基于Spline的数据血缘解析


一、前言
什么是数据血缘?数据血缘是数据产生、加工、转化,数据之间产生的关系。随着公司业务发展,通过数据血缘,能知道数据的流向,以便我们更好地进行数据治理。
二、为什么选择 Spline?
政采云大数据平台的作业目前主要有 Spark SQL、PySpark、Spark JAR、数据交换、脚本类型等,最初由于实现难度的问题,考虑解析 SparkPlan( Spark 物理计划)以获取表、字段血缘,但此方案针对 PySpark、Spark JAR 之类的作业自行解析较为复杂,而 Spline 则支持以上类型作业的解析。
附:SparkPlan
下图为 SparkPlan( Spark 物理计划)中的详情。
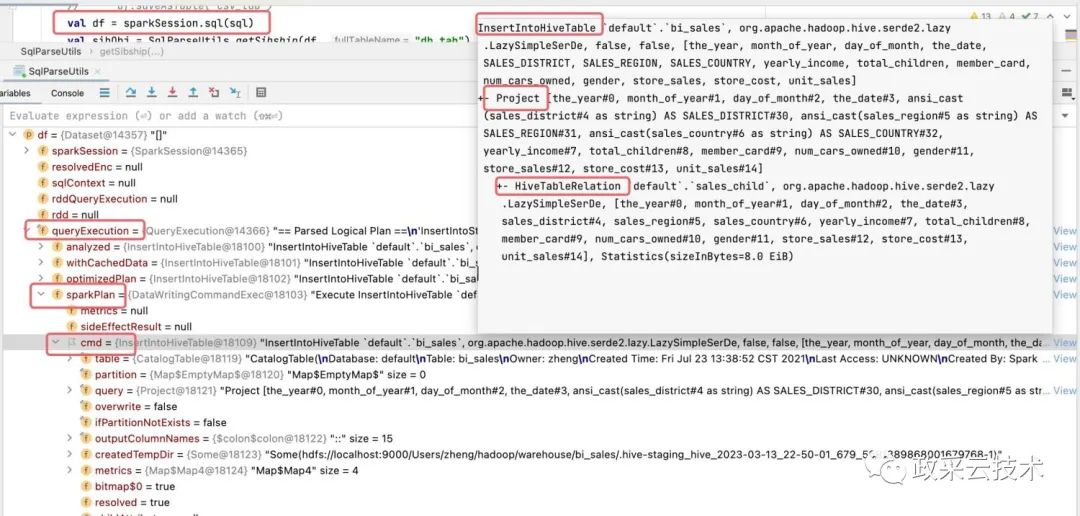
从 Reference 中可以获取到解析完后依赖的字段信息
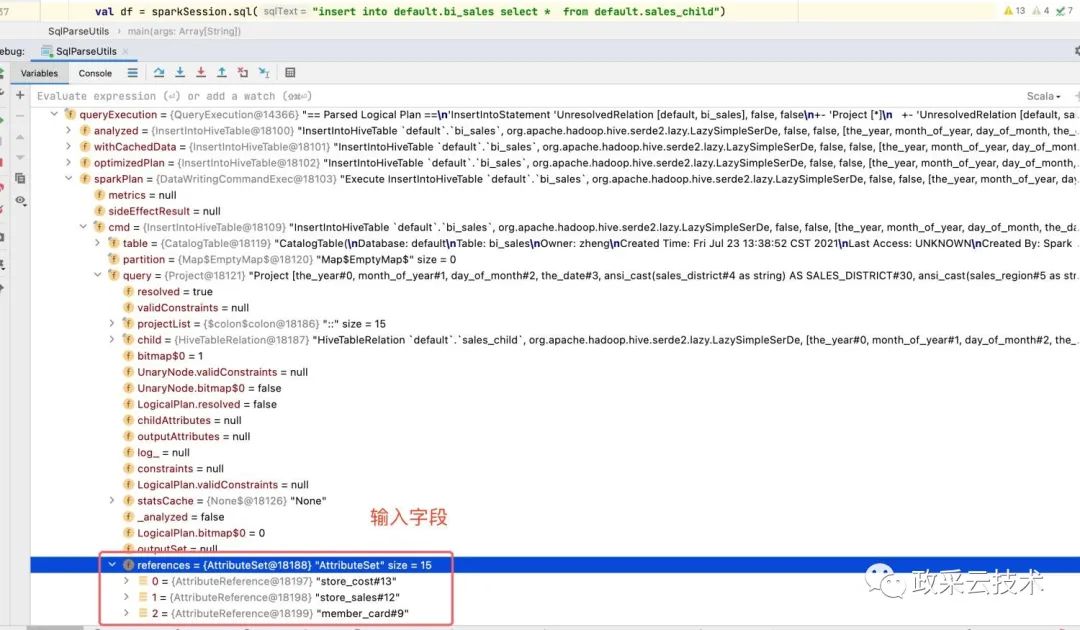
三、解析
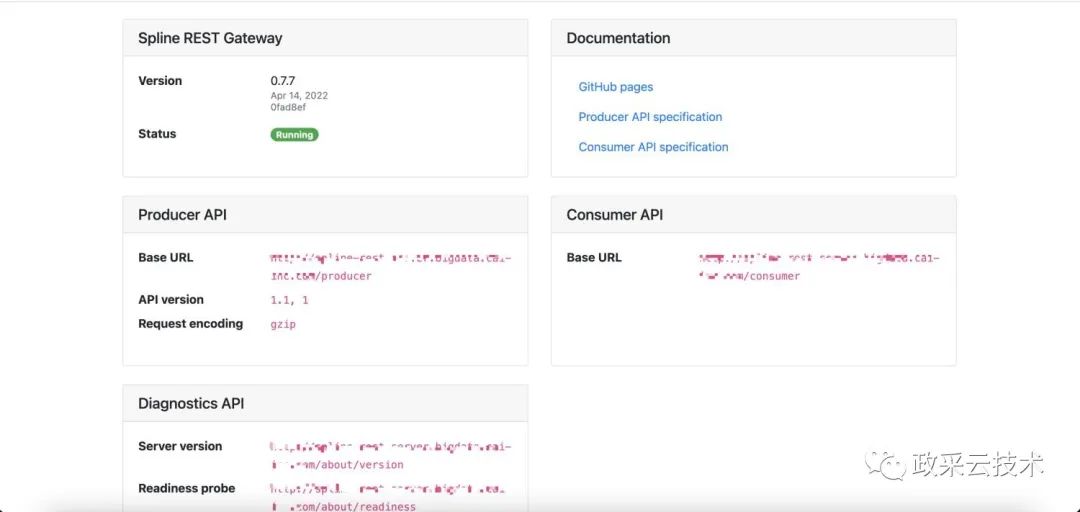
通过 Spline REST 文档可见,REST 接口分 Producer 和 Consumer 两部分,Spline Producer 支持把解析完的数据发送到 Kafka,应用可消费 Kafka 数据获取字段血缘数据进行解析,但政采云大数据平台,基于业务需要,字段血缘需要跟作业绑定,若通过消费 Kafka 的方式,无法在获取字段血缘数据的同时跟作业绑定。故,目前使用了调用 Consumer 端接口的方式获取字段血缘。 附,Spline REST 文档
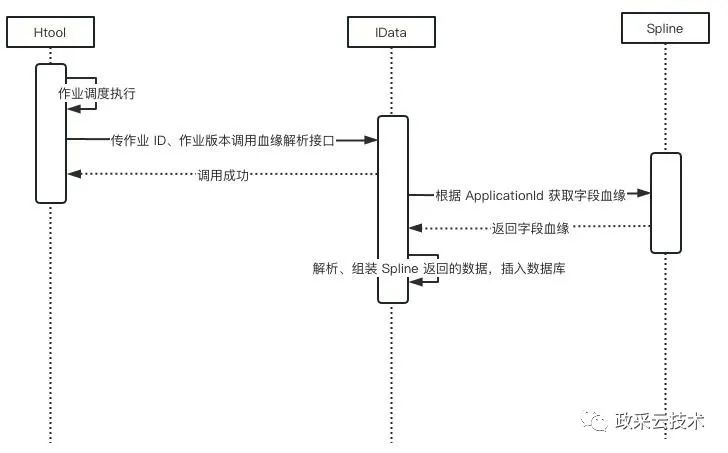
1、血缘解析流程
Htools:政采云大数据平台的一个调度工具 IData:政采云大数据平台应用层
2、基于接口解析血缘
解析字段血缘,主要涉及到 Consumer 端的接口,在 Api 接口文档中,我们可以看到各个接口详细的介绍。
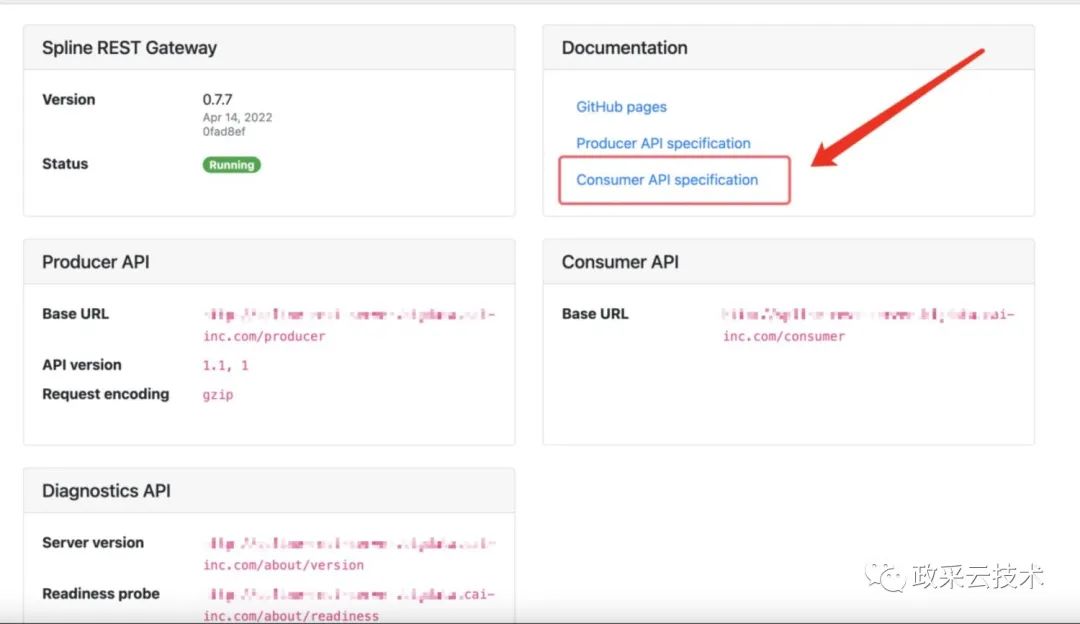

3、示例
以下案例基于 insert into …… select …… 语句的解析
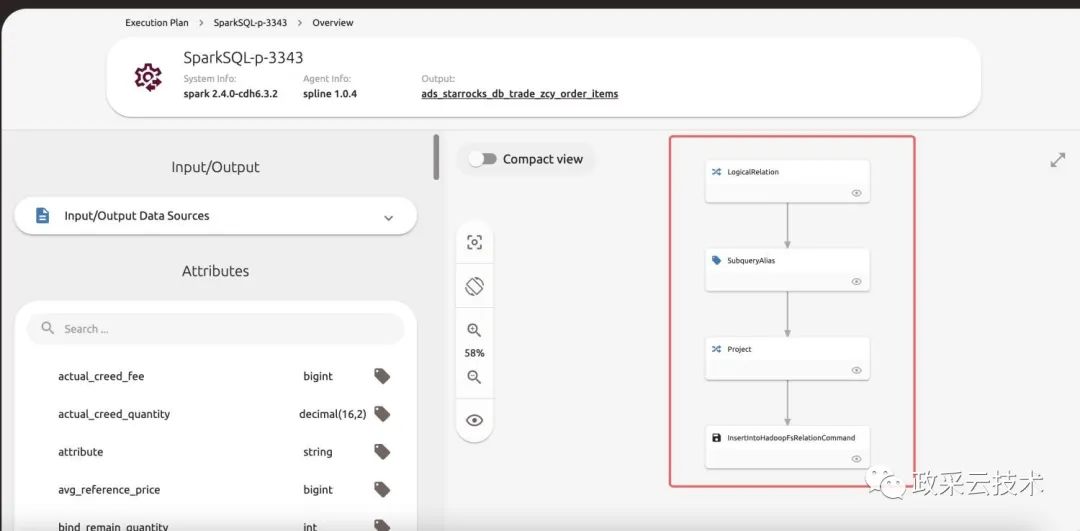
(1)执行计划
从下图,可以看到一个 insert into …… select …… 语句,被解析成几个步骤,下列截图所对应的步骤,和 Spark 物理计划一致。
(2)根据 applicationId 获取 planId


(3)根据 planId 获取执行节点信息
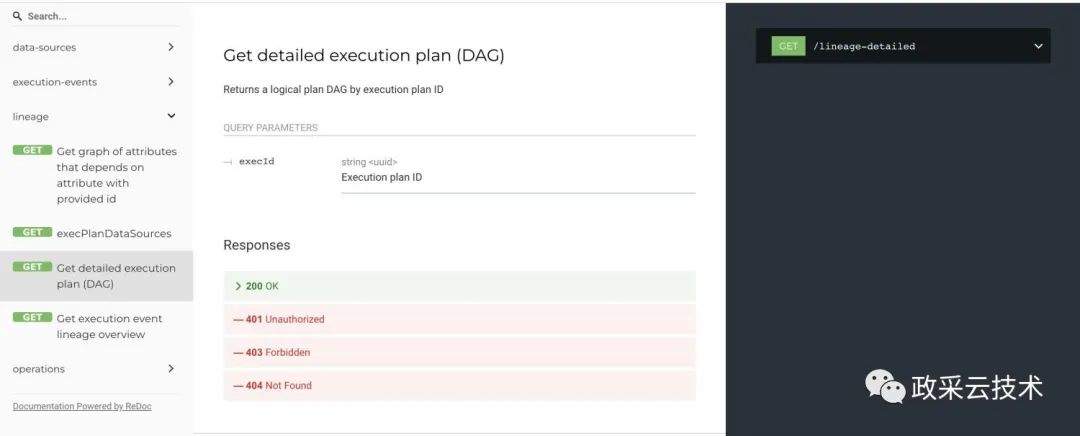
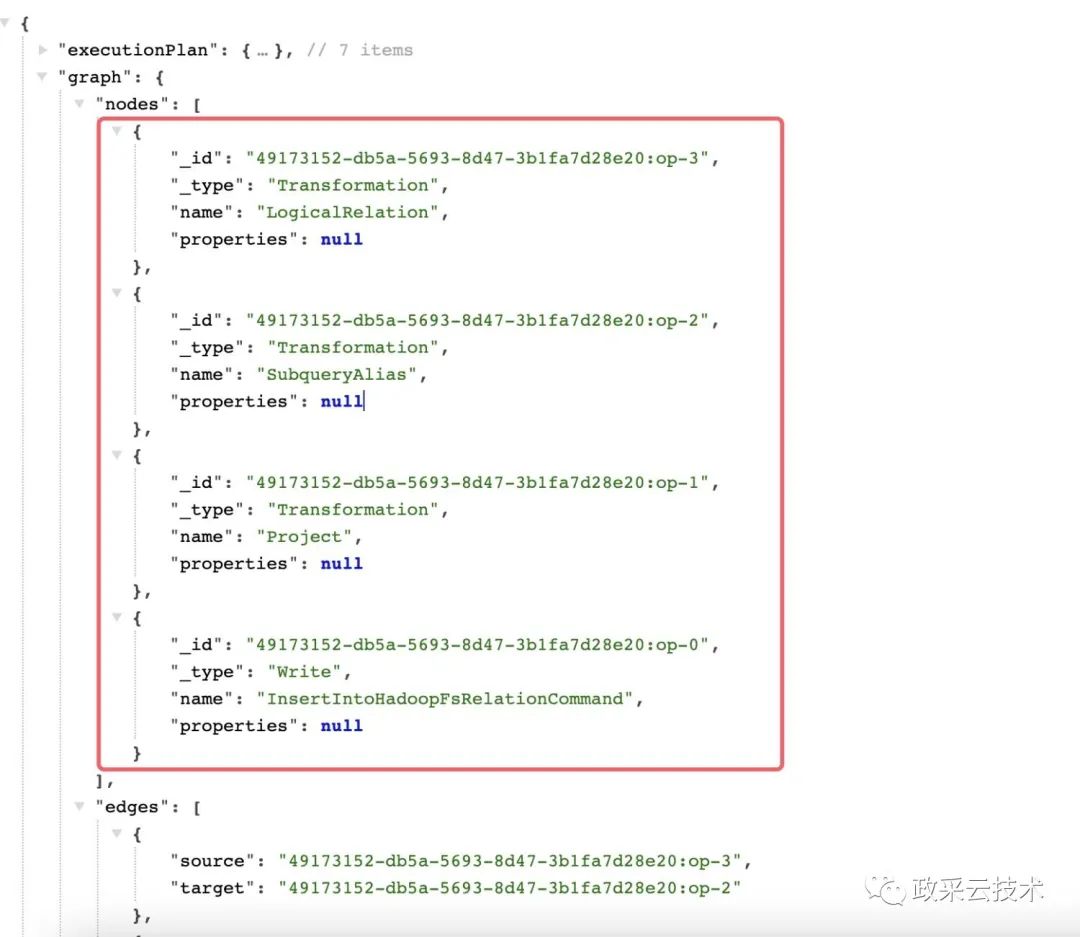
(4)根据节点 id 获取对应的信息
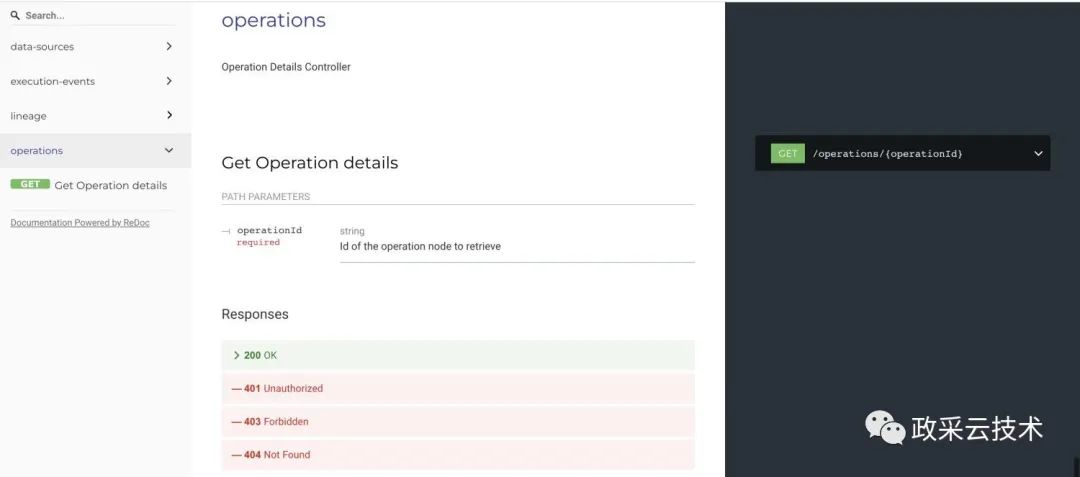
a、根据 Project 节点,获取输入表和输出表之间的字段血缘关系

b、根据 Relation 获取字段对应的表。
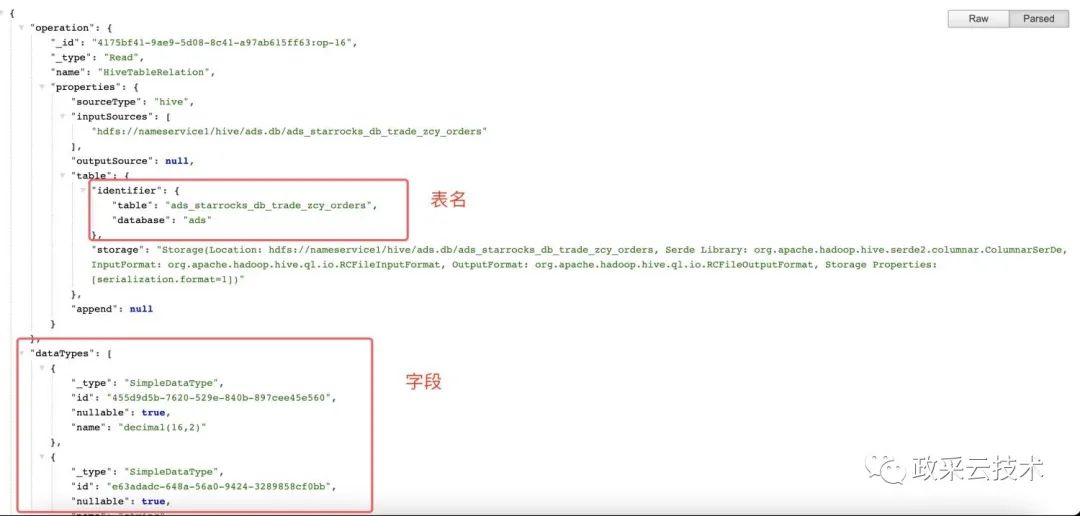
Hive 表的 Relation 分 HiveTableRelation 和 LogicalRelation 两种,有 Catalog 的 Hive 表是 LogicalRelation,无 Catalog 的 Hive 表是 HiveTableRelation。
为什么要多此一举再调用接口获取表跟字段的对应信息?
在 Project 中获取输入表和输出表之间的对应的字段,无法知道输入表涉及到的字段对应具体的表,所以需要根据 Relation 获取所有字段和表之间的关系,从而根据字段 Id 获取表。
(5)根据字段获取依赖的字段
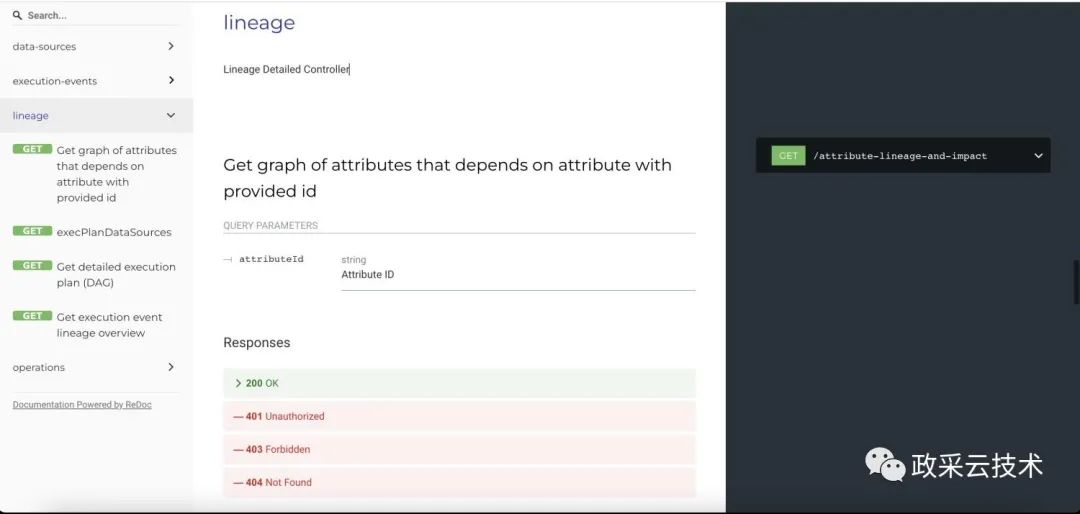
从 Project 中获得的字段血缘,一些复杂场景是无法直接获取到的。如在实际中,大量涉及到诸如 with input_tab as( …… ) insert into output_tab as select * from input_tab 的语句,这种语句,根据 REST 接口获取到的字段信息,只能获取到最外层的字段信息,跟内层 sql 依赖的字段信息是脱节的,故,需要当前接口辅助获取内层依赖字段。
4、调优
表、字段血缘跟作业绑定,故,若作业无变化的情况,表、字段的血缘是不会变化的,在作业调度完后,调用解析血缘的接口时,我们结合当前作业版本和前一次血缘记录中的作业版本进行比对,若作业版本不一致的情况才更新血缘,否则则不操作。
5、成果展示
如下图所示,可以看到字段 settle_record_id 上下游字段血缘关系。

四、总结
基于 Spline REST 接口获取表、字段血缘等相关信息,在实际实现过程中,每个作业调用的总接口次数是比较多的,但即便调用次数较多,也在服务器可承受范围内,上线后第一次解析血缘接口调用比较密集,后续只有在作业版本有变化的时候才会重新解析血缘。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-06-15,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号