搞懂 Claude Code 的 Agent 编排原理,我再也不一个个对话了

搞懂 Claude Code 的 Agent 编排原理,我再也不一个个对话了

码哥字节
发布于 2026-03-31 13:26:58
发布于 2026-03-31 13:26:58
本篇关键词: ["Claude Code", "多智能体", "AI编程", "Agent编排", "sub-agent", "Agent Teams", "oh-my-claudecode"] 你现在的用法大概是这样的:打开一个 Claude Code 对话,把任务描述扔进去,等它一步步做完,中途如果超出 context 就再开一个新对话,然后把前面的结论复制过来接着跑。
这没有任何问题——直到任务变得复杂。一个涉及十几个模块的重构,一次需要同时分析前后端代码的 bug 排查,一个要并行生成多个微服务脚手架的需求。这时候你会发现,一个对话窗口就像让一个人既写代码又做设计还要跑测试,效率瓶颈不在于他够不够聪明,而在于他只有一双手。
Claude Code 从 1.x 版本开始系统性地引入了多智能体编排能力。说白了,就是让你可以把任务分发给一批并行工作的 AI 实例,每个实例有自己独立的上下文和工具权限。这篇文章是我踩过坑之后整理的实战指南,从 Sub-agents 到 Agent Teams,从配置方法到实际限制,能用的我都写进来了。
核心洞察: 多智能体的本质不是「更聪明的 AI」,而是「用空间换时间」——用多个并行 context 换取任务的并行执行。
一个对话解决不了大任务
在讲怎么用之前,先说清楚为什么需要。这个问题的答案不是「因为多智能体很酷」,而是有具体的工程限制在里面。
Context window 是硬约束,不是软限制。 即使 Claude 支持 200K token 的上下文,一个复杂的全栈项目跑下来,代码文件、工具调用结果、中间推理过程加在一起,很容易超出。更关键的是,context 越长,模型的注意力就越分散——不是说它记不住早期内容,而是在海量信息中提取关键信号的能力会下降。这在 Anthropic 自己的研究报告里有明确提及。
任务天然有并行结构,但单对话是串行的。 想想一个典型的代码评审场景:安全漏洞检查、性能分析、代码规范审核、测试覆盖率评估——这四件事之间几乎没有数据依赖,完全可以同时做。但在单对话里,你只能一件一件排队。
错误传播没有隔离。 在一个对话里,如果某个中间步骤推断错了,后续所有步骤都会在错误的前提上继续构建。多智能体架构让你可以用「竞争假设」模式——让两个 agent 分别从不同角度分析同一个问题,最后合并结论,这在排查诡异 bug 时特别有用。
Anthropic 的官方文档给出了一个相对克制的建议:不是所有任务都适合多智能体。判断标准是:任务是否可以清晰分解?子任务之间是否可以并行?错误容忍度有多高?如果这三个问题的答案都是「是/高/高」,那多智能体值得上。如果你只是想跑一个简单脚本,开一个对话就够了,别过度工程化。
CLAUDE CODE 的三层「并行」架构
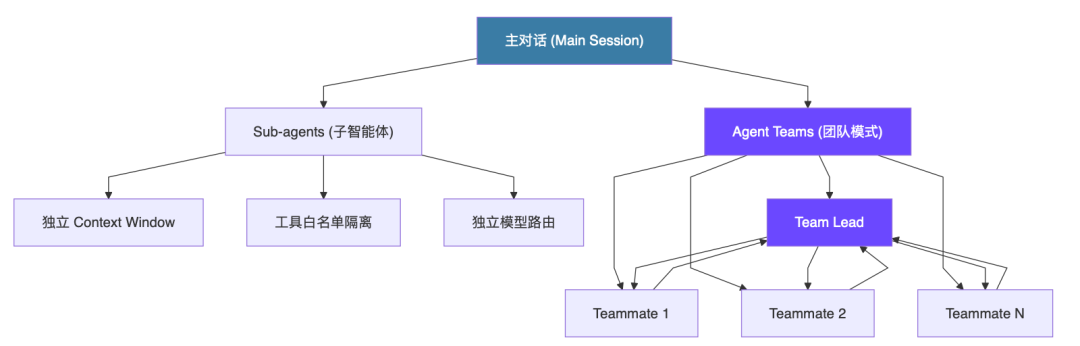
在具体讲每种方案之前,先建立一个整体认知框架。Claude Code 的多智能体能力实际上分三层。
b7e8c4c8a56ad8bb55dacfb77c140732
第一层:主对话(Main Session) 就是你直接交互的那个窗口,没什么特别的。
第二层:Sub-agents(子智能体) 是由主对话按需创建的专家实例。每个子智能体有独立的 context window,有预设的工具权限范围,完成任务后把结果返回给主对话。通信是单向的:主对话分发任务,子智能体上报结果,子智能体之间不能直接通信。
第三层:Agent Teams(团队模式) 是目前还在实验阶段的高级功能。它引入了 Team Lead + Teammates 的概念,成员之间可以双向通信,共享一个任务列表,适合需要协作推理的复杂场景。
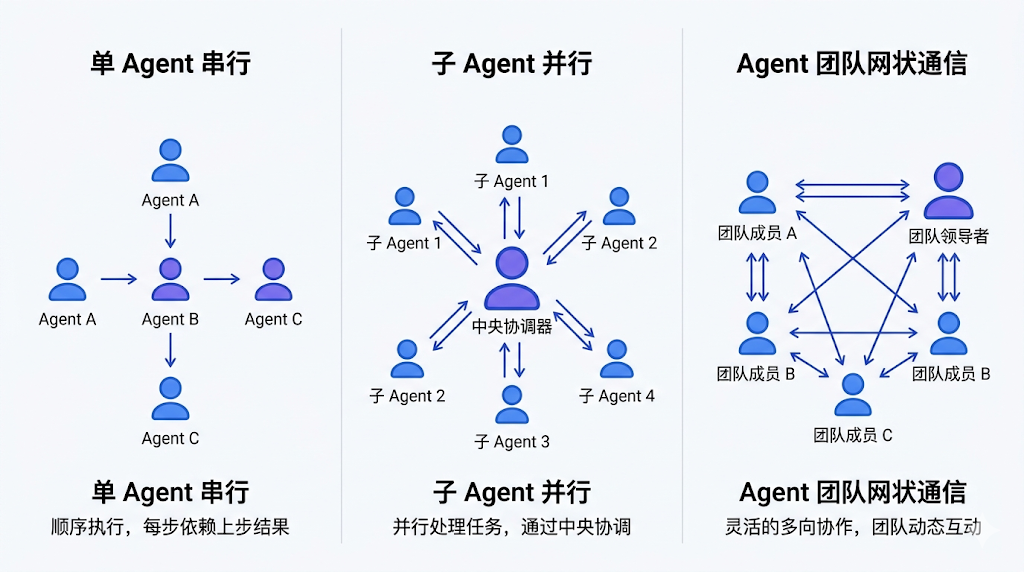
image-20260330193940048
三种模式的核心区别用一句话说:通信方式决定了适用场景。单向分发适合任务独立的并行工作;双向通信适合需要协作推理的复杂问题。token 成本上,每个 agent 实例都独占一个 context window,所以 agent 数量越多,token 消耗线性增长。
这三层之间有严格的创建权限约束。主对话可以创建任意子智能体;Sub-agent 不能创建新的子智能体(这是 Anthropic 刻意的安全设计);Agent Teams 的 Teammate 本质是特殊的 Sub-agent,同样受这个约束限制。理解这个层级关系,能帮你避免在设计工作流时踩到权限边界的坑。
另一个容易误解的点是:多智能体并不等于更快。如果任务之间存在强依赖(A 的输出必须作为 B 的输入),那并行化毫无意义,反而会因为协调开销而变慢。多智能体的加速效果来自于任务图中存在的并行分支,不是靠堆 agent 数量。在实际使用中,我的经验是先画出任务依赖图,找出可以并行的分支,再决定启动几个 agent,而不是反过来。
SUB-AGENTS:最实用的「专家团队」
Sub-agents 是当前最成熟、最实用的多智能体方案,我在生产项目里用得最多的也是它。
子智能体的运作原理
每个子智能体本质上是一个带有特定系统提示和工具白名单的独立 Claude 实例。它有自己独立的 context window——这意味着它不会「看到」主对话里的历史,只知道你分配给它的任务和它自己的工具调用记录。
这个设计有两个好处:一是 context 隔离让每个子智能体可以在干净的环境里专注于自己的任务;二是工具白名单让你可以精确控制每个子智能体的权限范围,比如只给代码评审 agent 读文件权限,不给写权限,降低误操作风险。
Claude Code 内置了四个预设子智能体:
- Explore:负责代码库探索和理解,只有读权限
- Plan:负责任务规划和分解,不执行实际操作
- General-purpose:通用型,工具集最完整
- Bash:专门处理 shell 命令执行
配置一个自定义子智能体
内置的四个不够用怎么办?写一个 YAML 配置文件。下面是一个 code-reviewer agent 的完整例子:
# .claude/agents/code-reviewer.yml
# 放在项目根目录的 .claude/agents/ 下,Claude Code 会自动加载
# 也可以放在 ~/.claude/agents/ 实现跨项目复用
name: code-reviewer
description: |
专注于代码质量审查的专家 agent。
适合在 PR 合并前对具体文件做深度审查。
当你需要检查安全漏洞、性能问题或代码规范时,@code-reviewer 它。
# 系统提示决定了这个 agent 的「人格」和专业领域
# 写得越具体,输出越稳定——模糊的提示会导致模糊的结果
system_prompt: |
你是一个经验丰富的 code reviewer,专注于以下四个维度:
1. 安全漏洞:SQL 注入、XSS、SSRF、敏感信息泄露
2. 性能问题:N+1 查询、不必要的全表扫描、内存泄漏风险
3. 代码规范:命名一致性、函数单一职责、注释完整性
4. 测试覆盖:边界条件、异常路径、mock 使用是否合理
输出格式要求:
- 每个问题标注严重程度:[CRITICAL] [WARNING] [SUGGESTION]
- 每个问题提供具体的代码行号和修改建议
- 不要泛泛而谈,每条评论要有具体的代码依据
# 工具白名单:只给它读文件的权限
# 不给写权限是因为 reviewer 不应该直接修改代码——只能提建议
# 这个约束是刻意的,防止 agent 在未经确认的情况下改动代码
tools:
- read_file
- list_files
- search_files
- bash # 需要 bash 来运行 lint 工具
# 限制可访问的目录,防止它读到不相关的配置文件或密钥
allowed_paths:
- src/
- tests/
- "*.go"
- "*.ts"
- "*.tsx"
# 模型路由:这个 agent 不需要最强的模型
# 用 claude-3-5-haiku 而不是 claude-opus-4,token 成本大概降 80%
# review 任务对推理深度要求不如架构设计高
model: claude-haiku-4-5三种调用方式
自然语言调用:在主对话里直接说「用 code-reviewer 帮我检查一下 src/auth/ 目录」,Claude Code 会自动匹配并启动对应的子智能体。
@-mention 调用:在对话里用 @code-reviewer 明确指定,比自然语言更精确,适合你知道具体要用哪个 agent 的场景。
Session 级别配置:在 CLAUDE.md 里声明哪些 agent 默认激活,这样不用每次手动指定,适合固定工作流。
<!-- 在项目 CLAUDE.md 里加这一段 -->
## 默认 Agent 配置
对于这个项目,以下 agent 默认激活:
- 每次修改 src/ 下的文件后,自动触发 @code-reviewer
- 每次新建功能模块时,先跑 @plan 生成任务清单再执行踩坑一:子智能体不能嵌套
这是我踩过最让人头疼的坑。Sub-agent 在执行过程中,不能再创建新的子智能体。也就是说,你不能让 @code-reviewer 在发现问题之后自动调起 @fix-agent 来修复。这个限制是 Anthropic 刻意设计的,目的是控制 agent 的行为边界,防止递归创建导致资源失控。
实际影响是:如果你的工作流需要「发现问题 → 自动修复 → 验证修复」这种链式结构,只能在主对话层面串联,而不能在子智能体内部实现。设计工作流时要把这个约束考虑进去。
AGENT TEAMS:真正的「团队作战」
Agent Teams 是 Claude Code 目前最激进的实验性功能,它解决了 Sub-agents 最大的限制:成员之间不能互相通信。
和 Sub-agents 的本质区别
在 Sub-agents 模式下,所有子智能体都只和主对话通信,彼此之间是信息孤岛。Agent Teams 引入了 Team Lead 角色,Teammates 之间可以双向通信,共享一个任务列表。
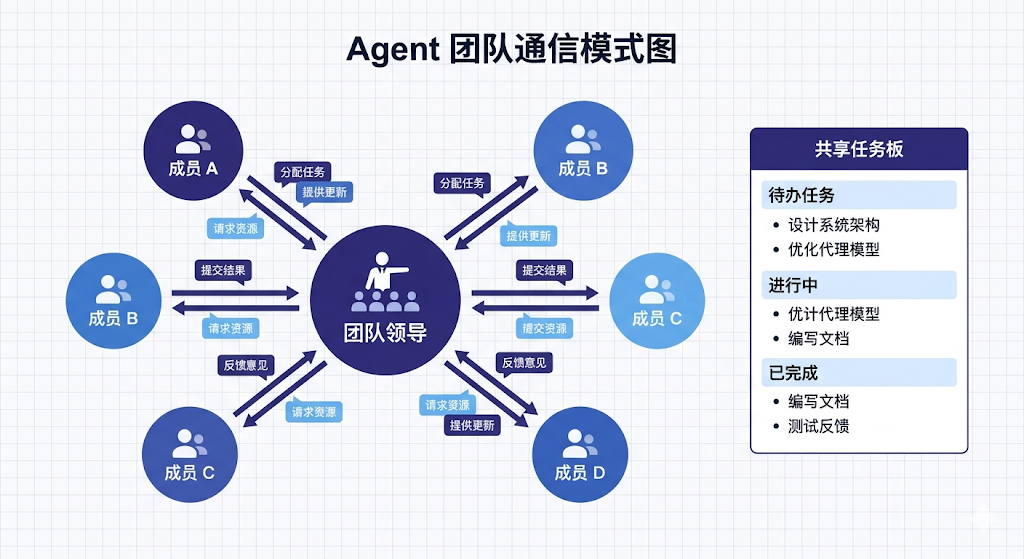
image-20260330194131282
说白了,Sub-agents 是「星形拓扑」(所有通信经过中心节点),Agent Teams 是「部分网状拓扑」(成员之间可以直接对话)。这让一些原本无法实现的协作模式成为可能,比如让两个 agent 互相质疑对方的结论。
如何开启
Agent Teams 目前需要手动启用,在项目的 .claude/settings.json 里加一行:
{
"experimental": {
"agentTeams": true
},
"env": {
"CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS": "1"
},
"team": {
"maxSize": 5,
"taskQueueSize": 30,
"coordinationModel": "claude-opus-4-5",
"workerModel": "claude-haiku-4-5"
}
}注意 coordinationModel 和 workerModel 分开配置——Team Lead 做协调和推理,用强模型;Teammates 执行具体任务,用轻量模型。这是 oh-my-claudecode(简称 OMC)里的智能路由思路,token 成本差异很显著。
三个真实使用场景
场景一:并行代码评审 同时启动安全审计 agent、性能分析 agent、代码规范 agent,三个 teammate 分别分析同一批代码,Team Lead 汇总结论并解决冲突。相比串行评审,时间压缩到 1/3,而且不同维度的分析互不干扰。
场景二:竞争假设调试 遇到诡异的 bug 时,让两个 agent 从不同假设出发各自排查——一个假设是并发问题,另一个假设是数据序列化问题。两个 teammate 并行跑,Team Lead 对比两条路径的发现,这种「让 AI 互相打架」的方式在定位复杂 bug 时出奇地有效。
场景三:跨层变更 做一个需要同时改动数据库 schema、后端 API、前端组件的功能时,三个 teammate 分别负责各自的层,Team Lead 维护变更依赖关系,确保接口契约一致。
踩坑二:/resume 不恢复进行中的成员
Agent Teams 有一个让人抓狂的已知问题:如果一个 Team 任务中途中断(比如你关掉了终端),用 /resume 命令恢复 session 时,已经在执行中的 teammate 不会被恢复,只有 Team Lead 会重启,它会以为所有子任务还没开始。
实际后果是:你可能看到重复执行——之前已经完成一半的任务被 Team Lead 重新分配,导致文件被重复修改。
规避方法:在启动 Agent Teams 任务前,在任务描述里明确要求 Team Lead 先检查文件修改时间戳,判断哪些子任务已完成。这是一个 workaround,不是根本解决方案——Anthropic 把这个问题列在了 known limitations 列表里,预计后续版本修复。
除了 /resume 问题,当前 Agent Teams 还有这些已知限制:
- 每个 Team 的 teammates 上限是 10 个(超出会静默失败)
- 任务队列在 session 结束后不持久化
- Teammate 之间的通信有延迟,不是实时的
- 不支持动态扩容(mid-task 无法新增 teammate)
- 调试信息不够完整,排查 teammate 行为比较困难
- 与某些第三方 MCP 工具的兼容性还有问题
- 高并发下偶发 race condition(官方确认但未修复)
社区是怎么玩的:OH-MY-CLAUDECODE 的实战经验
光看官方文档容易陷入理论层面。我在 GitHub 上找到两个社区项目,里面的实战经验比文档有用得多。
oh-my-claudecode(OMC) 目前有 16,900 stars、1,200 forks(2026年3月数据),是 Claude Code 生态里最活跃的扩展框架之一。claude-howto 有 8,900 stars,更偏向知识整理。
OMC 最有意思的设计是它的 Teams-First pipeline,把任务执行流程标准化为五个阶段:
plan(任务规划) → prd(需求细化) → exec(并行执行) → verify(验证) → fix(修复)每个阶段都有对应的 agent 配置和提示词模板,可以单独使用某个阶段,也可以串联整个流程。
OMC 提供了 7 种执行模式,其中最值得关注的是两个:
# ralph 模式:持久化执行,适合长时间运行的任务
# 它会自动处理 session 断开重连,维护任务进度
/ralph "重构整个认证模块,分离 JWT 逻辑和 OAuth 逻辑"
# ultrawork 模式:最大并行,适合独立子任务密集的场景
# 它会自动评估任务依赖关系,尽可能并行化
/ultrawork "给 user、order、payment 三个模块分别生成完整测试套件"
# 普通的 team 模式启动方式
/team "分析这个 PR 的安全风险和性能影响,输出评审报告"OMC 声称它的智能模型路由可以节省 30-50% 的 token 消耗。背后的逻辑是:根据任务的推理复杂度自动选择模型——简单的文件读写和格式转换用 Haiku,需要深度推理的架构决策用 Opus。这个数字在实际使用中是可信的,我自己测下来大概在 35% 左右。
OMC 的 CLAUDE.md 模板也值得参考,它把 Anthropic 推荐的 3-5 人团队规模、每人 5-6 个任务的参数直接写进了模板配置,你不用自己摸索起步规模。
什么时候该用多智能体,什么时候别用
坦白讲,我见过不少人把多智能体用成了「有锤子看啥都是钉子」的案例。所以这部分要讲清楚边界。
判断框架
用三个问题评估一个任务是否值得上多智能体:
1. 任务可以清晰分解吗? 如果子任务之间的边界模糊,agent 之间的通信协调成本会超过并行带来的收益。比如「优化整个项目的代码质量」这种需求,边界太模糊,不如「分别优化 A/B/C 三个模块的代码质量」这种有清晰边界的需求。
2. 子任务之间可以并行吗? 如果任务链是线性的(A 的输出是 B 的输入,B 的输出是 C 的输入),多智能体几乎没有优势,甚至因为通信开销而变慢。只有任务图中存在可以同时执行的分支,并行才有意义。
3. 错误代价有多高? 每个独立 agent 都可能犯独立的错误。在 Sub-agents 模式下,子 agent 的错误如果没有被主对话捕获,可能静默传播。在关键生产代码修改这种场景,宁可慢一点,用单对话配合严格的确认步骤。
真实的 token 成本
一个容易被忽略的问题是 token 成本不是线性的——它是乘法的。
如果主对话消耗 20K tokens,启动 5 个 Sub-agents 每个消耗 15K tokens,总消耗是 20K + 5×15K = 95K,是单对话的将近 5 倍。Agent Teams 因为成员间通信,还要加上协调本身的 token 消耗。
Anthropic 的推荐起步规模是 3-5 个 agent,每个 agent 5-6 个任务。这个规模能平衡并行效率和成本控制。超过这个规模,协调成本开始显著上升,边际收益递减。
实战建议:先用 3 个 agent 跑,根据实际任务完成时间和 token 消耗决定要不要扩。不要一上来就拉满。
常见问题
Q:Sub-agents 和 Agent Teams 能同时用吗?
可以,但要注意层级关系。Agent Teams 的 Teammate 本质上是特殊的 Sub-agent,所以「Teams 里的 Teammate 调用外部 Sub-agent」这种嵌套不支持,会触发前面说的嵌套限制。保持结构扁平是最稳的做法。
Q:子智能体的 context window 大小和主对话一样吗?
默认是一样的,都是模型的最大上下文。但 OMC 的配置允许你为每个 agent 设置 max_tokens 限制,主动缩小 agent 的 context 来降低成本。对于任务简单的 agent,这是个有效的成本控制手段。
Q:Agent Teams 现在稳定吗?适合上生产吗?
不适合直接上生产。「实验性」这个标签是认真的——当前版本有 7 个已知限制,session 恢复问题在关键场景下会造成重复操作。建议先在内部开发环境里用,积累一段时间经验再评估。
Q:oh-my-claudecode 需要付费吗?
OMC 本身是开源免费的,但它底层调用的 Claude API 正常收费。OMC 的价值在于它预配置好了一套合理的 agent 工作流,省去了你自己摸索配置的时间。
Q:如果我用 Cursor 或者 Windsurf,这些概念能迁移吗?
部分可以迁移。多智能体的思路是通用的,但具体的配置格式(YAML agent 定义、settings.json 字段)是 Claude Code 特有的。Cursor 有自己的 Rules for AI 系统,可以实现类似的专家角色划分,但没有 Agent Teams 这种级别的协作通信机制。
参考资料
- Claude Code 官方文档 - Sub-agents
- Claude Code 官方文档 - Agent Teams
- oh-my-claudecode GitHub — 16,900 stars,实战配置参考
- claude-howto GitHub — 8,900 stars,使用技巧整理
- Anthropic Blog - Building effective agents
多智能体编排会成为 AI 编程的标配工作流,还是会像微服务一样,在被过度使用一段时间后回归理性?我倾向于认为,三年内会出现一批专门针对多智能体协调的工具和规范——就像容器编排从手工脚本演化到 Kubernetes 一样。那时候今天这些手工配置的 YAML,大概会觉得很古朴。
关注「码哥跳动」解锁更多 AI 使用技巧,跟上 AI 时代步伐......
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-30,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号