Gemma 4 来了:原生多模态,小尺寸匹敌千亿参数大模型

Gemma 4 来了:原生多模态,小尺寸匹敌千亿参数大模型

用户11563501
发布于 2026-06-23 13:08:47
发布于 2026-06-23 13:08:47
Google DeepMind刚刚发布了Gemma 4,一个包含四个型号的多模态开源模型家族。
四款模型分别是:E2B(2.3B有效参数)、E4B(4.5B有效参数)、31B(密集模型)、26B A4B(MoE架构,4B激活参数)。31B和26B A4B都支持256k上下文窗口,可以在单张H100上运行。
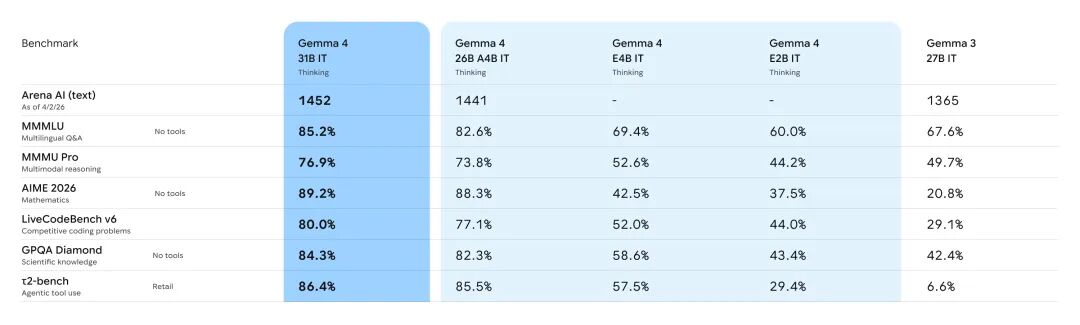
Gemma 4(31B)相比Gemma 3(27B),从架构角度几乎看不出变化。依然是那个有点特别的Pre-norm和Post-norm混合设置,依然是5:1的混合注意力——5层滑动窗口(局部)+1层全注意(全局)。注意力机制也是经典的GQA(分组查询注意力)。词汇量维持在262k,上下文长度倒是从128K涨到了256K。
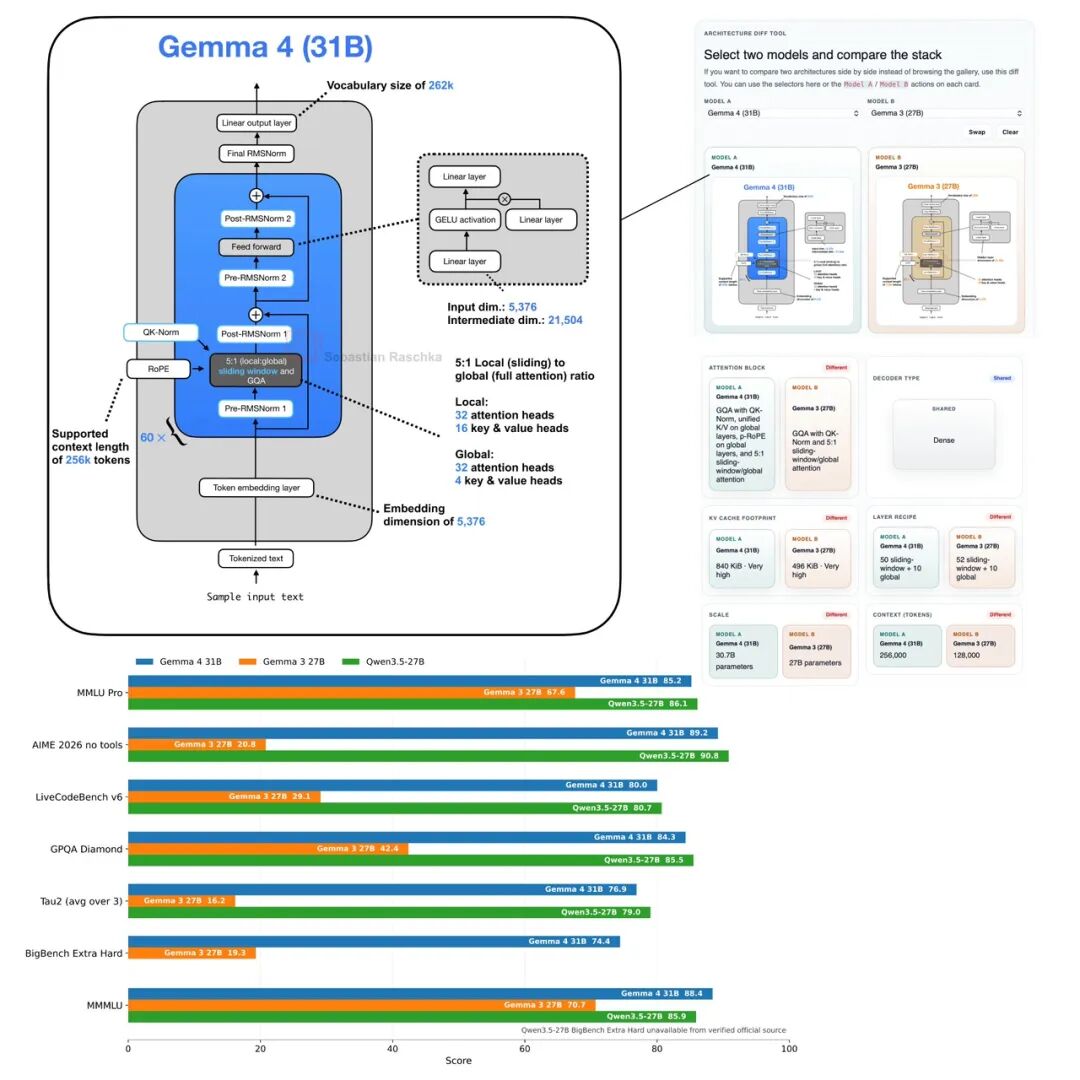
技术上的几个亮点:
- 256K上下文窗口。这是目前开源模型里最大的几个之一。意味着你可以把整个代码仓库或者超长文档一次性塞进去,足够让本地运行的模型完成真正的代码分析工作,而不是只能处理碎片。
- 原生多模态。视觉和音频是标配,E2B和E4B甚至支持本地音频处理。这对于需要在设备端做OCR、图表理解或者语音交互的场景很实用。
- Native Tool Use。支持函数调用、结构化JSON输出和原生系统指令。这才是真正的agent能力——模型不只是聊天,能帮你操作工具和API了。
这是Gemma系列第一次真正意义上的多模态。不只是图像,文本,还能处理视频。小模型(E2B、E4B)甚至支持音频。
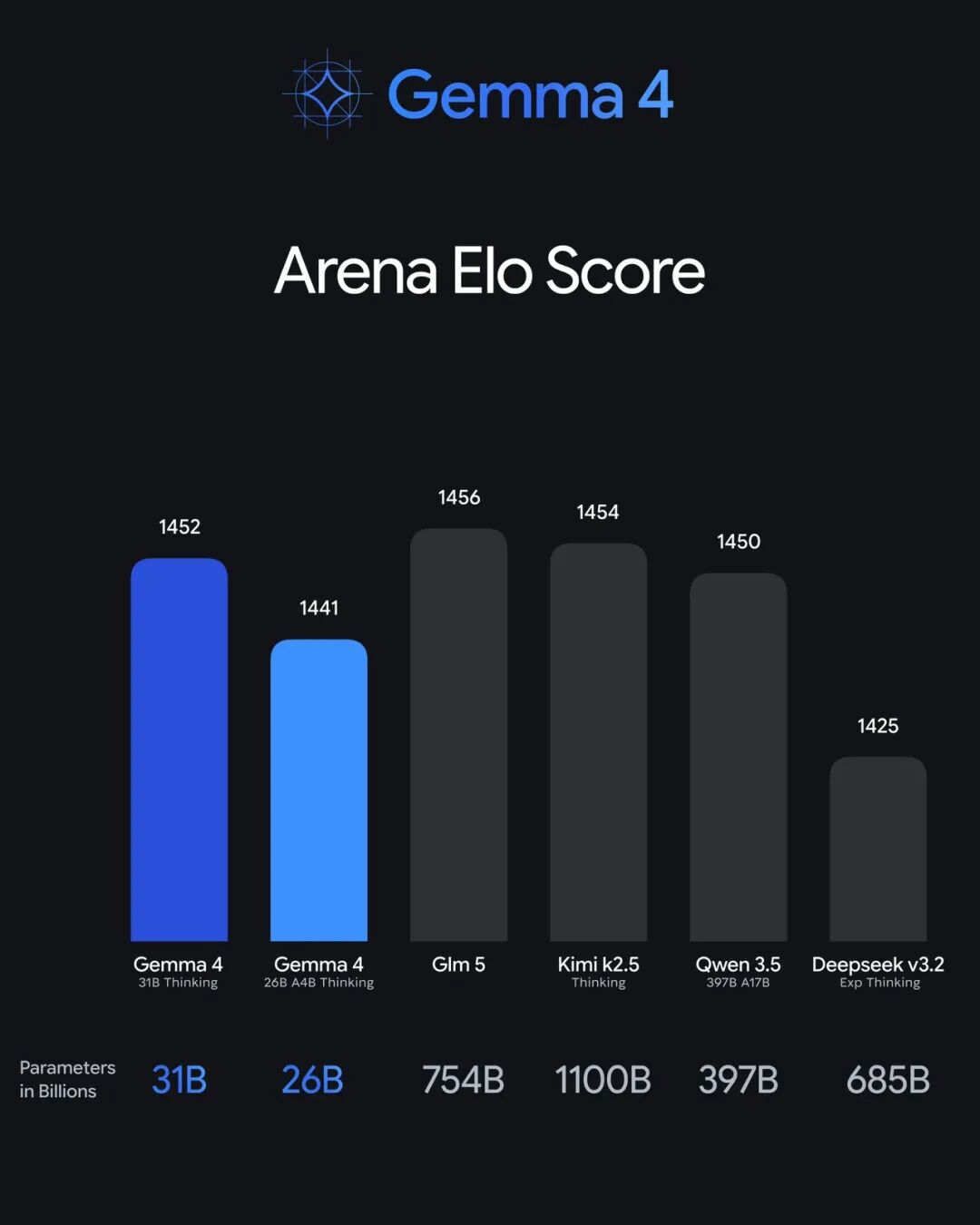
模型参数量看起来不大,但实际跑分相当离谱——31B版本在Arena排行榜上已经摸到全球第三开源模型的位置,26B MoE排第六。更夸张的是,这两个「小」模型在某些任务上能打掉比自己大20倍的竞品。
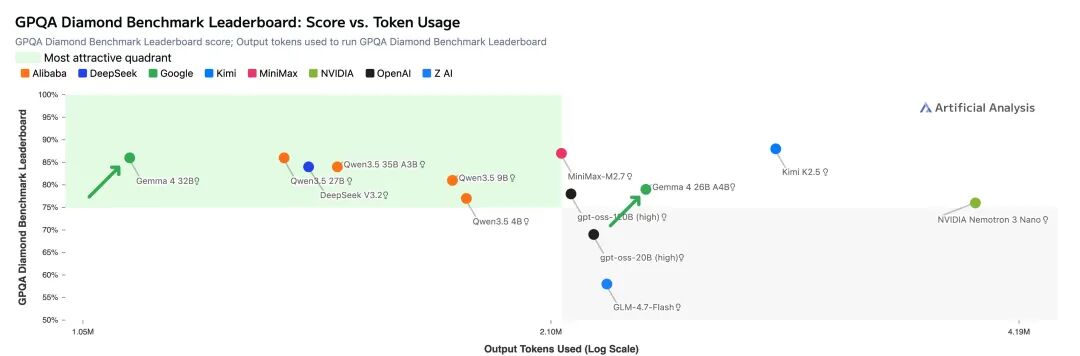
在GPQA Diamond科学推理基准上,Gemma 4 31B得分85.7%,只比Qwen3.5 27B低0.1个百分点。
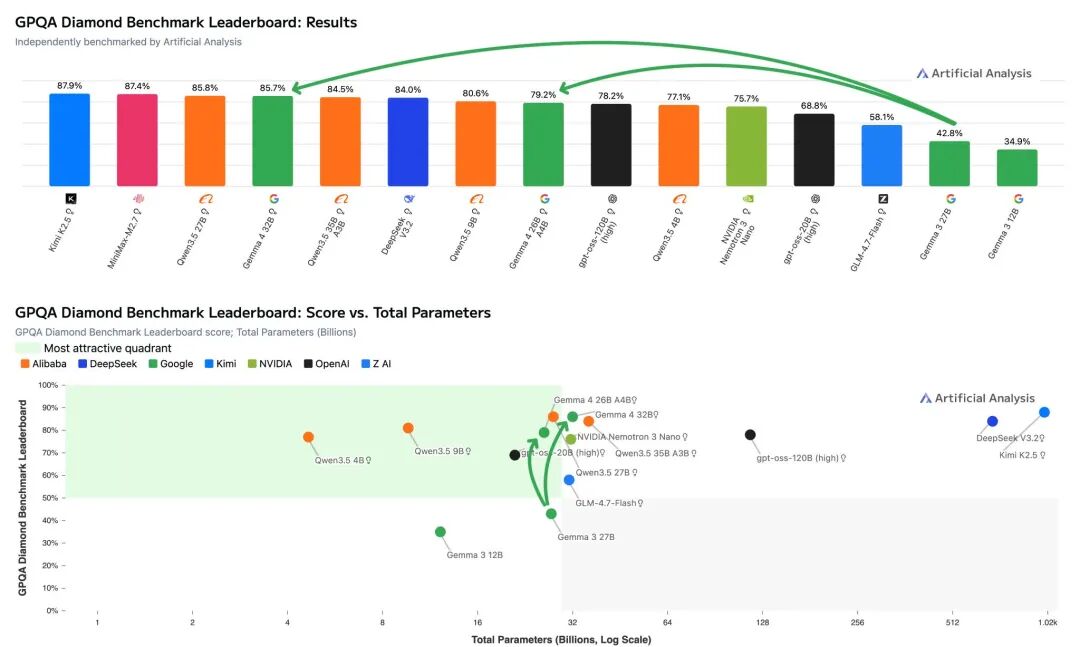
但有意思的是,Gemma 4只用了约120万输出tokens,而Qwen用了150万。效率上占优。
硬件适配做得比较扎实。31B的bfloat16权重可以塞进单张80GB H100,量化版本在消费级GPU上也能跑。E2B和E4B专门优化过,Google说已经能在Pixel手机和Jetson上离线运行,延迟基本无感。端侧应用有了更好的选择。
生态支持来得很快。transformers、llama.cpp、MLX、transformers.js、Mistral.rs都在第一时间支持了Gemma 4。Hugging Face的TRL也更新了,专门为Gemma 4做了多模态工具调用的适配。vLLM用一条docker命令就能拉起来跑:
docker run --gpus all \
-v ~/.cache/huggingface:/root/.cache/huggingface \
--env "HF_TOKEN=$HF_TOKEN" \
-p 8000:8000 \
--ipc=host \
vllm/vllm-openai:gemma4 \
--model google/gemma-4-31B-it这次还有一个变化就是许可证变为更通用限制更少的Apache 2.0许可证,这意味着各大厂可以放心商用。
模型权重已经上传到Hugging Face。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-03,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号