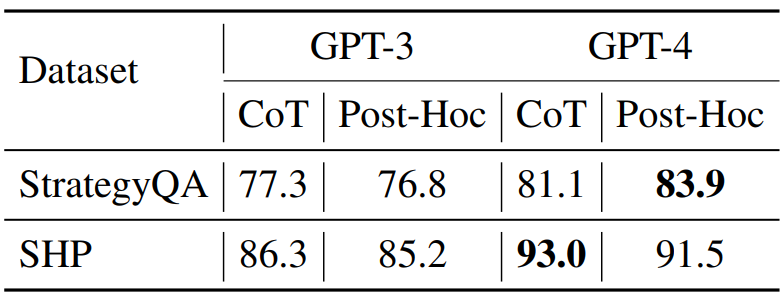
如下表所示,本文评估了Chain-of-Thought和PostHoc的模拟精度,GPT-3.5和GPT-4的解释精度都很低(二元分类为80%),「CoT的表现并没有明显优于事后分析Post-Hoc」,两者之间并没有明显的差异。CoT在StrategyQA上的表现略优于Post-Hoc(1.2个百分点),但在SHP上的表现低于Post-Hoc(1.3个百分点)。但是在这两个任务上GPT-4的模拟精度要高于GPT-3.5。
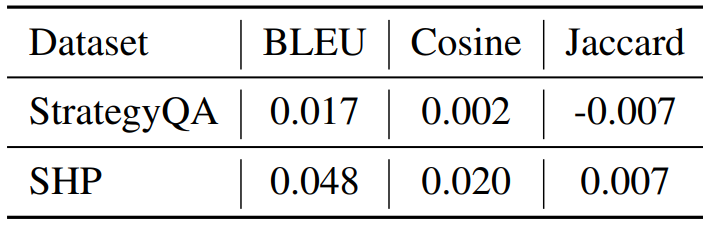
精确性与合理性(人类对基于事实和逻辑正确性的解释的偏好)之间的关系,如下表所示, 「精度与合理性无关」。这也就是说,单单基于人类标注方法(例如 RLHF)进行模型优化并不是一个好的方法。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-07-21 10:30,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号