Hermes Agent 持久化内存:2 文件、3 级扫描,1,300 tokens 告别重启失忆
原创
Hermes Agent 持久化内存:2 文件、3 级扫描,1,300 tokens 告别重启失忆
原创
运维有术
发布于 2026-05-28 23:35:30
发布于 2026-05-28 23:35:30
Hermes Agent 持久化内存:2 文件、3 级扫描,1,300 tokens 告别重启失忆
🚩 2026 年「术哥无界」系列实战文档 X 篇原创计划 第 123 篇,Hermes Agent 最佳实战「2026」系列第 5 篇
大家好,欢迎来到 术哥无界 | ShugeX | 运维有术。
我是术哥,一名专注于 AI 编程、AI 智能体、Agent Skills、MCP、云原生、AIOps、Milvus 向量数据库的技术实践者与开源布道者!
Talk is cheap, let's explore。无界探索,有术而行。

Hermes Agent 持久化内存架构概览
用 AI Agent 做过复杂任务的人,大概都踩过同一个坑:重启即失忆。
你在会话里花了半小时给它解释项目架构、代码规范、偏好设置,结果关掉终端再打开,它什么都不记得了。更烦人的是,即便在同一个会话里,聊到后面它也会把前面的关键信息忘干净——上下文窗口就那么大,塞满了新内容,老内容自然就被截掉了。
传统方案通常是用向量数据库把历史对话存起来,需要时检索注入上下文。但这么做有个致命问题:成本不可控。 注入多少、检索多少、每次 prompt 多花多少 token,全都靠天收。
Hermes Agent 用了一种完全不同的思路:给 Agent 一个固定大小的笔记本,2 个 Markdown 文件,总共 3,575 字符上限。写满了?合并旧条目。新会话?自动加载。这套方案的核心不是记住更多,而是在有限预算内记住最重要的东西。
说明:本文内容基于 Hermes Agent 源码(NousResearch/hermes-agent)和官方文档(hermes-agent.nousresearch.com)分析整理而成,源码分析基于笔者本地仓库版本,尚未在生产环境中完成全场景验证。文中的配置模板和参数建议仅供参考,实际效果请以你的业务数据和环境测试结果为准。如果有实际使用经验,欢迎在评论区分享交流。
1. 两个文件,3,575 字符:极简的存储模型
Hermes 的持久化内存由两个 Markdown 文件组成,存放在 ~/.hermes/memories/ 目录下:
文件 | 用途 | 字符上限 | 约等于 |
|---|---|---|---|
| Agent 的个人笔记:环境事实、项目约定、工具 quirks、经验教训 | 2,200 字符 | ~800 tokens |
| 用户画像:偏好、沟通风格、期望、工作习惯 | 1,375 字符 | ~500 tokens |
总开销约 1,300 tokens,每个会话固定,和对话内容多少无关。
为什么用字符限制而不是 token 限制?
源码注释写得很直白(memory_tool.py):
"Character limits (not tokens) because char counts are model-independent."
不同模型的 tokenizer 不同,同一段文本在 GPT 和 Claude 上的 token 数可能差不少。但字符数是稳定的——2,200 字符在哪个模型上都一样。这让预算控制在模型切换时也不会失效。
条目分隔和操作方式
内存条目用 §(section sign)分隔,支持多行内容。Agent 通过单个 memory 工具操作,action 参数区分三种操作:
- add:新增条目,触发字符预算检查
- replace:用短子串匹配替换现有条目
- remove:用短子串匹配删除现有条目
replace 和 remove 不需要提供完整的条目原文,只要给出一个能唯一定位到目标条目的短子串就行。如果子串匹配到多个不同条目,工具会报错要求更具体。

Hermes 双文件存储模型
图 1:双文件存储模型——MEMORY.md 和 USER.md 的字符预算分配与操作方式
当内存满了怎么办?
这是设计中最有意思的部分。当 add 操作超过字符限制时,工具不会自动挤掉旧条目。它返回一个错误,附带当前使用量和现有条目列表:
# memory_tool.py 预算检查逻辑(简化)
new_entries = entries + [content]
new_total = len(ENTRY_DELIMITER.join(new_entries))
if new_total > limit:
return {
"success": False,
"error": f"Memory at {current:,}/{limit:,} chars. "
f"Adding this entry ({len(content)} chars) "
f"would exceed the limit. "
f"Replace or remove existing entries first.",
"current_entries": entries,
"usage": f"{current:,}/{limit:,}",
}Agent 被引导走一条策展路径:先读现有条目 → 找出可以合并或删除的旧条目 → 用 replace 合并 → 再 add 新条目。这个过程本质上是在逼 Agent 定期整理记忆,保持信息密度。
2. 冻结快照:为什么修改内存不会让 KV Cache 失效?
Hermes 内存系统最精巧的设计,是 Frozen Snapshot Pattern(冻结快照模式)。
会话生命周期中的快照机制
会话启动
├── load_from_disk()
│ ├── 读取 MEMORY.md → live state
│ ├── 读取 USER.md → live state
│ ├── 安全扫描 → sanitized entries
│ └── 生成 _system_prompt_snapshot(冻结,不可变)
│
│ System Prompt 注入
│ format_for_system_prompt() → 返回 frozen snapshot
│
│ 会话中途写入
│ add/replace/remove → 更新 live state + 写入磁盘
│ 但 system prompt 中的 snapshot 不变
│
│ 下一个会话
│ load_from_disk() → 新的 frozen snapshot为什么要冻结?
源码注释(memory_tool.py 第 11-14 行)给出了明确的原因:
"Mid-session writes update files on disk immediately (durable) but do NOT change the system prompt — this preserves the prefix cache for the entire session."
背景知识:大模型推理时,system prompt 部分(前缀)会被缓存成 KV Cache。如果前缀不变,后续每个 prompt 都可以复用这份缓存,省掉重复计算。但只要前缀改了一个字,整个缓存就废了。
如果每次修改内存都更新 system prompt,那 Agent 每记住一个新东西,就等于把之前的缓存全部作废。Token 成本会随着会话推进越来越高。冻结快照把这个问题从源头解决了——整个会话期间,前缀始终不变。
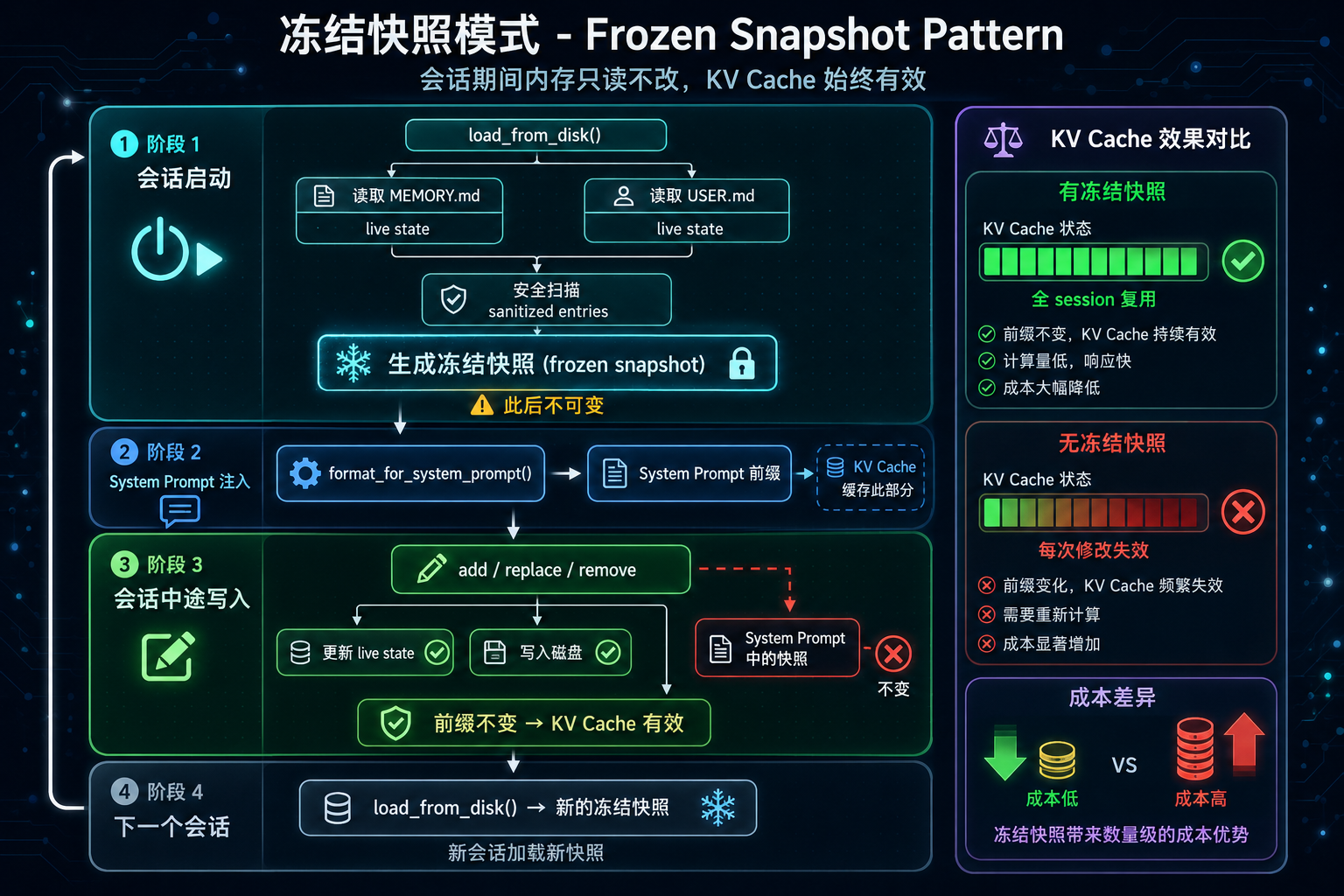
冻结快照模式流程图
图 2:冻结快照模式的完整生命周期——从加载到冻结到下一会话
系统提示中的内存注入格式
内存注入到 system prompt 时,格式长这样:
══════════════════════════════════════════════
MEMORY (your personal notes) [67% — 1,474/2,200 chars]
══════════════════════════════════════════════
User's project is a Rust web service at ~/code/myapi using Axum + SQLx
§
This machine runs Ubuntu 22.04, has Docker and Podman installed
§
User prefers concise responses, dislikes verbose explanationsHeader 里有使用率百分比和字符计数。Agent 能感知到我已经用了 67% 的空间,在做写入决策时有据可依。
这比无限制地往上下文里塞信息要好得多——Agent 知道预算有限,会更有选择性地记忆。
3. 三级安全扫描 + 外部漂移检测
持久化内存天然有个安全隐患:存下来的东西,每个新会话都会被加载到 system prompt 里。 如果有人在 MEMORY.md 里注入了恶意指令,那等于在每个会话里都种下了后门。
Hermes 用两级防御来应对这个问题。
三级威胁扫描
威胁模式定义在 tools/threat_patterns.py 中,分三个 scope:
范围 | 适用场景 | 检测内容 |
|---|---|---|
| 所有文本 | 经典注入 + 数据泄露 |
| 上下文文件 + 内存 + 工具结果 |
|
| 内存写入 + Skill 安装 |
|
内存写入使用最严格的 strict 级别。扫描发生在两个时间点:
- 写入时:每次
add/replace操作前扫描 - 加载时:
load_from_disk()时扫描,命中条目在快照中替换为[BLOCKED: ...]占位符
注意:加载时扫描不会删除原始条目,只是在新会话的快照中屏蔽。用户可以查看和手动清理被标记的条目。这个设计比较克制——误报时不会丢数据。
外部漂移检测(External Drift Detection)
这是一个比较独特的安全机制,检测 MEMORY.md / USER.md 是否被 Hermes 之外的程序修改过——比如 patch tool、shell append、手动编辑、或者另一个并发会话。
检测逻辑(memory_tool.py → _detect_external_drift())基于两个信号:
- Round-trip mismatch:把文件内容解析成条目再序列化回去,和原文件对比。不一致说明有人绕过 Hermes 的格式规范改了文件
- Entry-size overflow:单个条目超过整个 store 的字符限制。正常操作下不会出现这种情况
检测到漂移时,Hermes 会:
- 备份当前文件为
.bak.{timestamp} - 拒绝修改操作,返回错误
- 要求用户手动解决漂移后重试
这个机制在并发场景下尤其重要。两个会话同时往 MEMORY.md 里写东西,没有漂移检测的话,后写的会覆盖先写的,而且两个会话的 live state 都和磁盘不一致了。
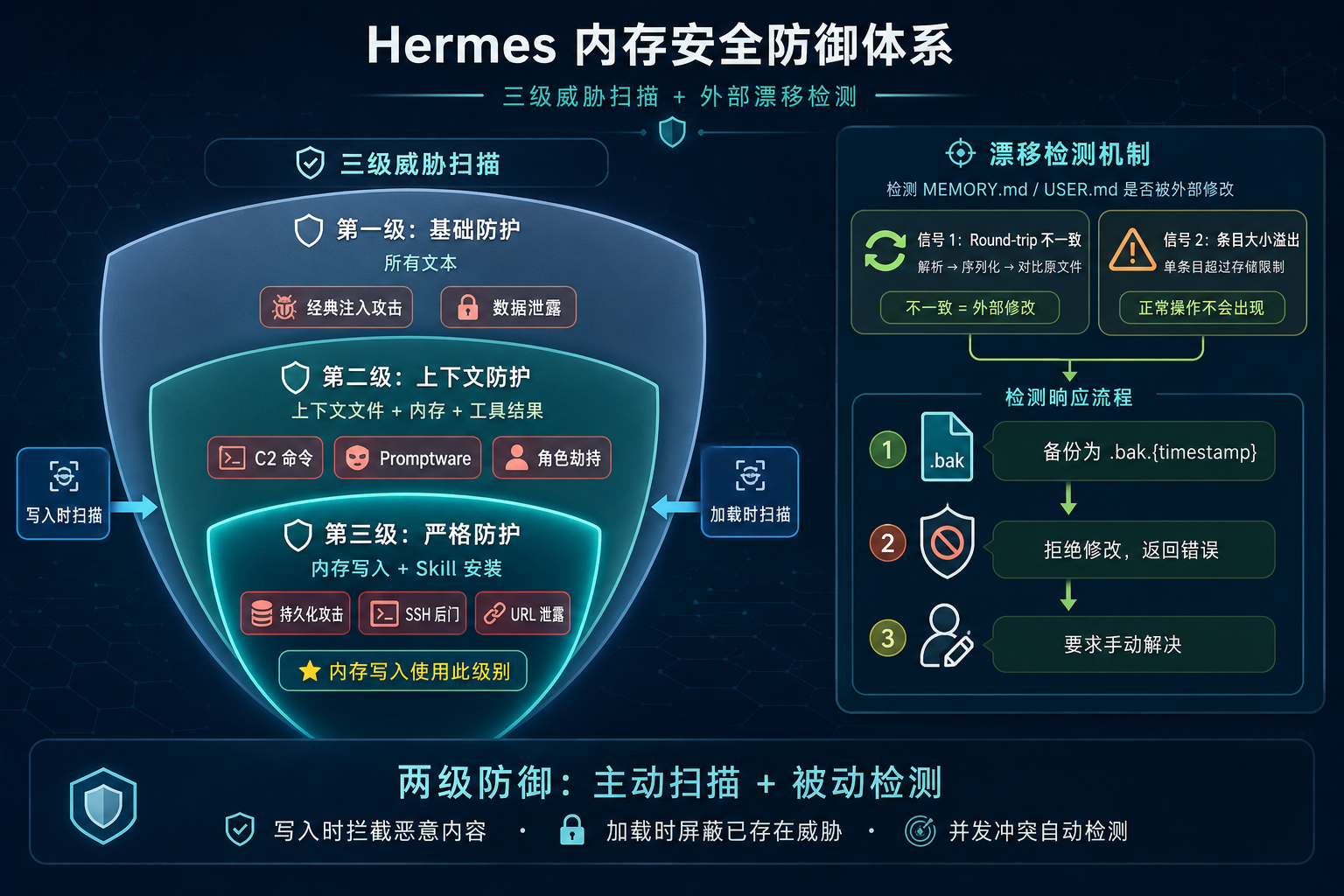
安全架构图
图 3:三级威胁扫描 + 外部漂移检测——Hermes 内存的双层安全防御体系
4. 跨会话召回:持久化内存 + FTS5 全文搜索
持久化内存和会话搜索是互补关系,不是替代关系。
维度 | Persistent Memory | Session Search |
|---|---|---|
容量 | ~1,300 tokens(固定) | 无限(所有历史会话) |
速度 | 即时(在 system prompt 中) | ~20ms FTS5 查询 |
Token 成本 | 每个 prompt 都有 | 按需(搜索时才消耗) |
管理方式 | Agent 手动策展 | 自动(所有会话自动存入 SQLite) |
信息类型 | 精炼的关键事实 | 原始对话全文 |
Session Search 的三种模式
所有 CLI 和消息会话自动存入 ~/.hermes/state.db(SQLite + FTS5 索引)。Agent 通过 session_search 工具调用:
模式 | 参数 | 用途 |
|---|---|---|
Discovery |
| FTS5 搜索 + 会话 lineage 去重 + top N 结果 |
Scroll |
| 按锚点上下滚动浏览 |
Browse | 无参数 | 返回最近的会话列表 |
两个有意思的细节:
- 零 LLM 成本:搜索结果直接返回数据库中的原始消息,不经过 LLM 摘要。省了一次模型调用
- Lineage 去重:通过
parent_session_id链追踪到根会话,排除当前会话链路中已有的消息。避免搜出自己说过的话
Memory Nudge:逼 Agent 定期回顾
Hermes 还有一个容易被忽略的机制——Memory Nudge(内存审查提醒)。当连续 N 个用户回合没有使用 memory 工具时,系统会注入一个提醒,引导 Agent 检查是否有值得持久化的事实。
# conversation_loop.py(简化)
if (agent._memory_nudge_interval > 0
and "memory" in agent.valid_tool_names
and agent._memory_store):
agent._turns_since_memory += 1
if agent._turns_since_memory >= agent._memory_nudge_interval:
_should_review_memory = True
agent._turns_since_memory = 0会话恢复时,通过取模保持原始节奏(prior_user_turns % nudge_interval),避免恰好在边界上重复触发。这个细节说明设计者对用户体验的考虑比较到位。
5. 实战配置:从安装到生产环境
安装与初始化
# 安装 Hermes Agent
curl -fsSL https://raw.githubusercontent.com/NousResearch/hermes-agent/main/scripts/install.sh | bash
# 启动交互式 CLI
hermes
# 配置模型(按提示操作)
hermes model
# 配置工具
hermes tools
# 完整设置向导(推荐新手使用)
hermes setup
# 环境诊断
hermes doctor内存目录结构
~/.hermes/
├── memories/
│ ├── MEMORY.md # Agent 个人笔记
│ ├── USER.md # 用户画像
│ ├── MEMORY.md.lock # 文件锁
│ └── USER.md.lock # 文件锁
├── state.db # SQLite 会话数据库(FTS5)
├── config.yaml # 全局配置
├── SOUL.md # Agent 人格定义
└── plugins/ # 用户安装的插件关键配置项
# ~/.hermes/config.yaml
memory:
memory_enabled: true # 启用 MEMORY.md
user_profile_enabled: true # 启用 USER.md
memory_char_limit: 2200 # MEMORY.md 字符上限
user_char_limit: 1375 # USER.md 字符上限
provider: "" # 外部 memory provider,空字符串表示仅内置默认值不需要改动就能跑起来。memory_char_limit 和 user_char_limit 可以调大,但要想清楚——字符预算越大,每个 prompt 的固定 token 开销就越高。
外部 Memory Provider
Hermes 支持 8 种外部 Memory Provider 作为内置内存的补充:
Provider | 特点 |
|---|---|
Honcho | 方言式用户建模、知识图谱 |
OpenViking | 语义搜索 |
Mem0 | 自动事实提取 |
Hindsight | 跨会话用户建模 |
Holographic | — |
RetainDB | — |
ByteRover | — |
Supermemory | Cloudflare Workers 上的长期记忆 |
几个要点:
- 同一时间只允许激活一个外部 Provider(
MemoryManager强制执行) - 外部 Provider 不会替代内置内存,而是作为补充
- 配置方式:
hermes memory setup(交互式选择)或直接修改config.yaml
选择建议:如果你只需要跨会话记住关键事实,内置内存已经够用了。如果需要语义搜索或更复杂的用户建模能力,再考虑外接 Provider。
6. 生产级最佳实践
多项目环境下的隔离策略
Hermes 支持通过 profile 覆盖内存目录路径(hermes_constants.get_hermes_home() 动态解析)。如果你在多个项目间切换,建议为每个项目设置独立的 profile,避免不同项目的记忆互相污染。
内存污染是真实会发生的:Agent 在 A 项目里记住的用户偏好简洁回复,可能会影响它在 B 项目里的行为。如果你 A 项目是 Rust 后端、B 项目是前端,两边的代码规范、工具链、测试习惯都不同,混在一起只会让 Agent 的记忆变得不可用。
防记忆污染
几个实用建议:
- 定期审查内存条目:直接查看
~/.hermes/memories/MEMORY.md,确认里面没有过时或矛盾的信息 - 利用字符预算约束:2,200 字符的限制是特性,不是 bug。它天然阻止了内存无限膨胀
- 关注使用率百分比:system prompt header 里的百分比是 Agent 策展行为的信号。超过 80% 时主动合并条目
- 善用漂移检测:如果看到
.bak.{timestamp}备份文件出现,说明有外部程序改过内存文件,需要排查原因
容量管理的实操建议
当内存接近上限时,Agent 的策展路径是:读 → 评估 → 合并/删除 → 再添加。你可以通过以下方式辅助这个过程:
- 在对话中明确告诉 Agent:帮我整理一下 MEMORY.md,把过时的条目清理掉
- 定期检查
MEMORY.md,手动合并相关条目 - 如果发现 Agent 频繁因为预算不足无法添加新条目,说明可能需要提高
memory_char_limit
系统提示的三层缓存结构
Hermes 的 system prompt 分三层组装,和内存的冻结快照紧密配合:
层 | 内容 | 缓存行为 |
|---|---|---|
stable | Agent 身份、工具指南、Skill 索引 | 跨会话稳定 |
context | 上下文文件(AGENTS.md 等) | 会话级稳定 |
volatile | Memory + USER profile + 时间戳 | 每次会话可能变化 |
内存属于 volatile 层,但因为在会话期间冻结,所以在这个会话内也是稳定的。三层结构从稳定到不稳定排列,最大化了 KV Cache 的复用率。
你在项目中用过类似的 Agent 记忆方案吗?和 Hermes 的字符预算思路比,你更倾向哪种?欢迎在评论区聊聊。
7. 和传统方案对比:字符预算 vs 向量注入
把 Hermes 的方案和传统向量数据库 + 上下文注入放在一起看,差异很明显:
维度 | 传统向量注入 | Hermes 字符预算 |
|---|---|---|
Token 开销 | 不确定(检索量可变) | 固定 ~1,300 tokens/会话 |
成本可预测性 | 难以预算 | 精确到字符 |
遗忘风险 | 高(上下文膨胀后被截断) | 低(冻结快照,每会话始终可见) |
信息质量 | 取决于检索质量 | Agent 手动策展,密度高 |
跨会话搜索 | 需要额外向量搜索 | 内置 FTS5 session search |
安全防护 | 通常无注入防护 | 三级威胁扫描 + 外部漂移检测 |
并发安全 | 通常无保护 | 原子写入 + 文件锁 + 漂移检测 |

方案对比图
图 4:字符预算 vs 向量注入——两种 Agent 记忆方案的核心差异
说实话,两种方案不是简单的谁好谁坏。
向量注入适合记忆量大、不需要精确预算的场景。比如客服 Agent,历史对话可能有几千条,检索 top-k 注入就行,不需要每条都精确管理。
Hermes 的字符预算适合需要精确控制成本的场景。比如长时间运行的个人 Agent,你知道每个 prompt 会花多少 token,可以精确计算月度开销。而且因为预算有限,Agent 会被迫只保留高价值信息,记忆质量反而更高。
总结
Hermes Agent 的持久化内存系统,核心思路可以概括为三句话:
用固定预算代替无限制增长。 2 个文件、3,575 字符上限,每个会话固定 ~1,300 tokens。成本可控,预算可预测。
用冻结快照保持缓存稳定。 会话期间内存只读不改,KV Cache 从头到尾有效。新会话再加载新快照。
用安全机制保护持久化入口。 三级威胁扫描防止注入攻击,外部漂移检测防止并发冲突,原子写入保证数据完整性。
36 氪报道中有个社区比喻流传很广:OpenClaw 负责干活,Hermes 负责动脑。 这个说法虽然简化了两个项目的能力边界,但确实点出了 Hermes 的差异化——它不只是能干活,而是能学会干活。
GitHub 上两个月涨到 7.1 万 Star,峰值一天涨 6,400 颗星。社区对越用越聪明这个特性的认可度很高。不过也要客观看待:企业用户普遍还在观望,稳定性和中文支持是主要顾虑。项目目前才 v0.14.0,离生产级成熟还有距离。
如果你的场景是个人开发或小团队协作,想试试一个能记住事情的 AI Agent,Hermes 值得花一个下午研究。建议先把内置内存跑通,理解字符预算和冻结快照的工作方式,再决定要不要外接 Memory Provider。
相关资源
官方文档:https://hermes-agent.nousresearch.com/docs/user-guide/features/memory
GitHub 仓库:https://github.com/NousResearch/hermes-agent
好啦,谢谢你观看我的文章,如果喜欢可以点赞转发给需要的朋友,我们下一期再见!敬请期待!
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号