【零基础学java】Set系列集合


前言 无序:存取顺序不一致 不重复:可以去除重复 无索引:没有带索引的方法,所以不能使用普通for循环遍历,也不能通过索引来获取元素 Set集合是一个接口,不能直接创建对象,要创建他的实现类对象
Set集合的实现类
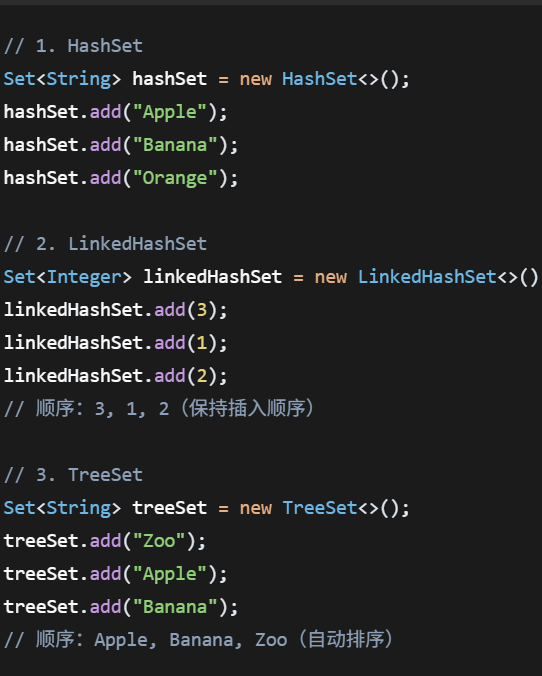
HashSet
HashSet底层原理:底层采取哈希表存储数据,哈希表是一种对于增删改查数据性能都较好的结构 哈希表的组成,数组加链表加红黑树
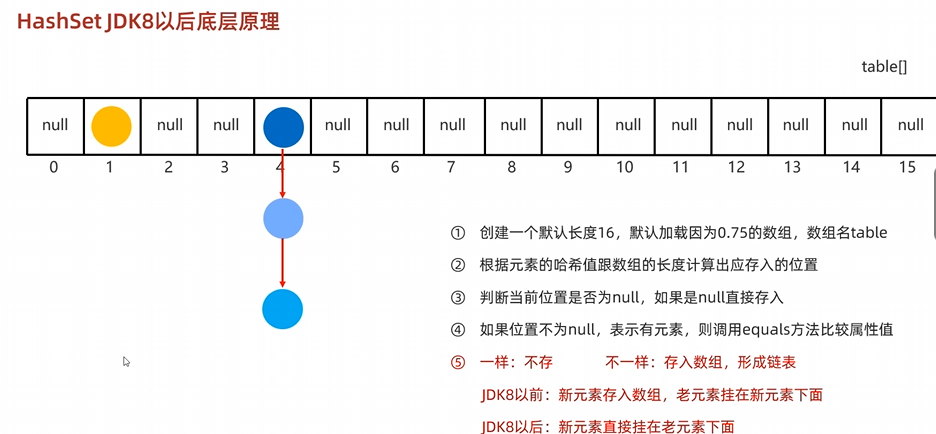
哈希值:根据hashCode方法算出来的int类型整数,该方法定义在Object类中,所有对象都可以调用,默认使用地址值进行计算,一般情况下,会重写hashCode方法,利用对象的内部属性值进行计算哈希值
对象的哈希值特点:如果没有重写hashCode方法,不同对象计算出的哈希值是不同的,如果已经重写了hashCode方法(在标准javabean中,ALT+insert,选equalsandhashcode),不同的对象只要属性值相同,计算出的哈希值就是一样的,小部分情况下,不同的属性值或者不同的地址值计算出来的哈希值也有可能一样
重写hashCode的目的:是我们希望根据属性值去计算哈希值 重写equals方法的目的:是我们希望在比较时,比的也是对象的属性值 HashSet是利用什么机制保证数据去重呢:利用HashCode方法得到哈希值,哈希值去确定当前元素添加在数组的位置,然后调用equals方法去比较对象内部的属性值是否一样
上述是具体的调用方法
LinkHsahSet
LinkeHashSet底层原理 :有序,不重复,无索引,这里的有序指的是保证存储和取出的元素顺序一致 底层数据结构依然是哈希表,只是每个元素又额外的多了一个双链表的机制记录存储的顺序
TreeSet
底层是红黑树 排序规则


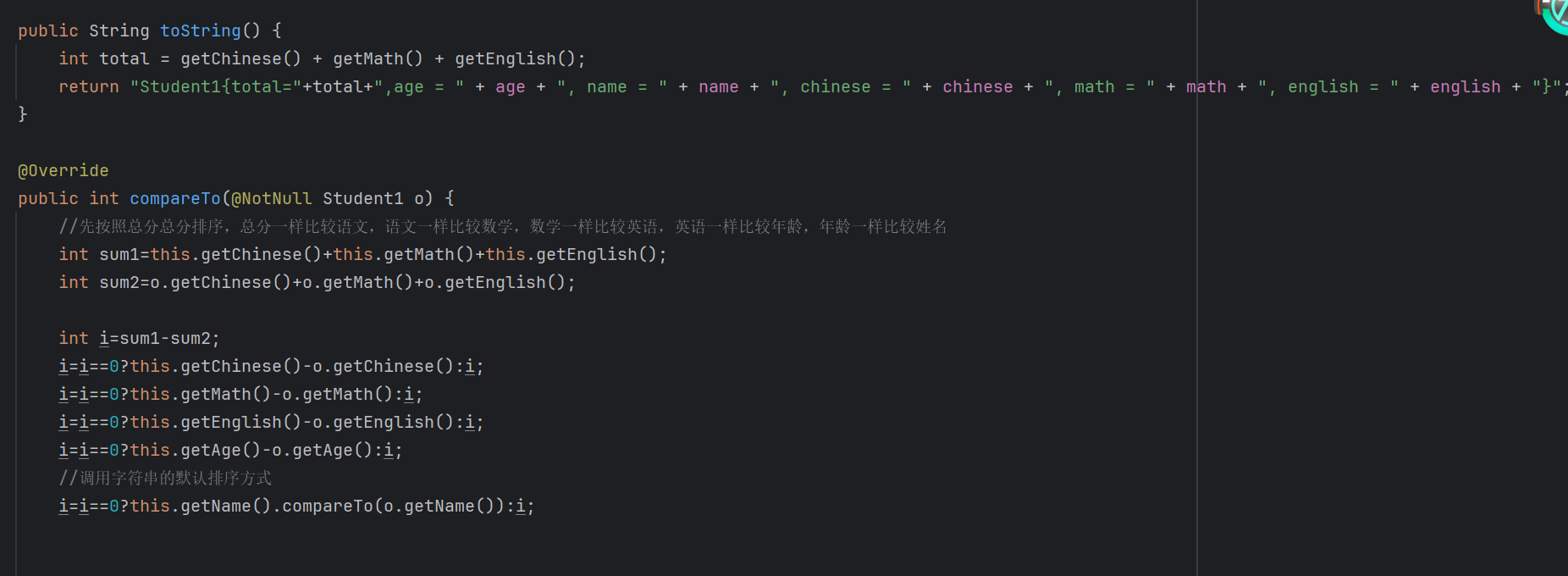
实例:在学生类中,添加了几个学生对象,想要按年龄的升序进行排序 在javabean中,我们可以写 return this.getAge()-0.getAge();
解释:this表示当前要添加的元素,o表示已经在红黑树存在的元素,返回值:负数,当前要添加的元素是小的,正数,认为要添加的元素是大的,存右边,0认为要添加的元素已经存在,舍弃

具体实例:
排序 第一种:默认排序 在javabean中implement Comparable这个接口,加上泛型,重写抽象方法,并在重写的方法中指定规则
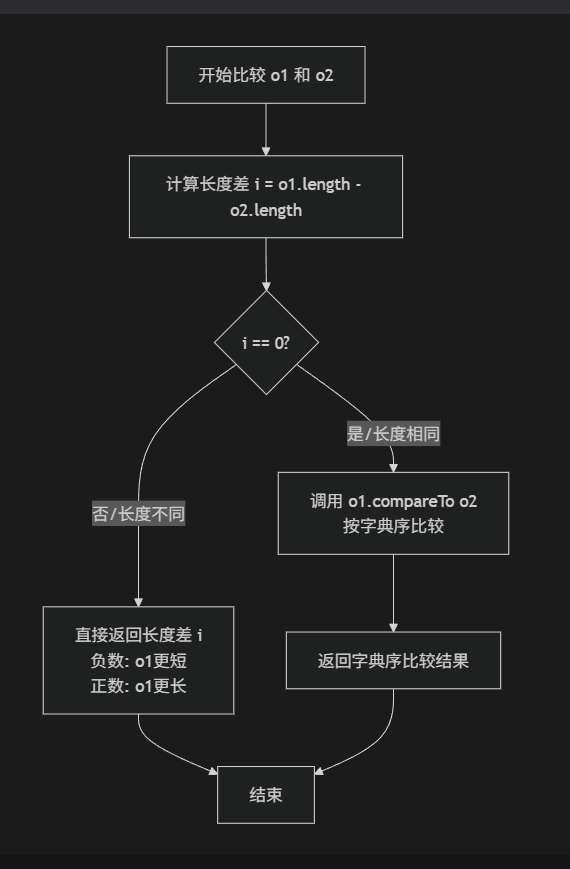
第二种:比较器排序 在创建TreeSet对象的时候,在小括号中传递比较器的对象 TreeSet<Student1> ts=new TreeSet<>();
逻辑思路
(在javabean中,toString实现了可视化,而不是地址值,最后打印出来的是属性值 )
集合的选择

本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2026-04-22,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号