在Elasticsearch中使用NVIDIA cuVS实现高达12倍速度提升的向量索引:GPU加速
原创
在Elasticsearch中使用NVIDIA cuVS实现高达12倍速度提升的向量索引:GPU加速
原创
点火三周
发布于 2025-12-11 17:55:42
发布于 2025-12-11 17:55:42

今年早些时候,Elastic宣布与NVIDIA合作,为Elasticsearch引入GPU加速,集成NVIDIA cuVS。有关详细信息,可以参考NVIDIA GTC的一个会议以及多个博客。本文是对与NVIDIA向量搜索团队共同开发工作的更新。
回顾
首先,让我们快速回顾一下。Elasticsearch已经成为一个功能强大的向量数据库,在大规模相似性搜索中提供了丰富的功能和强大的性能。它具备标量量化、改进的二进制量化(BBQ)、SIMD向量操作,以及更高磁盘效率的算法,如DiskBBQ等,提供了高效灵活的向量工作负载管理选项。
通过将NVIDIA cuVS集成为可调用模块以处理向量搜索任务,我们希望在向量索引性能和效率上实现显著提升,以更好地支持大规模向量工作负载。
挑战
构建高性能向量数据库的最大挑战之一是构建向量索引——HNSW图。随着每个向量与许多其他向量进行比较,索引构建过程迅速被数百万甚至数十亿的算术操作所主导。此外,索引生命周期操作如压缩和合并,也会进一步增加索引的计算开销。随着数据量和相关的向量嵌入呈指数增长,专为大规模并行处理和高吞吐量运算而设计的GPU在处理这些工作负载时具有理想的优势。
引入Elasticsearch-GPU插件
NVIDIA cuVS是一个开源的CUDA-X库,用于GPU加速的向量搜索和数据聚类,能够快速构建索引和提取嵌入,以支持AI和推荐工作负载。
Elasticsearch通过cuvs-java使用cuVS,这是一个由社区开发并由NVIDIA维护的开源库。cuvs-java库轻量且基于cuVS C API,使用Panama外部函数接口以惯用Java的方式暴露cuVS功能,同时保持现代和高性能。

Elasticsearch与NVIDIA cuVS、CPU和GPU索引的工作方式
cuvs-java库被集成到一个新的Elasticsearch插件中,因此,GPU上的向量索引可以在同一Elasticsearch节点和进程中进行,无需额外的代码或硬件。在索引构建过程中,如果安装了cuVS库,并且GPU存在且已配置,Elasticsearch将使用GPU加速向量索引过程。向量被传递给GPU,构建一个CAGRA图。然后将该图转换为HNSW格式,使其可以立即在CPU上进行向量搜索。构建的图的最终格式与在CPU上构建的格式相同;这允许Elasticsearch在底层硬件支持的情况下利用GPU进行高吞吐量向量索引,同时释放CPU的性能用于其他任务(如并发搜索、数据处理等)。
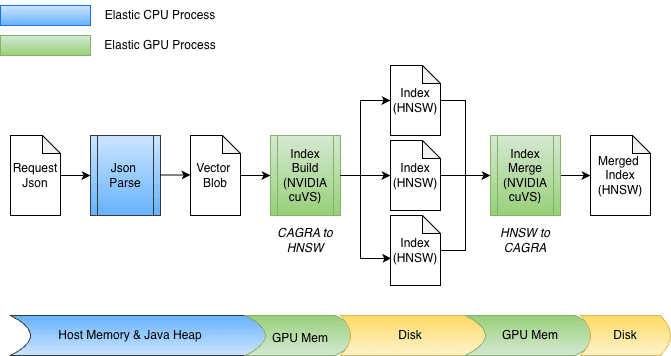
索引构建加速
作为Elasticsearch中集成GPU加速的一部分,cuvs-java进行了多项增强,重点在于高效的数据输入/输出和函数调用。一个关键的增强是使用cuVSMatrix透明地建模向量,不论它们位于Java堆内存、堆外内存,还是GPU内存中。这使得数据可以在内存和GPU之间高效移动,避免不必要的数十亿个向量副本。
由于这一底层零拷贝抽象,数据传输到GPU内存和从GPU检索图的过程可以直接进行。在索引过程中,向量首先缓存在Java堆内存中,然后发送到GPU以构建CAGRA图。该图随后从GPU中检索,转换为HNSW格式,并持久化到磁盘。
在合并时,向量已经存储在磁盘上,完全绕过Java堆。索引文件被内存映射,数据直接传输到GPU内存中。该设计还支持不同的位宽,如float32或int8,并自然扩展到其他量化方案。
那么,效果如何?
我们的初始基准测试结果非常有前景。我们在AWS的g6.4xlarge实例上运行了基准测试,该实例配备本地附加的NVMe存储。Elasticsearch的单节点配置为使用默认的最佳索引线程数(8个,每个物理核心一个),并禁用合并节流(对于快速的NVMe磁盘来说不太适用)。
对于数据集,我们使用了来自OpenAI Rally向量测试集的260万个具有1536维的向量,以base64字符串编码,并以float32 hnsw索引。在所有场景中,构建的图达到高达95%的召回率。我们的发现如下:
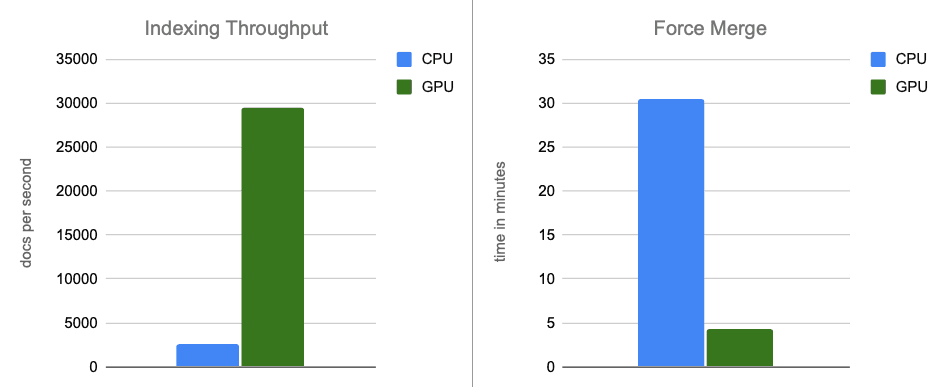
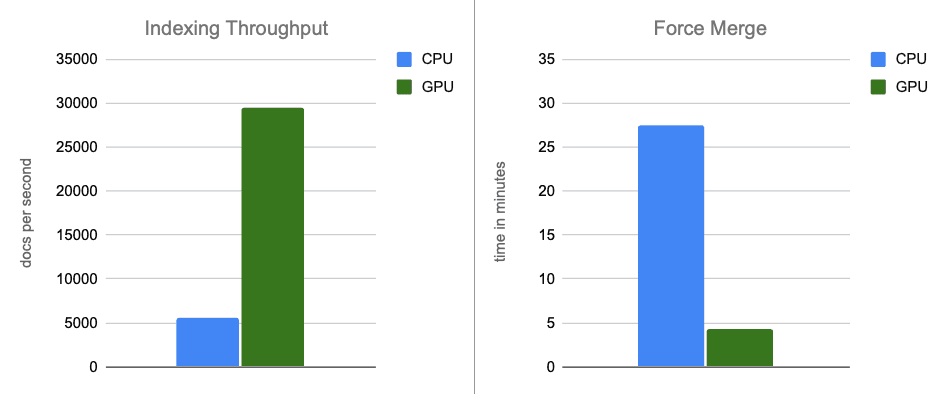
- 索引吞吐量: 通过在内存缓冲区刷新期间将图的构建转移到GPU上,我们的吞吐量提高了约12倍。
- 强制合并: 索引完成后,GPU继续加速段合并,将强制合并阶段的速度提高了约7倍。
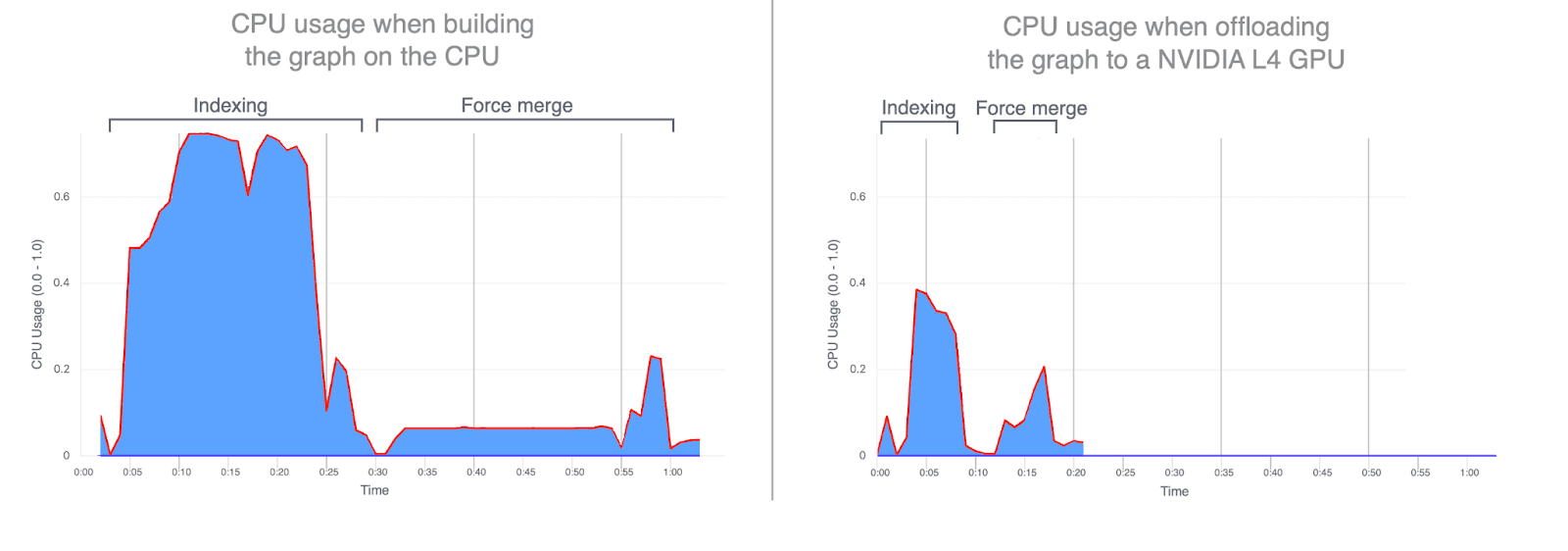
- CPU使用率: 将图的构建转移到GPU上显著减少了平均和峰值CPU利用率。下图展示了在索引和合并期间的CPU使用情况,突显出在GPU上运行这些操作时CPU使用率是多么低。GPU索引期间较低的CPU利用率释放了CPU周期,可用于提升搜索性能。
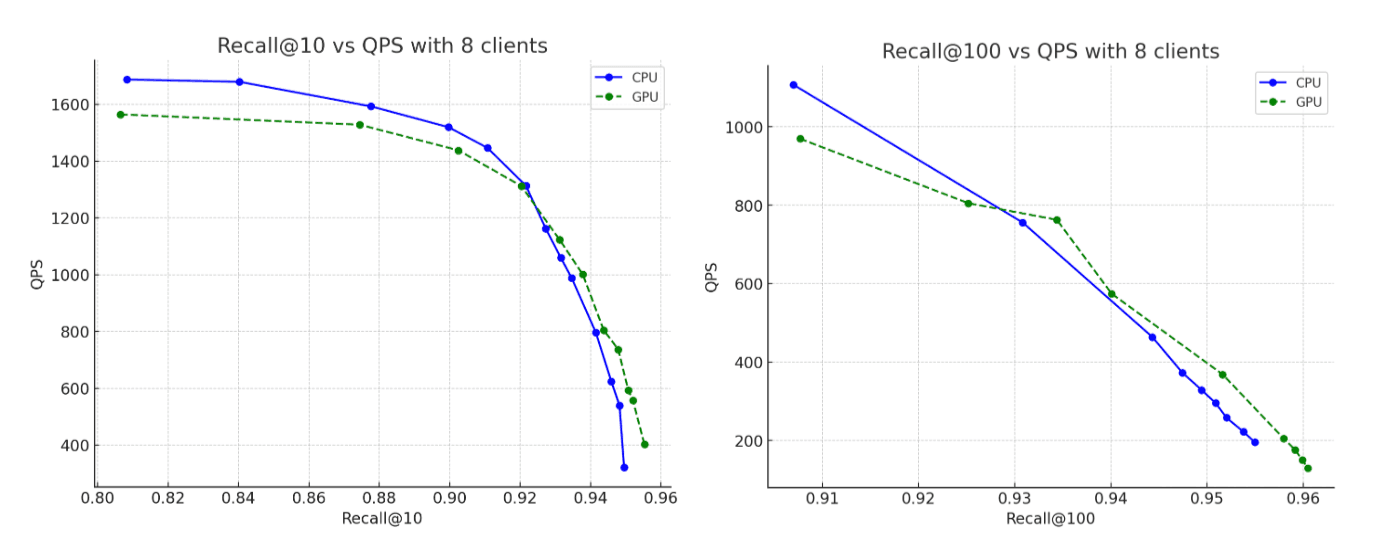
- 召回率: CPU和GPU运行之间的精度基本相同,GPU构建的图略微提高了召回率。
从另一个维度比较:价格
之前的比较有意使用了相同的硬件,唯一的区别是索引过程中是否使用了GPU。这有助于理解原始计算效果,但我们也可以从成本角度进行比较。以大致相同的价格,我们可以配置大约两倍数量的可比vCPU和RAM,即32个vCPU(AMD EPYC)和64GB内存,同时将索引线程数加倍到16。
更强大的CPU实例确实表现出比上述部分基准测试更好的性能,正如预期的那样。然而,当我们将这个更强大的CPU实例与原始的GPU加速结果进行比较时,GPU仍然提供了显著的性能提升:索引吞吐量提高约5倍,强制合并提高约6倍,同时构建的图达到高达95%的召回率。
结论
在端到端的场景中,使用NVIDIA cuVS进行GPU加速几乎提高了索引吞吐量12倍,并将强制合并延迟减少7倍,同时显著降低了CPU利用率。这表明向量索引和合并工作负载从GPU加速中获益良多。在成本调整的比较中,GPU加速继续带来显著的性能提升,索引吞吐量提高约5倍,强制合并操作速度提高约6倍。
GPU加速的向量索引计划在Elasticsearch 9.3中进行技术预览,该版本计划于2026年初发布。
敬请期待更多更新。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号