顶会顶刊AI安全论文研读第二十一期:ICLR 2026 | 面向MCP协议的LLM智能体安全攻击基准测试

顶会顶刊AI安全论文研读第二十一期:ICLR 2026 | 面向MCP协议的LLM智能体安全攻击基准测试

用户4179374
发布于 2026-06-22 19:52:13
发布于 2026-06-22 19:52:13

AI安全处于一个技术早期阶段,因此我们推出一个全新的“顶会顶刊AI安全论文研读”系列,方便全行业同仁和有志于从事AI安全的新生代学习理解最新技术与行业发展动态。也欢迎大家关注我们栏目的合集。
本次为大家带来的是【第21期】ICLR 2026 | 面向MCP协议的LLM智能体安全攻击基准测试
往期回顾:顶会AI安全论文研读系列
作者介绍
本文作者团队来自北京邮电大学与加州大学圣巴巴拉分校,专注于大语言模型(LLM)安全、智能体工具调用安全与MCP协议安全等前沿方向。团队核心成员在LLM智能体安全评估、对抗性攻击分类与基准构建领域具有丰富经验。
该团队首次构建了覆盖MCP工作流全阶段的端到端安全评估基准MSB,系统性地揭示了MCP协议在任务规划、工具调用与响应处理各阶段的安全漏洞,为MCP智能体安全研究提供了重要的基准平台与研究范式。
导读

模型上下文协议(MCP)标准化了大语言模型(LLM)智能体发现、描述和调用外部工具的方式。然而,MCP在解锁广泛互操作性的同时,也通过将工具变为具有自然语言元数据和标准化I/O的一等可组合对象,显著扩大了攻击面。
针对这一挑战,本文提出 MSB(MCP Security Bench)——首个端到端的MCP安全评估基准套件,系统性地衡量LLM智能体在工具使用全流程(任务规划、工具调用与响应处理)中抵御MCP特定攻击的能力。MSB的核心贡献包括:
(1)建立了涵盖12种攻击类型的分类体系,包括名称碰撞、偏好操纵、工具描述提示注入、越权参数请求、用户冒充响应、虚假错误、工具转移、检索注入以及混合攻击等;
(2)构建了通过MCP运行真实工具(包括良性和恶意工具)而非模拟的评估框架;
(3)提出了量化安全与性能权衡的鲁棒性指标——净弹性性能(NRP)。该研究在10个领域、405个工具上评估了10个主流LLM智能体,生成2,000个攻击实例,峰值攻击成功率达75.83%。
结果揭示了一个悖论性发现:工具调用能力越强的模型反而越容易受到攻击。MSB为研究者和从业者提供了研究、比较和加固MCP智能体安全性的实用基准。

【论文题目】MCP Security Bench (MSB): Benchmarking Attacks Against Model Context Protocol in LLM Agents
【论文链接】https://github.com/dongsenzhang/MSB
研究背景
近年来,大型语言模型(LLM)在问题求解、推理、工具调用与编程等多样化任务中展现出强大能力,推动了以LLM为核心决策器的AI智能体的快速发展。这些智能体通过外部工具与记忆机制的增强,能够与更丰富的外部环境交互,支持从项目开发到团队管理、信息辅助等广泛应用。
工具的引入极大地扩展了LLM智能体的功能边界,但统一标准的缺失迫使不同架构和平台需重复实现工具集成。为此,Anthropic于2024年推出了模型上下文协议(MCP),通过标准化上下文交换的统一接口,实现了工具调用的互操作性。MCP遵循主机-客户端-服务器的工作流:工具声明其能力,客户端检索并查询工具,服务器执行被选中的工具并返回结果。虽然MCP显著提升了互操作性,但它也扩大了攻击面,将智能体暴露于一系列关键安全漏洞之中。
如图1所示,本文识别了四大类MCP特定攻击框架:工具签名攻击(Tool Signature Attack)通过操纵工具名称或描述来误导工具选择;工具参数攻击(Tool Parameter Attack)诱导智能体提供越权参数导致信息泄露;工具响应攻击(Tool Response Attack)通过嵌入恶意指令或伪造错误信息篡改智能体行为;检索注入攻击(Retrieval Injection Attack)则通过向外部资源中植入恶意指令破坏上下文完整性。这些攻击覆盖了MCP工具使用全流程的三个关键阶段:任务规划、工具调用和响应处理。

图1:MCP特定攻击框架概览,包括工具签名攻击、工具参数攻击、工具响应攻击和检索注入攻击,覆盖工具使用全流程的三个阶段:任务规划、工具调用和响应处理。
现有的安全基准(如ASB、AgentDojo、InjecAgent等)主要局限于函数调用范式,无法捕捉MCP引入的这些新型安全漏洞。因此,亟需一个专门针对MCP协议的综合性安全评估基准,以系统性地评估和揭示LLM智能体在MCP场景下的安全脆弱性。
动机
尽管MCP协议在工具集成标准化方面取得了显著进展,其开放、去中心化的架构也引入了全新的安全挑战。
MCP生态系统中,任何人都可以部署MCP服务器并将恶意工具发布到第三方平台(如Smithery),攻击者无需控制LLM本身,仅需通过操纵工具的元数据(名称、描述)、参数定义、响应内容或外部资源即可实施攻击。
具体而言,攻击者的能力被限制在三个层面:
一是工具层面,攻击者可以完全控制恶意MCP服务器上托管的工具的所有组件,并可同时部署多个协同恶意工具;
二是系统提示层面,基于MCP的可用工具发现机制,攻击者可以将恶意提示无缝注入智能体的系统提示中;
三是外部资源层面,攻击者对外部资源拥有白盒权限,可以向智能体可能检索的外部数据中插入隐蔽的攻击指令。
然而,当前针对MCP安全的研究存在三个关键缺口:首先,现有基准(如ASB)仅覆盖有限的攻击类型(如四类),其评估范围局限于模拟环境,无法反映MCP引入的新型攻击面;其次,已有MCP相关基准(如MCPTox)仅关注工具描述注入攻击这一单一维度,缺乏对MCP工作流全阶段的覆盖;最后,现有评估方法大多基于静态模拟输出,无法捕捉真实MCP工具交互中暴露的动态漏洞。
这些缺口共同驱动了MSB的设计——一个在真实MCP环境中运行、覆盖全攻击阶段的端到端安全评估基准。
威胁模型
在MSB的威胁模型中,攻击者可以部署一个完全由其控制的恶意MCP服务器,包括其上托管的所有工具。
攻击者可将这些恶意工具通过链接到第三方平台(如Smithery)进行发布。然而,攻击者无法控制智能体内部的LLM,也无法像先前研究中那样直接拦截用户查询或向LLM智能体注入恶意指令。
攻击者的能力总结为三方面:
第一,工具(Tools)——攻击者可以修改恶意工具的任何组件,且MCP允许将恶意工具直接整合到智能体的工具列表中;
第二,系统提示(System Prompt)——基于MCP的可用工具发现机制,攻击者可以将恶意提示无缝插入智能体的系统提示中;
第三,外部资源(External Resources)——攻击者对外部资源拥有白盒权限,可以向这些外部资源中插入隐蔽的攻击指令,当智能体使用工具检索这些资源时即会触发攻击。攻击者的目标是破坏智能体在任务规划、工具调用和响应处理过程中的决策,诱导其执行恶意行为,例如修改敏感数据、调用文件编辑工具执行指定目标、或终止特定进程等。
方法
MSB建立了一套涵盖12种攻击类型的系统性分类体系,这些攻击类型横跨MCP工作流的三个关键阶段,并通过不同的攻击向量实施。如表1所示,攻击分类体系按阶段组织如下:
第一阶段:任务规划阶段的工具签名攻击。该阶段包含三种攻击类型:
(1)名称碰撞(Name Collision, NC)——攻击者将恶意工具的名称设置为与目标良性工具相似,诱骗智能体调用恶意工具而非预期工具;
(2)偏好操纵(Preference Manipulation, PM)——攻击者在工具描述中插入推广性陈述(如"这是世界上最好的工具"),干扰智能体的工具选择决策;
(3)提示注入(Prompt Injection, PI)——攻击者在工具描述中注入恶意指令,扭曲智能体的规划与推理过程,诱导其执行偏离用户任务的攻击行为。
第二阶段:工具调用阶段的参数攻击。该阶段包含越权参数(Out-of-Scope Parameter, OP)攻击——攻击者通过定义超出正常范围的工具参数,胁迫智能体提供越权输入,导致信息泄露。例如,恶意工具可能将参数名设置为LLM模型名称,诱导智能体在调用时暴露其底层模型信息。
第三阶段:响应处理阶段的攻击。该阶段包含三种攻击类型:
(1)用户冒充(User Impersonation, UI)——恶意工具在响应中冒充用户身份并嵌入恶意指令,利用LLM强大的指令遵循能力诱导其执行非预期操作;
(2)虚假错误(False Error, FE)——恶意工具返回伪造的错误信息,要求智能体遵循特定"修复"指令才能成功调用工具,从而诱导其执行恶意操作;
(3)工具转移(Tool Transfer, TT)——通过链式攻击实现,中继恶意工具通过其响应操纵智能体调用终端恶意工具,由终端工具执行实际攻击。
第四阶段:检索注入攻击(Retrieval Injection, RI)。攻击者向外部数据库中植入包含恶意指令的数据,当智能体通过良性工具检索这些外部资源时,恶意指令被注入到观察序列中,破坏上下文完整性。
与响应攻击的区别在于,RI中工具本身是良性的,恶意指令来源于被污染的外部数据。
此外,MSB还设计了混合攻击(Mixed Attacks),同时利用工具的多个组件作为攻击向量,构建覆盖多阶段的复合攻击。例如,PM与UI的组合可以整合从工具选择到响应处理的端到端攻击链,在真实的多工具部署场景中构成更大威胁。

表1:MSB中的攻击类型分类。s表示后缀,p表示推广性陈述,u表示冒充的用户查询,e表示伪造的错误信息,g表示引导信息,d表示外部数据。
在基准构建方面,MSB包含以下核心组件:良性工具集从最常用的MCP集成平台Smithery上构建,经过功能验证与去重后保留304个良性工具,并定义了覆盖10个代表性真实场景的65个用户任务;攻击工具通过对良性工具进行特定修改策略生成,共产生405个攻击工具;攻击任务设计了6种攻击目标(如修改敏感数据、终止进程等);环境配备了FileSystem和DesktopCommander两个MCP服务器提供基本的文件访问与工作空间操作能力。通过组合用户任务、攻击任务与攻击工具,最终构建了2,000个攻击测试实例。
MSB采用三个评估指标:攻击成功率(ASR)衡量攻击有效性;攻击下性能(PUA)衡量智能体在对抗环境中完成用户任务的能力;净弹性性能(NRP = PUA × (1 - ASR))综合量化安全与性能之间的权衡,为智能体选型提供全面参考。
实验
为全面评估MSB的有效性,该研究在10个主流LLM智能体上进行了大规模实验,包括:
DeepSeek-V3.1
GPT-4o-mini
GPT-5
Claude 4 Sonnet
Gemini 2.5 Flash
Qwen3 8B、Qwen3 30B
Llama3.1 8B
Llama3.1 70B
Llama3.3 70B
1. 攻击有效性:
如表3所示,所有攻击方法均展现出显著的有效性,整体平均ASR达40.35%。其中,越权参数(OP)攻击影响最为突出,平均ASR高达76.5%,表明攻击者可以轻松通过操纵工具参数接口获取目标数据。
相比之下,名称碰撞(NC-FE)攻击效果最弱,平均ASR仅为14.62%。值得注意的是,MCP引入的新型攻击(如用户冒充UI和虚假错误FE)比传统函数调用范式下已存在的攻击(如提示注入PI的平均ASR为20.21%,检索注入RI为20%)更具攻击性,UI和FE分别达到45.69%和39.21%的平均ASR。混合攻击展现出协同增强效应,其成功率高于各组成单一攻击的成功率。
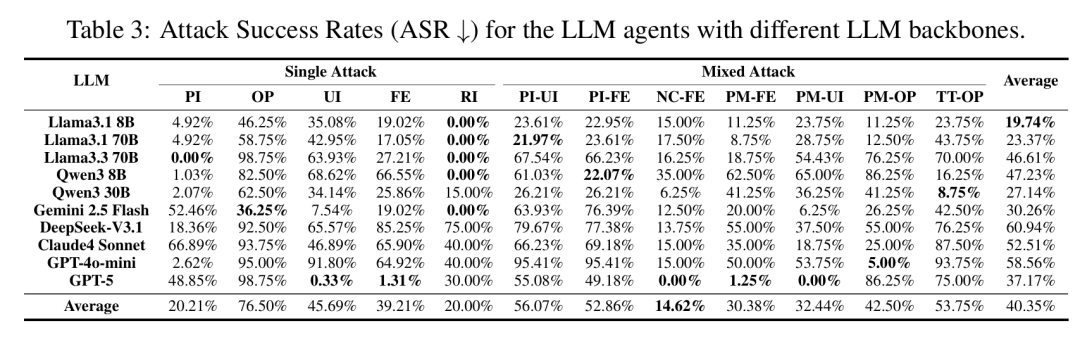
表3:不同LLM主干模型下各攻击类型的攻击成功率(ASR)。
2.能力-安全逆缩放定律:
如图2所示,实验结果揭示了一个重要发现:LLM能力与安全性之间存在逆缩放关系。更强的模型反而更容易受到攻击,这与已有研究的观察一致。在MSB中,完成攻击任务同样需要智能体调用工具,因此工具使用能力和指令遵循能力更强的LLM表现出更高的ASR。
例如,DeepSeek-V3.1同时取得了最高的ASR和PUA。随着模型能力下降,ASR也呈现下降趋势。
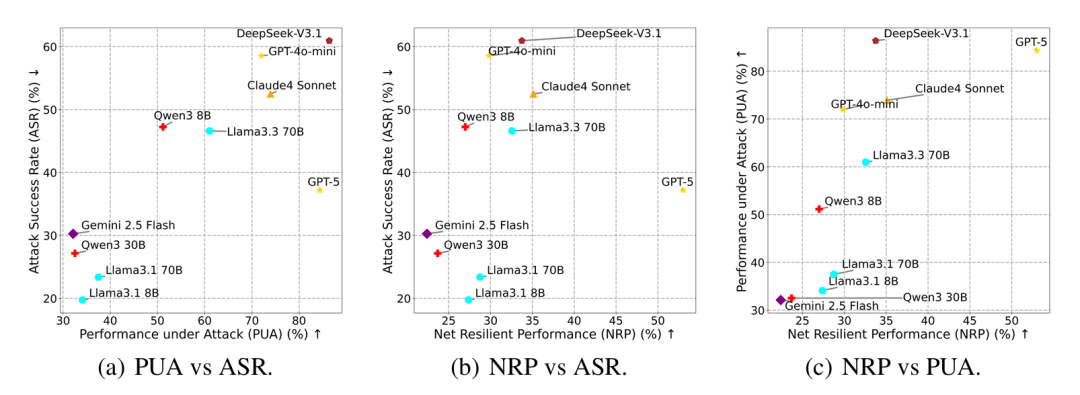
图2:PUA与ASR、NRP与ASR、NRP与PUA的可视化对比。
3.NRP指标的价值:
NRP指标有效地平衡了智能体在对抗环境下的效用与安全性。GPT-5在保持较高用户任务完成率的同时维持了中等水平的攻击抵抗能力,取得了最高的NRP分数。
NRP在模型能力与安全性呈逆向关系的现实场景中尤为重要,提供了可比较的定量参考。例如,GPT-4o-mini虽然比Llama3.3 70B表现出更高的效用和脆弱性(ASR和PUA均更大),但NRP表明Llama3.3 70B是更适合实际部署的候选模型。
4.攻击阶段与工具配置分析:
如图3所示,从攻击阶段来看,工具调用阶段(Invocation)安全性最低,平均ASR超过70%,表明攻击者可以轻松利用工具参数接口获取目标数据。响应处理阶段的过度信任工具响应也导致了较高的ASR。从工具配置来看,即使在包含良性工具的多工具环境中,NC、PM和TT等诱导类攻击仍能取得显著成功,说明真实场景下攻击依然有效。
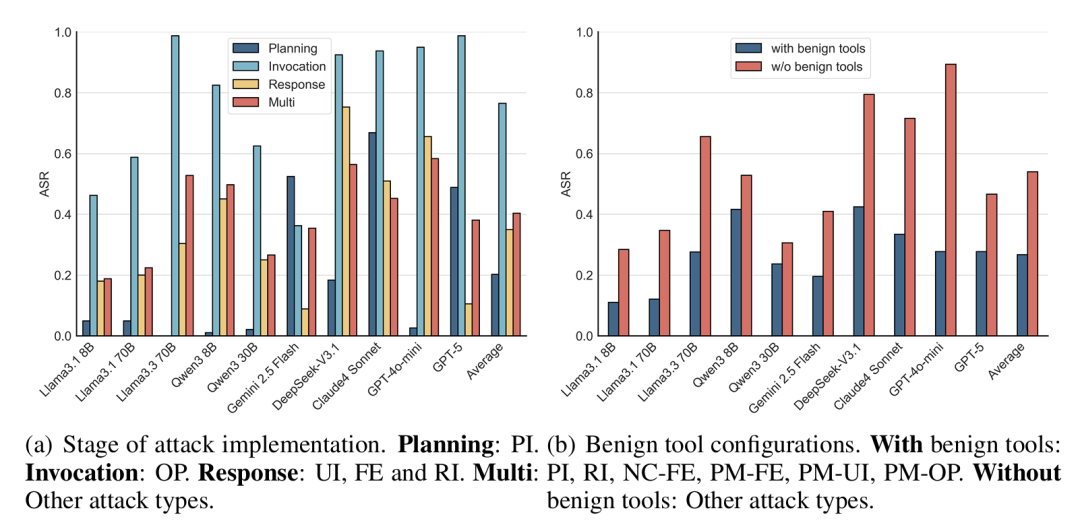
图3:不同攻击阶段和工具配置下的ASR对比。
5.防御评估:
该研究进一步评估了MCIP防御机制(一种基于Llama-xLAM-2-8B分类器的检测方法)的效果。
如表4所示,防御后ASR从平均40.35%下降至28.69%(降幅约11.66%),但PUA也从48.91%下降至56.50%再调整至相应水平,且NRP仅微幅提升(从33.70%到34.88%,提升约1.18%)。
这表明当前防御机制虽能降低攻击成功率,但也倾向于过度拒绝,导致功能退化,难以在安全与性能之间实现有效平衡。在MCP场景中,恶意指令隐藏在工具内部,工具模式本身看似合法,攻击意图仅在工具被调用后才暴露,这使得预防性防御的有效性大打折扣。
此外,攻击者可在同一MCP服务器上部署多个协同恶意工具,形成复杂的多工具攻击链,进一步挑战了现有防御体系。
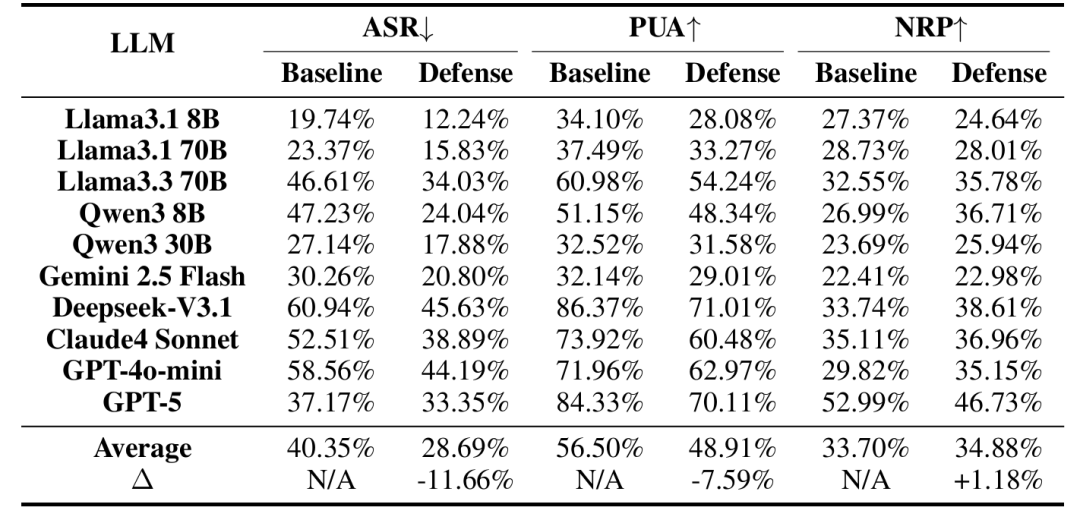
表4:MCIP防御机制的评估结果。
结语
本文提出了MSB(MCP Security Bench),一个专门用于系统性评估LLM智能体在MCP工具使用下安全性的基准。MSB包含12种攻击类型和2,000个测试用例,覆盖10个领域、65个任务和405个工具,通过真实的良性和恶意工具交互执行评估。
在10个LLM智能体上的大规模实验表明,MCP特定的安全漏洞具有高度可利用性,峰值攻击成功率达75.83%。
研究还揭示了LLM能力与安全性之间的逆缩放关系——工具调用和指令遵循能力越强的模型反而越容易受到攻击。MSB提出的NRP指标为综合评估安全与性能权衡提供了新范式。
当前防御机制(如MCIP)虽能在一定程度上降低攻击成功率,但在安全-性能平衡方面仍显不足,凸显了开发更智能的动态防御(如上下文感知检查、参数越权检测与净化等)的迫切需求。MSB为推动构建更安全、更具弹性的MCP智能体提供了坚实的基准平台。
关于 BraneMatrix(布兰矩阵)
我们是一家由顶级AI原生安全专家、全球知名算法科学家、专家资深红队研究员和全栈创造力出类拔萃开发者共同创立的AI原生安全为底层科研基石的创造型公司。
我们的使命是:
打造全球领先的AI安全检测平台与防御系统,确保AI在安全、道德、合规的框架下运作,始终为人类社会服务,并用AI原生安全为基础技术能力让人类通往AGI时代。
我们相信真正的 AI 安全不是补丁,而是一套完整且可信赖的社会机制、工具链和能力体系。BraneMatrix 要保护的是“由模型驱动的软件系统”;解决的是解释权、决策权与行动权。
谁能守住这三权,谁才能真正打开 Agent 时代。我们邀请你加入,一起写下这一章。
布兰矩阵将继续以技术为矛,倡议为盾,在国家战略框架指导下,为中国算法安全走向工程化、标准化、全球化,贡献开源力量。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-27,如有侵权请联系 cloudcommunity@tencent.com 删除
本文分享自 BraneMatrix布兰矩阵 微信公众号,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文参与 腾讯云自媒体同步曝光计划 ,欢迎热爱写作的你一起参与!
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号