打破十年瓶颈!DeepSeek mHC 重构神经网络底层逻辑,V4/R2 渐行渐近

打破十年瓶颈!DeepSeek mHC 重构神经网络底层逻辑,V4/R2 渐行渐近

Henry Zhang
发布于 2026-01-07 18:19:57
发布于 2026-01-07 18:19:57
残差网络十年之困终被破!mHC 开启神经网络架构新篇章!
2025年12月31日,当全球都沉浸在跨年的热闹氛围里时,DeepSeek 依旧是“每逢佳节倍出新”的节奏,悄悄放了个大招:mHC(流形约束超连接)架构的技术论文。论文一作是 DeepSeek 团队的解振达,梁文锋也在作者之列。

这篇论文看似是常规的学术输出,实则藏着大模型领域的关键突破。懂行的朋友都知道,现在大模型竞争早就过了“堆参数就能赢”的初级阶段,进入了拼“深层稳定性”和“学习效率”的深水区。而mHC,正是破解“极深层网络难稳定和难高效”这个核心难题的关键钥匙。
如果说 V3 和 R1 是在现有架构上把“算法”和“数据”玩到了极致,那么 mHC 就是在为未来的超大规模架构换地基。因此坊间估计,mHC极有可能是 DeepSeek 下一代模型 V4 和 R2 的底层架构。
可能有朋友会疑惑:“深层网络不是早就有了吗?”别急,要搞懂mHC的厉害之处,得先从我们熟悉的“残差连接”说起。今天就用最接地气的语言,带大家把这件事讲明白。
一、残差连接,让神经网络“长高”的核心秘诀
2015 年之前,深度学习存在 “层数不敢随意增加” 的致命魔咒。这就像盖房,楼层越高理论视野越好,可地基与承重不足,20 层便可能坍塌。传统多层感知机层数超 20 层,就会面临两大难题:一是信息失真,每一层计算都像 “传声筒游戏”,原始信息逐渐变成无效噪声;二是梯度消失,训练误差信号传到浅层时已极度微弱,模型无法有效调整参数。
2015年底,何恺明在微软亚洲研究院的团队提出了的残差网络(ResNet),打破了这个魔咒,其核心是给神经网络加一条 “信息高速公路”,让前一层输入跳过复杂计算,直接与当前层输出相加,数学表达式为 x(l+1)=x(l)+F(x(l),W(l)),这一设计即恒等映射。
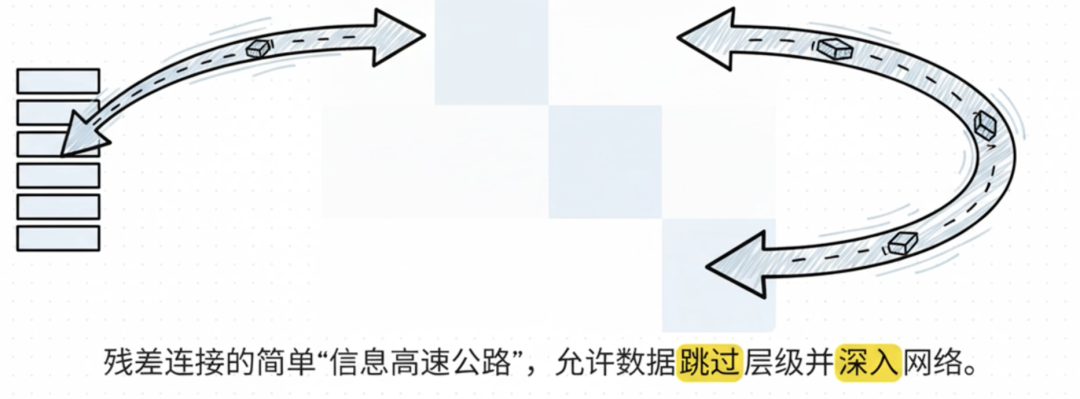
凭借这条捷径,原始信息可无损直达深层,神经网络深度一举突破至百层以上,甚至达到 1202 层,开启深度学习 “深层时代”。如今 GPT-4、DeepSeek-V3 等大模型均依托残差连接构建,但随着模型参数量迈向万亿级,残差连接的性能天花板也逐渐显现。
更多残差网络的解析,可参考之前这篇文章:残差网络核心原理及在 Transformer 与大语言模型中的影响解析
二、超连接的“双刃剑”困境
为突破残差连接性能上限,研究者提出 “扩宽高速路” 的超连接(HC)方案。若说残差连接是 “单车道高速”,超连接就是 “多车道立交桥”,它拓宽残差流宽度,加入可学习映射矩阵,让信息跨车道交流融合,理论上能提升模型特征学习能力。
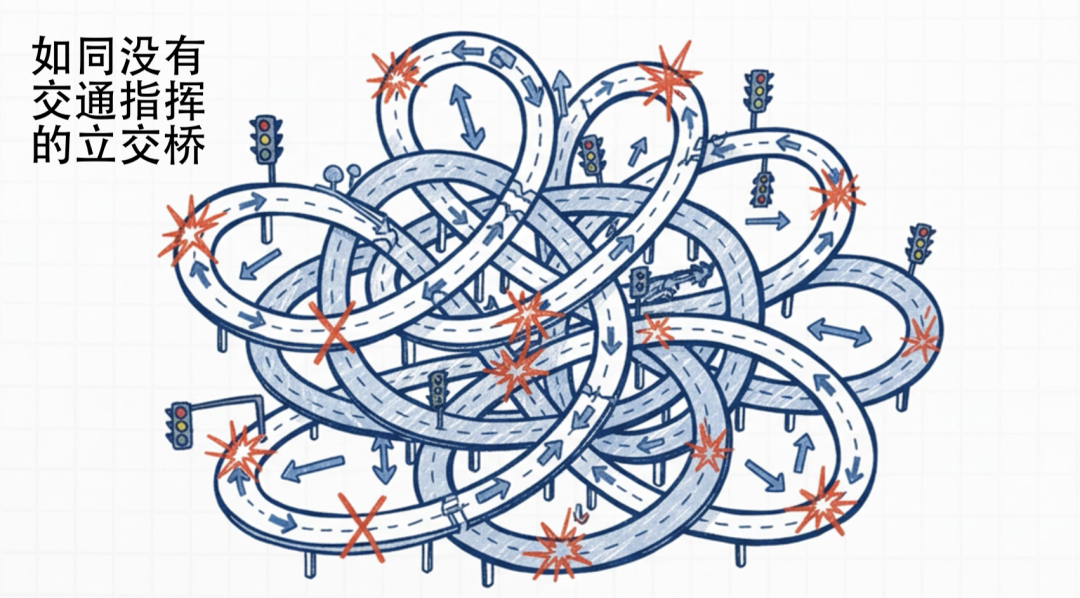
但超连接是把 “双刃剑”,问题核心在无约束的映射矩阵 —— 如同无交通指挥的立交桥,信号易被无限放大或凭空消失。实验数据显示,超连接复合映射的 “Amax 增益幅度” 峰值近 3000,如同车辆上桥后暴增 3000 倍,直接引发 “交通瘫痪”,反映在模型训练中就是损失值飙升、梯度范数震荡,训练极易崩溃。
残差连接稳定但上限低,超连接潜力大却难训练,兼顾二者的 mHC 方案由此应运而生。
三、mHC给超连接戴上“精准的数学镣铐”
mHC的全称是“流形约束超连接”(英文:Manifold-Constrained Hyper-Connections),它的核心思路特别巧妙:不抛弃超连接“多车道”的优势,而是给它加一副“精巧又精准的数学镣铐”:把无约束的映射矩阵“投影”到一个特定的数学空间(也就是“流形”)里,让它既能自由交流信息,又不会失控跑偏。
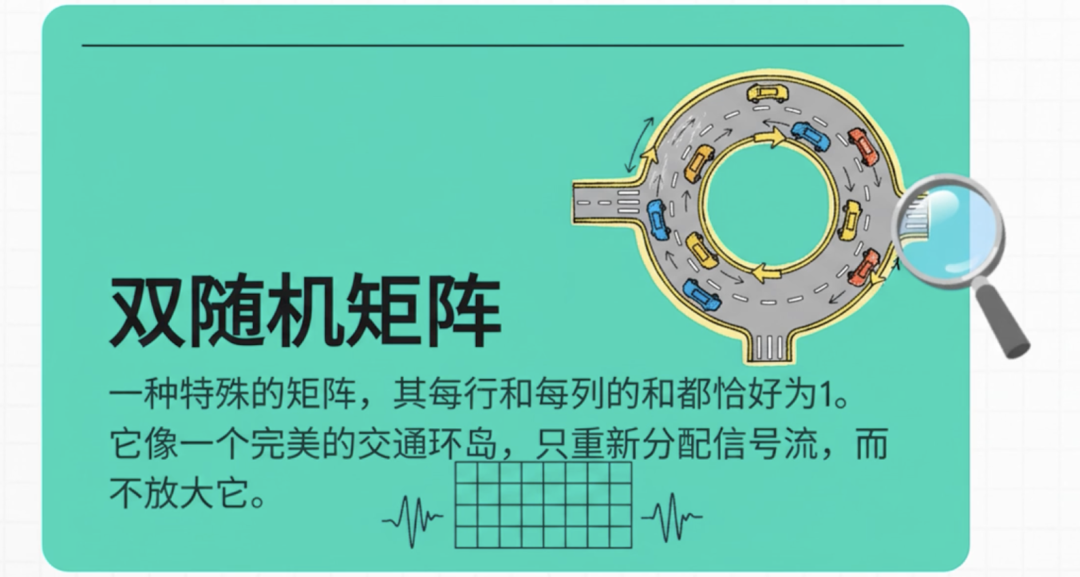
这副“数学镣铐”,就是双随机矩阵(也叫伯克霍夫多面体)。可能大家一听到“矩阵”就头大,其实不用懂复杂的公式,只要记住双随机矩阵的两个关键特点就行:一是所有元素都是非负的;二是每一行、每一列的和都恰好等于1。
如果把超连接的无约束立交桥比作“混乱的十字路口”,那双随机矩阵就像“有完美调度的环岛”,能带来三个关键保障,从根源上解决超连接的稳定性问题:
第一是“能量守恒”(专业说法叫“范数保持”)。双随机矩阵不会放大信号的整体强度,就像你在山谷里说话,回声再大也不会超过你原本的音量。这就从根源上杜绝了“梯度爆炸”的可能,信号在深层网络里传播时,再也不会突然“失控暴走”。
第二是“稳定传承”(专业说法叫“复合闭包”)。多个双随机矩阵相乘,结果还是双随机矩阵。这意味着不管网络有多少层,稳定性都不会打折扣——就像接力赛,每一棒都严格遵守规则,不会因为传递次数多就出乱子,深层网络的稳定性也就有了保障。
第三是“智能融合”(有清晰的几何解释)。这种映射本质上是对不同特征的“加权平均”,相当于让映射矩阵扮演“智能交通调度员”的角色:只能在不同车道间重新分配信息流,不能凭空创造或销毁信息。这样一来,既能实现信息的高效交流,又不会让信号失真。
那怎么把普通矩阵变成双随机矩阵呢?mHC用了一种经典的 Sinkhorn-Knopp算法(1964年发表)。这个算法的逻辑特别简单:通过反复交替归一化矩阵的行和列,直到每一行、每一列的和都无限接近1,就像把跑偏的车辆重新导回环岛一样,高效又精准,而且计算成本很低。
顺便说一下,我们熟知的机器学习中,主成分分析(PCA)与流形学习(Manifold Learning)的基本思路都从高维数据中发现简洁的低维结构,是降维思想的一体两面。PCA为线性降维提供了基础框架,而流形学习是其面对非线性结构时的泛化与扩展,可以说PCA就是流形的一个特例。
四、稳定性拉满,性能却反超
理论再优美,也得经得起实践检验。DeepSeek 团队在 3B、9B、27B 三个不同规模的 MoE 模型上做了充分实验,结果相当惊艳,完全验证了mHC的优势。
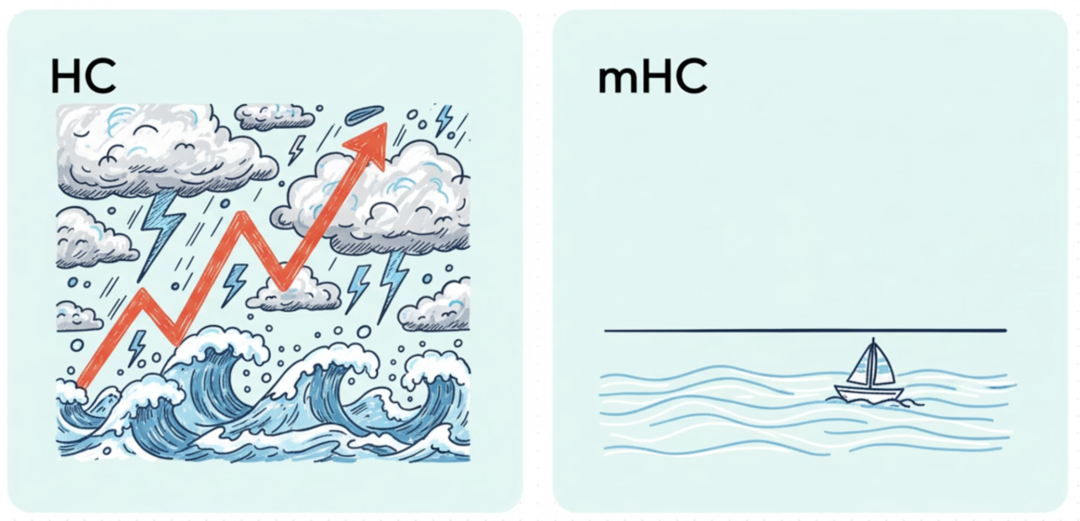
先看稳定性:超连接的Amax增益幅度峰值接近 3000,而 mHC 直接把这个值控制在 1.6 左右,相当于把信号放大倍数降低了三个数量级。反映在训练曲线上,超连接的损失曲线全是尖峰,梯度范数忽高忽低,看着就揪心;而 mHC 的损失曲线平稳下降,梯度稳定性和传统残差连接差不多,彻底解决了训练中途崩溃的老大难问题。
更关键的是,mHC没有为了稳定性牺牲性能,反而实现了“稳中有升”。在多个下游任务评测中,mHC全面超越了传统残差连接的基线模型,甚至比超连接的表现还好:在考验逻辑推理能力的BBH基准上提升了2.1%,在DROP阅读理解任务上提升了2.3%。别小看这几个百分点,在大模型领域,每一点提升都需要大量的技术积累,而且这些任务都是公认的“硬骨头”。
更难得的是,这样的提升几乎是“零成本”的。通过底层的算子融合优化,mHC仅增加了约6.7%的计算开销,却换来了稳定性和性能的双重飞跃。对于需要海量算力的大模型训练来说,这意味着能大幅缩短训练时间,降低成本——要知道,大模型训练的每一分钟,都是真金白银的投入。
五、为什么说 mHC 是 V4 和 R2 的关键基石?
DeepSeek选在2025年底发布mHC,绝非偶然。这是在为下一代双旗舰模型V4和R2铺路,mHC就是这两个模型的“核心骨架方案”。
对于DeepSeek-V4来说,它需要更大的参数量,远超现有的MoE架构。要驱动这么庞大的模型,必须有更深、更宽的网络结构。mHC提供的流形约束,能确保V4在训练时不会因为层数太深、参数太多而出现损失爆炸;同时,更稳定的架构能支持更高的学习率,大幅缩减昂贵的GPU训练时长,提升训练性价比——这对于万亿级模型来说,是至关重要的。
对于DeepSeek-R2来说,它的目标是解决人类的数学和科学难题,这需要极强的超长逻辑链处理能力。推理过程就像在脑子里进行数百步的模拟,每一步都不能丢信息。mHC的流形保持特性,能确保这些逻辑碎片在经过数百层计算后,依然能保持初衷,避免出现“幻觉”;同时,它还能捕捉到传统残差网络中被淹没的细微逻辑特征,让推理更精准和可靠。
结语:从“堆算力”到“懂数学”,DeepSeek的技术护城河
从 2024 年的 GRPO 算法,到 2025 年底的 mHC 架构,DeepSeek 一直走着一条不寻常的技术路线:不迷信“堆算力、堆参数”的粗放模式,而是靠数学创新和架构优化,突破大模型的物理极限。

如果说何恺明的残差连接开启了深度学习的“深度时代”,那么mHC很可能会开启“流形时代”。它告诉我们,神经网络的深度远没到尽头,只要能用数学约束管住信号的传播,就像控制深海潜流一样精准,AI的智慧深度就能不断突破。
2026 年已经到来,搭载 mHC 架构的 DeepSeek 下一代模型或许就在不远的将来出现。当 DeepSeek “节日发布”的传统再次上演,或许就是通用人工智能格局被改写的时刻。让我们一起期待!
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-01-02,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号