Pinecone Nexus 说要"编译知识"?我已经跑了两个月了

Pinecone Nexus 说要"编译知识"?我已经跑了两个月了

烟雨平生
发布于 2026-05-20 13:46:58
发布于 2026-05-20 13:46:58
近期 Pinecone 正式推出 Nexus,行业趋势已然明晰:AI 知识库正从检索文本片段,全面迈向预编译结构化知识。
巧了,这事我已经做了两个月,而且用真实数据验证了效果。
Nexus 说的"编译知识"到底是什么
Pinecone Nexus 的核心理念是把知识处理从运行时前移到构建时:
传统 RAG: 用户提问 → 临时搜索 chunk → 临时拼上下文 → 临时回答 Nexus 理念: 企业数据 → 提前结构化 → 编译 Knowledge Artifact → Agent 直接用
Karpathy 提出的 LLM Wiki 也是这个方向:让 LLM 持续读取资料、维护一个结构化 Wiki,里面有实体页、主题页、交叉引用和综合结论。
听起来很前沿?是的。但也有人讲得很实在:
编译知识是一个美好的愿望,Nexus 还很不成熟,更像是一种新技术范式的尝试
问题来了:有没有人已经把这个理念做出来了?
有。ExoMind 就是一个跑了两月的"编译知识"引擎
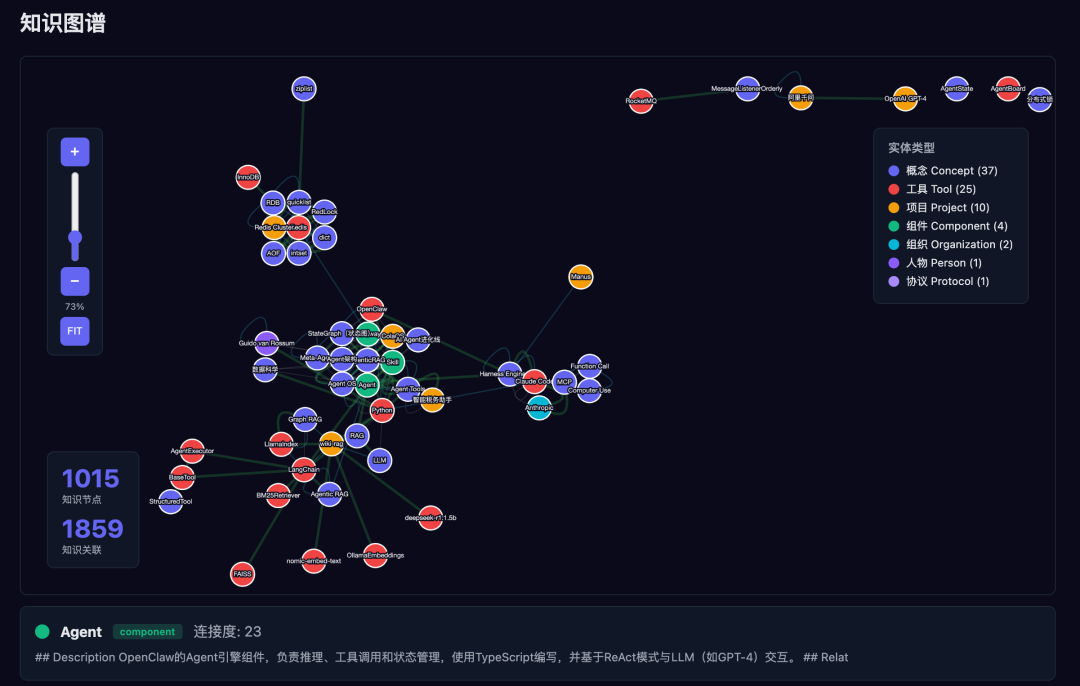
ExoMind(ExoMindManager)是我开发的一个个人知识复利飞轮系统。它的核心理念和 Nexus、LLM Wiki 高度一致,但更务实——不追求企业级完美,而是先让个人知识真正"复利增长"。
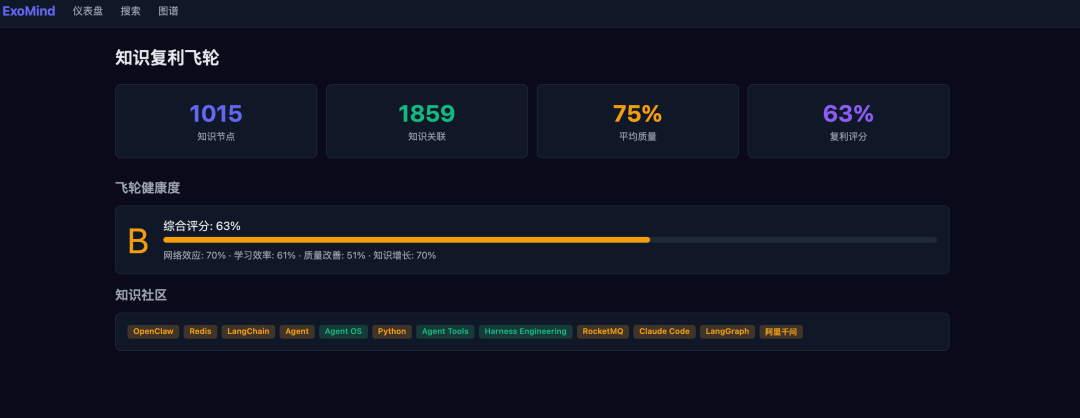
▪ 架构对比
维度 | 传统 RAG | Nexus(概念) | ExoMind(已实现) |
|---|---|---|---|
知识形态 | Chunk 片段 | Knowledge Artifact | 结构化 Wiki 页面 |
知识组织 | 向量索引 | Context Compiler | 知识图谱 + 实体页 |
检索方式 | TopK 召回 | Composable Retriever | BM25 + 向量 + LLM 精排 |
知识演进 | 无 | 不明确 | 自动演化 + 质量追踪 |
跨域发现 | 无 | 不明确 | 社区检测 + 桥接综合 |
▪ 它是怎么"编译"知识的
ExoMind 的知识编译流程:
原始文章/笔记 ↓ LLM 提取实体、关系、概念(ingest) ↓ 自动生成结构化 Wiki 页面(entities/, concepts/, summaries/) ↓ 构建知识图谱(节点 + 边 + 别名) ↓ 持续演化:合并重复、更新关系、质量评估 ↓ 搜索时:BM25 粗排 → LLM 精排 → 语义扩展 → 结构化回答
每一步都不是"临时拼凑",而是提前编译好的结构化知识。
两个月跑了多少数据?
实话说,我的数据不算大,但足够验证理念:
知识页面:2,361 页 ├── 实体页:1,014 页 ├── 概念页:1,061 页 ├── 摘要页:256 页 ├── 综合页:5 页(跨域综合) └── QA 页:3 页 知识图谱: ├── 节点:1,200+ ├── 自动检测社区:109 个 └── 跨域桥接节点:10+ 个
飞轮健康度:
综合评分:87%(A级) 7天知识注入:27 条 7天主动查询:19 次 注入→查询转化率:33% 质量覆盖率:76%(770 页有评分) 知识演化:34 次自动合并/更新
几个"编译知识"的真实效果
▪ 1. LLM 搜索重排序:从词频匹配到语义理解
传统 BM25 搜 "Redis 持久化",结果可能是"Redis 安装指南"排在前面(因为"Redis"这个词出现频率更高)。
ExoMind 用 LLM 做精排后:
$ exo search --rerank "Redis 持久化" 搜索结果(LLM 精排): 1. Redis持久化详解(danxin笔记) 相关度: 35.88 2. 持久化(概念页) 相关度: 51.28 3. Redis为什么这么快(系列文章) 相关度: 44.07 4. 状态持久化(概念关联) 相关度: 45.00
LLM 理解了"持久化"是一个概念,把相关主题排到了前面,而不是简单匹配关键词。
▪ 2. 跨域知识综合:发现你看不见的关联
Nexus 讲的"编译知识"一个核心能力是跨领域关联发现。ExoMind 已经在做:
$ exo communities 知识社区(109 个): concept (Redis) 大小: 24 凝聚度: 33% concept (LangChain) 大小: 31 凝聚度: 27% concept (RocketMQ) 大小: 25 凝聚度: 23% concept (Claude Code) 大小: 18 凝聚度: 33% ... 结构缺口(10 个): concept (OpenClaw) ↔ project (阿里千问) 缺口: 100% concept (OpenClaw) ↔ tool (Auth Service) 缺口: 100%
更厉害的是跨域综合:
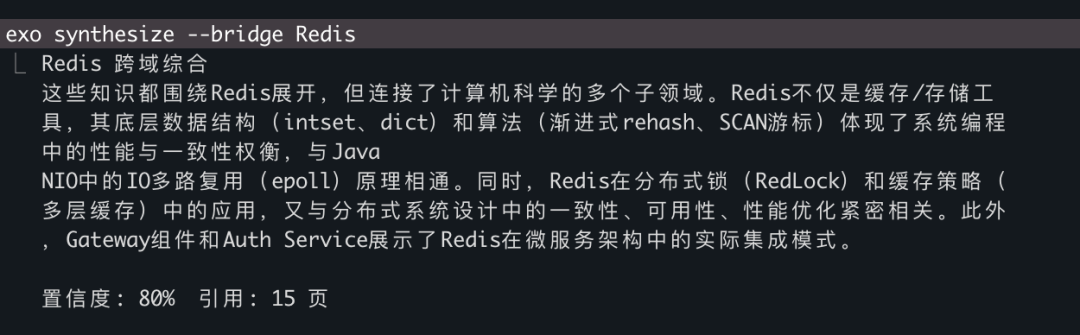
这不是从文档里搜出来的片段,而是 LLM 基于 15 个相关页面的内容编译出来的新洞察。
▪ 3. 质量飞轮:从 2% 覆盖到 76%
传统知识库一个致命问题:你不知道知识质量如何。
ExoMind 的质量飞轮:
Step 1:结构化评分(连接数、字数、标签数)→ 覆盖率 2% Step 2:LLM 批量评估(每 tick 20 页) → 覆盖率 76% Step 3:低质量页面自动生成追问 → 主动学习闭环
$ exo ask 正在分析知识缺口,生成追问... 发现 5 个值得深入的知识领域: 1. [低质量] OpenClaw Agent 框架(评分: 0.12) → OpenClaw 的任务拆解机制与 LangGraph 有何本质区别? 2. [缺失关联] Redis 与 Kafka 都涉及分布式场景 → Redis Stream 和 Kafka 在消息语义上有什么差异? 3. ...
系统主动告诉你哪些知识薄弱,并生成具体的追问帮你补全。
▪ 4. 作为 AI Agent 的知识引擎
Nexus 要做的是 Agent Knowledge Infrastructure。ExoMind 已经实现了 MCP Server,任何支持 MCP 协议的 AI Agent 可以直接访问知识库:
19 个 MCP 工具: search - 混合搜索(BM25 + 向量 + LLM 精排) query - 自然语言问答 ingest - 知识注入 get_relations - 关系查询 detect_communities - 社区检测 cross_domain_synthesis - 跨域综合 ...
Claude Code、Cursor、Windsurf 等 Agent 可以直接调用这些工具,不需要知道底层是 BM25 还是向量检索还是 LLM 精排——Agent 只管查,知识引擎负责编译和检索。
和 Nexus 的差异
坦诚讲差异:
维度 | Nexus | ExoMind |
|---|---|---|
定位 | 企业 Agent 知识基础设施 | 个人知识复利飞轮 |
规模 | 企业级(多用户、权限、RBAC) | 个人级(单用户) |
数据源 | Salesforce/Slack/Jira 等 | Markdown 文章/笔记 |
成熟度 | 概念 + 早期案例 | 开源,两个月实跑数据 |
知识编译 | 黑盒(平台控制) | 白盒(你控制每一步) |
价格 | 商业产品 | 开源免费 |
核心差异:Nexus 想做你的知识基础设施,ExoMind 想做你的第二大脑。
"多数企业做不了 Nexus"——但个人可以
很多企业连最基础的知识治理都没做好,资料散落在飞书文档、企业微信、PDF、PPT…… 如果企业连"文档在哪、哪个是最新版"都说不清,那就算给你 Nexus,你也很难用好。
这话说得非常对。企业做知识治理的门槛很高,但个人做知识管理的门槛很低。
你不需要:
- 不需要统一 6 个部门的数据格式
- 不需要搞 RBAC 权限体系
- 不需要等数据治理委员会审批
你只需要:
1. 把你读过的文章、学过的知识、踩过的坑丢进去
2. 系统自动编译成结构化知识
3. 下次需要的时候,搜一下就能找到——而且带着上下文和关联
两个月,2,361 页知识,87% 飞轮健康度。
这不是概念,是跑出来的数据。
如何开始
如果你用 Claude Code / Cursor 等 AI 工具,ExoMind 提供了 MCP Server,配置后 AI 可以直接帮你管理知识库——不用切换工具,AI 自动帮你摄入和检索知识。
Pinecone 用 Nexus 讲了一个好故事:AI 知识库要从检索走向编译。
但故事归故事,编译知识的理念不需要等 Nexus 成熟才能用。
ExoMind 已经在个人知识管理的场景下验证了这个方向:
提前结构化、提前消歧、提前建关联、提前评估质量——让知识的每一次使用都不是从零开始。
知识复利,从今天开始。
ExoMind 项目正在准备开源,感兴趣的同学可以关注后续动态。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-16,如有侵权请联系 cloudcommunity@tencent.com 删除
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号