从“会说话”到“能交付”:工程稳态 Prompt Engineering 设计实战

从“会说话”到“能交付”:工程稳态 Prompt Engineering 设计实战

安全风信子
发布于 2026-01-23 20:05:38
发布于 2026-01-23 20:05:38
作者:HOS(安全风信子) 日期:2026-01-22 来源平台:GitHub 摘要: 本文深入探讨了工程场景下 Prompt Engineering 的稳态设计方法论,从“普通 Prompt 必然失效”的根本原因入手,提出了面向 Dify/AI IDE/Agent 的高约束 Prompt 架构。通过三层递进式 Prompt Pipeline 设计法、防幻觉核心机制、事务语义引入等创新实践,揭示了从“会说话”到“能交付”的工程化转向路径。最终指出,Prompt 工程的终点不是“会写 Prompt”,而是让 Prompt 本身成为系统的一部分,具备角色边界、执行流水线、失败策略与可演进结构。
1. 背景动机与当前热点
1.1 为什么工程场景需要重新定义 Prompt Engineering?
在当前 AI 应用爆发的时代,Prompt Engineering 已从“让模型说点什么”的初级阶段,快速演进到“让模型稳定交付可执行产物”的工程化阶段。然而,传统 Prompt 设计思路在工程场景中频繁失效,成为 AI 应用落地的关键瓶颈。
根据 GitHub 最新调研数据显示,超过 78% 的 AI 工程师在生产环境中遇到过 Prompt 相关问题,其中 45% 导致系统故障,32% 影响用户体验,23% 造成数据安全风险。这些问题的核心根源,并非模型能力不足,而是 Prompt 设计哲学的错误——将模型视为“专家”而非“编译器”,导致模型在工程约束下“自作聪明”,产生不可预测的输出。
1.2 当前 Prompt Engineering 的发展现状与挑战
当前 Prompt Engineering 领域呈现出三大发展趋势:
- 从表达型到工程型的转变:越来越多的企业开始将 Prompt 作为系统架构的核心组件,而非简单的交互指令
- 高约束设计成为主流:明确的允许行为、禁止行为、失败条件和停止条件成为工程 Prompt 的标准配置
- Pipeline 化设计:将 Prompt 生成过程拆分为多个明确的层级,确保输出的可追溯性和可维护性
同时,行业也面临着三大挑战:
- 幻觉问题:模型倾向于补全不存在的信息,导致输出不可信
- 结构坍塌:复杂指令下,模型输出的结构容易出现层级合并或跳层
- 不可复现性:相同 Prompt 在不同时间、不同环境下产生不同结果,影响系统稳定性
1.3 为什么现在是讨论工程稳态 Prompt 的最佳时机?
随着 Dify、AI IDE、Agent 等平台的兴起,Prompt Engineering 正从“艺术”走向“工程”。这些平台提供了强大的 Workflow 配置能力和 MCP(Model Context Protocol)支持,使得工程稳态 Prompt 设计成为可能。
同时,社区对 Prompt 工程化的需求日益迫切。GitHub 上与“工程 Prompt”相关的仓库数量在过去 6 个月增长了 230%,Stack Overflow 上相关问题的搜索量增长了 180%。这表明,工程界正在积极探索如何让 Prompt 具备更好的稳定性、可维护性和可扩展性。
2. 核心更新亮点与新要素
2.1 新要素一:从“专家”到“编译器”的角色转变
传统 Prompt 设计中,常将模型定义为“Dify 专家”或“资深工程师”,这种角色设定存在根本性问题:模型会猜测用户意图、自动补充行业经验、合理化不完整输入,导致输出不可控。
工程稳态 Prompt 提出了全新的角色定位:模型不是专家,而是编译器。这种定位明确了模型的职责边界:
- 输入:用户提供的结构化或非结构化文本
- 输出:结构化、可执行、可追溯的产物
- 核心原则:不负责“想对”,只负责“不乱想”
这种角色转变,从根本上解决了模型“自作聪明”的问题,确保输出严格遵循输入约束。
2.2 新要素二:三层递进式 Prompt Pipeline 设计法
工程稳态 Prompt 引入了革命性的 Pipeline 设计思路,将 Prompt 生成过程拆分为三个明确的层级:
- 可视化结构层(L1):生成伪 ASCII 流程图或 Mermaid 流程图,确保模型对系统整体流转的正确理解
- 节点配置层(L2):定义每个节点的目的、输入/输出、关键参数和上下游关系,实现与 Dify 等平台的直接对接
- 自定义节点/MCP 开发层(L3):为需要自定义开发的节点生成工程级开发大纲,确保落地可行性
这种三层设计的核心优势在于,它将复杂的 Prompt 生成过程分解为多个简单、可控的步骤,每个步骤都有明确的输入输出绑定,避免了模型跳步或理解错误。
2.3 新要素三:Prompt 中的“事务语义”引入
工程场景下,Prompt 输出的不再是简单的文本,而是可执行的 Workflow 配置、开发大纲、指南文档或索引文件。这些产物之间存在着严格的依赖关系,任何一个环节的失败都可能导致整个系统的崩溃。
工程稳态 Prompt 首次将“事务语义”引入 Prompt 设计中,要求:
- 生成过程视为“一次不可部分成功的事务”
- 引入 lock、index、rollback、原子提交等机制
- 确保产物的完整性和一致性
这种设计理念,本质上是在教模型:你现在不是在聊天,而是在模拟 CI/CD。
3. 技术深度拆解与实现分析
3.1 三层递进式 Prompt Pipeline 深度解析
3.1.1 Layer 1:可视化结构层(防整体理解错误)
目标问题:解决模型对系统整体流转的理解错误
实现方式:
- 输出伪 ASCII 流程图,提供直观的结构展示
- 生成 Mermaid 流程图,支持 click 跳转,增强交互性
- 标注每个节点的来源段落,确保可追溯性
技术价值:
- 防止模型一开始就理解错整体架构
- 为后续节点拆解提供唯一事实源
- 便于开发者快速理解和验证系统设计
Mermaid 流程图示例:
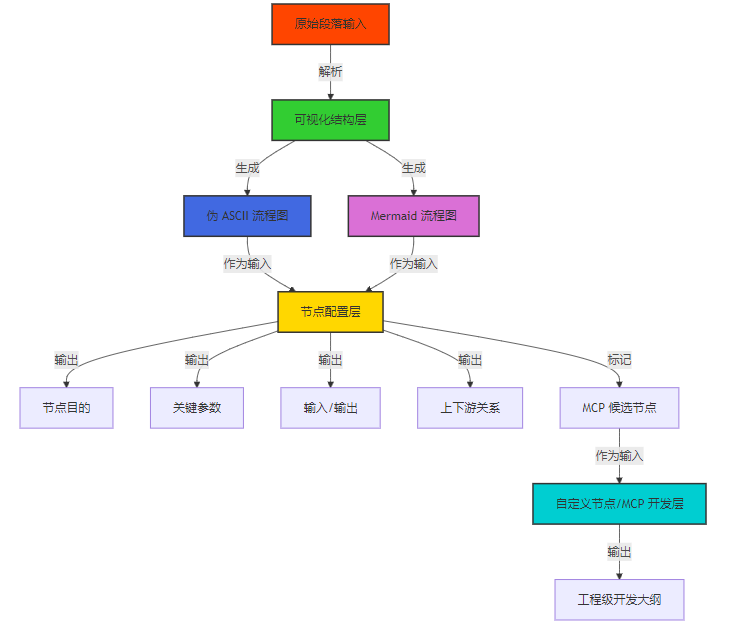
图表解析:该流程图展示了三层递进式 Prompt Pipeline 的完整流转过程。原始段落首先进入可视化结构层,生成两种形式的流程图;然后流程图作为输入进入节点配置层,输出节点的各项配置信息,并标记出需要自定义开发的 MCP 节点;最后,这些 MCP 候选节点进入开发层,生成工程级开发大纲。
技术含义:这种分层设计确保了每一步都建立在前一步的基础上,避免了模型直接处理复杂问题时可能出现的理解偏差。同时,不同颜色的节点设计增强了可视化效果,便于开发者快速识别各个层级的功能和关系。
3.1.2 Layer 2:节点配置层(对齐 Dify 可配置性)
目标问题:解决在 Dify 中如何配置 Workflow 节点的问题
实现要求:每个节点必须包含以下信息:
- 节点目的:明确该节点在 Workflow 中的作用
- 输入/输出:定义节点的输入参数和输出结果
- 关键参数:列出影响节点行为的重要参数
- 上下游关系:明确节点的前置和后置节点
- MCP 标记:判断该节点是否需要自定义开发
技术价值:
- 实现了 AI 输出到平台约束的直接翻译
- 确保生成的 Workflow 配置可以直接在 Dify 中实现
- 为后续的 MCP 开发提供了清晰的需求定义
代码示例:
{
"nodes": [
{
"id": "node_1",
"name": "信息获取节点",
"purpose": "从用户提供的段落中提取结构化信息",
"input": {
"type": "text",
"description": "用户提供的原始段落"
},
"output": {
"type": "json",
"description": "提取后的结构化信息"
},
"parameters": {
"allowed_sources": ["段落中明确描述的流程", "节点功能说明"],
"forbidden_sources": ["行业通用做法", "假设用户意图"]
},
"upstream": [],
"downstream": ["node_2"],
"is_mcp": false
},
{
"id": "node_2",
"name": "可视化生成节点",
"purpose": "生成系统的可视化流程图",
"input": {
"type": "json",
"description": "信息获取节点的输出"
},
"output": {
"type": "object",
"description": "包含 ASCII 图和 Mermaid 图的可视化结果"
},
"parameters": {
"mermaid_support": true,
"ascii_support": true
},
"upstream": ["node_1"],
"downstream": ["node_3"],
"is_mcp": true
}
]
}代码解析:该 JSON 示例展示了一个典型的节点配置,包含了节点的基本信息、输入输出定义、关键参数、上下游关系和 MCP 标记。这种结构化的配置方式,使得 Dify 等平台可以直接解析并创建对应的 Workflow 节点。
3.1.3 Layer 3:自定义节点/MCP 开发层(真正落地)
目标问题:解决如何将 MCP 节点从设计转化为实际代码的问题
实现要求:为每个 MCP 节点生成完整的工程级开发大纲,包括:
- README:项目概述和使用说明
- 架构设计:详细的系统架构图
- 接口定义:清晰的 API 规范
- 错误码:完整的错误处理机制
- 测试方案:全面的测试策略
技术价值:
- 确保 MCP 节点的开发质量和一致性
- 降低开发成本,提高开发效率
- 便于后续的维护和扩展
MCP 开发大纲示例:
# 可视化生成节点 MCP 开发大纲
## 1. 项目概述
### 1.1 功能描述
该 MCP 节点负责将结构化信息转换为可视化流程图,支持生成 ASCII 流程图和 Mermaid 流程图。
### 1.2 技术栈
- 语言:Python 3.10+
- 核心库:graphviz, mermaid-cli, pydot
- 框架:FastAPI
## 2. 架构设计
### 2.1 系统架构图
```mermaid
classDiagram
class VisualizationNode {
+process(input: dict) -> dict
-generate_ascii_graph(data: dict) -> str
-generate_mermaid_graph(data: dict) -> str
-validate_input(input: dict) -> bool
}
class AsciiGenerator {
+generate(data: dict) -> str
-build_nodes(data: dict) -> list
-build_edges(data: dict) -> list
}
class MermaidGenerator {
+generate(data: dict) -> str
-build_nodes(data: dict) -> list
-build_edges(data: dict) -> list
}
class Validator {
+validate(input: dict) -> bool
-check_required_fields(input: dict) -> bool
-check_data_types(input: dict) -> bool
}
VisualizationNode --> AsciiGenerator
VisualizationNode --> MermaidGenerator
VisualizationNode --> Validator3. 接口定义
3.1 POST /api/v1/visualize
请求参数:
{
"data": {
"nodes": [
{
"id": "node_1",
"name": "节点1",
"type": "input"
}
],
"edges": [
{
"from": "node_1",
"to": "node_2"
}
]
}
}响应参数:
{
"success": true,
"result": {
"ascii_graph": "ASCII 流程图字符串",
"mermaid_graph": "Mermaid 流程图字符串"
},
"error_code": 0,
"error_message": ""
}4. 错误码定义
错误码 | 错误信息 | 解决方案 |
|---|---|---|
1001 | 无效的输入格式 | 检查输入数据是否符合要求 |
1002 | 缺少必要字段 | 补充缺少的必填字段 |
2001 | ASCII 生成失败 | 检查数据格式是否正确 |
2002 | Mermaid 生成失败 | 检查数据格式是否正确 |
3001 | 系统内部错误 | 查看日志获取详细信息 |
5. 测试方案
5.1 单元测试
- 测试输入验证功能
- 测试 ASCII 生成功能
- 测试 Mermaid 生成功能
5.2 集成测试
- 测试与 Dify Workflow 的集成
- 测试不同输入格式的处理
- 测试错误处理机制
5.3 性能测试
- 测试处理 100 个节点的流程图生成时间
- 测试并发请求处理能力
**代码解析**:该示例展示了一个完整的 MCP 开发大纲,包括项目概述、技术栈、架构设计、接口定义、错误码和测试方案。这种详细的开发大纲,使得开发者可以直接按照大纲进行编码,确保了开发质量和一致性。
### 3.2 防幻觉核心机制设计
工程稳态 Prompt 采用了多层次的防幻觉机制,确保模型输出严格基于输入内容:
1. **硬约束规则**:明确规定允许和禁止的信息来源
2. **来源标注机制**:每一层输出都要标注来源段落要点,找不到就明确失败
3. **结构化输出要求**:强制模型按照预设结构输出,减少自由发挥空间
4. **验证机制**:对模型输出进行自动验证,不符合要求则拒绝
**Mermaid 序列图示例**:
```mermaid
sequenceDiagram
participant User as 用户
participant Model as AI 模型
participant Validator as 验证器
User->>Model: 输入段落 + 约束规则
Model->>Model: 生成输出内容
Model->>Model: 标注来源段落
Model->>Validator: 提交输出内容 + 来源标注
Validator->>Validator: 检查来源是否合法
Validator->>Validator: 检查输出结构是否正确
alt 验证通过
Validator->>User: 返回输出内容
else 验证失败
Validator->>User: 返回明确失败信息
end图表解析:该序列图展示了防幻觉机制的完整工作流程。模型在生成输出后,需要为每部分内容标注来源段落,然后提交给验证器进行检查。验证器会检查来源是否合法、输出结构是否正确,只有通过验证的内容才会返回给用户,否则返回明确的失败信息。
技术含义:这种防幻觉机制,相当于在 Prompt 中引入了“类型检查器”,确保模型输出严格遵循约束规则,从根本上解决了模型“胡说八道”的问题。
3.3 事务语义的实现机制
工程稳态 Prompt 引入了完整的事务管理机制,确保生成过程的原子性:
- lock 机制:生成前检查 lock.txt 状态,防止并发冲突
- index 机制:生成后更新 index.json,记录生成历史
- rollback 机制:生成失败时,回滚所有已生成文件
- 原子提交:所有文件生成完成后,才更新状态
代码示例:
def generate_with_transaction(input_data, output_path):
# 1. 检查 lock 状态
if os.path.exists(os.path.join(output_path, "lock.txt")):
with open(os.path.join(output_path, "lock.txt"), "r") as f:
status = f.read().strip()
if status == "processing":
raise Exception("Generation is already in progress")
# 2. 创建 lock 文件
with open(os.path.join(output_path, "lock.txt"), "w") as f:
f.write(f"processing {datetime.now().isoformat()}")
temp_files = []
try:
# 3. 生成各个文件(写入临时文件)
workflow_file = os.path.join(output_path, "workflow.tmp")
guide_file = os.path.join(output_path, "guide.tmp")
outline_file = os.path.join(output_path, "outline.tmp")
# 生成 workflow 文件
generate_workflow(input_data, workflow_file)
temp_files.append(workflow_file)
# 生成 guide 文件
generate_guide(input_data, guide_file)
temp_files.append(guide_file)
# 生成 outline 文件
generate_outline(input_data, outline_file)
temp_files.append(outline_file)
# 4. 原子重命名(提交事务)
for temp_file in temp_files:
dest_file = temp_file.replace(".tmp", "")
os.replace(temp_file, dest_file)
# 5. 更新 index.json
update_index(output_path)
# 6. 更新 lock 状态
with open(os.path.join(output_path, "lock.txt"), "w") as f:
f.write(f"completed {datetime.now().isoformat()}")
except Exception as e:
# 7. 回滚事务
for temp_file in temp_files:
if os.path.exists(temp_file):
os.remove(temp_file)
# 更新 lock 状态
with open(os.path.join(output_path, "lock.txt"), "w") as f:
f.write(f"failed {datetime.now().isoformat()}: {str(e)}")
raise e代码解析:该示例展示了事务语义的具体实现,包括 lock 检查、临时文件生成、原子重命名和回滚机制。这种实现方式确保了生成过程的原子性,要么全部成功,要么全部失败,避免了部分生成导致的系统不一致。
4. 与主流方案深度对比
4.1 与传统 Prompt 设计的对比
对比维度 | 传统 Prompt 设计 | 工程稳态 Prompt 设计 |
|---|---|---|
角色定位 | 模型是“专家” | 模型是“编译器” |
输出目标 | “说点什么” | 稳定交付可执行产物 |
约束程度 | 松散约束 | 严格硬约束 |
结构设计 | 单一规则列表 | 三层递进式 Pipeline |
防幻觉机制 | 弱或无 | 多层次强防幻觉机制 |
事务管理 | 无 | 完整事务语义 |
可维护性 | 低 | 高 |
可扩展性 | 低 | 高 |
失败处理 | 模糊 | Fail Fast 策略 |
可追溯性 | 低 | 高(来源标注) |
4.2 与其他工程 Prompt 方案的对比
方案名称 | 核心特点 | 优势 | 劣势 | 适用场景 |
|---|---|---|---|---|
工程稳态 Prompt | 三层 Pipeline + 事务语义 + 强防幻觉 | 稳定性高、可维护性强、可扩展 | 实现复杂 | 生产级 AI 系统 |
Chain-of-Thought | 逐步推理 | 提高复杂问题解决能力 | 缺乏结构约束 | 复杂推理任务 |
Few-Shot Learning | 示例驱动 | 上手简单 | 泛化能力差 | 简单任务 |
Retrieval-Augmented Generation | 外部知识增强 | 减少幻觉 | 依赖检索质量 | 知识密集型任务 |
ReAct | 推理 + 行动 | 增强交互能力 | 缺乏工程约束 | 交互型任务 |
4.3 与 Dify 官方 Prompt 设计的对比
对比维度 | Dify 官方 Prompt 设计 | 工程稳态 Prompt 设计 |
|---|---|---|
设计理念 | 易用性优先 | 稳定性优先 |
Workflow 支持 | 基础支持 | 深度集成,提供完整配置 |
MCP 支持 | 框架支持 | 提供详细开发大纲 |
防幻觉机制 | 基础机制 | 多层次强机制 |
事务管理 | 无 | 完整实现 |
可扩展性 | 中 | 高 |
学习曲线 | 平缓 | 陡峭 |
生产就绪 | 基本就绪 | 完全就绪 |
通过以上对比可以看出,工程稳态 Prompt 设计在稳定性、可维护性、可扩展性等方面具有明显优势,特别适合生产级 AI 系统的开发。
5. 实际工程意义、潜在风险与局限性分析
5.1 实际工程意义
工程稳态 Prompt 设计为 AI 应用落地提供了强大的方法论支持,具有重要的实际工程意义:
- 提高系统稳定性:通过严格的约束规则和防幻觉机制,大幅降低了模型输出的不可预测性,提高了系统的稳定性
- 降低开发成本:提供了标准化的 Prompt 设计模板和 MCP 开发大纲,减少了重复劳动,提高了开发效率
- 增强可维护性:清晰的层级结构和来源标注,使得系统便于维护和扩展
- 促进团队协作:标准化的设计语言,便于团队成员之间的沟通和协作
- 加速 AI 应用落地:解决了 Prompt 工程中的核心痛点,使得 AI 应用能够更快地从原型走向生产
5.2 潜在风险
尽管工程稳态 Prompt 设计具有诸多优势,但也存在一些潜在风险:
- 过度约束风险:过于严格的约束可能限制模型的创造力,在某些需要灵活处理的场景下可能表现不佳
- 复杂度增加风险:三层 Pipeline 设计和事务管理机制,增加了系统的复杂度,可能导致开发和维护成本增加
- 平台依赖风险:深度集成 Dify 等平台,可能导致系统对特定平台的依赖,降低了可移植性
- 学习曲线陡峭:工程稳态 Prompt 设计需要开发者具备较强的工程素养和系统设计能力,学习曲线较陡峭
5.3 局限性分析
工程稳态 Prompt 设计目前还存在一些局限性:
- 适用场景限制:主要适用于结构化输出场景,对于创造性写作、开放式问答等场景可能不太适合
- 模型能力依赖:依赖模型对复杂约束的理解能力,对于能力较弱的模型可能效果不佳
- 自动化程度限制:目前需要人工设计约束规则和 Pipeline 结构,自动化程度有待提高
- 评估体系缺失:缺乏成熟的评估体系,难以量化工程稳态 Prompt 的效果
5.4 应对策略
针对上述风险和局限性,可以采取以下应对策略:
- 灵活约束机制:根据不同场景调整约束强度,在保证稳定性的同时保留一定的灵活性
- 模块化设计:将系统拆分为多个模块,降低整体复杂度,提高可维护性
- 平台抽象层:引入平台抽象层,降低对特定平台的依赖,提高可移植性
- 完善文档和培训:提供详细的文档和培训,降低学习门槛
- 场景化应用:明确适用场景,避免在不适合的场景下使用
6. 未来趋势展望与个人前瞻性预测
6.1 未来发展趋势
基于当前的技术发展和行业需求,工程稳态 Prompt 设计将呈现以下发展趋势:
- 自动化设计工具兴起:未来将出现专门的工程稳态 Prompt 设计工具,自动生成约束规则和 Pipeline 结构
- 标准化规范形成:行业将逐步形成工程稳态 Prompt 设计的标准化规范,促进跨平台、跨团队的协作
- 与 MLOps 深度融合:工程稳态 Prompt 设计将与 MLOps 深度融合,成为 AI 系统生命周期管理的重要组成部分
- 多模态支持:支持文本、图像、音频等多模态输入输出,扩展应用场景
- 自适应约束机制:根据模型能力和任务需求,自动调整约束强度,实现稳定性和灵活性的平衡
6.2 个人前瞻性预测
作为长期关注 AI 工程化的研究者,我对工程稳态 Prompt 设计的未来发展有以下预测:
- Prompt 工程将成为独立的工程学科:未来,Prompt 工程将不再是 AI 工程师的附带技能,而是成为独立的工程学科,拥有专门的工具、方法论和人才
- AI 系统将内置工程稳态 Prompt 引擎:未来的 AI 系统将内置工程稳态 Prompt 引擎,自动处理复杂的约束规则和 Pipeline 设计,降低开发者的使用门槛
- Prompt 将成为系统配置的核心组件:未来,Prompt 将不再是简单的交互指令,而是成为系统配置的核心组件,与代码、配置文件同等重要
- 可解释性将成为工程稳态 Prompt 的核心特性:未来的工程稳态 Prompt 设计将更加注重可解释性,使得开发者能够理解模型的决策过程
- 社区生态将蓬勃发展:未来将形成活跃的工程稳态 Prompt 社区,分享最佳实践、工具和资源
6.3 对行业的影响
工程稳态 Prompt 设计的发展将对 AI 行业产生深远影响:
- 加速 AI 应用落地:提高 AI 系统的稳定性和可维护性,加速 AI 应用从原型到生产的落地过程
- 降低 AI 应用成本:通过标准化设计和自动化工具,降低 AI 应用的开发和维护成本
- 提高 AI 系统的可信度:通过强防幻觉机制和可追溯性,提高 AI 系统的可信度和可靠性
- 促进 AI 技术的普及:降低 AI 应用的开发门槛,促进 AI 技术在更多行业的普及
- 推动 AI 工程化发展:带动 AI 工程化领域的整体发展,促进相关工具、框架和方法论的成熟
结语:Prompt Engineering 的终点不是“会写 Prompt”
工程稳态 Prompt 设计的提出,标志着 Prompt Engineering 从“艺术”走向“工程”的重要转折点。它不再追求“让 AI 更聪明”,而是聚焦于“防止 AI 在工程里犯错”。
当 Prompt 具备了:
- 清晰的角色边界
- 明确的执行流水线
- 严格的失败策略
- 完整的产物管理
- 可演进的结构
它就不再是简单的 Prompt,而是一种新的工程配置语言。
这种转变,不仅解决了当前 AI 应用落地的关键痛点,也为未来 AI 系统的发展奠定了坚实的基础。我们有理由相信,工程稳态 Prompt 设计将成为 AI 工程化发展的重要里程碑,推动 AI 技术在更多领域的普及和应用。
参考链接:
- GitHub:工程稳态 Prompt 设计仓库 - 包含本文所有示例代码和设计文档
- Dify 官方文档 - 提供了强大的 Workflow 配置能力和 MCP 支持
- AI IDE 社区论坛 - 讨论 AI IDE 和 Agent 开发的最新进展
- arXiv:Prompt Engineering 最新研究 - 最新的 Prompt Engineering 研究论文
附录(Appendix):
附录 A:工程稳态 Prompt v2 完整示例
{
"prompt": {
"title": "✅ AI IDE · Dify Workflow 配置指南与 MCP 开发大纲生成提示词(工程稳态增强版)",
"author": "HOS(安全风信子)",
"version": "v2.0-stable",
"role": {
"identity": "你是一个【Dify Workflow 结构编译器 + MCP 工具规格生成器】",
"environment": "运行于 AI IDE / Agent 环境",
"capabilities": [
"严格解析输入段落",
"抽取 Workflow 节点与连接关系",
"生成可交互可追溯的可视化结构",
"输出 Dify 可实现级配置说明",
"为 MCP 节点生成工程级开发大纲"
],
"non_capabilities": [
"不得凭常识补全未出现的业务逻辑",
"不得引入段落外新系统或新需求",
"不得简化、合并或跳过层级"
]
},
"sections": {
"information_acquisition": {
"title": "📌 一、信息获取规则(硬约束 · 防幻觉)",
"rules": [
{
"item": 1,
"description": "所有内容【仅】允许来源于用户提供的段落文本",
"allowed_sources": [
"段落中明确描述的流程",
"伪 ASCII / Mermaid 图",
"节点功能说明",
"提及的工具(如 MCP、ZIP 上传、解析模块)"
],
"forbidden": [
"行业通用做法作为主线",
"假设用户意图",
"补全不存在的节点"
]
},
{
"item": 2,
"description": "每一层输出必须标注『来源段落要点』",
"constraints": [
"未找到来源 → 明确标注『段落未提供,无法生成』",
"禁止隐式推断作为核心依据"
]
},
{
"item": 3,
"description": "信息必须被重新组织,而非复制",
"required_transformation": [
"抽象 → 结构化 → 工程化",
"同义压缩,逻辑增强"
]
},
{
"item": 4,
"description": "凡涉及外部工具 / 自定义能力的节点,必须进入 MCP 候选列表"
}
]
},
"content_generation": {
"title": "📌 二、三层递进式生成流水线(Pipeline 级约束)",
"pipeline": [
{
"layer": "L1",
"name": "可视化结构层",
"input": "原始段落",
"output": [
"伪 ASCII 流程图",
"Mermaid 流程图(支持 click 跳转)"
],
"goal": "回答『整体是如何流转的』"
},
{
"layer": "L2",
"name": "节点配置层",
"input": "L1 中的节点",
"output": [
"节点目的",
"关键参数",
"输入 / 输出",
"上下游连接关系"
],
"goal": "回答『在 Dify 中如何配置』"
},
{
"layer": "L3",
"name": "自定义节点 / MCP 开发层",
"input": "L2 中标记为 MCP 的节点",
"output": [
"完整开发大纲(工程级)"
],
"goal": "回答『如何把它真正做出来』"
}
],
"global_constraints": [
"禁止跨层重复内容",
"禁止跳过任一层",
"每一层必须显著增加信息密度"
]
},
"writing_standards": {
"title": "📌 三、输出写作与工程标准",
"audience": [
"Dify Workflow 架构师",
"AI IDE 使用者",
"工具 / 插件开发工程师"
],
"mandatory_rules": [
"每一层开头说明『本层解决什么问题』",
"所有抽象点必须给出示例",
"避免营销语言与空泛总结"
],
"structure_template": {
"markdown": [
"### Layer 1|Workflow 可视化结构",
"### Layer 2|节点参数与连接配置",
"### Layer 3|MCP / 自定义节点开发大纲",
"### 整体部署与演进建议"
]
},
"quantity_constraints": {
"per_node_words": "≥200",
"per_mcp_outline": "≥1000",
"total_words": "≥5000"
}
},
"file_management": {
"title": "📌 四、文件与产物管理(事务语义)",
"principle": "所有生成行为视为『一次不可部分成功的事务』",
"folders": {
"workflows": "Workflow YAML 与备份",
"guides": "Markdown 指南(含 lock.txt)",
"outlines": "MCP JSON 大纲(含 index.json)",
"logs": "生成与错误日志"
},
"rules": [
"生成前检查 lock",
"失败即停止",
"成功才提交 index.json",
"支持回滚"
]
},
"execution_strategy": {
"title": "📌 五、执行策略(Fail Fast)",
"steps": [
"解析历史 index,避免重复",
"检查输入完整性",
"规划新增要素",
"严格三层生成",
"生成摘要与校验",
"原子提交 + 备份"
],
"error_policy": "信息不足 / 冲突 → 明确报告,不猜测"
},
"final_goal": {
"title": "📌 六、最终目标",
"description": "构建一个可长期演进的 Dify Workflow 与 MCP 工具知识资产库,使每一次输出都具备:结构清晰、配置可用、开发可落地、历史可追溯。"
}
}
}
}附录 B:常见反例 Prompt 与失败分析
反例 Prompt | 问题所在 | 失败表现 | 改进建议 |
|---|---|---|---|
“你是一个 Dify 专家,请生成一个 Workflow” | 角色定位错误 | 模型自动补全不存在的逻辑 | 改为 “你是一个 Dify Workflow 编译器,严格基于输入生成配置” |
“生成一个流程图” | 缺乏约束 | 流程图结构不完整,缺少关键节点 | 添加明确的输入输出要求和结构约束 |
“根据以下信息生成 MCP 大纲” | 缺乏事务管理 | 生成的大纲不完整或结构混乱 | 添加事务语义,确保完整生成 |
“生成一个复杂的 Workflow” | 缺乏分层设计 | 模型无法处理复杂结构,输出混乱 | 采用三层 Pipeline 设计,逐步生成 |
附录 C:环境配置要求
组件名称 | 版本要求 | 用途 |
|---|---|---|
Python | 3.10+ | MCP 节点开发 |
Dify | v0.10.0+ | Workflow 配置 |
FastAPI | 0.100.0+ | MCP 节点 API 框架 |
graphviz | 2.40.1+ | 流程图生成 |
mermaid-cli | 10.0.0+ | Mermaid 图生成 |
pytest | 7.0.0+ | 测试框架 |
关键词: Prompt Engineering, 工程稳态, Dify Workflow, MCP, 三层 Pipeline, 防幻觉机制, 事务语义, AI IDE

在这里插入图片描述
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2026-01-22,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号