Doubao-Seed-Code 深度体验测评:支持视觉理解的编程模型
原创
Doubao-Seed-Code 深度体验测评:支持视觉理解的编程模型
原创
fanstuck
修改于 2025-11-27 10:57:36
修改于 2025-11-27 10:57:36
前言
如果不是亲自测一遍,我真的不会相信:一个国产编程模型,居然能做到“看着设计稿直接写代码”。但这次参与 Doubao-Seed-Code 的定向评测,让我第一次意识到,国内模型在 coding 场景上的突破可能真的来了——而且来的比我预想的更快、更猛烈、更具颠覆性。
我本身就是一个长期使用 Claude Code 的开发者,每天写代码、调服务、做 AI Agent、跑大模型 API,这是我的日常工作。换句话说,我对编码模型要求非常真、也非常苛刻:要么实打实提高效率,要么别来打扰我。本来是抱着“试试看”的心态来尝试豆包编程模型 Doubao-Seed-Code,却没想到体验后直接把 Claude Code 的 API 给切了——因为这个模型带来的那种“直觉冲击感”是我过去在国产 Coding 模型里从未体验过的。
最关键的一点是:它真的会“看图写代码”。下面我就结合自己的真实测试体验,把这次测评的全部过程展开。
Doubao-Seed-Code的独特之处
作为深度依赖智能体与 LLM 的开发者,我的主力工具其实一直是 Claude Code。它的体验太强:长上下文、计划能力强、重构能力强,而且对复杂任务的规划真的领先国内一大截。
但它有一个天生短板:不会看图。
这听起来像是个“小问题”,但在真实开发中,它其实是一个非常大的痛点。比如:
- 前端改样式时经常要截图:Claude 看不懂图,只能文字描述
- UI 设计稿做页面:Claude 无法理解图,只能我手动描述布局
- 样式 bug 截图:Claude 无法直接对比图,只能让我解释问题
久而久之就会意识到:程序员每天写代码,其实有 30% 的场景是和图片相关的。Doubao-Seed-Code原生支持 256K 长上下文, 轻松处理长代码文件、多模块依赖等复杂场景,实现端到端自主编程,全栈开发友好,前端能力突出。而且是国内首个支持视觉理解能力的编程模型,可参考 UI 设计稿、截图或手绘草图生成代码,也能对生成页面进行视觉比对,自主完成样式修复和 Bug 修复,大幅提升前端开发效率;登顶 SWE-Bench Verified 榜单,在多项权威评测集中表现优异。
在Terminal Bench、SWE-Bench-Verified-Openhands、Multi-SWE-Bench-Flash-Openhands 等主流测评集中表现出色,仅次于 Claude Sonnet 4.5,碾压国内模型。
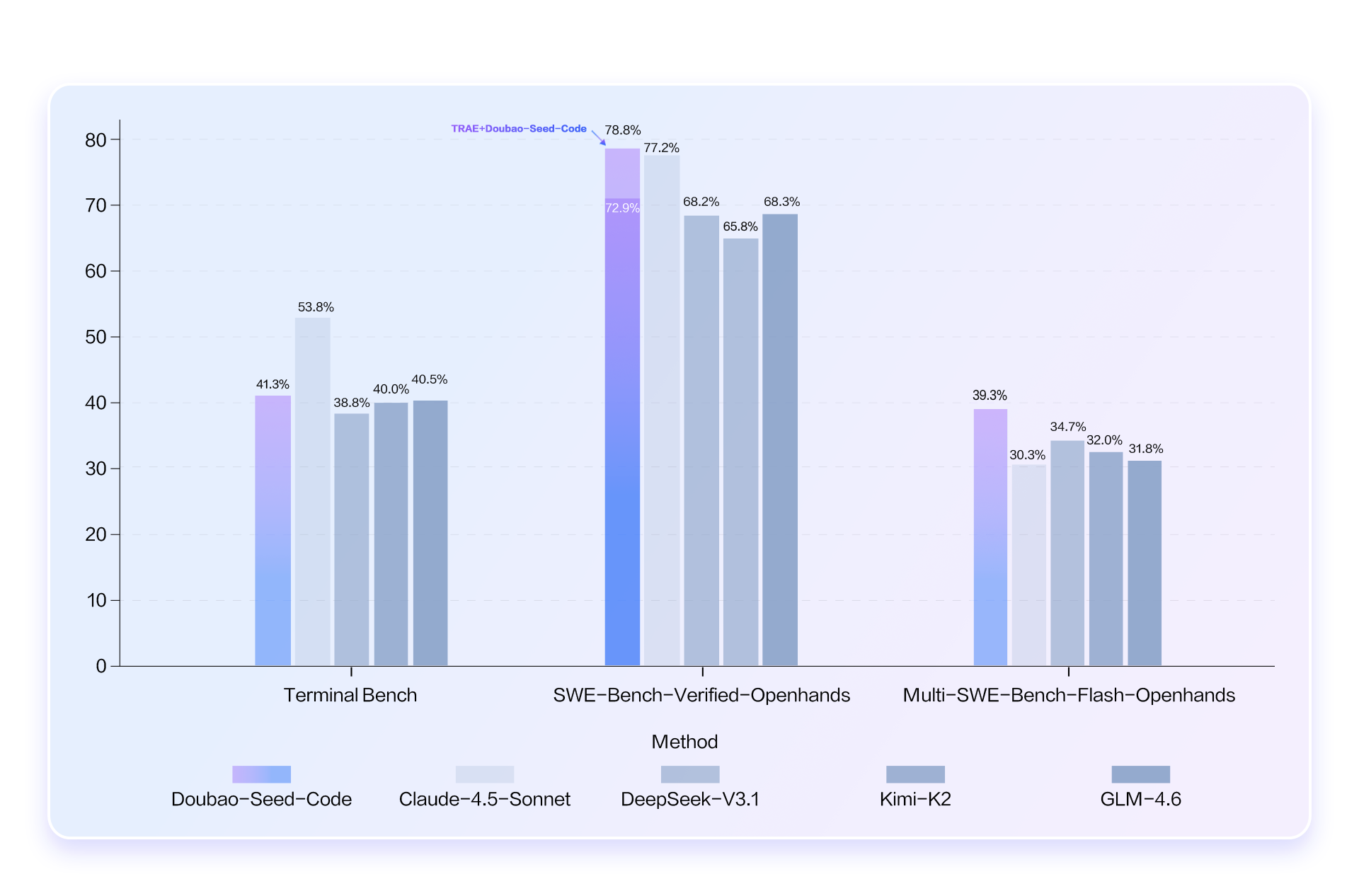
这是一件值得好好测试的事情。
配置体验
接入Doubao-Seed-Code比较简单,方舟 Code Plan 支持在多款主流的编程工具中使用,我这里使用TRAE CN进行接入,Doubao-Seed-Code模型同步登录TRAE CN,无需特殊配置,直接体验最新模型体验。同时,在TRAE CN中使用预置的Doubao-Seed-Code模型不会占用Coding Plan使用额度。
关闭Auto Mode模式选择Doubao-Seed-Code即可体验,丝滑代替。
那么我们就按照我们真实需求来

我们首先拿到一个需求文档包含UI设计:相应的附上生成的UI信息:
(一)顶部筛选区(高度:80px)
<!--br {mso-data-placement:same-cell;}--> td {white-space:nowrap;border:0.5pt solid #dee0e3;font-size:10pt;font-style:normal;font-weight:normal;vertical-align:middle;word-break:normal;word-wrap:normal;}
组件名称 | 位置 | 样式描述 | 交互逻辑 |
|---|---|---|---|
时间筛选器 | 左侧(占比 30%) | 下拉框 + 输入框组合,默认显示「近 30 天」,边框 #E0E0E0,选中态边框 #1E88E5,文字 #333333(14px) | 点击下拉框展开选项(日 / 周 / 月 / 自定义),选择「自定义」弹出日期选择器(开始日期 + 结束日期),确认后实时刷新全页面数据 |
用户类型筛选 | 中间(占比 25%) | 下拉框,默认显示「全部用户」,样式同时间筛选器 | 选项:全部用户 / 新用户 / 老用户 / 付费用户 / 非付费用户,选择后刷新关联图表(如用户特征分析、转化漏斗) |
商品类目筛选 | 右侧(占比 25%) | 下拉框,默认显示「全部类目」,样式同前 | 选项:全部类目 + TOP10 类目名称,选择后刷新商品相关图表(类目浏览 TOP10、加购商品类目分布等) |
刷新按钮 | 最右侧(占比 10%) | 图标按钮(刷新 SVG,颜色 #1E88E5,hover 色 #1565C0)+「刷新」文字(14px,#333) | 点击后加载动画(旋转 1.5 秒),同步刷新所有数据,加载期间图表显示骨架屏 |
(二)核心指标卡片区(高度:160px)
单卡片设计(4 个卡片均分宽度,间距 20px)
<!--br {mso-data-placement:same-cell;}--> td {white-space:nowrap;border:0.5pt solid #dee0e3;font-size:10pt;font-style:normal;font-weight:normal;vertical-align:middle;word-break:normal;word-wrap:normal;}
卡片名称 | 辅助信息样式 | 特殊设计 |
|---|---|---|
访问用户数 | 昨日 XX 人 / 本周 XX 人 / 本月 XX 人(#888) | 数值后加「↑XX%」(绿色 #4CAF50)或「↓XX%」(红色 #F44336),显示日环比变化 |
下单转化率 | 同比 XX% / 环比 XX%(正向绿色,负向红色) | 数值字体加大至 32px,突出核心 |
加购率 | 昨日 XX% / 本周 XX% / 本月 XX%(#888) | 卡片底部加浅蓝背景条(高度 4px,#1E88E5) |
复购率 | 近 30 天 XX%(#888) | 若低于行业均值(12%),数值颜色变为橙色 #FF9800,右侧加警示小图标(!) |
将上述需求直接输入给Doubao-Seed-Code即可开始任务编排:
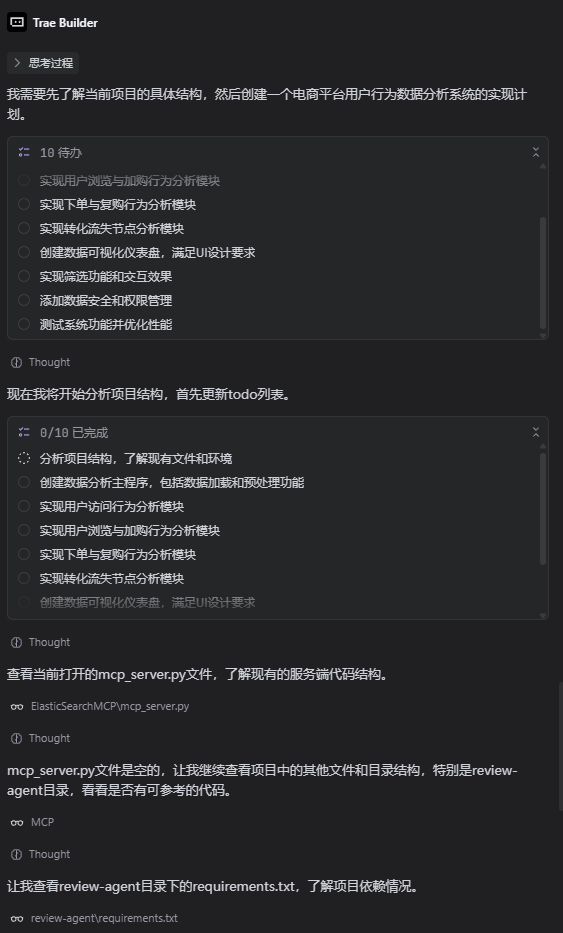
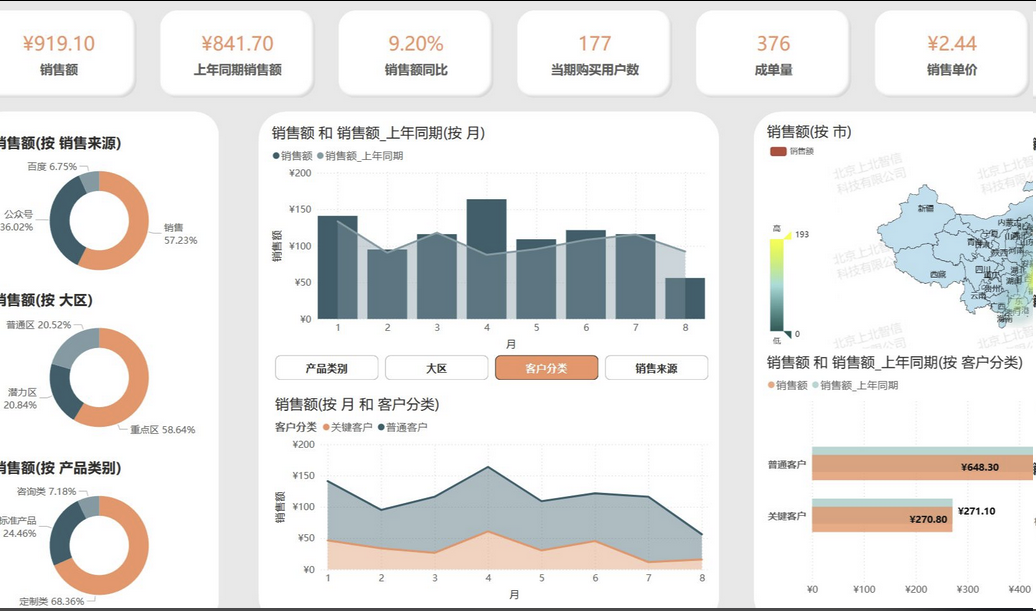
一般来说,如果是 Claude Code 或国产 coding 模型(DeepSeek / Kimi / GLM / MiniMax),会要求 MCP 转成文字描述,导致丢失大量细节,绝大多数模型无法做到视觉级别的布局还原。在以往,我是绝不会把这样一张高度复杂的电商用户行为分析仪表盘截图直接丢给模型的。因为所有国产模型过去都无法真正“看懂图”——它们会把 UI 当成一张纯图片,当你问它「帮我写个页面」时,要么说无法理解要素,要么只能依赖工具把图片转成文字描述,再由大模型根据文字来编排页面结构。这种“图片 → 文字 → 再生成代码”的链路不仅损失大量视觉细节,最终生成的页面和设计稿往往像是两个产品团队做出来的一样。
我们再把刚才那份文档化的需求(筛选条件、KPI 卡片、图表类型、颜色规范、安全要求等)连同“希望用 Python + Dash 打一套可运行 demo”的要求,一起丢给 Doubao-Seed-Code,让它自己思考项目结构、选择技术栈、规划模块划分,然后一步步把代码写出来。
从那张截图里能很清楚地看到它的工作方式:左边是一个标准的 Python 工程目录,包含 analysis.py、data_preprocessing.py、visualization_utils.py、security.py、dashboard_with_security.py 等核心模块;右边则是 TRAE 中模型的“思考过程”和每一步修改过的文件列表。模型不是一股脑儿把所有代码吐出来,而是先规划、再建文件、再补逻辑、最后整体联调,这个过程非常像一个有经验的工程师在搭项目骨架。
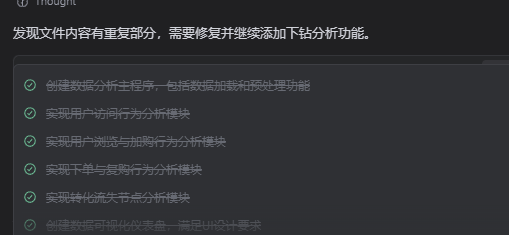
在 dashboard_with_security.py 这份文件里,可以明显看出它的“工程思路”:
- 顶部先配置好
Config对象,把系统配置、敏感字段规则、数据源等集中管理; - 使用
dash.Dash初始化应用,把 Bootstrap 主题、响应式 meta 标签、页面 title 都设置好; - 引入
SecurityManager和DataMasking,专门负责权限校验与数据脱敏——这一步几乎是“安全意识在线”的表现; - 通过
UserBehaviorAnalyzer组件完成样本数据初始化与行为分析计算,把核心指标、漏斗数据、分渠道访问分布等一并算好; - 再基于
visualization_utils.py中封装好的绘图函数,生成访问趋势折线图、渠道分布饼图、转化漏斗图、类目浏览 TOP10 柱状图以及高复购用户偏好雷达图,最后把这些组件全部挂载到 Dash 布局里。
也就是说,它不是简单写个 app.layout = ...,而是真正把“数据层 → 分析层 → 可视化层 → 安全层 → 界面层”这条链路串了起来。哪怕你从来没看过这次对话,单独把这个项目打包给一个数据分析工程师,对方大概率会觉得这是某个同事写的 demo 项目,而不是模型生成的。
更有意思的是安全这块。按照我最初给的需求,只是希望在仪表盘里“注意脱敏,不要展示手机号全量、不要展示用户真实姓名”。Doubao-Seed-Code 并没有偷懒,而是单独生成了一个 security.py,里面封装了一个简单的 SecurityManager 和若干数据脱敏策略:
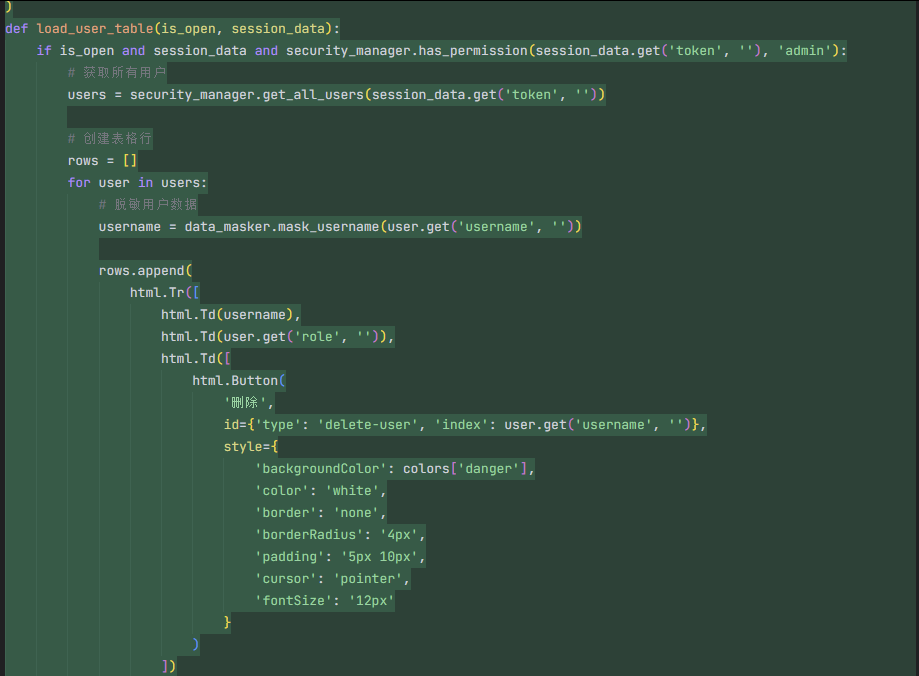
当它提示“项目整体结构已经完成,可以启动本地服务进行调试”的时候,我基本只做了两件事:pip install -r requirements.txt,然后 python dashboard_with_security.py。浏览器里弹出的,就是刚才我们在设计稿里看到的那套电商用户行为分析仪表盘——筛选条件能正常联动,图表能随时间和用户类型变化而刷新,数据脱敏生效,甚至连页面 title 和 favicon 都帮我设好了。
它能理解业务需求、能读懂 UI、能组织项目结构、能搭建数据分析链路,也能在你提醒之后,把安全、日志、配置抽象这些本该属于高级工程师思维的部分补齐。
有一个场景非常常见:我临时想到了某个页面大概长什么样,但不想手动描述结构,于是拿纸随便画了两下。以往我根本不会把这张图给大模型,因为没意义。但这次我试了一下,把我的手绘草图拍照后丢给 Doubao-Seed-Code,它能识别出我手绘的组件层级而且看懂了我乱写的箭头和文本块。这种体验非常像是“拿着白板和一个全能助手快速迭代 UI/UX 结构”,对我这种经常写前端 demo 的人来说太有用了。
那一刻我真的觉得:国产模型第一次对“真实项目调试”有了实质能力。
性能评测:官方数据 + 我的理解
官方给出的测评数据很硬:
- 在 SWE-Bench-Verified-Openhands、Multi-SWE-Bench-Flash-Openhands 的综合表现仅次于 Sonnet 4.5
- 在搭配字节自家的 TRAE IDE 时更是直接登顶 SOTA
我个人对这些 benchmark 的理解是:
- Terminal Bench 更偏终端任务与流程自动化
- SWE-Bench 更偏向真实代码环境下的问题定位、程序修复
而 Doubao-Seed-Code 最大的特点是: 它不是靠蒸馏,而是靠端到端 RL 训练出来的。
成本对比如下:
<!--br {mso-data-placement:same-cell;}--> td {white-space:nowrap;border:0.5pt solid #dee0e3;font-size:10pt;font-style:normal;font-weight:normal;vertical-align:middle;word-break:normal;word-wrap:normal;}
模型 | 成本(同等 tokens) |
|---|---|
Claude Sonnet 4.5 | 约 4.05 元 |
GLM-4.6 | 约 0.77 元 |
Doubao-Seed-Code | 约 0.34 元 |
尤其前端开发,我强烈推荐你尝试一下,它真的能省下大量脑力。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号