北交&字节最新开源ThinkGen:首次显式利用多模态CoT处理生成任务,多项任务性能SOTA

北交&字节最新开源ThinkGen:首次显式利用多模态CoT处理生成任务,多项任务性能SOTA

AI生成未来
发布于 2025-12-31 19:05:17
发布于 2025-12-31 19:05:17
作者:Siyu Jiao等
解读:AI生成未来

论文链接:https://arxiv.org/pdf/2512.23568 项目链接:https://github.com/jiaosiyuu/ThinkGen HF 链接:https://huggingface.co/JSYuuu/ThinkGen
亮点直击
- 首次提出思考驱动的视觉生成框架: ThinkGen 是第一个显式利用 MLLM 的思维链(CoT)推理来处理各种生成场景的思考驱动视觉生成框架。这解决了现有方法在泛化性和适应性方面的局限性,因为它们通常针对特定场景设计 CoT 机制。
- 解耦架构: ThinkGen 采用解耦架构,将预训练的 MLLM 和 Diffusion Transformer (DiT) 分开。其中,MLLM 负责根据用户意图生成定制指令,DiT 则根据这些指令生成高质量图像。这种设计克服了现有框架缺乏高级推理能力的问题。
- 视觉生成指令提炼 (VGI-refine) 模块: 为了解决 CoT 推理过程中冗余信息的问题,提出了 VGI-refine 模块。该模块从 MLLM 的推理链中提取简洁的指令信息,并将其与可学习的 Prepadding States 连接起来,从而实现 MLLM 表示分布的自适应调整,更好地与 DiT 的要求对齐。
- 可分离 GRPO-based 训练范式 (SepGRPO): 提出了一种名为 SepGRPO 的可分离强化学习训练范式,它在 MLLM 和 DiT 模块之间交替进行强化学习。这种灵活的设计支持在不同数据集上进行联合训练,从而促进了在广泛生成场景中有效的 CoT 推理。
- 在多生成场景中实现 SOTA 性能: 广泛的实验证明,ThinkGen 在多个生成基准测试中实现了稳健的、最先进的性能,尤其是在推理密集型任务中表现出色。
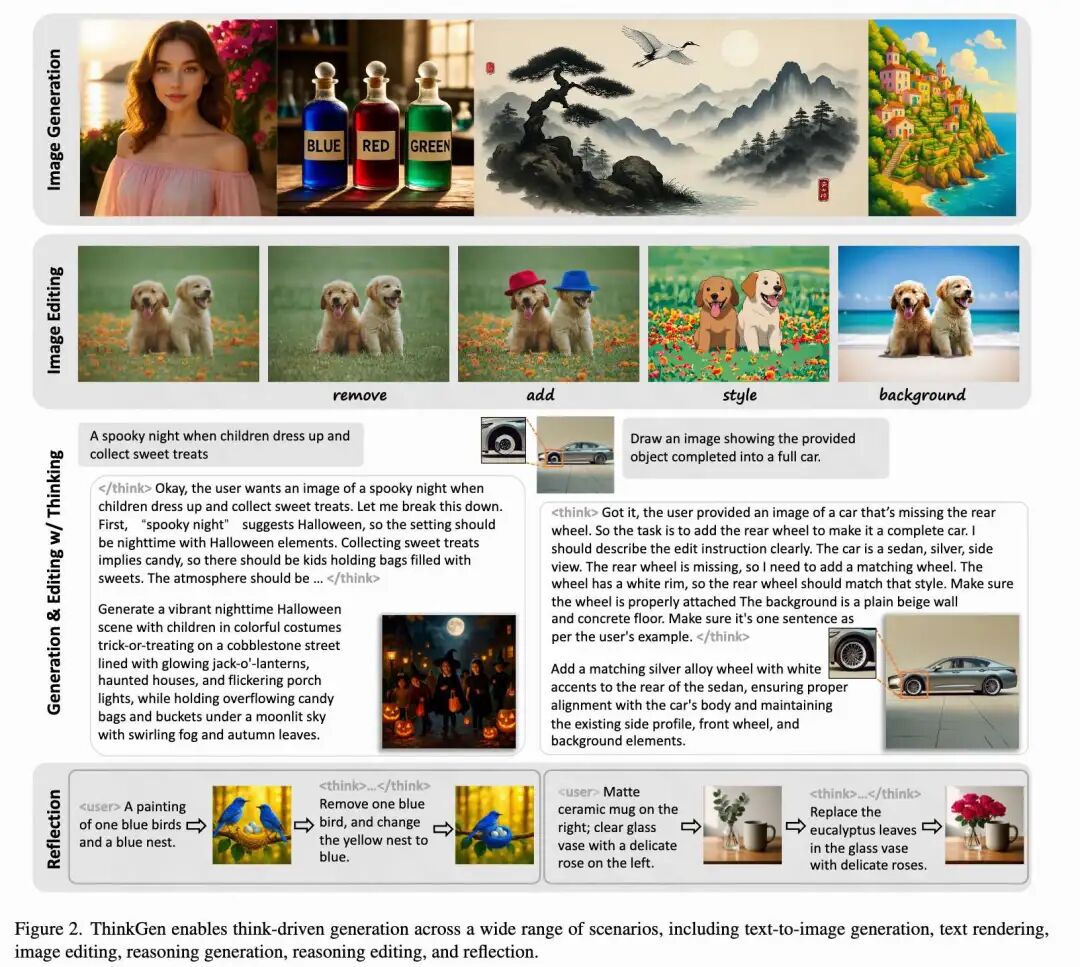
总结速览
解决的问题
- 现有的多模态大语言模型(MLLMs)在理解任务中展现了思维链(CoT)推理的有效性,但其在生成任务中的扩展仍然处于初级阶段。
- 现有针对生成任务的 CoT 机制通常是针对特定场景定制的,这限制了其泛化能力和适应性,导致在更广泛的任务中性能下降,并且通常需要手动干预来激活不同生成任务的 CoT 推理。
- 当前框架普遍缺乏高级推理能力。
提出的方案
- 本文提出了 ThinkGen,这是一个通用且思考驱动的视觉生成框架,旨在显式地利用 MLLM 的 CoT 推理能力,以解决各种生成场景中的复杂任务。
- 通过解耦 MLLM 和 Diffusion Transformer (DiT) 的架构,实现了在生成之前制定高质量计划的能力。
应用的技术
- 解耦架构: 框架包含一个预训练的 MLLM(用于生成定制指令)和一个 Diffusion Transformer (DiT)(用于生成高质量图像)。
- 思维链(CoT)推理: 显式地利用 MLLM 的 CoT 推理能力,通过生成明确的中间步骤来系统地解决复杂任务。
- 视觉生成指令提炼 (VGI-refine): 引入 VGI-refine 模块,从 MLLM 的自回归 CoT 输出中筛选掉冗余信息,并结合可学习的 Prepadding States 进行对齐。
- 可分离 GRPO-based 训练范式 (SepGRPO): 一种交替在 MLLM 和 DiT 模块之间进行强化学习的训练策略,旨在鼓励 MLLM 生成与 DiT 偏好对齐的指令,并使 DiT 基于这些指令生成高质量图像。
达到的效果
- 在多个生成基准测试中实现了稳健的、最先进的性能。
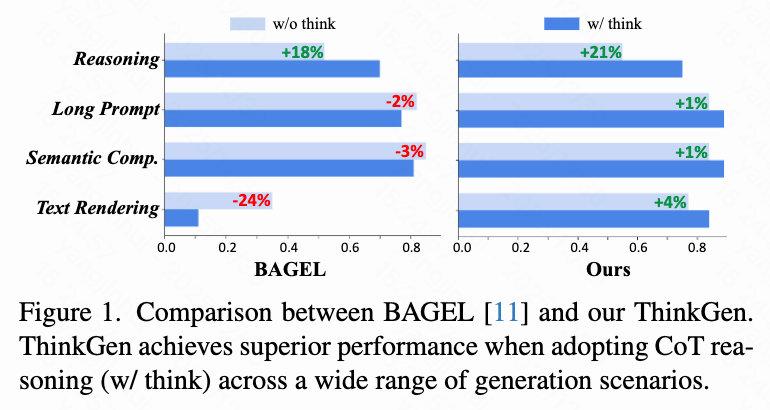
- ThinkGen 在采用 CoT 推理时,在广泛的生成场景中取得了卓越的性能(如下图1所示)。
- 实现了在多种生成场景下的有效 CoT 推理,从而增强了泛化能力。
架构方法
ThinkGen 采用解耦架构,包含一个预训练的 MLLM 和一个 Diffusion Transformer (DiT)。MLLM 负责根据用户意图生成定制指令,而 DiT 则根据这些指令生成高质量图像。这种解耦设计确保了每个组件的最佳性能,同时保持了系统的可扩展性和模块化,如下图3所示。
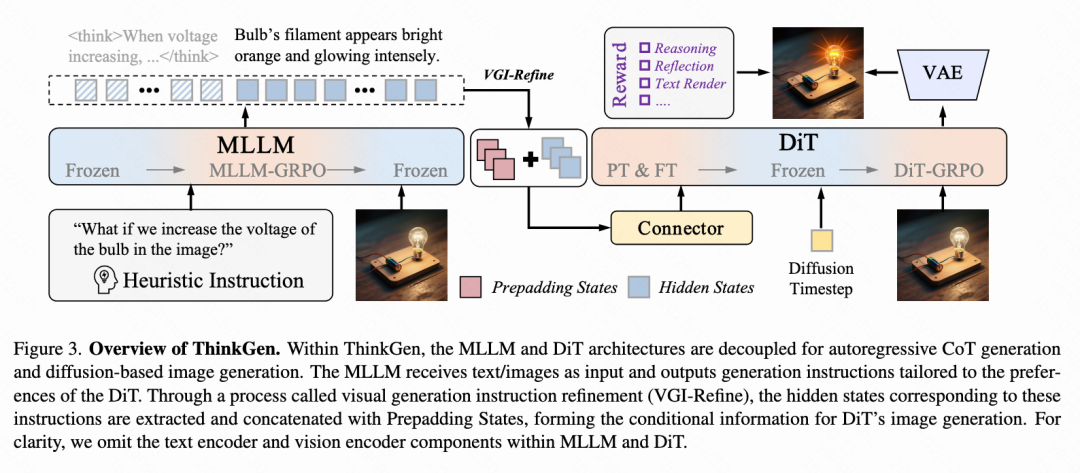
多模态大型语言模型 (MLLM)
ThinkGen 利用 MLLM 处理视觉和文本输入,并通过自回归生成进行 CoT 推理。MLLM 使用 Qwen3-VL-8B-Think 初始化。对于图像生成任务,本文设计了一个专门的系统提示([SYS])来促使 MLLM 理解用户意图并提供适当的重写指令。随后,从 </think> 标记之后生成的隐藏状态的最后两层被提取出来,作为 DiT 的条件输入。经验结果表明,使用最后两层隐藏状态对视觉生成有显著益处。
Diffusion Transformer (DiT)
ThinkGen 采用标准的 DiT 架构,并使用 OmniGen2-DiT-4B初始化。MLLM 的输出作为 DiT 的条件文本输入。在图像编辑任务中,额外的参考图像通过 VAE处理并作为条件视觉输入。视觉和文本输入与噪声潜在特征连接,实现跨模态的联合注意力。本文采用一个简单的线性层作为连接器,以对齐来自多个条件输入的特征。
VGI-refine
为了解决 MLLM 自回归思维链(CoT)输出中存在的冗余信息,本文引入了视觉生成指令提炼(VGI-refine)模块,包含两个步骤。首先,从 MLLM 生成的文本标记中提取 </think> 特殊标记之后的指令标记,从而分离出用于下游图像生成的必要 CoT 结果。其次,将 K 个可学习的 Prepadding States 连接到提取的指令标记上。这种连接调节了输出隐藏状态的数据分布,尤其对于短指令(例如,“生成一只狗”或“移除猫”)特别有益。最终得到的精炼指令状态作为条件输入提供给 DiT。
训练策略
ThinkGen 的训练分为五个不同的阶段,如下图4所示。首先,对 DiT 进行监督预训练(阶段 1-3)以确保高质量的图像生成。随后,引入了一种称为 SepGRPO 的可分离 MLLM 和 DiT 强化学习方法(阶段 4-5)。通过 SepGRPO 训练,MLLM 学习生成与 DiT 偏好最佳对齐的描述或编辑指令,而 DiT 则在此基础上进一步优化以生成更优质的图像。
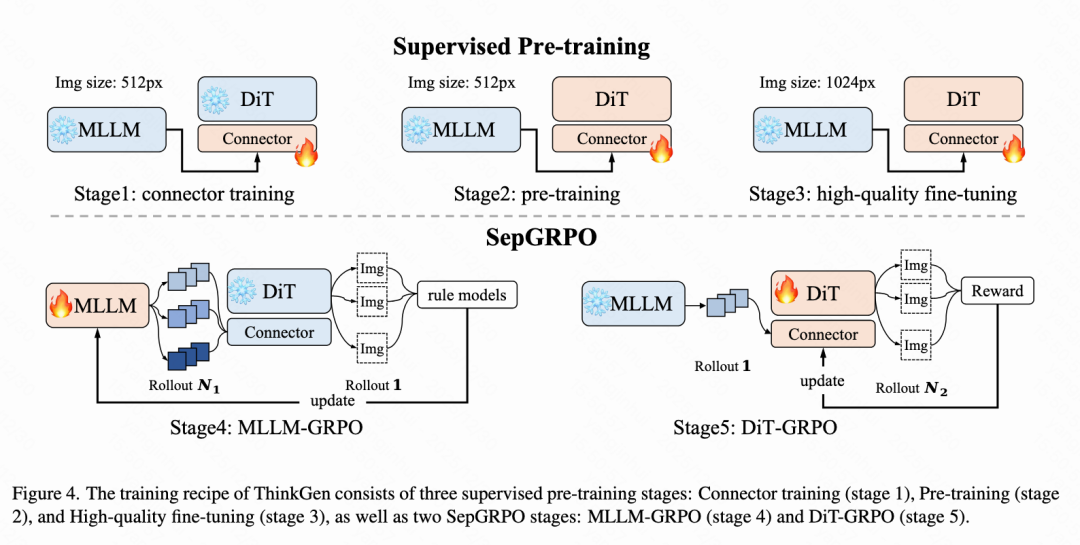
监督预训练
监督预训练阶段(阶段 1-3)旨在将 DiT 与 MLLM 对齐,同时提高图像生成质量。本文采用 Rectified Flow训练范式,通过最小化 Flow Matching 目标直接回归速度场 。
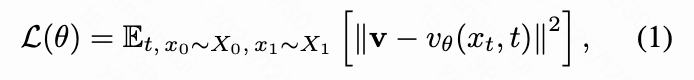
其中 表示目标速度场。
- 输入格式: 在预训练阶段,为了避免昂贵的重写每个标题或编辑指令的成本,本文构建了伪 CoT 模板来模拟 MLLM 的 CoT 过程。具体来说,
<think> </think>内的内容留空,并简单地重复原始标题或编辑指令作为答案。 - 阶段1 对齐: 在此阶段,本文引入 K 个可学习的预填充状态,并通过仅训练线性连接器来将 DiT 与 MLLM 对齐,同时保持 MLLM 和 DiT 冻结。
- 阶段2 预训练: 在此阶段,所有 DiT 参数都是可训练的。训练语料库包含 60M 图像样本,包括文本到图像、图像编辑、文本渲染和上下文生成数据。
- 阶段3 高质量微调: 在监督微调阶段,本文构建了一个 0.7M 的高质量子集,以增强 DiT 的指令遵循能力和图像美学。
SepGRPO
SepGRPO,一种强化学习训练策略,旨在鼓励 MLLM 生成与 DiT 偏好最佳对齐的标题/编辑指令,同时使 DiT 能够根据这些指令生成更高质量的图像。SepGRPO 解耦了文本和视觉的展开过程:首先,固定 DiT,通过联合多任务训练将 GRPO 应用于 MLLM;然后,固定 MLLM,将 GRPO 应用于 DiT。
- 输入格式: 在策略训练期间,本文设计了一个专门的
[SYS]来促进冷启动,允许 MLLM 探索 DiT 偏好的文本条件。具体来说,本文将[SYS]、输入样本[C]和特殊<think>标记连接起来作为 MLLM 的输入。 - 阶段4 MLLM-GRPO: 在此阶段,将 GRPO 应用于 MLLM,以鼓励生成与 DiT 偏好对齐的重写文本。本文在多个场景下优化 MLLM,以增强 CoT 推理的泛化能力。本文选择了五个代表性生成场景:语义组合、推理生成、文本渲染、图像编辑和反射。如下表1所示,针对每个场景,本文收集并整理了专用数据集,并设计了相应的规则模型来指导优化。
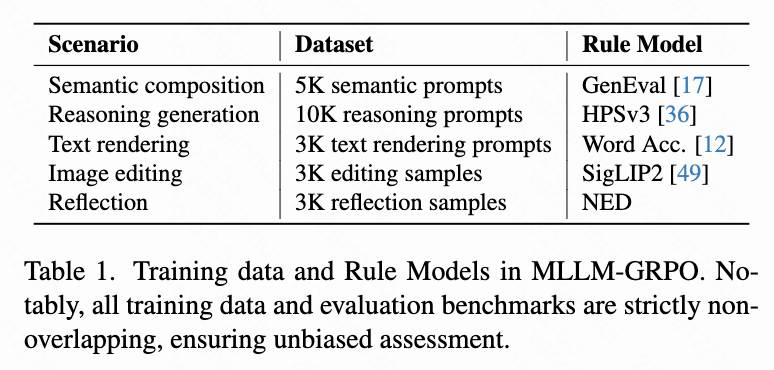
对于 MLLM 的每个输入,本文从策略 执行 次 rollout 以生成轨迹 ,然后 DiT 使用这些轨迹生成相应的图像。规则模型用于计算每个轨迹的奖励 。随后,以组相对的方式计算第 个轨迹的优势 :
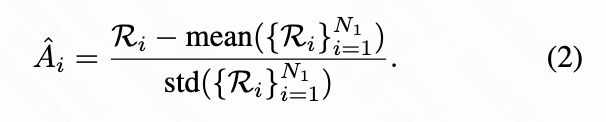
然后通过优化 GRPO 目标来更新策略 ,该目标是带有 KL 散度正则化的裁剪替代函数:
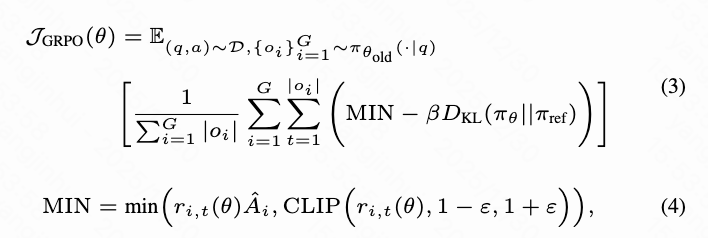
其中 表示 和 输出当前 token 的概率比。在此过程中,DiT 和规则模型共同充当奖励模型。
- 阶段5 DiT-GRPO: 在此阶段,本文应用 FlowGRPO来增强 DiT 的指令遵循能力。本文利用来自 Simple Scene 和 Text Rendering 场景的数据,以及它们相应的奖励计算方法。
实验结果总结
ThinkGen 在多种生成场景下进行了评估,并与现有方法进行了比较。结果表明,ThinkGen 在推理生成、推理编辑、文本到图像生成和图像编辑方面都取得了显著的性能提升。
推理生成
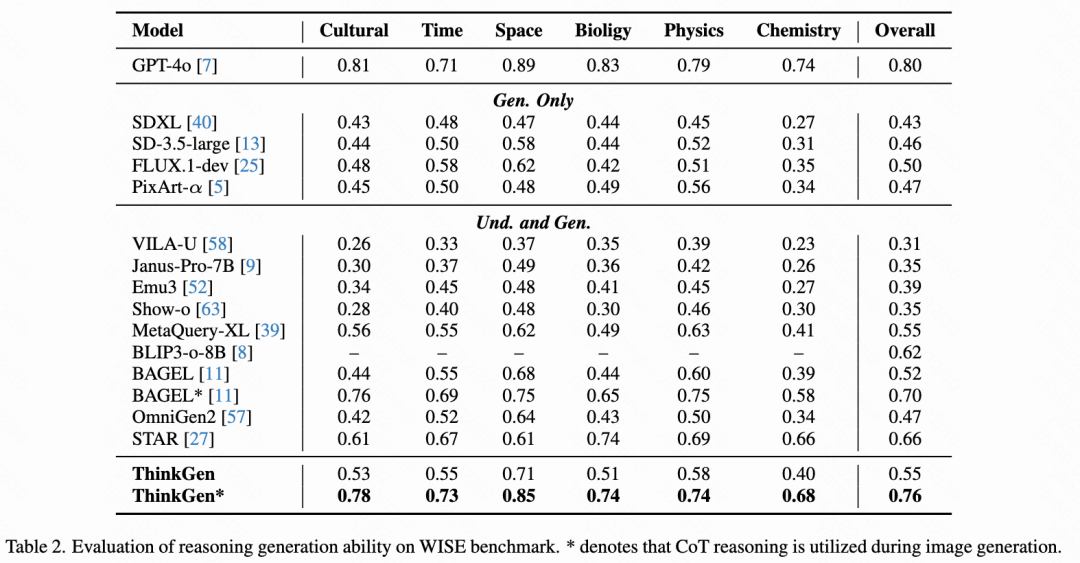
如下表2所示,在 WISEBench 基准测试中,ThinkGen 表现出优于直接生成方法的显著优势。通过利用 CoT 推理,ThinkGen 实现了 +21% (0.55 → 0.76) 的显著改进,并在 WISEBench 上建立了新的最先进性能。
推理编辑
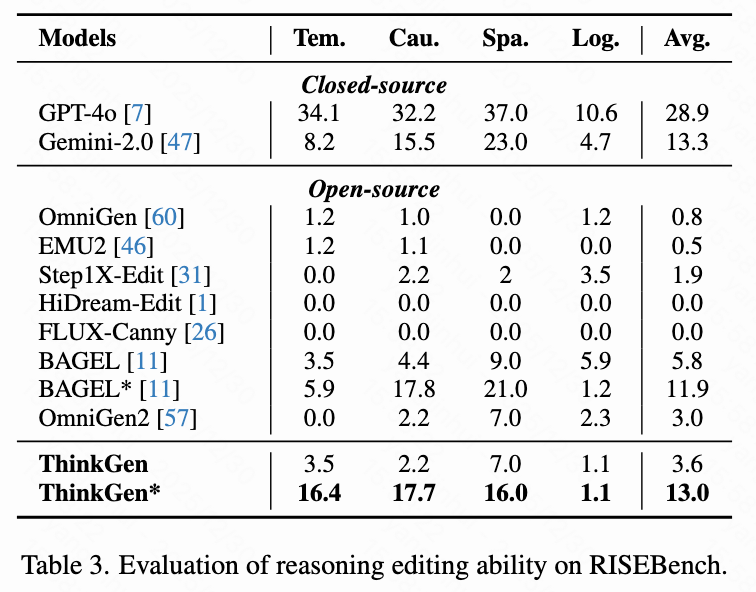
如下表3所示,在 RISEBench 上,ThinkGen 的 CoT 推理能力显著超越了开源模型(3.6 → 13.0),并取得了与闭源模型 Gemini-2.0 相当的结果。
文本到图像生成
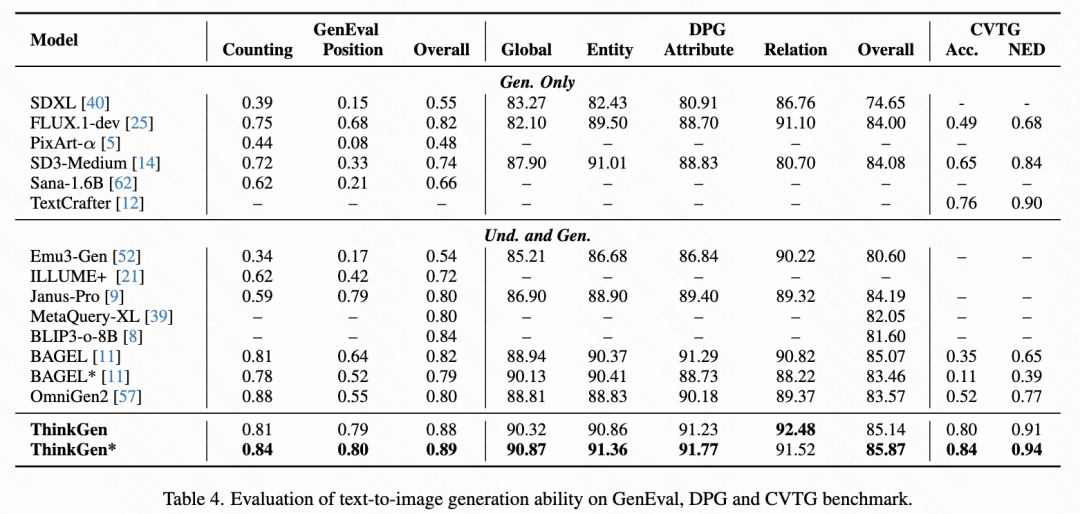
如下表4所示,ThinkGen 在 GenEval、DPG-Bench 和 CVTG 基准测试中,通过 CoT 推理,始终在所有场景中表现出改进,并在许多知名模型中取得了最佳结果。这些结果表明 ThinkGen 具有强大的指令遵循和文本渲染能力。
图像编辑
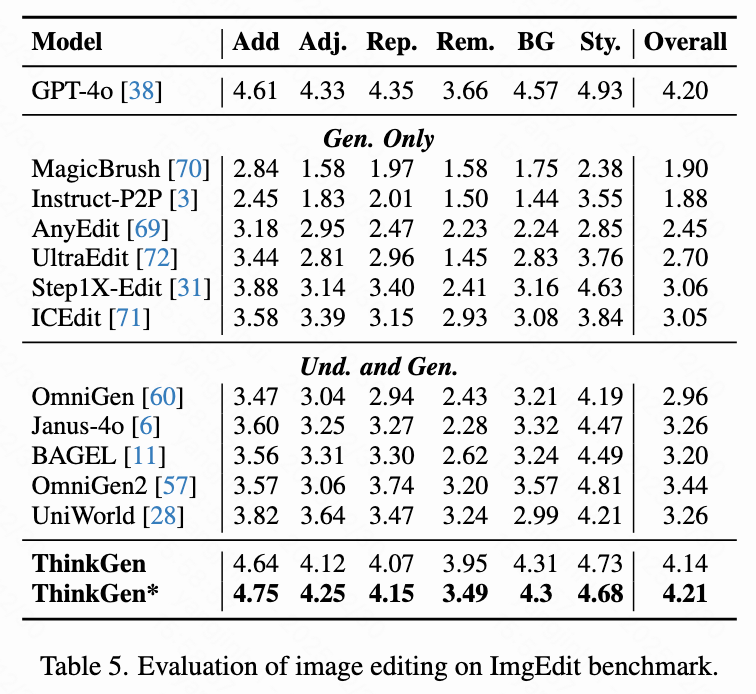
如下表5所示,在 ImgEdit 上,ThinkGen 与一系列开源模型相比,显示出显著优越的指标,取得了与 GPT-4o 相当的性能。
消融研究
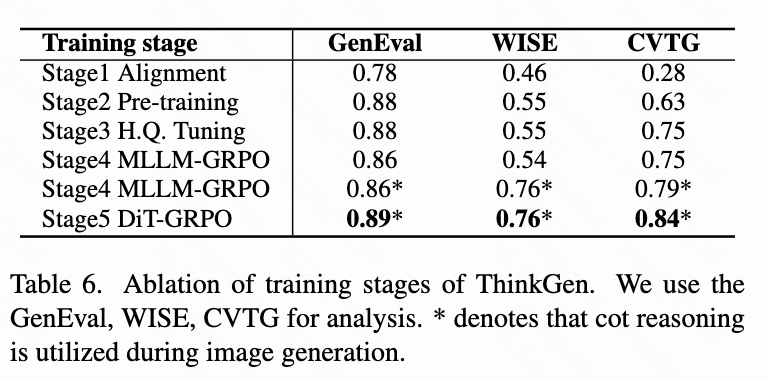
- 训练阶段消融: 如下表6所示,逐步应用每个训练阶段对 ThinkGen 的性能都有贡献。
- 仅训练连接器(Stage1)导致文本渲染性能不佳(CVTG: 0.28),表明 MLLM 和 DiT 之间缺乏足够的细粒度对齐。
- 大规模预训练(Stage2)显著改善了图像质量,GenEval 增加了 10%,WISE 增加了 9%,CVTG 增加了 35%。
- 高质量微调(Stage3)进一步增强了图像细节,CVTG 提高了 +12.0%。
- 将 GRPO 应用于 MLLM(Stage4)略微影响了 GenEval (-0.01) 和 WISE (-0.01) 上的图像生成,但结合 CoT 显著提升了推理和生成能力(WISE: 0.55 → 0.76)。
- DiT-GRPO(Stage5)进一步提高了图像生成质量,尤其是在细粒度文本渲染任务中(CVTG: 0.79 → 0.84)。
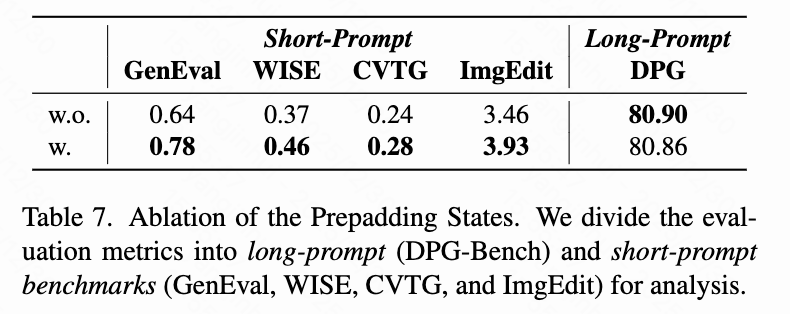
- Prepadding States: 如下表7所示,预填充状态显著改善了短提示基准测试的性能(GenEval: 0.64→0.78,WISEBench: 0.37→0.46,CVTG: 0.24→0.28,ImgEdit: 3.46→3.93)。
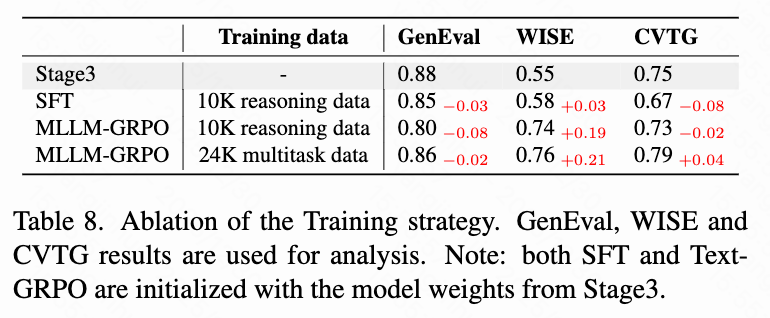
- 训练策略: 如表8所示,直接将 SFT 应用于具有推理数据的 DiT 并未改善推理基准测试的性能。然而,使用 MLLM-GRPO 训练 MLLM 极大地增强了 ThinkGen 的推理能力(WISE: 0.55 → 0.74)。
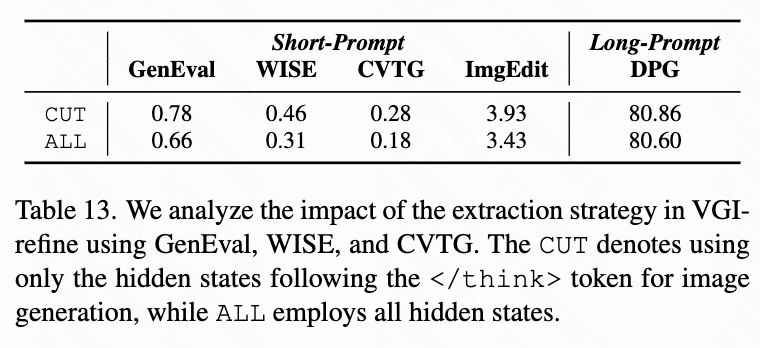
- VGI-refine 中的提取策略: 如下表13所示,仅使用
</think>标记后面的隐藏状态(CUT)比使用所有隐藏状态(ALL)在所有基准测试中都产生了持续的改进,尤其是在短提示生成任务中。这表明截断pre-</think>隐藏状态可以有效消除冗余信息,从而提高图像生成质量。
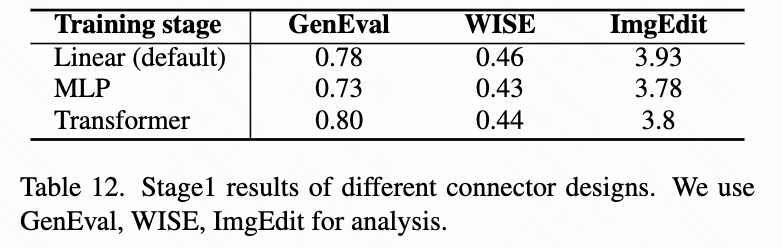
- 连接器设计: 如下表12所示,线性层连接器优于 MLP 或 Transformer 连接器。
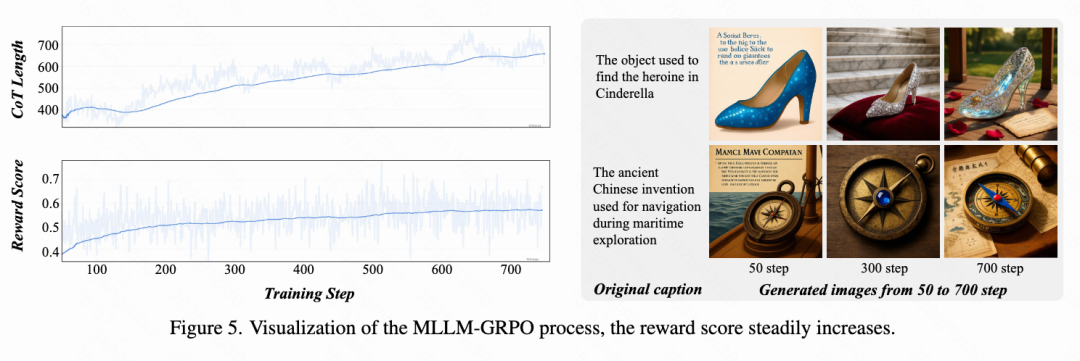
SepGRPO 过程分析
如图5所示,通过可视化 SepGRPO 的中间过程,观察到以下关键现象:
- CoT 长度增加: 平均 CoT 长度逐渐增长,表明模型在训练期间发展出更复杂的推理能力。
- 统一奖励增长: 随着训练的进行,多任务奖励稳步增加,表明 ThinkGen 学习在不同场景中自适应地思考。
- 图像质量改进: 50、300 和 700 步的图像可视化显示出图像生成质量的明显提升趋势,生成的图像展现出更丰富的细节和更高的保真度。
结论
ThinkGen,一个新颖的思考驱动框架,能够自动地将思维链(CoT)推理应用于多样化的生成任务。本文的方法采用解耦的 MLLM-DiT 架构,并通过 SepGRPO 进行训练,使其能够在生成之前制定高质量的计划。广泛的实验证明,ThinkGen 在推理密集型任务上取得了显著的改进。本工作代表着构建更智能、更通用、无缝整合推理与创造的生成模型迈出了关键一步。
参考文献
[1] ThinkGen: Generalized Thinking for Visual Generation
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-12-31,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号