腾讯灯塔融合引擎的设计与实践



丨导语丨
本文分享的主题是腾讯灯塔融合引擎的设计与实践,主要围绕以下四个方面进行介绍:
1. 背景介绍
2. 挑战与融合分析引擎的解法
3. 实践总结
4. 未来演进方向
分享作者|冯国敬 腾讯 后台开发工程师
一
背景介绍
腾讯灯塔是一款端到端的全链路数据产品套件,旨在帮助产品、研发、运营和数据科学团队 30 分钟内做出更可信及时的决策,促进用户增长和留存。

2020 年后数据量仍然呈爆炸性增长的趋势,且业务变化更加迅速、分析需求更加复杂,传统的模式无法投入更多的时间来规划数据模型。我们面临一个海量、实时和自定义的三角难题。不同引擎都在致力于去解决这个问题。谷歌等博客中曾提到,也是我们很认可的一个观点是以卓越的性能可直接访问明细数据(ODS/DWD)成为下一代计算引擎的必然趋势。

下图展示了灯塔融合分析引擎的整体技术架构:

左侧对接应用系统,包括灯塔自己提供的分析模型、可视化方案和一些 API 请求;右侧为融合分析引擎,包括查询引擎层、计算层、物化存储层、存储层分析策略中心和产品化中心。
- 服务层,包括查询、接收以及治理,比如任务级别的缓存拦截等服务相关功能。
- 计算层,不同于其他公司的自研方案,我们是在开源能力之上做增强和整合,来满足不同场景的需求。
- 物化存储层,其中包含了我们构建现代物化视图的解决方案,实现了基于 Alluxio 的块级别缓存池,以及针对 BI 场景基于 Clickhouse 的抽取加速方案。
- 存储层,对接了多种存储引擎,包括托管给灯塔的存储层和非托管的存储层,即业务方自己的数据。
- 分析策略中心,位于上述四层之上。主要负责业务方查询的工作负载中的治理和理解执行的整体链路。从一个任务开始执行,到执行计划的各个阶段的计算的资源消耗、存储的消耗、效率等表征作统一存储,并基于这些明细的数据抽出来一些衍生的指标,以推动任务优化,比如物化模型的构建和 SQL 自动优化,旨在端到端地解决这些问题。
- 产品化中心,除了灯塔产品套件整体作为产品对外输出以外,融合分析引擎也可以单独作为产品对外输出。
二
挑战与融合分析引擎的解法
回到前文提到的挑战,即以卓越的性能直接访问明细数据,我们会从融合、内核优化和加速三个方面发力。
1. 融合
同类产品的思路多为一体化,而本文的思路是取长补短,博采众长,融合开源社区的能力实现 1+1>2 的效果。
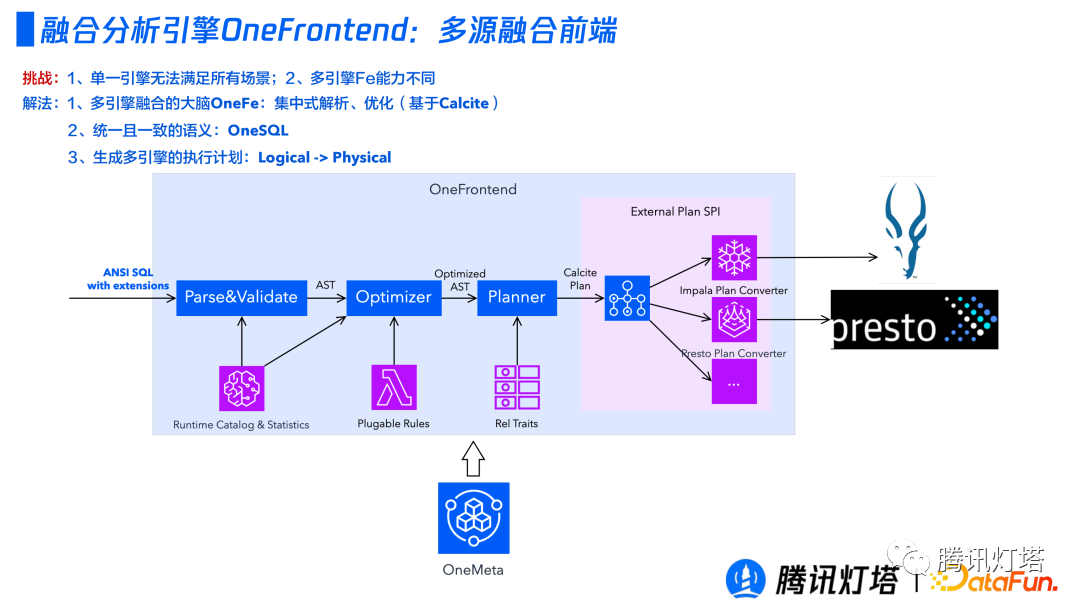
① 多源融合前端
前端聚焦于提供集中化的 SQL 解析、优化和执行计划生成。它更多的承担的是对各个底层的理解以做出更优逻辑执行计划的角色。
前端是基于 Calcite 的两段式。第一段为常规操作,一个 SQL 要经过 Parse、Validate、Optimizer、Planner,通过自建的统一元数据管理中心来提供了运行时的Catalog和统计信息以辅助生成更优的执行计划;第二段为不同引擎的融合,提供统一的对外接口且进行一些定制化的增强。
② 融合后端
前端主要解决的是 SQL 解析和执行计划的生成优化,融合后端真正解决计算层面融合。
RDBMS面临算力、内存不足,无法提高计算并行度;Clickhouse 数据源面临复杂查询效率低等问题。
针对上述问题分别有以下解决方案:
- 通用 MPP 引擎(Presto\Impala)加上高性能 connector。
- 增强版 JDBC Connection,基于Mysql表模型对 Split Providers 进行自适应的优化,将单个 Table Scan 转换为多个 Table Scan 以提升计算效率。
- 针对 Clickhouse 数据源会将分布式表运算改为基于本地表运算。
- 对 Projection、Aggregation、Predicate 操作进行下推。

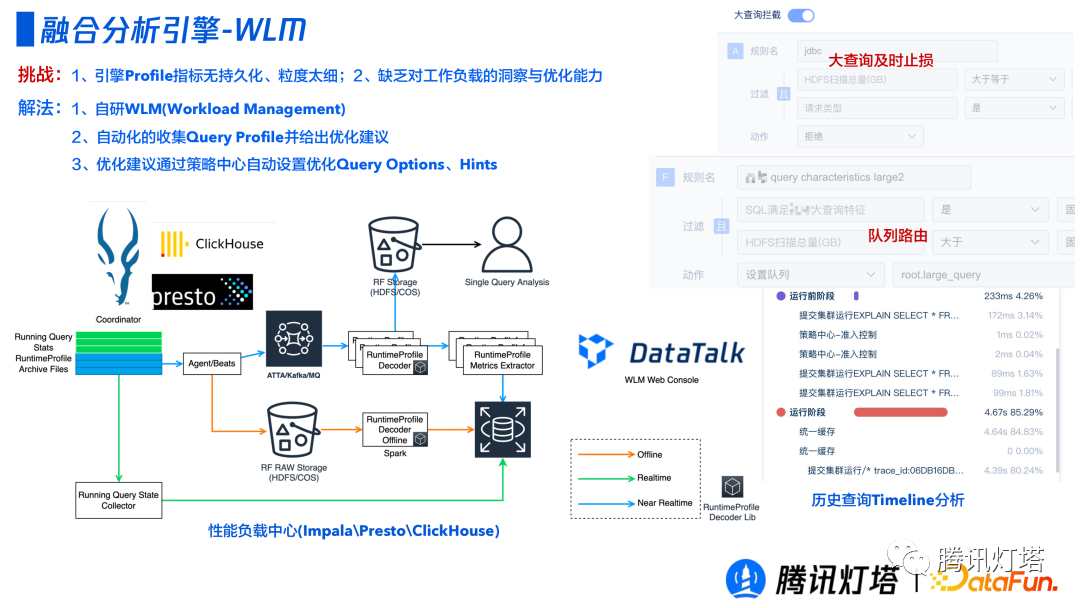
③ WLM(Workload Management)
前端和后端解决的是多个引擎如何融合和配合的问题,除此之外是端到端的分析策略中心的实现。裸用开源引擎存在以下问题:
- 引擎 Profile 指标无持久化,单点分析粒度太细,无法对租户整体进行洞察;
- 对运维人员要求高,需要足够的工作负载的洞察与优化的能力。
本设计的解决方案是通过自研的WLM(Workload Management),自动化收集不同引擎的 Query Profile 并结合历史查询给出基于专家经验给出优化建议,在策略中心基于优化建议自动设置 Query Options、Hints 等优化配置。
通过一系列的规则探查到这个 SQL 会存在大量的 Shuffle,会导致占用了大量的内存和网络资源。该装置会注入一些 Query Options 和 Hints,比如把它的 broadcast 换成 shuffle join,对于一些 CPU 优化器完成不了的事情基于我们的策略做一个自动优化,等 SQL 再进来就会有比较好的规划。
2. 内核优化
在商业场景下经常会遇到很消耗资源量的大查询,如何能够在运行时识别和隔离大查询成为一个挑战。
查询在运行前是无法断定其查询对资源的影响的,比如两表 JION 后笛卡尔积的导致其输出有上万亿记录数的规模。于是本引擎在收集监控运行时的指标参数,结合负载中心的优化建议,自动设置优化参数,以使得查询更高效的运行;对于无法优化且识别对资源使用有严重影响的查询,会进行拦截,及时止损。

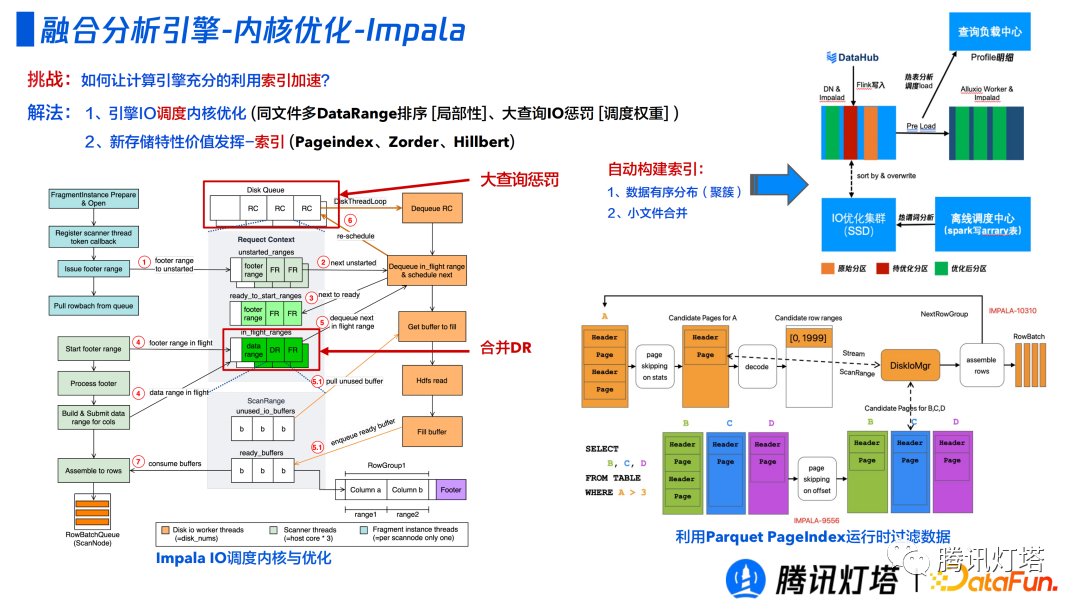
① Impala
Impala 面临的一个挑战是如何充分利用计算引擎的索引加速。
- 引擎 IO 调度内核优化,比如局部性的同文件多 DataRange 排序;通过调整权重以实现大查询 IO 惩罚,因为有些场景更多想保小查询,将大查询放到慢车道。
- 存储特性价值发挥-索引(Pageindex、Zorder、Hillbert)。要高效查询原始数据,就需要利用好原始数据中的索引,比如 Parquet 中的数据页 Page Index,可以结合原始存储数据中的索引信息,在运行时进行数据过滤。如果要达到很高的效率,往往不是算法本身,而是底层的数据分布。比如一个谓词的列都是随机分布,那么一个值分布在每个数据页,就无法进行跳过,我们会通过负载中心查看历史查询去优化 Zorder 或者 Hillbert 索引。
② Presto
云架构 Presto 在大规模集群下如何保持高效的 Scalabaility Coordinator 单点问题是一个公认的挑战,这部分优化并非我们独创,而是业界的一个 feature。
第一种方案是 Coordinator HA 方案,但其并没有从根源解决问题,一旦 Active 节点失活,过不久 stand by 节点也会挂掉。
第二种方案是多 Cluster 联邦方案,部署多个集群,通过 Presto Gateway 路由不同的集群。但是路由策略管理是一个很大的难点,如果路由策略不当会带来严重的资源碎片化。
第三种方案是 Disaggregated Coordinator 方案,引入了 ResouceManager 聚合分布式资源状态,每个 RM 内存中维护一份状态数据,RM 之间通过心跳达成状态数据的最终一致。Coordinator 可以正常的 Parse、Validate、Plan,准入时 RM 统一获取资源视图,判断是执行还是等待等状态。

③ Kudu
这是一个不常见的问题,在一个运行很久的大集群,有一台机器要裁撤,由于大集群长时间运行元信息负债严重,导致 Tablet Server 无法优雅下线(需要重启 master),耗时可能高达几小时。
在一次实际生产 Case 中,几十万 Tablet,占用内存 50G 以上,Master 启动和Leader 切换都非慢。经排查,集群一直在加载元数据,并发现以前删除的表和数据集群还在维护。通过源码级别的增强,Master 内存消耗降低 10 倍。

3. 加速
考虑到集群的算力和引擎本身的瓶颈上限,除了融合和内核优化,我们还需要做各种各样的加速手段。
除了引擎优化,Databrick 商业版的 OLAP 引擎添加了缓存层和索引层;Snowflake 支持了物化视图的能力;Google 的 BigQuery 提供了多级缓存,以进一步的加速。缓存、计算优化、索引与数据分布、物化、云化是业界的主攻方向,本次分享主要介绍三种手段。

① 缓存
实际场景中经常会遇到重复的查询,我们需要解决如何通过多级缓存机制避免“硬查”集群,加速“SQL 内”的数据扫描性能。该引擎的缓存设计借鉴了 Databrick 的内核缓存、Snowflake 的数仓缓存的缓存设计理念,研发了预计算与多级缓存的技术。
- 预计算(固定图卡):通过“增量缓存”只刷最新天数据,避免大量数据扫描
- 统一缓存(重复查询判+非固定图卡缓存):深耕 Calcite 源码,基于 SQL 常量折叠(变更检测)、SQL改写、SQL规则判断。
- 内核缓存(大 SQL 内存缓存):通过远程告诉缓存+SQL磁盘溢写缓存(Alluxio),加速大查询,减轻 HDFS IO 压力。
- Alluxio(HDFS 热数据缓存->SSD):通过对历史 SQL 性能数据分析,缓存热表(如大左表)。

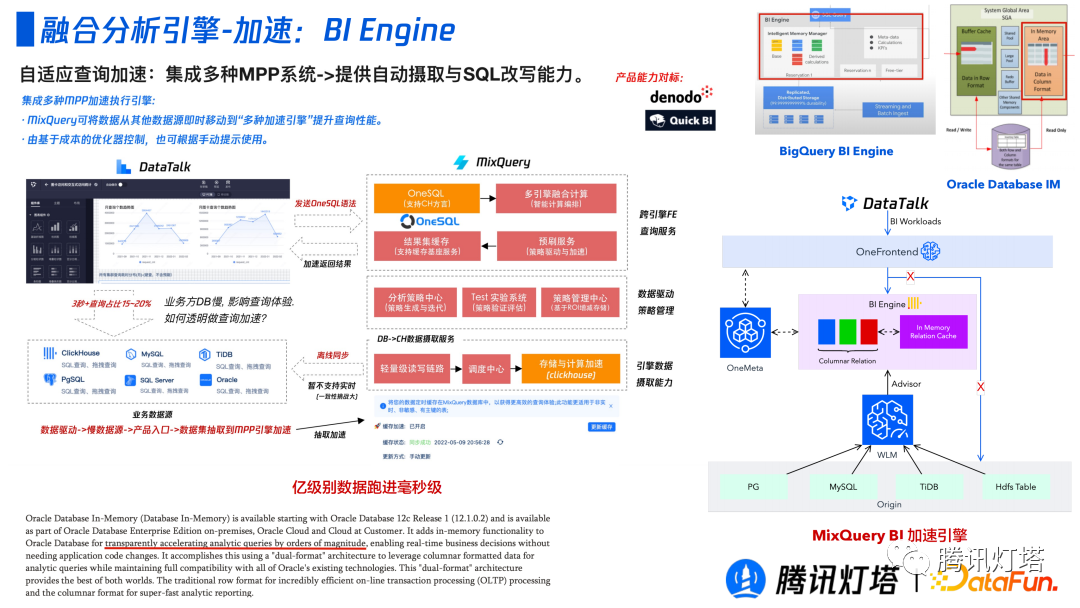
② BI Engine
由于 BI 场景不用其他的查询分析场景,BI 场景下的看板对出数的时延要求很高,所以需要 BI 场景进行了特殊的优化。借鉴以 BigQuery 为例,它是有一块单独的内存池,它会根据历史查询判断出热数据并以列式的缓存下来。该引擎除了使用到上述的默认策略,还会添加一个 Clickhouse 的缓存层,基于历史记录判断那些数据是可加速并透明的将可加速的表移动到 Clickhouse 中作为缓存数据。这一整套策略可以让亿级数据运行至毫秒级。
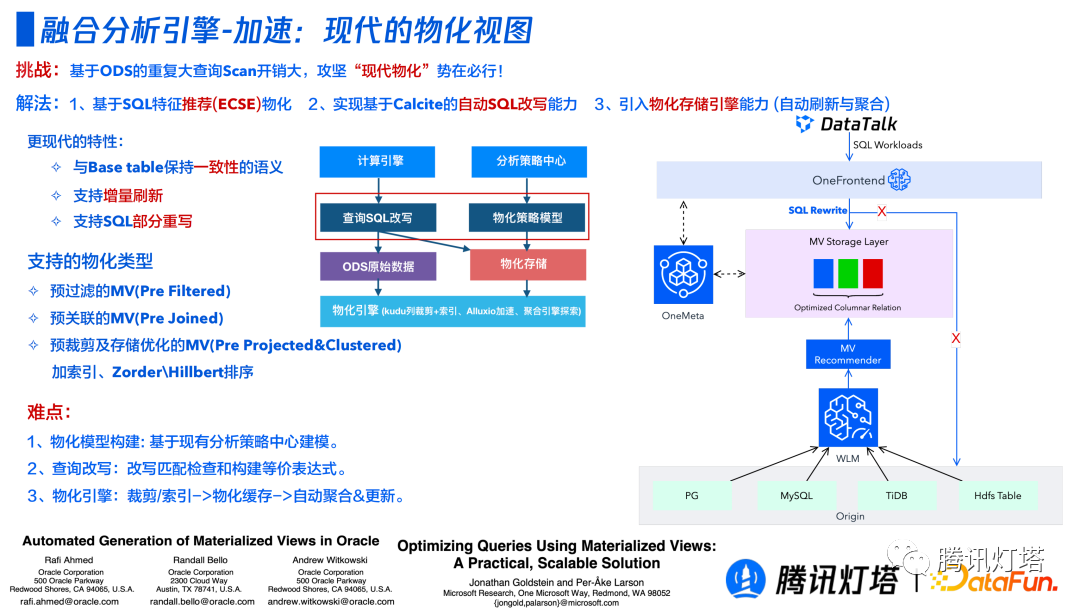
③ 现代的物化视图
如何更高效利用好物化视图面临着三个问题:如何达到用最少成本达到最高性能;如何低成本维护好物化视图;查询时,在不改变查询语句的前提下如何将查询路由到不同的物化视图? 现代物化视图就是在致力于解决上述三个问题。
- 如何达到用最少成本达到最高性能? 一般方案是做一些领域专家模型。但是对于这样一个平台化的产品是无法做到这一点的, 因为业务方才是最了解业务的。所以该产品可以依赖端到端的负载中心去历史查询记录来找到最大的公共子查询来自动的实现物化视图。同时,还会做一些其他的优化,比如添加相应的索引或者 Zorder\hillbert 排序。
- 如何低成本维护好物化视图? 增量刷新物化视图,并通过负载中心来分析历史查询物化视图是否起到加速的效果,删除加速效果较差的物化视图。
- 查询时,在不改变查询语句的前提下如何将查询路由到不同的物化视图? 通过基于 Calcite 的自动改写功能,用户不需要修改原有的 SQL 语句,SQL 会透明地路由到不同的物化视图。
三
实践总结
灯塔融合分析引擎,在 SQL、计算和存储三个技术领域,做了很多的技术创新和沉淀。下图列出了重要的优化点。

四
未来演进方向
我们未来将继续致力于从融合、内核优化和加速三个方向,解决“以卓越性能直接访问数据”的问题。

冯国敬
腾讯 后台开发工程师
2013年毕业于哈尔滨工业大学,一直从事大数据领域研发工作,目前在腾讯灯塔负责融合分析引擎的研发。


让数据驱动为企业增长决策指引方向

灯塔是腾讯大数据平台倾力打造的“一站式敏捷分析”平台,借助大数据套件及各类型原子能力,为企业发展和增长提供:从“数据上报、接入,到自定义万亿级实时数据分析,再到数据行动、数据可视化”的全链路数据解决方案。
官网地址:beacon.qq.com
(建议PC端登录)

长按识别进入用户群|掌握最新资讯
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-02-16,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号