使用GPT4快速解读整个python项目的几个尝试方法之二2023.6.14

使用GPT4快速解读整个python项目的几个尝试方法之二2023.6.14

用户7138673
发布于 2023-08-16 21:38:30
发布于 2023-08-16 21:38:30
1、这个脚本会遍历目标文件夹及其子文件夹(深度最多为2),找出所有.py文件,并查找其中的def和class行。这个脚本把文件夹、文件和代码行的树状结构写入到一个.txt文件中。每个子级别会增加一级缩进。
import os
def process_folder(folder_path, indent="", depth=0):
result = f"{indent}[{os.path.basename(folder_path)}]\n"
for item in os.listdir(folder_path):
item_path = os.path.join(folder_path, item)
if os.path.isfile(item_path) and item.endswith('.py'):
result += f"{indent} {item}\n"
with open(item_path, 'r', encoding='utf-8') as file:
for line in file:
if line.lstrip().startswith(('def ', 'class ')):
result += f"{indent} {line}"
elif os.path.isdir(item_path) and depth < 2:
result += process_folder(item_path, indent + ' ', depth + 1)
return result
# 设置输出文件名
output_file = "folder_structure_new.txt"
# 获取当前目录作为目标文件夹
target_folder = os.getcwd()
# 调用处理文件夹的函数开始处理,初始深度为0
output = process_folder(target_folder)
# 将结果写入到输出文件
with open(output_file, 'w', encoding='utf-8') as file:
file.write(output)
2、可以用PowerShell完成吗?不行,文件夹和文件名称一直读不到。
3、这个是一个python项目的文件夹、py文件名、class、def,把英文翻译为中文,并用流程插件,生成完整的流程图
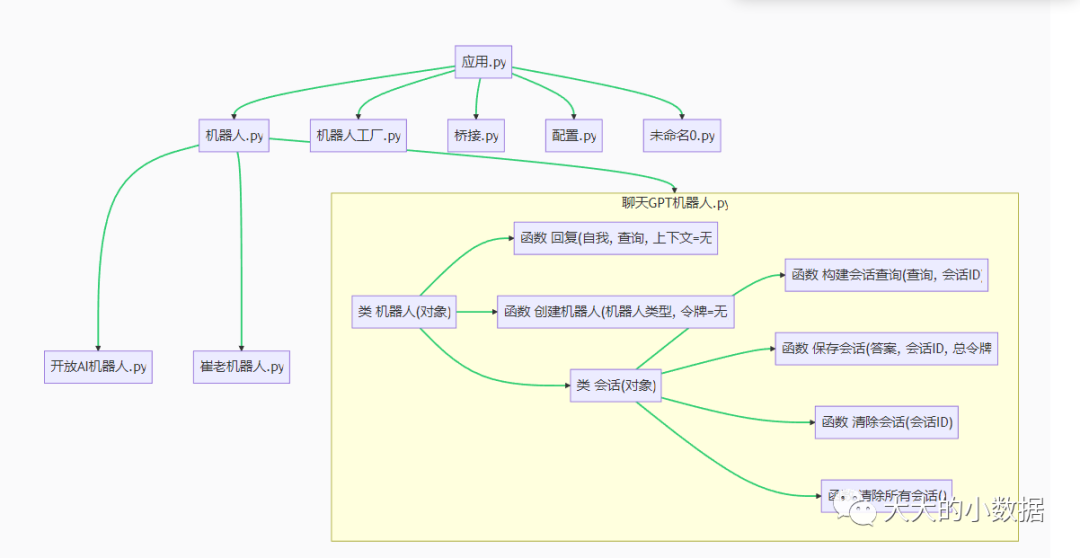
4、
[chatgpt-bot-wechat]
[.git]
[hooks]
[info]
[logs]
[objects]
[refs]
[.github]
[.idea]
[inspectionProfiles]
[.venv]
[bin]
activate_this.py
[lib]
[share]
app.py
[bot]
[baidu]
baidu_unit_bot.py
class BaiduUnitBot(Bot):
def reply(self, query, context=None):
def get_token(self):
bot.py
class Bot(object):
def reply(self, query, context=None):
bot_factory.py
def create_bot(bot_type, token=None):
[chatgpt]
chat_gpt_bot.py
class ChatGPTBot(Bot):
def __init__(self):
def reply(self, query, context=None):
def reply_text(self, session, session_id, retry_count=0) ->dict:
def create_img(self, query, retry_count=0):
class Session(object):
def build_session_query(query, session_id):
def save_session(answer, session_id, total_tokens):
def discard_exceed_conversation(session, max_tokens, total_tokens):
def clear_session(session_id):
def clear_all_session():
[openai]
open_ai_bot.py
class OpenAIBot(Bot):
def __init__(self):
def reply(self, query, context=None):
def reply_text(self, query, user_id, retry_count=0):
def create_img(self, query, retry_count=0):
class Session(object):
def build_session_query(query, user_id):
def save_session(query, answer, user_id):
def discard_exceed_conversation(session, max_tokens):
def clear_session(user_id):
def clear_all_session():
[zhishuyun]
cuilao_bot - 副本.py
class CuiLaoBot(Bot):
def __init__(self, token):
def reply(self, query, context=None):
def clear_session(self):
cuilao_bot.py
class CuiLaoBot(Bot):
def __init__(self, token):
def reply(self, query, context=None):
[__pycache__]
[bridge]
bridge.py
class Bridge(object):
def __init__(self):
def fetch_reply_content(self, query, context):
def fetch_voice_to_text(self, voiceFile):
def fetch_text_to_voice(self, text):
[__pycache__]
[channel]
channel.py
class Channel(object):
def startup(self):
def handle_text(self, msg):
def send(self, msg, receiver):
def build_reply_content(self, query, context=None):
def build_voice_to_text(self, voice_file):
def build_text_to_voice(self, text):
class Channel(object):
def startup(self):
def handle_text(self, msg):
def send(self, msg, receiver):
def build_reply_content(self, query, context=None):
def build_voice_to_text(self, voice_file):
def build_text_to_voice(self, text):
channel_factory.py
def create_channel(channel_type):
[wechat]
wechaty_channel.py
class WechatyChannel(Channel):
def __init__(self):
def startup(self):
def check_prefix(self, content, prefix_list):
def check_contain(self, content, keyword_list):
wechat_channel.py
def handler_single_msg(msg):
def handler_group_msg(msg):
def handler_single_voice(msg):
class WechatChannel(Channel):
def __init__(self):
def startup(self):
def handle_voice(self, msg):
def _do_handle_voice(self, msg):
def handle_text(self, msg):
def _handle_single_msg(self, msg, content):
def handle_group(self, msg):
def send(self, msg, receiver):
def _do_send_voice(self, query, reply_user_id):
def _do_send_text(self, query, reply_user_id):
def _do_send_img(self, query, reply_user_id):
def _do_send_group(self, query, msg):
def check_prefix(self, content, prefix_list):
def check_contain(self, content, keyword_list):
[__pycache__]
[common]
expired_dict.py
class ExpiredDict(dict):
def __init__(self, expires_in_seconds):
def __getitem__(self, key):
def __setitem__(self, key, value):
def get(self, key, default=None):
log.py
def _get_logger():
tmp_dir.py
class TmpDir(object):
def __init__(self):
def path(self):
[__pycache__]
config.py
def load_config():
def get_root():
def read_file(path):
def conf():
[docker]
[sample-chatgpt-on-wechat]
[docs]
[images]
[scripts]
[voice]
[baidu]
baidu_voice.py
class BaiduVoice(Voice):
def __init__(self):
def voiceToText(self, voice_file):
def textToVoice(self, text):
[google]
google_voice.py
class GoogleVoice(Voice):
def __init__(self):
def voiceToText(self, voice_file):
def textToVoice(self, text):
[openai]
openai_voice.py
class OpenaiVoice(Voice):
def __init__(self):
def voiceToText(self, voice_file):
def textToVoice(self, text):
voice.py
class Voice(object):
def voiceToText(self, voice_file):
def textToVoice(self, text):
voice_factory.py
def create_voice(voice_type):
[__pycache__]
[__pycache__]5、
这是一个 Python 项目,看起来是一个基于 WeChat 的聊天机器人,它使用了多个不同的机器人和语音处理引擎。以下是我对项目结构的解读:
.git,.github,.idea,.venv和__pycache__是与版本控制、IDE、Python 虚拟环境和 Python 字节码缓存相关的目录,不直接与项目功能有关。app.py可能是整个项目的主入口文件。bot文件夹包含了多个机器人的实现,如baidu_unit_bot.py(百度的机器人)、chat_gpt_bot.py(使用GPT模型的机器人)、open_ai_bot.py(OpenAI的机器人)和cuilao_bot.py(CuiLao的机器人)等。它们都继承自bot.py中的Bot类,这可能是一个抽象基类,定义了所有机器人应该有的接口。另外,bot_factory.py可能用于根据类型动态创建机器人。bridge文件夹可能包含的是在项目中进行消息传递的相关代码。channel文件夹看起来包含了消息通道的代码,比如wechaty_channel.py和wechat_channel.py。Channel类可能定义了消息通道应有的接口,而channel_factory.py可能用于根据类型动态创建消息通道。common文件夹包含一些通用的代码和工具,如日志工具log.py,临时目录处理tmp_dir.py,以及一种可以设置过期时间的字典expired_dict.py。config.py看起来是用来读取和处理配置信息的。docker文件夹可能包含了 Docker 相关的文件,以便将此项目容器化。docs文件夹可能包含了项目的文档。voice文件夹可能包含了处理语音的代码,包括不同语音处理引擎的实现,如baidu_voice.py(百度的语音处理)、google_voice.py(Google的语音处理)和openai_voice.py(OpenAI的语音处理)等。Voice类可能定义了语音处理引擎应有的接口,而voice_factory.py可能用于根据类型动态创建语音处理引擎。
总的来说,这个项目看起来使用了工厂模式来动态创建机器人、消息通道和语音处理引擎,从而提供了很高的扩展性和灵活性。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-06-15,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号