学术论文AI味超标!Science子刊最新研究:至少13.5%生物医学论文有AI痕迹,部分领域超40%

学术论文AI味超标!Science子刊最新研究:至少13.5%生物医学论文有AI痕迹,部分领域超40%

不二小段
发布于 2026-04-09 16:21:06
发布于 2026-04-09 16:21:06
一场由大语言模型引发的「写作革命」,正以前所未有的速度和规模,席卷全球学术界。
你是否曾怀疑,那些读起来措辞华丽、句式精巧,但又似乎缺少了一丝「人味」的论文,背后是否有 AI 的身影?
现在,来自德国图宾根大学等机构的研究人员,在顶级期刊 Science Advances 上发表的一篇重磅论文,实锤了 AI 代写学术论文的现象。
这项研究没有依赖任何黑箱的 AI 检测器,而是开创了一种名为「超额词汇」的分析方法。通过对 2010 年至 2024 年间超过 1500 万篇 PubMed 生物医学论文摘要的深入挖掘,得出了一个惊人结论:
到 2024 年,至少 13.5% 的生物医学论文摘要,都经过了 LLM 的处理。
这还只是一个保守的「下限」。在某些特定领域和地区,这个比例甚至飙升至 40% 以上。
更令人震撼的是,LLM 对科学写作的影响力,无论在性质还是数量上,都已经超越了像新冠疫情这样的全球性重大事件。
那么,研究人员究竟是如何从海量文本中找到 LLM 留下的「指纹」的?这些「AI 味」十足的词汇又有哪些特征?这场变革对科学的未来意味着什么?
让我们一起「delve into」(深入探究)这项研究的「intricate」(错综复杂)之处。
学术界的「法医语言学」:超额词汇分析法
要追踪 LLM 在学术写作中的足迹,并非易事。
过去的方法,通常依赖于训练一个「LLM 检测器」模型。 这类方法有两个天然的缺陷:
- • 首先,它们需要一个「标准答案」数据集,包含纯人类写作和 AI 生成的文本,但我们无从知晓现实世界中的科学家们究竟在使用哪个 LLM、如何使用,这使得训练数据本身就可能存在偏差。
- • 其次,这些检测器本身就是个「黑箱」,我们很难理解它们做出判断的具体依据,也就无法洞察 LLM 对写作风格的深层影响。
为此,由 Dmitry Kobak 领导的研究团队另辟蹊径,其灵感来源非常巧妙——流行病学中的「超额死亡率」分析。
在新冠期间,为了评估疫情的真实影响,公共卫生专家会计算一个「超额死亡人数」。他们首先根据往年(疫情前)的数据,预测出在没有疫情的情况下,某个地区「预期」会有多少人死亡;然后,将这个预期值与「实际」死亡人数进行比较。两者之差,就是由疫情导致的「超额死亡」。
Kobak 和他的同事们将这个思路完美地「移植」到了语言学分析上。
他们假设,在没有 ChatGPT 这类工具的「正常世界」里,学术词汇的使用频率会遵循一个相对平稳的趋势。于是,他们利用 2021 年和 2022 年(ChatGPT 发布前)的数据,对每个单词的频率变化趋势进行线性外推,从而预测出它在 2024 年的「预期频率」(expected frequency)。
然后,他们将这个「预期频率」与 2024 年的「观测频率」(empirical frequency)进行比较。两者之间的差距,就是「超额频率」。
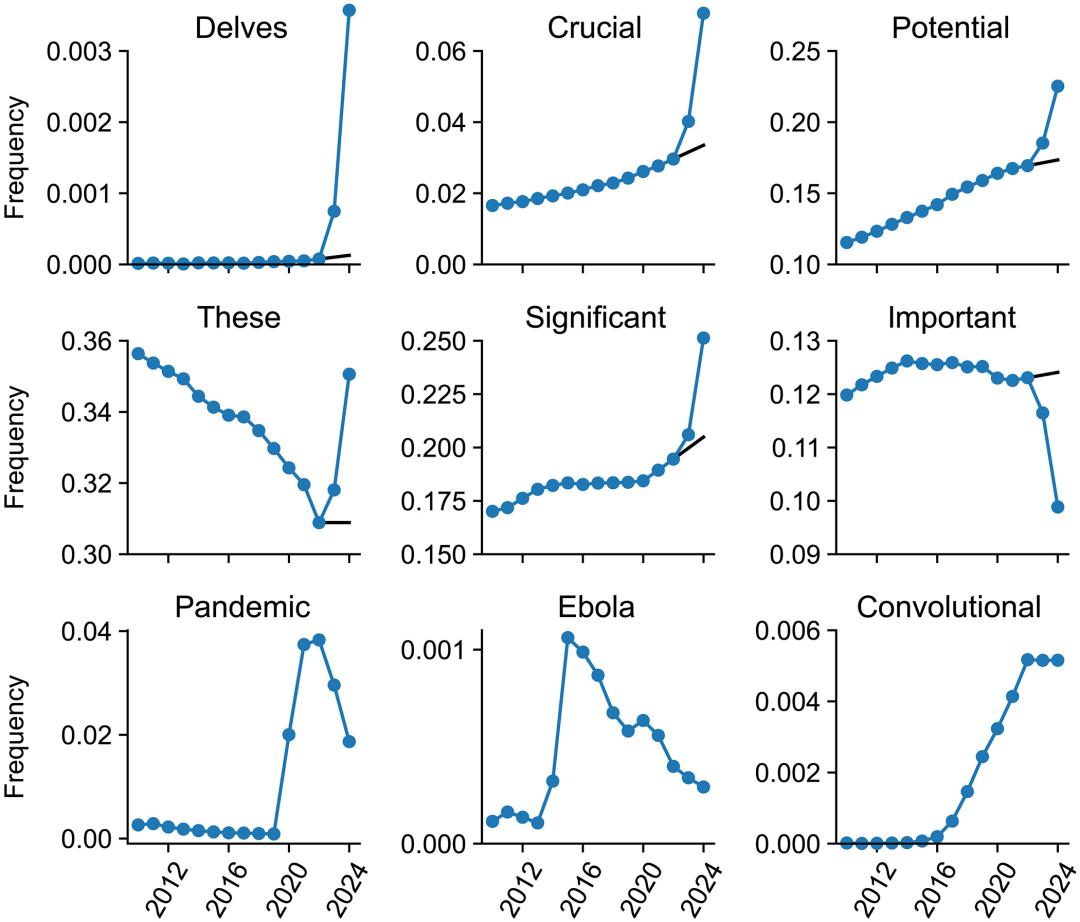
这个差值,便成了追踪 LLM 影响的有力证据。
为了实施这个计划,团队处理了一个庞大的数据集:2010 年至今,PubMed 数据库中超过 1510 万篇英语摘要。 他们将这些文本数据转换成一个巨大的「词汇-摘要」矩阵,并重点分析了在 2023 和 2024 年都较为常用(年使用次数 > 100)的 26,657 个单词。
AI 的「文风指纹」:这些词汇正在「占领」学术圈
分析结果,让 LLM 的「文风偏好」暴露无遗。
研究人员发现,自 2023 年以来,大量词汇的使用频率出现了不符合历史趋势的、爆炸性的增长。
其中,一些不那么常见的词汇,其频率增长比率(r 值)高得惊人,例如:
- • delves (深入探究):
r= 28.0,意味着其实际使用频率是预期的 28 倍! - • underscores (强调):
r= 13.8 - • showcasing (展示):
r= 10.7
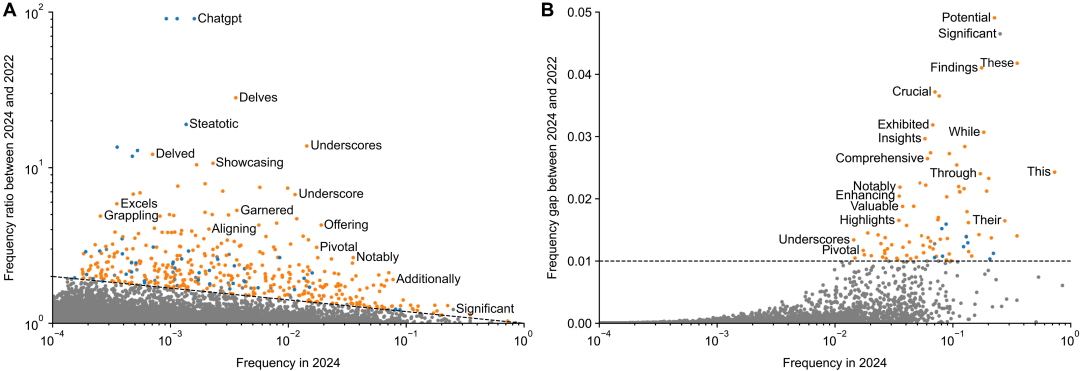
而一些本就常见的词汇,其频率差距(δ 值)则非常显著,说明它们在大量论文中被「额外」添加了进去,例如:
- • potential (潜在的):
δ= 0.052,意味着在 2024 年,包含该词的论文摘要比例,比预期高出了整整 5.2 个百分点。 - • findings (发现):
δ= 0.041 - • crucial (至关重要的):
δ= 0.037
研究人员在论文中提供了一些真实的、充满「AI 风味」的 2023 年摘要例句,读来颇为生动:
- 1. 「By meticulously delving into the intricate web connecting […] and […], this comprehensive chapter takes a deep dive into their involvement as significant risk factors for […].」 (通过细致地深入研究连接 […] 和 […] 的错综复杂的网络,这篇全面的章节深入探讨了它们作为 […] 的重要风险因素的参与。)
- 2. 「A comprehensive grasp of the intricate interplay between […] and […] is pivotal for effective therapeutic strategies.」 (全面掌握 […] 和 […] 之间错综复杂的相互作用,对于有效的治疗策略至关重要。)
- 3. 「Initially, we delve into the intricacies of […], accentuating its indispensability in cellular physiology, the enzymatic labyrinth governing its flux, and the pivotal […] mechanisms.」 (首先,我们深入研究 […] 的复杂性,强调其在细胞生理学中的不可或缺性、控制其流动的酶促迷宫以及关键的 […] 机制。)
这种华丽、甚至有些浮夸的文风,正是许多用户熟悉的 LLM 特征。
更有趣的是,研究发现,LLM 带来的词汇变革与以往截然不同。
在新冠流行期间,激增的词汇大多是与内容相关的「内容词」,而且主要是名词,例如 coronavirus、covid、pandemic。
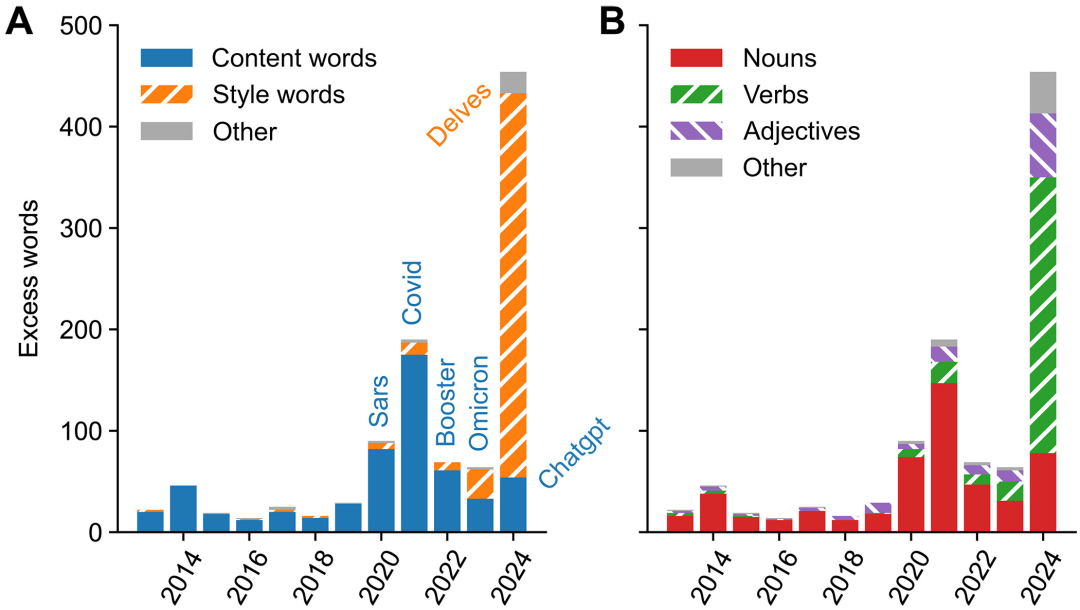
然而,在 2024 年的「超额词汇」清单中,情况发生了 180 度大转弯。这份清单几乎完全被「风格词」所主导,而这些词汇中,66% 是动词,14% 是形容词。
这清晰地表明,LLM 并非在创造新的科学「内容」,而是在深刻地重塑科学的「表达方式」。
保守统计,13.5% 的论文都有 AI 痕迹
找到了这些「指纹」,如何估算整体的「污染率」?
单个词汇的超额频率,只能提供一个非常有限的下限。例如,potential 一词 5.2% 的超额使用率,仅能证明「至少 5.2%」的论文被 LLM 处理过,因为其他被处理过的论文可能没有使用这个词。
为了得到更可靠的估计,研究人员采用了两种独立的启发式策略来组合多个「标记词」:
- 1. 稀有词集合 (Rare set): 自动选取所有频率低于某个阈值(
p < 0.02)的 291 个超额风格词。 - 2. 常见词集合 (Common set): 手动挑选了 10 个具有高超额频率的常见风格词,包括
across,additionally,comprehensive,crucial,enhancing,exhibited,insights,notably,particularly,within。
这两个词集几乎没有重叠,可以视为两次独立的实验。 令人信服的是,它们得出了高度一致的结果:
- • 基于「稀有词集合」的估算:LLM 使用下限为 13.6%。
- • 基于「常见词集合」的估算:LLM 使用下限为 13.4%。
将两者平均后,研究团队给出了最终的估算结果:13.5%。
13.5% 是什么概念?研究人员做了一个对比。他们用同样的方法分析了 2021 年疫情顶峰时期与新冠相关的文献规模,发现其对整体词汇库的贡献度(Δ 值)约为 6.9%。
这意味着,LLM 在 2024 年对学术写作的改造力度,至少是新冠疫情在 2021 年顶峰时期的两倍!
考虑到 PubMed 每年收录约 150 万篇论文,13.5% 意味着每年至少有 20 万篇生物医学论文的摘要是在 LLM 的辅助下完成的。
研究者反复强调,这仅仅是下限。 真实的 LLM 使用率,几乎可以肯定远高于这个数字。
全球图景:哪些领域、哪些国家在「拥抱」AI 写作?
研究更深入的部分,则是对不同子群体的异质性分析。LLM 的使用并非均匀分布,而是呈现出明显的「热点」。
- • 按领域划分: 计算相关领域遥遥领先。例如「计算科学」和「生物信息学」等领域,LLM 的使用率估算值(
Δ)达到了约 20%。 研究人员推测,这可能是因为计算机科学家对 LLM 技术更熟悉,也更愿意采纳。 - • 按国家/地区划分: 结果出人意料。一些英语母语国家,如英国,使用率相对较低(约 5%)。 而在中国、韩国等非英语母语地区,使用率则要高得多,普遍在 20% 左右。 研究者认为,这可能是因为 LLM 能有效帮助这些地区的研究者进行英语润色。
- • 按期刊划分: 期刊的「声望」与 LLM 的可检测使用率呈现负相关。 像 Nature、Science、Cell 这样的顶级期刊,估算值约为 7%-10%。 而一些拥有简化或加速审稿流程的出版商,如 MDPI 和 Frontiers,其旗下期刊的估算值则分别高达 21% 和 20%。
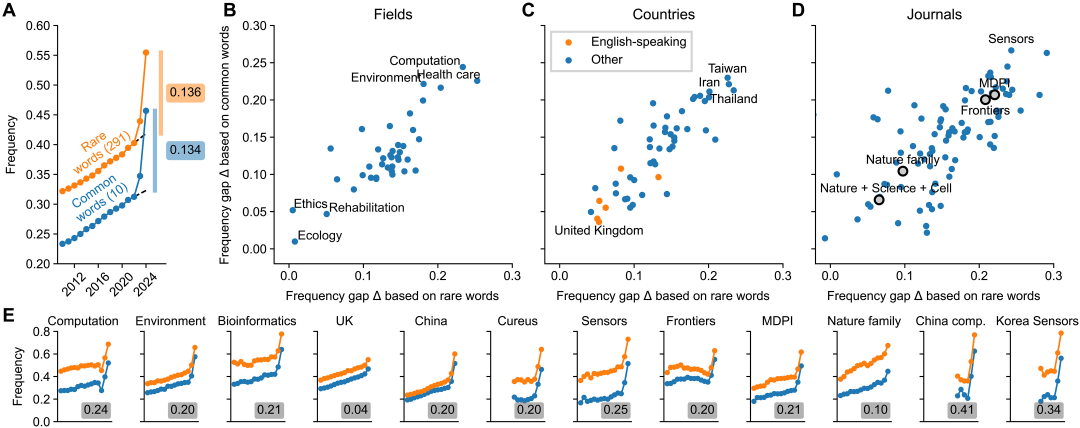
当这些维度交叉时,出现了更为极端的情况:
- • 发表在《Sensors》(MDPI 旗下期刊)上的韩国论文,使用率估算值高达 34%。
- • 来自中国的计算科学论文,使用率估算值更是达到了惊人的 41%!
研究者还提出了一个耐人寻味的猜想:这种差异,除了反映真实的采纳率不同外,也可能与使用者「隐藏」AI 痕迹的能力有关。
英语母语者可能同样频繁地使用 LLM,但他们或许更擅长发现并主动删除 LLM 输出中不自然的风格词汇。
如果这个猜想成立,那么那些检测出高使用率的群体,可能只是更大规模冰山中,最「天真」、最容易被检测到的那一部分。
研究者据此推断,整个生物医学领域的真实 LLM 使用率,可能更接近于他们观测到的最高值——超过 30%。
一场不可逆转的革命,机遇与风险并存
这项研究清晰地表明,我们正处在一场科学写作方式的深刻变革之中。
LLM 的优势显而易见:它们可以改善语法、优化修辞、提升文本可读性,还能帮助非母语者跨越语言障碍,快速生成初稿和摘要。
但风险同样不容忽视。LLM 因其「幻觉」问题而臭名昭著,它们会编造参考文献、提供不准确的摘要、并以一种权威而令人信服的口吻提出虚假主张。
它们还可能在潜移默化中强化训练数据中的偏见,甚至直接抄袭。
更深远的忧虑在于,写作风格的「同质化」可能会扼杀科学的创新和多样性。
当所有关于某个主题的引言都听起来千篇一律,引用着相同的文献时,新的、突破性的想法就更难涌现。
面对这场来势汹汹的变革,整个学术界都需要重新审视现有的规则和政策。
从禁止 LLM 担任论文作者,到限制其在同行评审中的使用,各大出版商和资助机构已经在行动。
而 Kobak 团队的这项工作,恰好提供了一种急需的、数据驱动的、可重复的监测工具。
它不仅揭示了 LLM 使用的现状,更提供了一把标尺,用以衡量未来政策的成效。
正如研究者在论文结尾巧妙地写道:
「我们希望未来的工作能够meticulously delve into(细致地深入研究)更准确地追踪 LLM 的使用情况,并评估哪些政策变化是 crucial(至关重要的),以应对 LLM 在科学出版领域崛起所带来的 intricate(错综复杂的)挑战。」
是的,这场变革已经开始,而我们才刚刚开始理解它的全貌。
论文信息:*Dmitry Kobak et al., Delving into LLM-assisted writing in biomedical publications through excess vocabulary. Science Advances | https://www.science.org/doi/10.1126/sciadv.adt3813
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-07-05,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号