深入拆解RedAmon:AI驱动自动化红队框架架构解析

深入拆解RedAmon:AI驱动自动化红队框架架构解析

Ms08067安全实验室
发布于 2026-06-24 12:07:16
发布于 2026-06-24 12:07:16
文章来源|MS08067 AI安全应用知识星球
作者:小玉玉
RedAmon 是一个基于 AI 的自动化红队框架,它将传统渗透测试工具与现代 AI 编排技术深度融合,实现了从侦察、利用到后渗透的端到端自动化攻击链。项目采用创新的 ReAct 架构模式,通过 Fireteam 并行专家子智能体协调攻击任务,利用 Neo4j 图数据库驱动攻击面智能分析,支持 500+ 项目配置参数、400+ AI 模型、185,000+ 检测规则和多 LLM 提供商,代表了 AI 驱动安全测试领域的先进工程实践水平。
在网络安全领域,红队演练(Red Team Exercise)是检验组织安全防护能力的重要手段。传统红队行动主要依赖经验丰富的安全专家,他们需要手工执行数十种工具,分析海量的扫描结果,制定复杂的攻击策略——这个过程既耗时又容易出错。随着 AI 技术的快速发展,一个自然的问题是:能否让 AI 智能体替代人类专家,实现自动化、智能化的渗透测试?
RedAmon 项目给出了肯定的答案。本文将从系统架构、核心技术拆解、差异化能力三个维度,全面解析 RedAmon 的技术实现,带你深入了解 AI 如何改变传统安全测试的工作方式。无论你是安全从业初学者,还是有经验的研究者,都能从中获得有价值的启发。
系统架构与核心设计
RedAmon 的核心理念是用 AI 智能体替代传统手工渗透测试流程,通过自动化编排实现攻击链的全流程智能化。对于初学者来说,可以理解为一个"智能渗透测试机器人"——它像经验丰富的安全专家一样思考,但不知疲倦地执行各种测试任务。
其整体架构采用容器化微服务 + 图数据库驱动 + AI 智能体编排的三层设计。这种架构听起来很复杂,但可以想象成一个现代化的工厂:底层是各种专业工具(传统红队工具如 Nmap、Metasploit、Nuclei 等),中间层是智能调度系统(LangGraph 驱动的 Agent 系统),顶层是统一的管理界面。系统将这些工具封装为 MCP(Model Context Protocol)标准接口,让 AI 能够像人类安全专家一样自主决策调用,实现"侦察 → 利用 → 后渗透 → 修复"的完整闭环。
系统分层架构
要理解 RedAmon 的复杂架构,我们可以将其类比为一个现代化的军事情报系统:最上层是指挥中心(编排层),中间是各种专业情报队伍(工具层),底层是庞大的情报数据库(数据层),而前端界面则是与指挥官交互的控制台。
以下是 RedAmon 的具体分层设计:
层级 | 职责 | 生命周期 |
|---|---|---|
编排层 | Root Agent 决策、Fireteam 并行协调、Phase 管理 | 持续运行 |
工具层 | 40+ 安全工具的 MCP 封装、Kali 沙箱执行 | 按需启动 |
数据层 | Neo4j 攻击面图、PostgreSQL 配置存储 | 持久化存储 |
交互层 | Next.js Web UI、实时聊天、工作空间管理 | 会话级别 |
基础设施 | Docker 容器化、网络隔离、文件系统共享 | 长期运行 |
图1:RedAmon 项目创建界面
图1:RedAmon 项目创建界面
核心数据模型
在深入了解 RedAmon 的数据模型之前,我们需要理解什么是图数据库。传统的关系数据库(如 MySQL)用表格存储数据,适合处理结构化的事务;而图数据库(如 Neo4j)用节点和关系存储数据,特别适合处理复杂的关联查询——这正是攻击面分析所需要的。
想象一下,你要分析一个目标系统的攻击路径:哪些域名解析到哪些 IP?哪些 IP 运行着哪些服务?哪些服务存在哪些漏洞?这些漏洞能让你访问到哪些其他系统?用传统数据库需要多次关联查询,而用图数据库一次查询就能找到完整的攻击链。
RedAmon 使用 Neo4j 图数据库来构建攻击面知识图谱,以下是它的核心约束定义:
// 文件位置: graph_db/schema.py
// RedAmon Neo4j 图数据库核心约束定义(租户隔离的多租户架构)
// 域名唯一性约束(租户隔离:同一域名可在不同项目中存在)
CREATE CONSTRAINT domain_unique IF NOT EXISTS FOR (d:Domain) REQUIRE (d.name, d.user_id, d.project_id) IS UNIQUE;
// 子域名唯一性约束
CREATE CONSTRAINT subdomain_unique IF NOT EXISTS FOR (s:Subdomain) REQUIRE (s.name, s.user_id, s.project_id) IS UNIQUE;
// IP 地址唯一性约束
CREATE CONSTRAINT ip_unique IF NOT EXISTS FOR (i:IP) REQUIRE (i.address, i.user_id, i.project_id) IS UNIQUE;
// 端口唯一性约束(同一 IP 的同一端口在不同租户间可重复)
CREATE CONSTRAINT port_unique IF NOT EXISTS FOR (p:Port) REQUIRE (p.number, p.protocol, p.ip_address, p.user_id, p.project_id) IS UNIQUE;
// 服务唯一性约束
CREATE CONSTRAINT service_unique IF NOT EXISTS FOR (svc:Service) REQUIRE (svc.name, svc.port_number, svc.ip_address, svc.user_id, svc.project_id) IS UNIQUE;
// 端点唯一性约束(用于 Web 应用攻击面映射)
CREATE CONSTRAINT endpoint_unique IF NOT EXISTS FOR (e:Endpoint) REQUIRE (e.path, e.method, e.baseurl, e.user_id, e.project_id) IS UNIQUE;
// 漏洞唯一性约束
CREATE CONSTRAINT vulnerability_unique IF NOT EXISTS FOR (v:Vulnerability) REQUIRE v.id IS UNIQUE;
// CVE 唯一性约束(全局共享参考数据)
CREATE CONSTRAINT cve_unique IF NOT EXISTS FOR (c:CVE) REQUIRE c.id IS UNIQUE;
// 漏洞节点与关系
MERGE (v:Vulnerability {
cve: $cve_id,
severity: $severity,
cvss: $cvss_score,
description: $description
})
MERGE (srv)-[:HAS_VULNERABILITY]->(v);
// 端点节点(AI 接口)
MERGE (ep:Endpoint {
path: $endpoint_path,
method: $http_method,
ai_interface_type: $ai_type, // REST / GraphQL / WebSocket
auth_required: $needs_auth
})
MERGE (srv)-[:EXPOSES_ENDPOINT]->(ep);
// 凭据节点与关系
MERGE (cred:Credential {
username: $user,
hash_type: $hash_type,
crack_time: $time_to_crack
})
MERGE (h)-[:HAS_CREDENTIAL]->(cred);
// 攻击链关系
MERGE (a1:Asset {name: $asset1})
MERGE (a2:Asset {name: $asset2})
MERGE (a1)-[:CAN_COMPROMISE {technique: $mitre_technique, difficulty: $diff_level}]->(a2);
// 元数据标注
MERGE (t:Tag {name: $tag_name, category: $tag_category})
MERGE (v)-[:TAGGED_WITH]->(t);
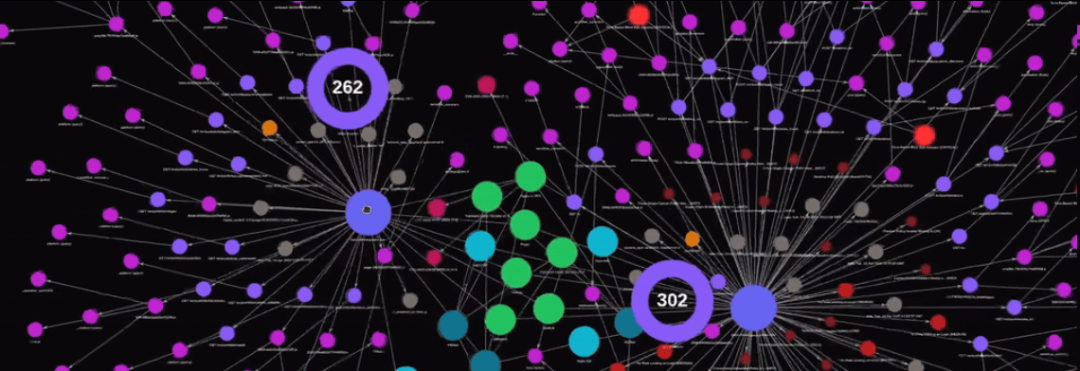
图2:RedAmon 攻击面动态关系图展示
上图展示了 RedAmon 如何将分散的攻击数据转化为可视化的关系网络。你可以看到,不同的节点(域名、IP、端口、漏洞)通过线条(关系)连接在一起,形成了完整的攻击面地图。这种可视化让安全测试人员能够一目了然地看到攻击路径和风险点。
对于初学者来说,理解这种图数据模型可能有些抽象。让我们用一个实际例子来说明:假设你要攻击 example.com 域名,传统工具会分别告诉你子域名列表、IP 地址列表、开放端口列表,但你需要手工整理它们之间的关联。而 RedAmon 的图数据库会自动建立这些关联,你一眼就能看到 www.example.com 解析到 192.168.1.100,这个 IP 的 80 端口运行着 Apache 2.4.41,存在 CVE-2019-0211 漏洞,利用这个漏洞可能让你访问到内网的数据库服务器。
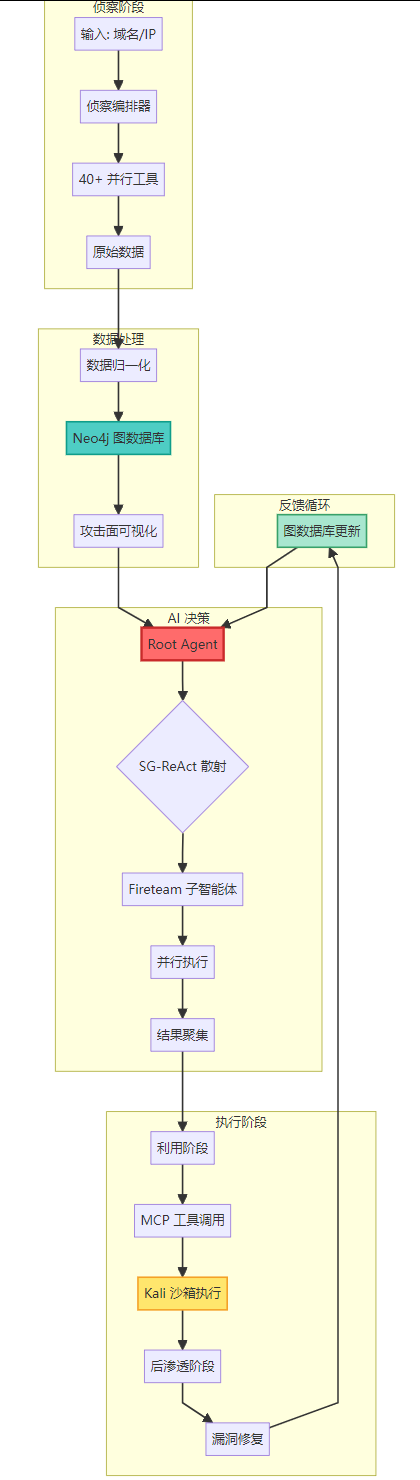
以下是 RedAmon 端到端自动化攻击链的流程图:
graph TB
subgraph "侦察阶段"
A[输入: 域名/IP] --> B[侦察编排器]
B --> C[40+ 并行工具]
C --> D[原始数据]
end
subgraph "数据处理"
D --> E[数据归一化]
E --> F[Neo4j 图数据库]
F --> G[攻击面可视化]
end
subgraph "AI 决策"
G --> H[Root Agent]
H --> I{SG-ReAct 散射}
I --> J[Fireteam 子智能体]
J --> K[并行执行]
K --> L[结果聚集]
end
subgraph "执行阶段"
L --> M[利用阶段]
M --> N[MCP 工具调用]
N --> O[Kali 沙箱执行]
O --> P[后渗透阶段]
P --> Q[漏洞修复]
end
subgraph "反馈循环"
Q --> R[图数据库更新]
R --> H
end
style H fill:#ff6b6b,stroke:#c92a2a,stroke-width:3px
style F fill:#4ecdc4,stroke:#0f9d8a,stroke-width:2px
style O fill:#ffe66d,stroke:#f4a127,stroke-width:2px
style R fill:#a8e6cf,stroke:#38a169,stroke-width:2px
架构高度抽象让我们看到了整体轮廓,但要真正理解 RedAmon 如何实现"AI 替代人工"的愿景,还需深入工程底层,逐一拆解支撑这套模型的七项关键技术面。
核心技术与工程架构
一、技术栈全景
在深入具体技术细节之前,我们先全面了解 RedAmon 的技术栈。对于初学者来说,这部分可能包含很多陌生的技术名词,但不用担心——我们会逐一解释它们的作用和意义。
RedAmon 的技术选型体现了安全工具容器化 + AI 编排现代化的双重追求,既保留了传统渗透测试工具的威力,又引入了最新的 AI 框架和前端技术。可以想象一下,这就像是把传统的手工工具(螺丝刀、扳手)升级为电动化、智能化的现代工具生产线。
以下是 RedAmon 完整的技术栈:
层级 | 技术方案 | 选型理由 |
|---|---|---|
AI 编排 | LangGraph + LangChain | 提供 Agent 状态管理、ReAct 循环、检查点持久化的原生支持 |
Web 框架 | FastAPI(Agent API) + Next.js(Webapp) | 高性能异步 API + React SSR,类型安全,现代化 UI |
关系数据库 | PostgreSQL 16 | 存储用户配置、项目设置、Agent 检查点等结构化数据 |
图数据库 | Neo4j 5.26 + APOC 插件 | 原生图查询、攻击路径推演、Cypher 语言表达力强 |
前端框架 | Next.js 14+ + TypeScript + Tailwind CSS | React SSR、类型安全、现代化 UI、暗色主题支持 |
容器化 | Docker + Docker Compose | 微服务解耦、环境一致性、一键部署、网络隔离 |
LLM 提供商 | OpenAI(GPT-4) / Anthropic(Claude) / OpenRouter(400+ 模型) | 多模型支持、成本优化、本地模型(Ollama/vLLM)兼容 |
工具集成 | FastMCP(Model Context Protocol) | 工具标准化、跨语言互操作、可扩展性强、SSE 传输 |
安全工具 | 100+ 工具(Nmap、Nuclei、Metasploit、Hydra、sqlmap) | 覆盖侦察、漏洞扫描、利用、后渗透全流程 |
知识库 | NVD + ExploitDB + Nuclei + GTFOBins + LOLBAS | 185,000+ 检测规则、CVE 数据、利用数据库 |
多租户 | Tenant-scoped 约束 + 复合索引 | 支持多用户并发、项目隔离、数据安全 |
有了这些技术作为底座,RedAmon 得以构建其最核心的竞争力——ReAct 智能体编排系统 + Fireteam 并行专家系统。不同于市面上传统自动化工具(如 Autosploit、Sparta)的静态脚本化做法,RedAmon 选择了一条更工程化的路径:用 LangGraph 构建可中断恢复的状态机、用 FastMCP 标准化 100+ 安全工具接口、用 Neo4j 图数据库记忆全局攻击面、用 PostgreSQL 持久化检查点实现长期运行。
二、SG-ReAct 智能体编排
SG-ReAct(Scatter-Gather ReAct)是 RedAmon 的核心架构创新,也是理解整个系统的关键。在深入代码之前,我们先理解这个概念。
ReAct 模式是 AI 领域的一种重要推理模式,代表"推理-行动"(Reasoning + Acting)的循环。想象一个经验丰富的渗透测试专家在工作中会如何思考:首先观察当前情况(比如发现一个开放端口),然后思考下一步该做什么(比如检查该端口是否存在漏洞),接着采取行动(运行漏洞扫描工具),最后根据结果继续下一步。这就是 ReAct 循环。
RedAmon 将这种模式扩展为散射-聚集模式:
- Root Agent(根智能体)负责全局决策和协调
- 散射(Scatter):将复杂任务分解为多个子任务,分发给专家智能体
- 聚集(Gather):收集各专家的结果,更新全局状态
- 循环迭代:不断重复这个过程,直到达成目标
这种架构的优势在于:既有统一的战略规划(Root Agent),又有专业的具体执行(专家子智能体),就像一个高效的军事指挥系统。
以下是 SG-ReAct 编排器的核心实现代码:
# 文件位置: agentic/orchestrator.py
# RedAmon Agent Orchestrator - ReAct 风格编排器实现
from langchain_core.language_models import BaseChatModel
from langchain_core.messages import AIMessage, HumanMessage
from langgraph.graph import StateGraph, START, END
from langgraph.checkpoint.memory import MemorySaver
from state import AgentState, InvokeResponse
from tools import MCPToolsManager, Neo4jToolManager, PhaseAwareToolExecutor
class AgentOrchestrator:
"""
ReAct 风格智能体编排器 - 渗透测试核心引擎
实现 Thought-Tool-Output 模式,支持:
- 阶段跟踪(Informational → Exploitation → Post-Exploitation)
- LLM 管理的待办事项列表
- 基于检查点的阶段转换审批
- 完整执行追踪(内存中)
"""
def __init__(self):
"""初始化编排器及配置"""
# 基础设施环境变量(保持在 docker-compose 中)
self.neo4j_uri = os.getenv("NEO4J_URI", "bolt://localhost:7687")
self.neo4j_user = os.getenv("NEO4J_USER", "neo4j")
self.neo4j_password = os.getenv("NEO4J_PASSWORD")
# 模型和工具管理
self.model_name: Optional[str] = None
self.llm: Optional[BaseChatModel] = None
self.tool_executor: Optional[PhaseAwareToolExecutor] = None
self.neo4j_manager: Optional[Neo4jToolManager] = None
self.graph = None
# 会话管理(支持多用户并发)
self._streaming_callbacks: dict[str, object] = {}
self._guidance_queues: dict[str, asyncio.Queue] = {}
asyncdef initialize(self):
"""异步初始化 - 设置 LLM 和工具执行器"""
if self._initialized:
return
# 设置 LLM 客户端(根据项目设置配置)
self.llm = await setup_llm()
# 初始化工具管理器
self.neo4j_manager = Neo4jToolManager(
self.neo4j_uri, self.neo4j_user, self.neo4j_password
)
mcp_manager = MCPToolsManager() # MCP 工具服务器管理
self.tool_executor = PhaseAwareToolExecutor(
self.neo4j_manager, mcp_manager
)
# 构建 LangGraph 状态机
self.graph = self._build_graph()
self._initialized = True
def _build_graph(self) -> StateGraph:
"""构建 LangGraph 状态机 - 定义节点和边"""
workflow = StateGraph(AgentState)
# 添加核心节点
workflow.add_node("initialize", initialize_node)
workflow.add_node("think", think_node)
workflow.add_node("execute_tool", execute_tool_node)
workflow.add_node("fireteam_deploy", fireteam_deploy_node)
workflow.add_node("fireteam_collect", fireteam_collect_node)
workflow.add_node("await_approval", await_approval_node)
workflow.add_node("generate_response", generate_response_node)
# 定义状态流转
workflow.set_entry_point("initialize")
workflow.add_edge("initialize", "think")
workflow.add_conditional_edges(
"think",
should_deploy_fireteam,
{
"execute": "execute_tool",
"deploy": "fireteam_deploy",
"end": END
}
)
workflow.add_edge("execute_tool", "think")
workflow.add_edge("fireteam_deploy", "fireteam_collect")
workflow.add_edge("fireteam_collect", "think")
# 编译状态机(带检查点支持)
return workflow.compile(checkpointer=checkpointer)
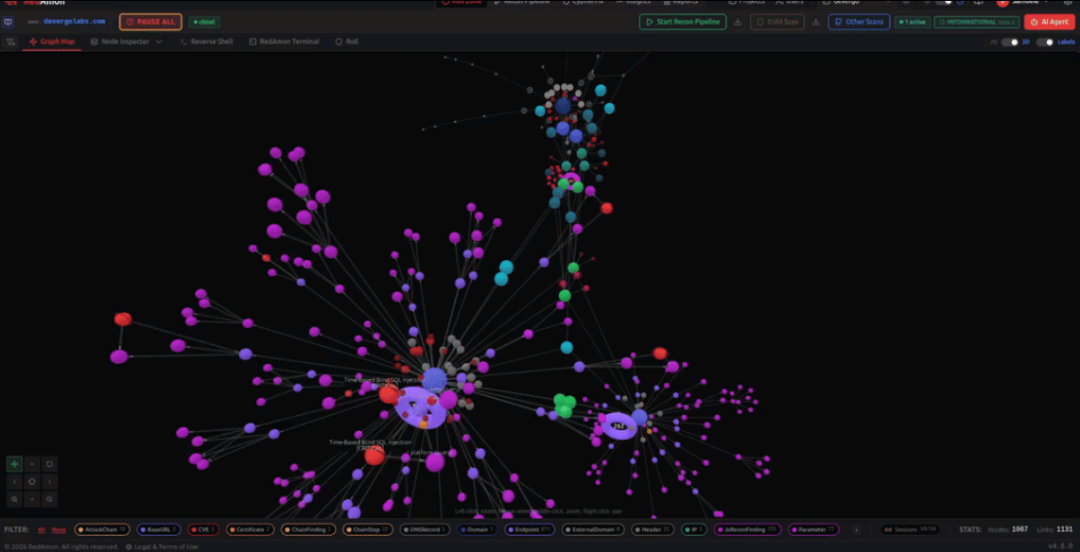
图3:RedAmon Agent 代理运行界面
三、Fireteam 专家子智能体系统
Agent 再强大也无法凭空执行操作。它们需要一套**"双手"**来触碰目标系统——这正是 Fireteam 专家子智能体体系的价值所在。
Fireteam(消防队)这个名字来源于军事术语,指代一组协同工作的专业人员。在 RedAmon 中,Fireteam 代表了一个专家协作系统,将红队技能拆解为 6 个专家角色,每个专家专注特定领域。这种分工协作的模式类似于真实红队团队的组织结构:有人负责信息收集,有人负责漏洞利用,有人负责后渗透,有人负责报告编写。
为什么要采用这种专家分工模式?因为现代渗透测试涉及的技术领域非常广泛,一个通用的 AI 很难在所有领域都达到专家水平。通过角色分工,每个子智能体只需要精通自己领域的知识和技能,既能提高专业性,又能简化决策逻辑。
以下是 RedAmon 的 6 大专家子智能体:
网络侦察专家:负责发现目标网络中的所有资产,包括端口扫描、服务识别、操作系统指纹识别等。
Web 应用专家:专注于 Web 应用安全,包括漏洞扫描、目录枚举、参数模糊测试等。
凭据破解专家:负责获取目标系统的访问凭据,包括暴力破解、哈希破解、默认凭据测试等。
漏洞利用专家:专注于漏洞利用技术,包括 Exploit 选择、利用执行、Shell 获取等。
后渗透专家:在获取初步访问权限后进行深入渗透,包括权限提升、凭据收集、持久化等。
报告生成专家:负责汇总所有发现,生成专业的渗透测试报告。
以下是 Fireteam 专家子智能体系统的实现代码:
# 文件位置: agentic/fireteam.py
# Fireteam 专家子智能体定义
from typing import List, Dict, Callable
from enum import Enum
class SpecialistType(Enum):
"""专家类型枚举"""
NETWORK_AGENT = "network_agent" # 网络侦察专家
WEB_AGENT = "web_agent" # Web 应用专家
CREDENTIAL_AGENT = "credential_agent" # 凭据破解专家
EXPLOITATION_AGENT = "exploitation_agent"# 漏洞利用专家
POST_EXPLOIT_AGENT = "post_exploit_agent"# 后渗透专家
REPORTING_AGENT = "reporting_agent" # 报告生成专家
class SpecialistAgent:
"""专家子智能体基类"""
def __init__(self, specialist_type: SpecialistType, llm_provider, tool_registry):
self.type = specialist_type
self.llm = llm_provider
self.tools = tool_registry.get_tools_for_specialist(specialist_type)
self.system_prompt = self._build_system_prompt()
def _build_system_prompt(self) -> str:
"""构建专家专属系统提示词"""
prompts = {
SpecialistType.NETWORK_AGENT: """
你是网络侦察专家。你的职责:
1. 扫描目标网络段,发现所有活跃主机
2. 识别开放端口和运行服务
3. 检测服务版本和潜在漏洞
4. 绘制网络拓扑图
你可以使用的工具:
- nmap_scan: 端口扫描和服务识别
- masscan: 快速大范围端口发现
- nuclei_scan: 基于 Nuclei 模板的漏洞扫描
- subfinder_discover: 子域名发现
工作原则:
- 先做快速扫描(masscan),再做精细扫描(nmap)
- 优先关注高危端口(21, 22, 80, 443, 3306, 3389, 5432, 8080)
- 将发现的所有资产结构化记录
""",
SpecialistType.WEB_AGENT: """
你是 Web 应用安全专家。你的职责:
1. 爬取和枚举 Web 应用端点
2. 检测常见 Web 漏洞(SQL 注入、XSS、RCE 等)
3. 分析认证和授权机制
4. 测试 GraphQL 端点安全
你可以使用的工具:
- katana_crawl: Web 爬虫
- nuclei_http: HTTP 漏洞扫描
- graphql_audit: GraphQL 安全测试
- ffuf_fuzz: 目录和参数模糊测试
工作原则:
- 优先测试登录页面、文件上传、API 端点
- 注意 GraphQL 端点的 introspection 暴露
- 记录所有发现的敏感端点和漏洞
""",
SpecialistType.CREDENTIAL_AGENT: """
你是凭据破解专家。你的职责:
1. 收集目标系统的用户名和哈希
2. 使用字典和规则进行密码破解
3. 尝试常见默认凭据
4. 利用凭据进行横向移动
你可以使用的工具:
- hydra_crack: 多协议暴力破解
- hashcat_crack: 哈希破解
- ssh_login: SSH 登录测试
- smb_login: SMB 认证测试
工作原则:
- 优先尝试常见默认凭据(admin:admin, root:123456)
- 使用行业专用密码字典(如 IoT 设备)
- 破解成功后立即验证可用性
- 记录破解时间和破解难度
""",
SpecialistType.EXPLOITATION_AGENT: """
你是漏洞利用专家。你的职责:
1. 分析漏洞可利用性
2. 选择合适的 Exploit 模块
3. 执行漏洞利用并获取 Shell
4. 验证利用成功并建立持久化
你可以使用的工具:
- metasploit_exploit: Metasploit 框架利用
- searchsploit: 搜索公开 Exploit
- exploitdb_poc: Exploit-DB POC 执行
- sqlmap_inject: SQL 注入利用
工作原则:
- 优先选择 Metasploit 成熟模块
- 利用前先验证漏洞存在性
- 注意利用失败时的清理工作
- 获取 Shell 后立即建立持久化
""",
SpecialistType.POST_EXPLOIT_AGENT: """
你是后渗透专家。你的职责:
1. 在已攻陷主机上收集信息
2. 提升权限到 SYSTEM/root
3. 收集敏感数据和凭据
4. 建立持久化后门
你可以使用的工具:
- linpeas_enum: Linux 枚举脚本
- winpeas_enum: Windows 枚举脚本
- mimikatz_dump: 凭据转储
- bloodhound_audit: BloodHound 分析
工作原则:
- 先做信息收集再做提权
- 优先寻找内核漏洞和配置错误
- 收集所有哈希和票据
- 建立隐蔽的持久化机制
""",
SpecialistType.REPORTING_AGENT: """
你是报告生成专家。你的职责:
1. 汇总所有发现资产和漏洞
2. 按严重性排序漏洞
3. 生成修复建议
4. 生成专业渗透测试报告
你可以使用的工具:
- graph_query_attack_chain: 查询攻击链
- vuln_priority_sort: 漏洞优先级排序
- report_generate_markdown: 生成 Markdown 报告
- cypherfix_create_pr: 创建修复 PR
工作原则:
- 漏洞按 CVSS 评分排序
- 攻击链按 MITRE ATT&CK 映射
- 修复建议要具体可执行
- 报告要符合行业标准(PTES、OSSTMM)
"""
}
return prompts.get(self.type, "你是一个渗透测试专家。")
asyncdef execute(self, task: Dict) -> Dict:
"""执行专家任务"""
prompt = f"""
{self.system_prompt}
当前任务:{task['objective']}
目标上下文:{task['context']}
请制定执行计划并执行工具调用。输出 JSON 格式结果。
"""
# 使用 LLM 生成工具调用序列
tool_calls = await self.llm.generate_with_tools(
prompt=prompt,
tools=self.tools
)
# 执行工具调用
results = []
for call in tool_calls:
tool_result = await call['tool'].execute(**call['parameters'])
results.append({
"tool": call['tool'].name,
"result": tool_result
})
return {
"specialist": self.type.value,
"task": task['objective'],
"results": results
}
class FireteamManager:
"""Fireteam 管理器"""
def __init__(self, llm_provider, tool_registry):
self.specialists = {}
for specialist_type in SpecialistType:
self.specialists[specialist_type] = SpecialistAgent(
specialist_type,
llm_provider,
tool_registry
)
def get_specialist(self, specialist_type: SpecialistType) -> SpecialistAgent:
"""获取指定专家"""
return self.specialists.get(specialist_type)
asyncdef execute_parallel(self, allocations: Dict[SpecialistType, List[Dict]]) -> List[Dict]:
"""并行执行多个专家任务"""
tasks = []
for specialist_type, task_list in allocations.items():
specialist = self.get_specialist(specialist_type)
for task in task_list:
tasks.append(specialist.execute(task))
returnawait asyncio.gather(*tasks)
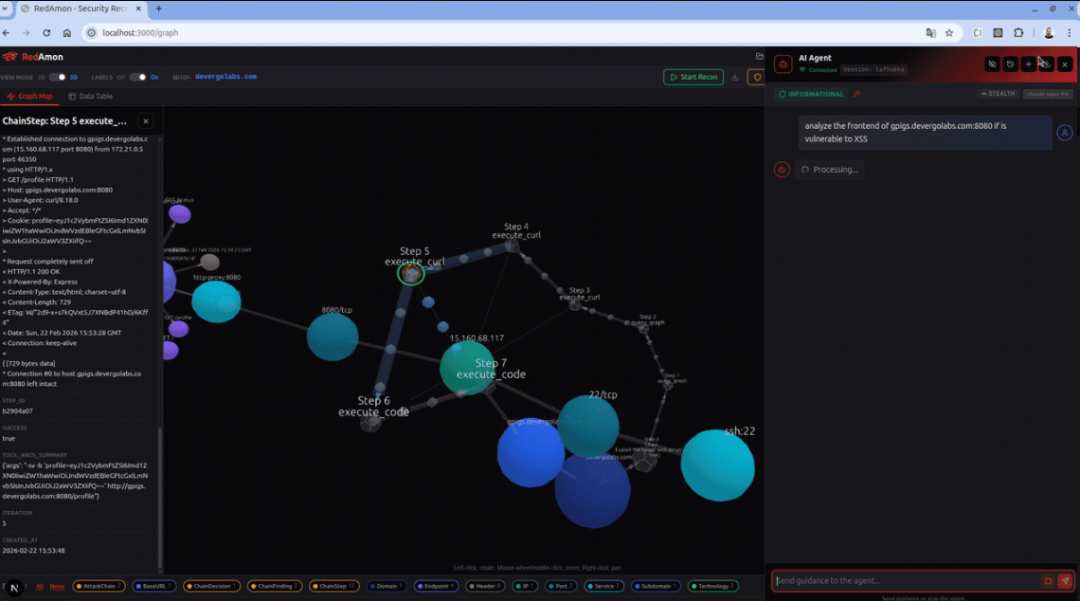
图4:RedAmon 漏洞利用过程界面
四、MCP 工具编排与 Kali 沙箱
工具调用让 Agent 能够"动手",但一个更深层的问题随之而来:渗透测试往往需要执行 70+ 种 CLI 工具,如何保证它们的安全隔离、环境一致性和结果可追踪性?
这里我们需要理解几个关键技术概念:
MCP(Model Context Protocol):这是一种标准化的工具调用协议,可以理解为 AI 智能体和外部工具之间的"通用语言"。就像 USB 接口标准化了电脑和外设的连接一样,MCP 标准化了 AI 和工具的交互。
Kali Linux:这是专为渗透测试设计的 Linux 发行版,预装了 300+ 安全工具。传统方式下,安全测试人员需要在 Kali 系统上手工运行各种工具。
Docker 容器化:这是一种轻量级的虚拟化技术,可以将应用程序及其依赖环境打包在一起。对于渗透测试来说,容器化提供了重要的安全隔离——即使工具被恶意利用,也不会影响宿主系统。
RedAmon 的解决方案是:将所有工具封装为 MCP 服务器,在 Kali Docker 容器中统一执行。这种设计带来了三大优势:
- 安全隔离:所有危险操作都在隔离的容器中执行
- 环境一致:每次测试都在相同的环境中运行,结果可重复
- 统一管理:通过 MCP 协议,AI 可以统一调用各种工具
以下是 Nmap MCP 工具服务器的实现代码:
# 文件位置: mcp/servers/nmap_server.py
# Nmap MCP 工具服务器 - FastMCP 实现
from fastmcp import FastMCP
import subprocess
import shlex
import re
import os
# 去除 ANSI 转义码(终端颜色)的正则表达式
ANSI_ESCAPE = re.compile(r'\x1b\[[0-9;]*[a-zA-Z]')
# 服务器配置
SERVER_NAME = "nmap"
SERVER_HOST = os.getenv("MCP_HOST", "0.0.0.0")
SERVER_PORT = int(os.getenv("NMAP_PORT", "8004"))
mcp = FastMCP(SERVER_NAME)
@mcp.tool()
def execute_nmap(args: str) -> str:
"""
执行 nmap 网络扫描器(支持任意有效 CLI 参数)
Nmap 是标准的网络发现和安全审计工具。
用于服务版本检测、操作系统指纹识别和 NSE 脚本执行。
参数:
args: nmap 的命令行参数(不包含 'nmap' 命令本身)
返回:
命令输出(stdout + stderr 合并)
示例:
服务版本检测:
- "-sV 10.0.0.5 -p 80,443"
激进扫描(版本 + OS + 脚本 + 路由跟踪):
- "-A 10.0.0.5 -p 22,80"
默认脚本 + 版本检测:
- "-sV -sC 10.0.0.5 -p 80,443,8080"
使用 NSE 进行漏洞扫描:
- "-sV --script vuln 10.0.0.5"
操作系统指纹识别:
- "-O 10.0.0.5"
特定 NSE 脚本:
- "--script http-enum 10.0.0.5 -p 80"
UDP 扫描:
- "-sU 10.0.0.5 --top-ports 20"
"""
try:
cmd_args = shlex.split(args)
result = subprocess.run(
["nmap"] + cmd_args,
capture_output=True,
text=True,
timeout=600
)
# 去除 ANSI 转义码
output = ANSI_ESCAPE.sub('', result.stdout)
if result.stderr:
clean_stderr = ANSI_ESCAPE.sub('', result.stderr)
if clean_stderr.strip():
output += f"\n[STDERR]: {clean_stderr}"
return output if output.strip() else"[INFO] No results returned"
except subprocess.TimeoutExpired:
return"[ERROR] 命令超时(600秒)。考虑减少扫描端口或使用 --host-timeout。"
except FileNotFoundError:
return"[ERROR] nmap 命令未找到。请确保在 Kali 沙箱环境中运行。"
except Exception as e:
returnf"[ERROR] 执行失败: {str(e)}"
graph LR
subgraph "Agent 层"
A[Root Agent]
B[Network Specialist]
C[Web Specialist]
end
subgraph "MCP 工具层"
D[Nmap Server]
E[Nuclei Server]
F[Metasploit Server]
G[Hydra Server]
end
subgraph "Kali 沙箱"
H[/workspace 目录]
I[工具执行环境]
J[结果输出]
end
A --> B
A --> C
B --> D
B --> E
C --> F
C --> G
D --> H
E --> H
F --> H
G --> H
H --> I
I --> J
J --> D
J --> E
J --> F
J --> G
style A fill:#ff6b6b,stroke:#c92a2a,stroke-width:3px
style H fill:#ffe66d,stroke:#f4a127,stroke-width:2px
style D fill:#4ecdc4,stroke:#0f9d8a,stroke-width:2px
style E fill:#4ecdc4,stroke:#0f9d8a,stroke-width:2px
style F fill:#4ecdc4,stroke:#0f9d8a,stroke-width:2px
style G fill:#4ecdc4,stroke:#0f9d8a,stroke-width:2px

五、Neo4j 图数据库驱动的攻击面管理
工具调用让 Agent 能够"动手",但一个更深层的问题随之而来:渗透测试往往持续数小时甚至数天,Agent 如何在长时间的任务执行中保持持续认知?
想象一下人类渗透测试专家是如何工作的:他们会做笔记,画思维导图,记录已发现的资产、已尝试的攻击路径、已获取的凭据等。这些"记忆"让专家能够在长时间的工作中保持策略的连贯性。传统自动化工具使用临时变量或文件存储状态,一旦中断就前功尽弃。
RedAmon 的解决方案是:将所有攻击面数据持久化到 Neo4j 图数据库,使 Agent 能够"记忆"已发现的资产、已攻陷的主机和未完成的攻击路径。
为什么选择图数据库而不是传统关系数据库?
这就涉及到图数据库的核心优势。假设你发现了一个 SSH 弱口令漏洞,想要知道利用这个漏洞能访问到哪些高价值目标。用传统 SQL 数据库,你需要执行多次复杂的 JOIN 查询;而用图数据库,只需要一次图遍历查询,就能找到完整的攻击链。
具体来说,RedAmon 的图数据库支持以下强大功能:
攻击链推演:自动发现从外部可达目标的攻击路径资产关联分析:识别看似无关资产之间的隐藏关系横向移动规划:基于已获取凭据计算下一步最优目标漏洞影响评估:分析一个漏洞可能影响的所有资产
以下是 Neo4j 图数据库操作接口的实现代码:
# 文件位置: graph_db/neo4j_interface.py
# Neo4j 图数据库操作接口
from neo4j import AsyncGraphDatabase
from typing import Dict, List, Optional
class Neo4jInterface:
"""Neo4j 图数据库操作接口"""
def __init__(self, uri: str, user: str, password: str):
self.driver = AsyncGraphDatabase.driver(uri, auth=(user, password))
asyncdef close(self):
"""关闭数据库连接"""
await self.driver.close()
asyncdef insert_recon_data(self, data: Dict) -> None:
"""
插入侦察数据到图数据库
参数说明:
- data: 侦察结果,包含子域名、主机、端口、服务等信息
"""
asyncwith self.driver.session() as session:
# 处理域名和子域名
for subdomain in data.get('subdomains', []):
await session.run("""
MERGE (d:Domain {name: $domain})
MERGE (s:Subdomain {name: $subdomain})
MERGE (s)-[:BELONGS_TO]->(d)
""",
domain=data['target'],
subdomain=subdomain
)
# 处理主机和端口
for host in data.get('hosts', []):
await session.run("""
MERGE (h:Host {ip: $ip})
SET h.os = $os, h.mac = $mac
""",
ip=host['ip'],
os=host.get('os'),
mac=host.get('mac')
)
for port in host.get('ports', []):
await session.run("""
MERGE (h:Host {ip: $ip})
MERGE (p:Port {number: $port, protocol: $protocol})
MERGE (h)-[:HAS_OPEN_PORT]->(p)
SET p.status = $status, p.service = $service
""",
ip=host['ip'],
port=port['port'],
protocol=port.get('protocol', 'tcp'),
status=port.get('status', 'open'),
service=port.get('service')
)
# 处理漏洞
for vuln in data.get('vulnerabilities', []):
await session.run("""
MERGE (v:Vulnerability {cve: $cve})
SET v.severity = $severity, v.cvss = $cvss,
v.description = $description, v.references = $refs
""",
cve=vuln.get('cve'),
severity=vuln.get('severity'),
cvss=vuln.get('cvss'),
description=vuln.get('description'),
refs=vuln.get('references', [])
)
asyncdef query_attack_surface(self, target: str) -> Dict:
"""
查询目标的完整攻击面
返回值:
- 攻击面图的结构化快照
"""
asyncwith self.driver.session() as session:
# 查询所有子域名
subdomains_result = await session.run("""
MATCH (d:Domain {name: $domain})<-[:BELONGS_TO]-(s:Subdomain)
RETURN s.name as subdomain
""",
domain=target
)
subdomains = [record['subdomain'] asyncfor record in subdomains_result]
# 查询所有主机和端口
hosts_result = await session.run("""
MATCH (h:Host)<-[:RESOLVES_TO]-(:Subdomain)-[:BELONGS_TO]->(:Domain {name: $domain})
OPTIONAL MATCH (h)-[:HAS_OPEN_PORT]->(p:Port)
RETURN h.ip as ip, h.os as os,
collect({port: p.number, protocol: p.protocol, service: p.service}) as ports
""",
domain=target
)
hosts = [record asyncfor record in hosts_result]
# 查询所有漏洞
vulns_result = await session.run("""
MATCH (d:Domain {name: $domain})<-[:BELONGS_TO]-(s:Subdomain)-[:RESOLVES_TO]->(h:Host)
MATCH (h)-[:HAS_OPEN_PORT]->(p:Port)-[:RUNS_SERVICE]->(srv:Service)
MATCH (srv)-[:HAS_VULNERABILITY]->(v:Vulnerability)
RETURN DISTINCT v.cve as cve, v.severity as severity,
v.cvss as cvss, v.description as description
""",
domain=target
)
vulns = [record asyncfor record in vulns_result]
return {
"target": target,
"subdomains": subdomains,
"hosts": hosts,
"vulnerabilities": vulns
}
asyncdef find_attack_chains(self, target: str, max_depth: int = 3) -> List[Dict]:
"""
查询所有可能的攻击链
参数说明:
- target: 目标域名
- max_depth: 攻击链最大深度(跳数)
返回值:
- 所有可能的攻击路径列表,每条路径包含:
- 起点(可利用的漏洞或凭据)
- 中间节点(可攻陷的主机)
- 终点(高价值目标)
"""
asyncwith self.driver.session() as session:
result = await session.run("""
MATCH path = (start:Asset {target: $target})-[:CAN_COMPROMISE*1..{max_depth}]->(end:Asset)
WHERE start.value > 0 AND end.value > 0
RETURN path,
reduce(score = 1.0, r IN relationships(path) | score * r.difficulty) as success_prob,
length(path) as depth
ORDER BY success_prob DESC, depth ASC
LIMIT 10
""",
target=target,
max_depth=max_depth
)
attack_chains = []
asyncfor record in result:
path = record['path']
chain = {
"success_probability": record['success_prob'],
"depth": record['depth'],
"nodes": [],
"relationships": []
}
for node in path.nodes:
chain['nodes'].append({
"label": list(node.labels)[0],
"properties": dict(node)
})
for rel in path.relationships:
chain['relationships'].append({
"type": rel.type,
"properties": dict(rel)
})
attack_chains.append(chain)
return attack_chains
asyncdef track_compromised_host(self, host_ip: str, credential: Dict, technique: str) -> None:
"""
记录已攻陷主机和获取的凭据
参数说明:
- host_ip: 已攻陷主机的 IP
- credential: 获取的凭据(用户名、密码、哈希等)
- technique: 利用技术(MITRE ATT&CK ID)
"""
asyncwith self.driver.session() as session:
# 创建已攻陷主机节点
await session.run("""
MERGE (h:Host {ip: $ip})
SET h.compromised = true,
h.compromised_at = datetime(),
h.compromised_via = $technique
""",
ip=host_ip,
technique=technique
)
# 创建凭据节点并关联到主机
await session.run("""
MERGE (h:Host {ip: $ip})
MERGE (c:Credential {username: $user, hash: $hash})
MERGE (h)-[:HAS_CREDENTIAL]->(c)
SET c.crack_time = $crack_time, c.type = $type
""",
ip=host_ip,
user=credential.get('username'),
hash=credential.get('hash'),
crack_time=credential.get('crack_time'),
type=credential.get('type', 'password')
)
asyncdef get_next_priority_targets(self, target: str, limit: int = 5) -> List[Dict]:
"""
获取下一阶段优先目标列表
参数说明:
- target: 原始目标域名
- limit: 返回目标数量
返回值:
- 按优先级排序的目标列表,每个目标包含:
- 主机 IP
- 优先级分数
- 推荐理由
"""
asyncwith self.driver.session() as session:
result = await session.run("""
MATCH (d:Domain {name: $domain})<-[:BELONGS_TO]-(s:Subdomain)-[:RESOLVES_TO]->(h:Host)
WHERE NOT h.compromised = true
OPTIONAL MATCH (h)-[:HAS_OPEN_PORT]->(p:Port)-[:RUNS_SERVICE]->(srv:Service)
OPTIONAL MATCH (srv)-[:HAS_VULNERABILITY]->(v:Vulnerability)
WITH h, COUNT(DISTINCT srv) as service_count,
COUNT(DISTINCT v) as vuln_count,
SUM(CASE WHEN v.severity = 'CRITICAL' THEN 1 ELSE 0 END) as critical_count
RETURN h.ip as ip,
service_count as exposed_services,
vuln_count as total_vulnerabilities,
critical_count as critical_vulns,
(service_count * 0.3 + vuln_count * 0.5 + critical_count * 0.2) as priority_score
ORDER BY priority_score DESC
LIMIT $limit
""",
domain=target,
limit=limit
)
targets = []
asyncfor record in result:
targets.append({
"ip": record['ip'],
"priority_score": record['priority_score'],
"exposed_services": record['exposed_services'],
"total_vulnerabilities": record['total_vulnerabilities'],
"critical_vulnerabilities": record['critical_vulns'],
"recommendation": f"主机暴露 {record['exposed_services']} 个服务,"
f"发现 {record['total_vulnerabilities']} 个漏洞,"
f"其中 {record['critical_vulns']} 个高危漏洞"
})
return targets
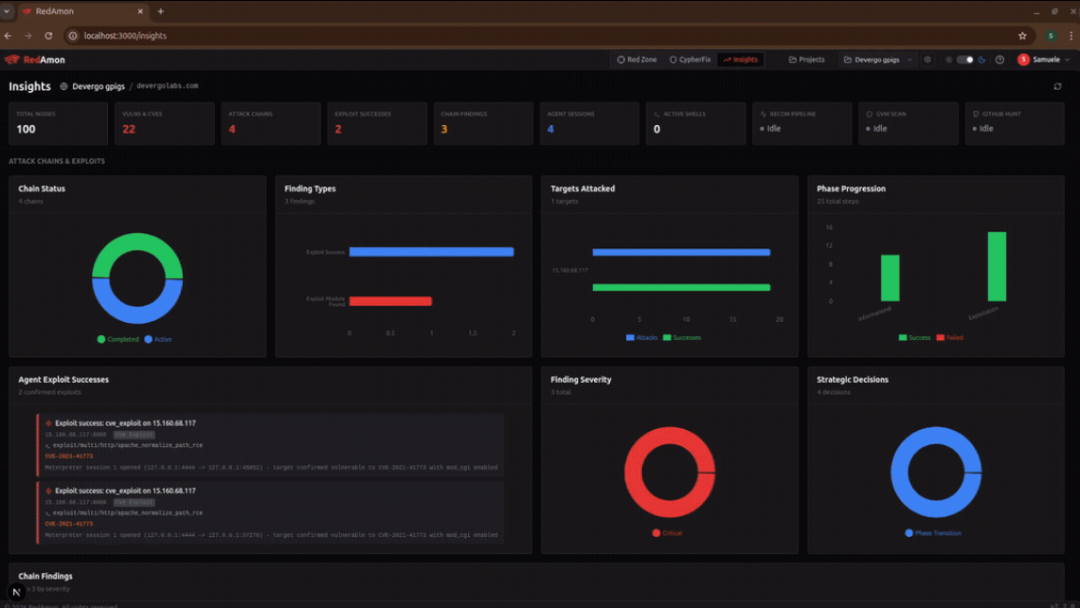
图5:RedAmon Insights 菜单总览界面
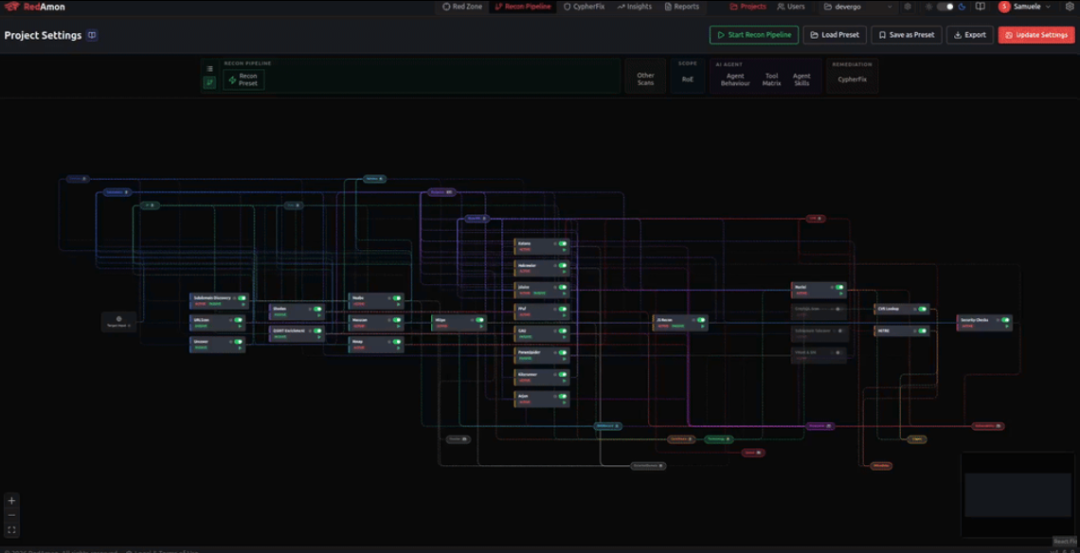
图6:RedAmon Pipeline 方式信息收集界面
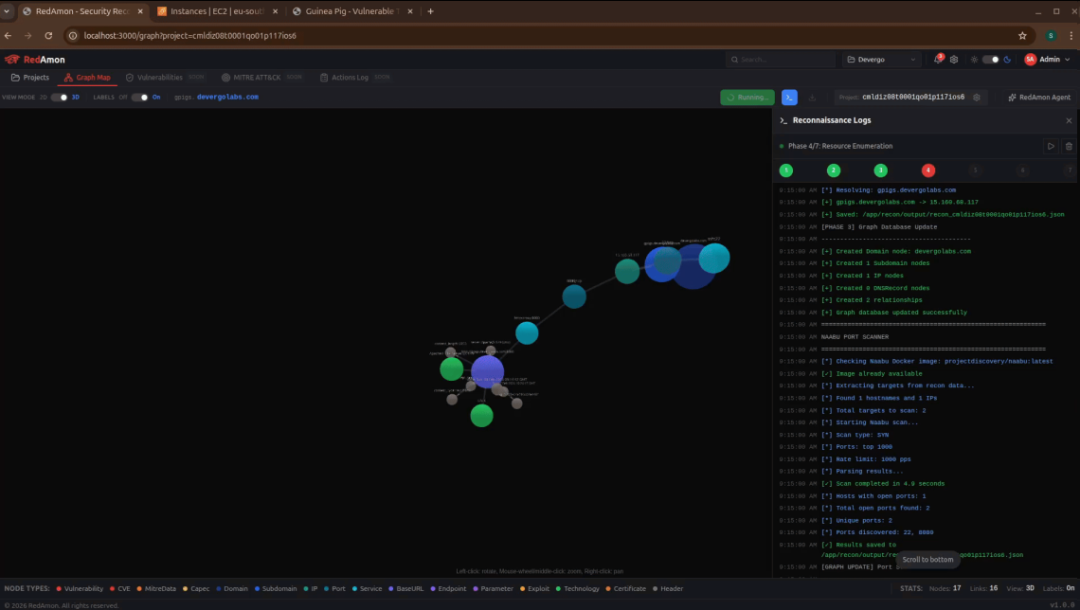
图7:RedAmon 普通信息收集界面
六、CypherFix 自动漏洞修复系统
有了记忆系统保障长周期认知的连续性,还需要解决另一个更棘手的问题:当 Agent 发现漏洞后,如何快速生成修复代码并提交给开发团队?
在实际的安全测试工作中,发现漏洞只是第一步,更重要的是推动漏洞的修复。传统流程存在多个痛点:
- 沟通成本高:渗透测试人员需要向开发人员解释漏洞的危害和修复方法
- 修复周期长:从发现到修复往往需要数周甚至数月时间
- 修复质量参差:开发人员可能不熟悉安全编码,修复不彻底
- 重复漏洞多:同类漏洞在不同项目中反复出现
CypherFix 系统的目标是实现漏洞到修复代码的全自动化,大幅缩短修复周期,提高修复质量。它的设计理念很创新:将漏洞修复视为一种编程任务,让 AI 代码生成模型来完成。
CypherFix 的核心工作流程:
- 漏洞识别:从图数据库中获取新发现的漏洞信息
- 代码定位:自动分析漏洞关联的代码仓库,定位存在问题的代码
- 修复生成:基于最佳实践生成符合规范的修复代码
- 测试验证:运行单元测试确保修复没有引入新问题
- 自动提交:创建 GitHub PR,包含修复代码和详细说明
这种自动化修复系统代表了安全测试的未来方向——不仅是发现问题,更重要的是解决问题。
以下是 CypherFix 自动漏洞修复编排器的实现代码:
# 文件位置: agentic/cypherfix_codefix/orchestrator.py
# CypherFix 自动漏洞修复编排器 - 纯 ReAct 循环
import asyncio
import json
import logging
import os
from typing import Optional
import httpx
from .state import CodeFixState, CodeFixSettings
from .tools import CODEFIX_TOOLS
from .tools.github_repo import GitHubRepoManager
from .prompts.system import build_codefix_system_prompt
from .project_settings import load_cypherfix_settings
logger = logging.getLogger(__name__)
TOOL_HANDLERS = {
"github_glob": github_glob, # 模式匹配文件搜索
"github_grep": github_grep, # 内容搜索文件
"github_read": github_read, # 读取文件内容
"github_edit": github_edit, # 编辑文件
"github_write": github_write, # 写入文件
"github_bash": github_bash, # 执行 bash 命令
"github_list_dir": github_list_dir, # 列出目录
"github_symbols": github_symbols, # 符号搜索
"github_find_definition": github_find_definition, # 查找定义
"github_find_references": github_find_references, # 查找引用
"github_repo_map": github_repo_map, # 仓库映射
}
# 需要顺序执行的工具(不能并行)
SEQUENTIAL_TOOLS = {"github_edit", "github_write", "github_bash"}
class CodeFixOrchestrator:
"""纯 ReAct 循环编排器 - LLM 是唯一控制器"""
def __init__(self, state: CodeFixState, callback):
self.state = state
self.callback = callback
self.repo_manager: Optional[GitHubRepoManager] = None
self.llm_client = None
self.approval_future: Optional[asyncio.Future] = None
self.guidance_messages: list[str] = []
self.max_output_chars = 20000
self.context_compact_threshold = 0.80
self.last_llm_text: str = ""
asyncdef run(self, remediation_id: str):
"""主入口 - CypherFix 会话启动"""
SEP = "=" * 80
logger.info(f"\n{SEP}\n CODEFIX SESSION START — {remediation_id}\n{SEP}")
# 加载设置
settings_dict = await load_cypherfix_settings(self.state.project_id)
if settings_dict:
self.state.settings = CodeFixSettings(**{
k: v for k, v in settings_dict.items()
if k in CodeFixSettings.model_fields
})
# 构建系统提示词(包含工具描述)
system_prompt = build_codefix_system_prompt(self.state.settings)
# 初始化 GitHub 仓库管理器
if self.state.settings.github_repo:
self.repo_manager = GitHubRepoManager(
self.state.settings.github_repo,
self.state.settings.default_branch
)
await self.repo_manager.clone_repo()
# ReAct 循环:思考 → 工具调用 → 观察 → 迭代
iteration = 0
while iteration < self.state.settings.max_iterations:
iteration += 1
# 思考阶段:LLM 分析当前状态并决定下一步
thought = await self._think_phase(system_prompt, iteration)
# 工具执行阶段:执行 LLM 决定的工具调用
tool_result = await self._tool_execution_phase(thought)
# 判断是否完成
if self._is_fix_complete(tool_result):
break
# 会话结束
logger.info(f"\n{SEP}\n CODEFIX SESSION END — {remediation_id}\n{SEP}")
asyncdef _think_phase(self, system_prompt: str, iteration: int) -> dict:
"""思考阶段 - LLM 分析并决策"""
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": f"第 {iteration} 轮迭代"}
]
# 调用 LLM 生成决策(包含工具调用)
response = await self.llm_client.chat.completions.create(
model=self.state.settings.model,
messages=messages,
tools=self._get_tool_schemas(),
tool_choice="auto"
)
return response
asyncdef _tool_execution_phase(self, thought: dict) -> dict:
"""工具执行阶段 - 执行 LLM 决定的工具调用"""
ifnot thought.tool_calls:
return {"status": "no_tools"}
results = []
for tool_call in thought.tool_calls:
tool_name = tool_call.function.name
tool_args = json.loads(tool_call.function.arguments)
# 执行工具
handler = TOOL_HANDLERS.get(tool_name)
if handler:
result = await handler(**tool_args)
results.append({
"tool": tool_name,
"result": result
})
return {"results": results}
图8:RedAmon CypherFix Diff 比较界面
七、容器化架构与部署
至此,Agent 能够思考、能够行动、能够记忆、能够自我纠偏。但还有一个关键问题悬而未决:当整个系统全速运转时,如何保证各组件的隔离性、可移植性和环境一致性?
这里我们需要理解容器化技术的重要价值。传统的软件部署方式就像在同一个房间里运行所有设备,相互之间容易产生干扰。而容器化技术就像是给每个组件分配独立的"房间",它们各自运行,互不干扰,但又可以通过标准化的方式相互通信。
RedAmon 采用全栈容器化架构的优势:
- 环境一致性:开发、测试、生产环境完全一致,避免"在我机器上能跑"的问题
- 快速部署:一条命令就能启动完整系统,大大降低使用门槛
- 资源隔离:渗透测试工具在隔离环境中运行,不会影响宿主系统
- 易于扩展:可以快速添加新的工具和服务
- 便于维护:每个组件职责清晰,升级和调试都更简单
RedAmon 的答案是:基于 Docker Compose 的全栈容器化架构,将所有服务(Web 应用、Agent、Neo4j、PostgreSQL、Kali 沙箱、MCP 工具服务器)封装为独立容器,通过 docker-compose.yml 一键部署。
对于初学者来说,这意味着你不需要精通复杂的环境配置,只需要安装 Docker,运行一条命令,就能获得一个完整的自动化渗透测试平台。
以下是 RedAmon Docker Compose 配置文件:
# 文件位置: docker-compose.yml
# RedAmon 统一 Docker Compose 配置
# 启动: docker compose up -d
# 停止: docker compose down
# 日志: docker compose logs -f
# 构建: docker compose --profile tools build
services:
# ===========================================================================
# 数据库服务
# ===========================================================================
postgres:
image:postgres:16-alpine
container_name:redamon-postgres
environment:
POSTGRES_USER:${POSTGRES_USER:-redamon}
POSTGRES_PASSWORD:${POSTGRES_PASSWORD:-redamon_secret}
POSTGRES_DB:${POSTGRES_DB:-redamon}
ports:
-"${POSTGRES_PORT:-5432}:5432"
volumes:
-postgres_data:/var/lib/postgresql/data
restart:unless-stopped
healthcheck:
test:["CMD-SHELL","pg_isready -U ${POSTGRES_USER:-redamon} -d ${POSTGRES_DB:-redamon}"]
interval:10s
timeout:5s
retries:5
networks:
-redamon
neo4j:
image:neo4j:5.26-community
container_name:redamon-neo4j
environment:
NEO4J_AUTH:neo4j/${NEO4J_PASSWORD:-changeme123}
NEO4J_PLUGINS:'["apoc"]'
NEO4J_dbms_security_procedures_unrestricted:apoc.*
NEO4J_dbms_security_procedures_allowlist:apoc.*
ports:
-"${NEO4J_HTTP_PORT:-7474}:7474"# HTTP
-"${NEO4J_BOLT_PORT:-7687}:7687" # Bolt
volumes:
-neo4j_data:/data
-neo4j_logs:/logs
restart:unless-stopped
healthcheck:
test:["CMD","wget","-q","--spider","http://localhost:7474"]
interval:15s
timeout:10s
retries:10
start_period:30s
networks:
-redamon
# ===========================================================================
# 后端服务
# ===========================================================================
recon-orchestrator:
build:./recon_orchestrator
container_name:redamon-recon-orchestrator
ports:
-"${RECON_ORCH_PORT:-8010}:8010"
volumes:
-/var/run/docker.sock:/var/run/docker.sock# Docker-in-Docker 支持
-./recon_orchestrator:/app
-./recon:/app/recon:ro
environment:
RECON_IMAGE:redamon-recon:latest
NEO4J_URI:bolt://localhost:7687
NEO4J_USER:neo4j
NEO4J_PASSWORD:${NEO4J_PASSWORD:-changeme123}
AGENT_API_URL:http://localhost:${AGENT_PORT:-8090}
INTERNAL_API_KEY:${INTERNAL_API_KEY:-changeme}
restart:unless-stopped
networks:
-redamon
kali-sandbox:
build:
context:./mcp
dockerfile:kali-sandbox/Dockerfile
network:host
container_name:redamon-kali
cap_add:
-NET_ADMIN # 允许网络扫描
-NET_RAW
-SYS_PTRACE
ports:
-"${MCP_NETWORK_RECON_PORT:-8000}:8000"
-"${MCP_NUCLEI_PORT:-8002}:8002"
-"${MCP_METASPLOIT_PORT:-8003}:8003"
-"${MCP_NMAP_PORT:-8004}:8004"
-"${MCP_PLAYWRIGHT_PORT:-8005}:8005"
-"4444:4444" # Metasploit 监听器
volumes:
-./mcp/servers:/opt/mcp_servers
-./agentic/agent-workspace:/workspace# 共享工作空间
environment:
PYTHONUNBUFFERED:"1"
MCP_TRANSPORT:sse
NEO4J_URI:bolt://neo4j:7687
NEO4J_USER:neo4j
NEO4J_PASSWORD:${NEO4J_PASSWORD:-changeme123}
REDAMON_AGENT_URL:http://agent:8080
restart:unless-stopped
networks:
redamon:
pentest-net:
agent:
build:
context:.
dockerfile:agentic/Dockerfile
args:
SKIP_KB:"${SKIP_KB:-false}"
container_name:redamon-agent
ports:
-"${AGENT_PORT:-8090}:8080"
environment:
# Neo4j 连接(内部 Docker 网络)
NEO4J_URI:bolt://neo4j:7687
NEO4J_USER:neo4j
NEO4J_PASSWORD:${NEO4J_PASSWORD:-changeme123}
# MCP 工具服务器(内部 Docker 网络)
MCP_NETWORK_RECON_URL:http://kali-sandbox:8000/sse
MCP_NUCLEI_URL:http://kali-sandbox:8002/sse
MCP_NMAP_URL:http://kali-sandbox:8004/sse
MCP_METASPLOIT_URL:http://kali-sandbox:8003/sse
# PostgreSQL(检查点持久化)
DATABASE_URL:"postgresql://${POSTGRES_USER:-redamon}:${POSTGRES_PASSWORD:-redamon_secret}@postgres:5432/${POSTGRES_DB:-redamon}"
PERSISTENT_CHECKPOINTER:"true"
# Webapp API(内部 Docker 网络)
WEBAPP_API_URL:http://webapp:3000
INTERNAL_API_KEY:${INTERNAL_API_KEY:-changeme}
volumes:
-./agentic/logs:/app/logs
-./agentic/skills:/app/skills:ro
-./agentic/agent-workspace:/workspace# 每项目工作空间
depends_on:
neo4j:
condition:service_healthy
kali-sandbox:
condition:service_healthy
postgres:
condition:service_healthy
restart:unless-stopped
networks:
-redamon
# ===========================================================================
# 前端服务
# ===========================================================================
webapp:
build:
context:./webapp
args:
REDAMON_VERSION:"${REDAMON_VERSION:-0.0.0}"
container_name:redamon-webapp
ports:
-"${WEBAPP_PORT:-3000}:3000"
environment:
# PostgreSQL (Prisma)
DATABASE_URL:"postgresql://${POSTGRES_USER:-redamon}:${POSTGRES_PASSWORD:-redamon_secret}@postgres:5432/${POSTGRES_DB:-redamon}"
# Neo4j (服务端图查询)
NEO4J_URI:bolt://neo4j:7687
NEO4J_USER:neo4j
NEO4J_PASSWORD:${NEO4J_PASSWORD:-changeme123}
# 后端服务(服务端 API 路由 → 内部 Docker 网络)
RECON_ORCHESTRATOR_URL:http://recon-orchestrator:8010
AGENT_API_URL:http://agent:8080
AGENT_WS_URL:ws://agent:8080/ws/agent
volumes:
-./recon/output:/data/recon-output:ro
-./mcp/nuclei-templates:/data/nuclei-templates:rw
-report_data:/data/reports
depends_on:
postgres:
condition:service_healthy
neo4j:
condition:service_healthy
restart:unless-stopped
networks:
-redamon
networks:
redamon:
name:redamon-network
driver:bridge
pentest-net:
driver:bridge
ipam:
config:
-subnet:172.28.0.0/16
volumes:
postgres_data:
neo4j_data:
report_data:
八、多 LLM 提供商支持
说了这么多 Agent 的编排和治理,一个自然的追问是:这些 Agent 背后的"大脑"到底从何而来?
LLM(Large Language Model,大语言模型)是驱动整个系统的核心智能引擎。就像人类专家需要大脑来思考和决策一样,AI 智能体也需要强大的语言模型来理解任务、分析情况、制定策略。
目前市面上有多种优秀的 LLM 提供商:
- OpenAI:提供 GPT-4 等强大模型,API 稳定,文档完善
- Anthropic:推出 Claude 系列,在安全和准确性方面表现出色
- Google:拥有 Gemini 等多模态模型
- 开源模型:通过 Llama、Qwen 等可在本地运行
RedAmon 的设计哲学是LLM 提供商无关性——通过抽象层统一接入多种提供商,用户可以根据成本、性能、合规性需求自由切换模型。
为什么这种多提供商支持很重要?
- 成本优化:不同任务的复杂度不同,可以灵活选择模型,简单的任务用便宜模型,复杂的任务用强大模型
- 风险分散:不依赖单一提供商,避免服务中断风险
- 合规要求:某些企业可能要求数据在本地处理,可以使用本地模型
- 技术选择:可以根据实际效果选择最适合的模型
RedAmon 通过统一的接口层屏蔽了不同提供商的差异,让用户可以像更换汽车轮胎一样轻松切换 AI 模型。
以下是多 LLM 提供商统一接口的实现代码:
# 文件位置: agentic/llm_providers.py
# 多 LLM 提供商统一接口
from abc import ABC, abstractmethod
from typing import List, Dict, Optional
import asyncio
class LLMProvider(ABC):
"""LLM 提供商抽象基类"""
@abstractmethod
asyncdef generate(self, prompt: str, **kwargs) -> str:
"""生成文本"""
pass
@abstractmethod
asyncdef generate_with_tools(self, prompt: str, tools: List[Dict], **kwargs) -> Dict:
"""生成文本并调用工具"""
pass
@abstractmethod
asyncdef stream_generate(self, prompt: str, **kwargs):
"""流式生成文本"""
pass
class AnthropicProvider(LLMProvider):
"""Anthropic Claude 提供商"""
def __init__(self, api_key: str, model: str = "claude-opus-4-20250514"):
self.api_key = api_key
self.model = model
self.client = self._initialize_client()
def _initialize_client(self):
import anthropic
return anthropic.AsyncAnthropic(api_key=self.api_key)
asyncdef generate(self, prompt: str, **kwargs) -> str:
"""生成文本"""
response = await self.client.messages.create(
model=self.model,
max_tokens=kwargs.get('max_tokens', 4096),
temperature=kwargs.get('temperature', 0.7),
messages=[
{"role": "user", "content": prompt}
]
)
return response.content[0].text
asyncdef generate_with_tools(self, prompt: str, tools: List[Dict], **kwargs) -> Dict:
"""生成文本并调用工具"""
# 转换工具定义为 Anthropic 格式
anthropic_tools = []
for tool in tools:
anthropic_tools.append({
"name": tool['name'],
"description": tool['description'],
"input_schema": {
"type": "object",
"properties": tool['parameters'],
"required": tool.get('required', [])
}
})
response = await self.client.messages.create(
model=self.model,
max_tokens=kwargs.get('max_tokens', 4096),
temperature=kwargs.get('temperature', 0.7),
messages=[
{"role": "user", "content": prompt}
],
tools=anthropic_tools
)
# 解析响应
result = {
"content": response.content[0].text if response.content else"",
"tool_calls": []
}
for block in response.content:
if block.type == "tool_use":
result["tool_calls"].append({
"id": block.id,
"name": block.name,
"parameters": block.input
})
return result
asyncdef stream_generate(self, prompt: str, **kwargs):
"""流式生成文本"""
stream = await self.client.messages.create(
model=self.model,
max_tokens=kwargs.get('max_tokens', 4096),
temperature=kwargs.get('temperature', 0.7),
messages=[
{"role": "user", "content": prompt}
],
stream=True
)
asyncfor event in stream:
if event.type == "content_block_delta":
yield event.delta.text
class OpenAIProvider(LLMProvider):
"""OpenAI GPT 提供商"""
def __init__(self, api_key: str, model: str = "gpt-4-turbo"):
self.api_key = api_key
self.model = model
self.client = self._initialize_client()
def _initialize_client(self):
import openai
return openai.AsyncOpenAI(api_key=self.api_key)
asyncdef generate(self, prompt: str, **kwargs) -> str:
"""生成文本"""
response = await self.client.chat.completions.create(
model=self.model,
max_tokens=kwargs.get('max_tokens', 4096),
temperature=kwargs.get('temperature', 0.7),
messages=[
{"role": "user", "content": prompt}
]
)
return response.choices[0].message.content
asyncdef generate_with_tools(self, prompt: str, tools: List[Dict], **kwargs) -> Dict:
"""生成文本并调用工具"""
# 转换工具定义为 OpenAI 格式
openai_tools = []
for tool in tools:
openai_tools.append({
"type": "function",
"function": {
"name": tool['name'],
"description": tool['description'],
"parameters": {
"type": "object",
"properties": tool['parameters'],
"required": tool.get('required', [])
}
}
})
response = await self.client.chat.completions.create(
model=self.model,
max_tokens=kwargs.get('max_tokens', 4096),
temperature=kwargs.get('temperature', 0.7),
messages=[
{"role": "user", "content": prompt}
],
tools=openai_tools
)
# 解析响应
message = response.choices[0].message
result = {
"content": message.content or"",
"tool_calls": []
}
if message.tool_calls:
for call in message.tool_calls:
result["tool_calls"].append({
"id": call.id,
"name": call.function.name,
"parameters": json.loads(call.function.arguments)
})
return result
asyncdef stream_generate(self, prompt: str, **kwargs):
"""流式生成文本"""
stream = await self.client.chat.completions.create(
model=self.model,
max_tokens=kwargs.get('max_tokens', 4096),
temperature=kwargs.get('temperature', 0.7),
messages=[
{"role": "user", "content": prompt}
],
stream=True
)
asyncfor chunk in stream:
if chunk.choices[0].delta.content:
yield chunk.choices[0].delta.content
class OpenRouterProvider(LLMProvider):
"""OpenRouter 多模型提供商"""
def __init__(self, api_key: str, model: str = "anthropic/claude-opus-4"):
self.api_key = api_key
self.model = model
self.base_url = "https://openrouter.ai/api/v1"
self.client = self._initialize_client()
def _initialize_client(self):
import openai
return openai.AsyncOpenAI(
api_key=self.api_key,
base_url=self.base_url
)
# OpenRouter 使用与 OpenAI 兼容的接口
asyncdef generate(self, prompt: str, **kwargs) -> str:
"""生成文本"""
response = await self.client.chat.completions.create(
model=self.model,
max_tokens=kwargs.get('max_tokens', 4096),
temperature=kwargs.get('temperature', 0.7),
messages=[
{"role": "user", "content": prompt}
]
)
return response.choices[0].message.content
asyncdef generate_with_tools(self, prompt: str, tools: List[Dict], **kwargs) -> Dict:
"""生成文本并调用工具(OpenRouter 部分模型支持)"""
# 类似 OpenAI 的实现
pass
class LLMFactory:
"""LLM 提供商工厂"""
@staticmethod
def create(provider: str, config: Dict) -> LLMProvider:
"""创建 LLM 提供商实例"""
if provider == "anthropic":
return AnthropicProvider(
api_key=config['api_key'],
model=config.get('model', 'claude-opus-4-20250514')
)
elif provider == "openai":
return OpenAIProvider(
api_key=config['api_key'],
model=config.get('model', 'gpt-4-turbo')
)
elif provider == "openrouter":
return OpenRouterProvider(
api_key=config['api_key'],
model=config.get('model', 'anthropic/claude-opus-4')
)
else:
raise ValueError(f"不支持的 LLM 提供商: {provider}")
图9:RedAmon 系统设置界面
七项核心技术拆解完毕,RedAmon 的工程全貌已经清晰。但技术从来不是目的——这些设计最终要回答的是:它在真实场景中解决了哪些传统方法无法解决的问题?
差异化能力与行业痛点
七项核心技术拆解完毕,RedAmon 的工程全貌已经清晰。但技术从来不是目的——这些设计最终要回答的是:它在真实场景中解决了哪些传统方法无法解决的问题?
为了更好地理解 RedAmon 的价值,我们需要先了解传统自动化渗透测试工具的局限性。市面上已经有了很多优秀的扫描器(如 Nessus、OpenVAS)和自动化框架(如 Autosploit),为什么还需要 RedAmon?
传统工具面临的三大核心痛点:
- 手工决策无法自动化:现有工具只能执行固定脚本,无法根据实时结果动态调整策略。就像一个只会按固定路线行驶的汽车,遇到道路施工就无法绕行。
- 工具结果无法关联:各种扫描器输出孤立结果,难以识别资产间关系和攻击链。这就像是得到了一堆拼图碎片,却不知道如何拼成完整的画面。
- 修复流程无法闭环:发现漏洞后仍需手工编写修复代码,耗时且易出错。这就像是医生诊断出了疾病,却无法开具药方。
RedAmon 通过 AI 编排、图数据库驱动和自动修复三大创新,系统性地回应了这些行业难题。接下来我们逐一分析这些痛点和解决方案。
行业痛点 | 传统做法的局限 | RedAmon 的差异化 |
|---|---|---|
手工决策瓶颈 | 自动化工具只能执行固定脚本,无法根据实时结果动态调整策略 | SG-ReAct 架构让 Root Agent 基于全局状态自主决策,动态调整攻击路径 |
攻击面盲区 | 扫描器输出孤立结果,无法识别资产间关系和攻击链 | Neo4j 图数据库将分散数据转化为攻击路径图,智能推演可达性 |
工具集成困难 | 每个工具独立运行,结果格式不统一,难以跨工具查询 | MCP 工具系统标准化 70+ 工具接口,统一输出到图数据库 |
修复流程断裂 | 发现漏洞后需手工编写修复代码,耗时长且易出错 | CypherFix 自动生成修复代码并创建 PR,实现漏洞到修复的闭环 |
持续认知缺失 | 工具中断后状态丢失,无法恢复之前的测试进度 | Neo4j 持久化所有攻击面数据,Agent 可从中断处恢复 |
痛点一:手工决策瓶颈与 AI 自主编排
传统自动化工具的致命缺陷是决策逻辑硬编码——Nessus 扫描完输出报告就停止,Autosploit 只能按预定义顺序运行 Exploit,无法根据实际情况调整策略。这就像一个只会按剧本演出的演员,一旦舞台状况变化就束手无策。真实渗透测试中的决策远比"如果漏洞则利用"复杂:需要权衡优先级(先攻内网数据库还是边界 Web 服务器?)、考虑风险(利用失败会触发报警吗?)、动态调整(发现 SSH 弱口令后,是直接登录还是先做横向移动?)。传统工具无法处理这些场景,最终还得回到手工决策。
RedAmon 的 SG-ReAct 架构从根本上改变了这个困境。Root Agent 不是执行固定脚本,而是持续观察-思考-行动循环:从 Neo4j 读取当前攻击面状态(观察),用 LLM 分析下一步最优策略(思考),部署 Fireteam 执行专家任务(行动),将结果写回 Neo4j(观察),如此循环。这种循环使 Agent 能够动态应对真实世界的不确定性——发现漏洞后决定是否利用,利用失败后调整策略,获取凭据后决定横向移动目标。更重要的是,所有决策过程都可以审计(Neo4j 记录每次迭代的攻击面快照),既保证了智能,又保留了可解释性。
痛点二:攻击面盲区与图数据库智能推演
扫描器输出的最大问题是数据孤岛——Nmap 识别出开放端口,Nuclei 扫出漏洞,Subfinder 发现子域名,但这些结果无法关联。你很难回答"哪些子域名解析到同一台主机?"、"哪些漏洞可以利用同一端口?"、"从已攻陷主机能访问哪些高价值目标?"这类跨工具查询问题。传统做法是手工将结果导入 Excel 或思维导图,效率低下且易出错。
RedAmon 用 Neo4j 图数据库彻底解决了这个问题。根据实际的 schema.py 文件,系统定义了 60+ 种节点类型(Domain、Subdomain、IP、Port、Service、Vulnerability、CVE、Endpoint、Parameter、Header、GitHubSecret 等)和 100+ 种关系类型,所有节点都支持 (user_id, project_id) 租户隔离。所有工具结果直接写入图数据库,形成完整的攻击面图。
这样你就可以用 Cypher 查询语言提出复杂问题:
// 查询所有可从边界主机横向移动到数据库服务器的攻击路径
MATCH path = (boundary:IP {exposed:true})-[:RESOLVES_TO|HAS_OPEN_PORT|RUNS_SERVICE*1..3]->(db:IP)
WHERE db.role = 'database'
RETURN path,
[n IN nodes(path) | n.address] as attack_path,
[r IN relationships(path) | r.type] as techniques
ORDER BY length(path) ASC
LIMIT 5
这种图查询能自动发现攻击链——例如"边界 Web 服务器 (CVE-2021-44228) → 内网跳板机 (SSH 弱口令) → 核心数据库 (未授权访问)",这是传统扫描器无法提供的洞察。更重要的是,所有查询都自动应用租户过滤器,确保多用户环境下的数据安全。
痛点三:修复流程断裂与 CypherFix 自动化
发现漏洞后的修复流程是另一个效率黑洞。传统流程是:渗透测试人员编写 PoC → 开发人员复现漏洞 → 分析代码 → 编写修复补丁 → 测试验证 → 提交 PR。整个流程耗时数天到数周,且容易出现沟通误解(PoC 环境与生产环境不一致)、修复不彻底(只修复表面问题,未考虑边缘情况)、测试覆盖不足(遗漏边缘场景)等问题。
RedAmon 的 CypherFix 系统将这个流程自动化到极致:从 Neo4j 查询漏洞关联的代码仓库 → 自动克隆仓库 → 用代码感知工具定位漏洞代码 → 调用 LLM 分析成因并生成修复代码 → 运行测试验证修复 → 创建 GitHub PR。整个过程无需人工介入,从发现漏洞到修复 PR 可以在数小时内完成。更重要的是,LLM 生成的修复代码遵循安全编码最佳实践(参数化查询、输入验证、错误处理),且包含详细注释说明修复原因,既解决了问题,又传递了知识。
痛点四:持续认知缺失与状态持久化
长时间运行的渗透测试(如红队演练持续数周)最大的挑战是状态连续性——测试人员需要记住已扫描的资产、已尝试的 Exploit、已获取的凭据、未完成的攻击路径。传统自动化工具一旦中断(进程崩溃、网络故障、人工暂停),所有临时状态都会丢失,重新启动后得从头再来。
RedAmon 通过 Neo4j 持久化彻底解决了这个问题。所有攻击面数据(主机、端口、漏洞、凭据)都永久存储在图数据库中,Agent 可以随时从中断处恢复:查询 Neo4j 获取最新攻击面 → 继续未完成的攻击链 → 更新图状态。即使 Agent 重启、容器销毁、工具失败,进度都不会丢失。这种持久化还支持多 Agent 协作——多个 Agent 可以同时访问同一个图数据库,共享攻击面状态,实现真正的并行红队作战。
以上四大差异化能力共同回答了"RedAmon 为什么值得关注"。但理论终归要在实践中接受检验。接下来我们看看社区的真实评价和客观争议。
社区评价与行业观察
以上四大差异化能力共同回答了"RedAmon 为什么值得关注"。但理论终归要在实践中接受检验——一个架构再完美的系统,如果在实际使用中效果不佳,那也只是空中楼阁。
接下来我们看看社区的真实评价和客观争议,了解 RedAmon 在实际应用中的表现。
RedAmon 项目由 Samuele Giampieri(samugit83)和 Ritesh Gohil 维护,自开源以来获得 1.9k+ GitHub Stars,已成为 AI 驱动安全测试领域的标杆项目。在 GitHub 这个全球最大的开源平台上,能获得近 2000 星标的安全项目并不多见,这说明 RedAmon 确实解决了很多安全从业者的实际需求。
社区普遍认为其架构设计先进、工程化程度高,代表了 AI 安全测试的发展方向。但同时也存在一些质疑和争议——主要集中在实际效果和成本方面。毕竟,AI Agent 真的能替代经验丰富的手工渗透测试专家吗?
项目背景与定位
维度 | 信息 |
|---|---|
开源时间 | 2023 年 |
当前版本 | 4.15.1 |
GitHub Stars | 1.9k+ |
维护团队 | Samuele Giampieri(架构设计)、Ritesh Gohil(核心开发) |
技术博客 | redamon.org |
官方文档 | GitHub Wiki |
许可证 | MIT |
技术规模 | 400+ AI 模型、185,000+ 检测规则、500+ 项目设置、100+ 安全工具 |
与同类项目的对比
类型 | 代表项目 | 与 RedAmon 的差异 |
|---|---|---|
自动化扫描器 | Nessus, OpenVAS | RedAmon 增加 AI 决策层,可动态调整策略 |
编排框架 | Autosploit, Sparta | RedAmon 使用 LangGraph 状态机,支持中断恢复 |
Agent 框架 | PentAGI, HackbarAI | RedAmon 集成 Neo4j 图数据库,攻击面管理更强 |
手工工具 | Kali Linux, Metasploit | RedAmon 将这些工具封装为 MCP 接口,AI 可调用 |
社区争议与客观评价
支持观点:
- 架构创新:SG-ReAct 模式被认为是 AI 编排领域的重要创新,突破了传统自动化的决策瓶颈
- 工程化水平:Docker 容器化、MCP 工具系统、Neo4j 集成展现了高度的工程化水平
- 教学价值:作为 AI 安全的开源教学项目,帮助研究者理解 AI 编排和图数据库应用
质疑观点:
- 实际效果存疑:社区有用户反馈"AI Agent 经常陷入死循环"、"工具调用失败率较高"、"生成的 Exploit PoC 不稳定"
- 成本高昂:使用 Claude Opus 4.6 作为主模型,长时间红队演练可能产生数千美元的 API 费用
- 合规风险:自动化漏洞利用可能违反《网络安全法》等法规,需谨慎使用
待优化方向
- 稳定性改进:增加工具调用的重试机制、超时控制和错误恢复逻辑,减少 Agent 陷入死循环的概率
- 成本优化:支持本地模型(Ollama、vLLM)替代云 API,降低长期运行成本
- 结果验证:增加自动化结果验证机制(如 Exploit 成功检测、凭据有效性验证),提高可信度
- 权限控制:增加多用户管理和细粒度权限控制,支持企业级部署
- 合规增强:增加审计日志、使用授权、目标白名单等合规特性,降低法律风险
综合来看,RedAmon 已在技术完备性和工程化程度上走在了前列,但"能做"和"做得好"之间仍有距离。从这些已知的短板出发,我们不难看到接下来的演进方向。
未来展望与结语
综合来看,RedAmon 已在技术完备性和工程化程度上走在了前列,但"能做"和"做得好"之间仍有距离。从这些已知的短板出发,我们不难看到接下来的演进方向。
AI 和安全都是快速发展的领域,RedAmon 作为两者的结合体,其未来发展值得期待。基于当前的技术趋势和社区反馈,我们可以预见以下几个重要的发展方向:
- 本地模型深度集成:随着 Llama 3、Qwen2.5 等开源模型能力逼近 GPT-4/Claude Opus,RedAmon 可能增加对本地模型的一等支持,降低 API 成本、提高数据隐私性
- 多模态智能体:集成视觉模型(如 GPT-4V、Claude 3.5 Sonnet),支持截图识别、验证码识别、UI 渗透测试等场景
- 联邦学习协同:多个 RedAmon 实例共享攻击面知识(不共享原始数据),形成分布式的红队知识网络
- 合规自动化:增加渗透测试合同生成、授权管理、合规报告生成等功能,覆盖红队服务的完整业务流程
- 云原生架构:从 Docker Compose 迁移到 Kubernetes,支持大规模部署和弹性扩容
- 防御侧应用:将 SG-ReAct 架构应用于蓝队场景(自动化威胁狩猎、事件响应),形成攻防一体的 AI 安全平台
从这些发展方向可以看出,RedAmon 不仅仅是一个渗透测试工具,更是 AI 与安全融合的探索平台。它的演进将引领整个安全行业向智能化、自动化方向发展。
结语
RedAmon 代表了 AI 与安全融合的最新尝试——它不是简单地用 AI 替代手工,而是通过架构创新(SG-ReAct)、数据驱动(Neo4j)、工程化(容器化、MCP)将 AI 的决策能力与传统安全工具的执行能力深度结合,实现了从"工具自动化"到"决策自动化"的跨越。
当然,它距离"完全替代手工渗透测试"还有相当距离。当前的 AI 技术仍有局限性,安全测试的复杂性也远超一般人的想象。但它为行业指明了一个方向:未来的安全工具不一定是功能最强大的,但一定是决策最智能的。
当我们回顾 RedAmon 的技术全貌——SG-ReAct 编排、Fireteam 专家系统、Neo4j 攻击面图、CypherFix 自动修复、MCP 工具生态、Docker 容器化、多 LLM 支持——会发现它的核心价值不在于某个单一技术,而在于将前沿 AI 技术系统性地解决安全领域的真实痛点。
这正是 AI 时代安全创新的正确路径:不追求炫技式的功能堆砌,而是深入理解行业本质问题,用技术手段提供系统性解决方案。对于安全从业者来说,RedAmon 不仅是一个实用工具,更是理解 AI 如何改变传统安全工作方式的绝佳案例。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-17,如有侵权请联系 cloudcommunity@tencent.com 删除
本文分享自 Ms08067安全实验室 微信公众号,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文参与 腾讯云自媒体同步曝光计划 ,欢迎热爱写作的你一起参与!
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号