DeepSeek技术架构解析:MoE混合专家模型

DeepSeek技术架构解析:MoE混合专家模型

老周聊架构
发布于 2025-11-20 10:47:52
发布于 2025-11-20 10:47:52
一、前言
2025年初,DeepSeek V3以557万美元的研发成本(仅为GPT-4的1/14)和开源模型第一的排名,在全球AI领域掀起波澜。其核心创新之一——混合专家模型(Mixture of Experts, MoE)的优化设计,不仅突破了传统大模型的算力瓶颈,更以37B激活参数实现671B总参数规模的性能输出,成为开源社区与工业界关注的焦点。本文将从技术原理、工程创新以及应用潜力三个维度,深度解析这一架构的设计逻辑与行业意义。
二、什么是混合专家模型?
在有限算力条件下,优化模型架构的参数量通常比增加训练迭代次数更能有效提升模型性能。相比于盲目延长训练周期,合理扩大模型容量往往能以更低的时间成本获得更优的收敛效果。
混合专家架构(MoE)的突破性价值体现在其独特的计算效率优势——该架构通过动态激活专家模块的机制,可在大幅降低算力消耗的同时完成高质量预训练。这使得研发团队在同等硬件资源下,既可尝试构建超大规模语言模型,也能拓展训练数据边界。特别值得关注的是,该架构在基础训练阶段展现出显著的训练速率优势,相较于传统稠密网络结构,能以更短的时间周期达成同等级别的模型能力指标。
混合专家模型(MoE)本质上是一种改进版的Transformer架构,其核心创新点在于引入动态计算的模块化结构,具体可通过以下维度理解:
- 稀疏 MoE 层:不同于传统Transformer中每个前馈网络(FFN)层采用固定结构的密集计算方式,MoE通过拆分-重组架构实现计算稀疏化。在典型设计中,单层会被拆解为平行的多个专业处理单元(常见如8-128个)。这些单元虽形式上保留FFN的结构特性,但每个单元都会通过参数差异化训练发展出独特的特征处理能力,甚至允许嵌套式MoE架构形成多级专家筛选体系。
- 门控网络或路由: 模型内部嵌入可训练的决策神经网络作为调度中枢,该子系统在实时推断过程中执行两项关键职能:
这种动态路由机制使模型总参数量呈指数级增长的同时,单个样本前向传播的计算量仅需激活约13%-25%的专家模块。这种稀疏激活范式正是MoE在保持模型巨大知识容量的同时,显著降低算力消耗的本质原因。
- 语义特征解析:对每个输入的词语切片进行特征解构,分析其潜在语义需求。
- 动态专家调度:基于语义特征矩阵与专家能力矩阵的匹配度计算,将各词语切片智能分配到最适配的1-2个专家模块进行处理。例如"量子"可能被指向物理学知识专家,而"语法"则分配给语言学专家。
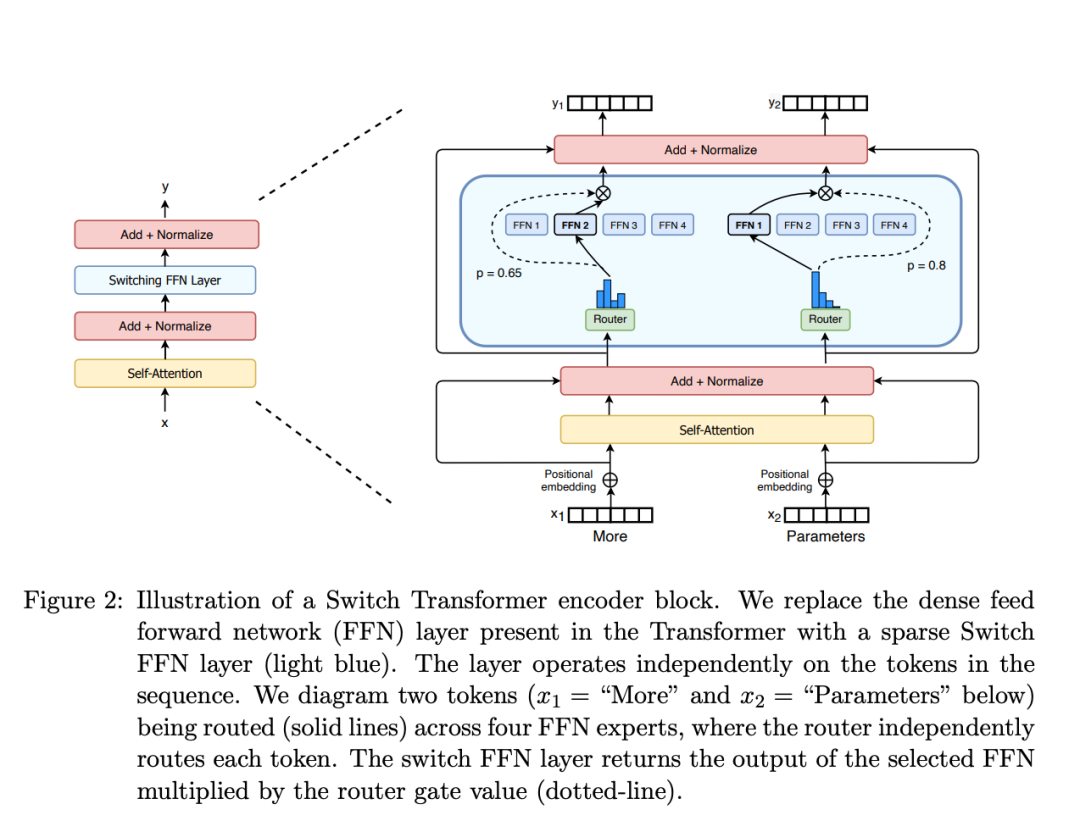
该图参考论文:https://arxiv.org/pdf/2101.03961
例如,在上图中,“More”这个令牌可能被发送到第二个专家,而“Parameters”这个令牌被发送到第一个专家。有时,一个令牌甚至可以被发送到多个专家。
尽管混合专家模型 (MoE) 提供了若干显著优势,例如更高效的预训练和与稠密模型相比更快的推理速度,但它们也伴随着一些挑战:
- 训练挑战: 虽然 MoE 能够实现更高效的计算预训练,但它们在微调阶段往往面临泛化能力不足的问题,长期以来易于引发过拟合现象。
- 推理挑战:1)内存黑洞效应
2)计算量子隧穿现象
- 当每个token激活2个专家时,理论计算量=2x7B部分 + 共享7B部分,等效于约(7x2+7x0.35)=16.45B FLOPs。
- 对比稠密模型:14B模型的FLOPs=14x1.35≈18.9B,实际速度优势达23%(归功于并行计算优化)。
- 理论参数量陷阱:以Mixtral 8x7B为例,其真实参数量=专家非共享参数(8专家x FFN参数)+共享参数(注意力模块等)。假设标准Transformer中FFN占65%参数,则总参数量=0.65x7Bx8 + 0.35x7B=36.4B + 2.45B≈39B而非表面56B。
- 显存加载刚性需求:即使每次推理仅激活部分专家,仍需完整加载47B参数的张量图谱(存在参数重复优化空间)。
三、混合专家模型简史
3.1 萌芽期(1991-2010):模块化思想的觉醒
- 1991年:Robert Jacobs提出原始MoE框架《Adaptive Mixtures of Local Experts》,通过人工设计的分段函数,让多个"专家网络"分别处理输入空间的不同区域,门控网络基于输入分配权重(类似加权投票机制)
- 理论基础:Hinton《Adaptive Mixtures of Local Experts》的数学证明(1994),验证专家网络通过"分治策略"提升模型容量的有效性
- 技术制约:手工特征工程时代,MoE的专家区分难以自动化,需预先定义专家分工(如按图像区域划分)
3.2 探索期(2011-2016):深度学习的催化剂
- 动态路由突破:Shazeer在《Outrageously Large Neural Networks》(2017预印本)中提出可训练的门控网络,允许专家选择自动演化
- 硬件红利:GPU算力崛起后,Google首次在LSTM+MoE结构上验证百亿参数规模可行性(4个expert)
- 初步问题:负载不均衡(某些专家被过度选择)、训练不稳定(门控网络与专家博弈)
3.3 爆发期(2017至今):Transformer时代的重构
3.3.1 阶段1:架构重塑(2017-2021)
- Transformer嫁接:Google将MoE层嵌入Transformer,替代传统FFN(GShard项目,2020),用2048个专家处理多语言翻译任务
- 稀疏计算革命:Switch Transformer(2021)证明单个token仅激活1个专家时,可在1T参数量下维持可行计算成本
特别是在 2017 年,Shazeer 等人 (团队包括 Geoffrey Hinton 和 Jeff Dean,后者有时被戏称为 “谷歌的 Chuck Norris”) 将这一概念应用于 137B 的 LSTM (当时被广泛应用于 NLP 的架构,由 Schmidhuber 提出)。通过引入稀疏性,这项工作在保持极高规模的同时实现了快速的推理速度。这项工作主要集中在翻译领域,但面临着如高通信成本和训练不稳定性等多种挑战。
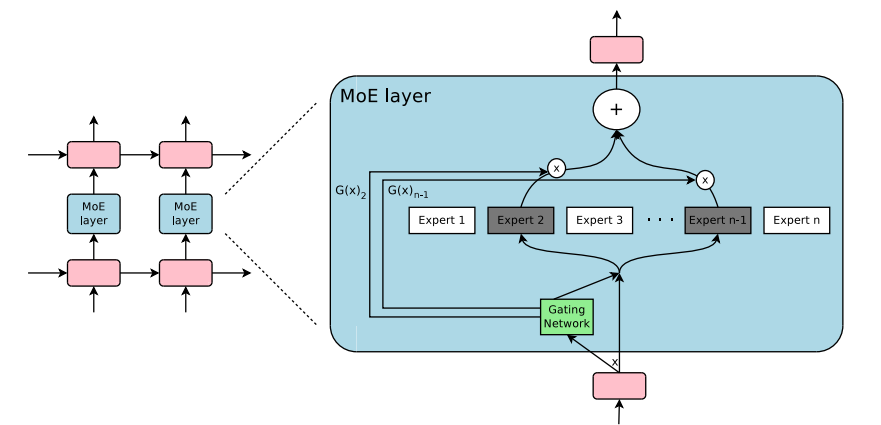
Outrageously Large Neural Network 论文中的 MoE layer
Outrageously Large Neural Network 论文中的 MoE layer
3.3.2 阶段2:工程攻坚(2021-2023)
- 内存优化:DeepSpeed-MoE提出专家分片存储(ZeRO-Offload)、动态加载策略,使单个GPU可运行万亿级MoE
- 路由算法革新:
- BASE Layer(2022):用贝叶斯优化缓解专家负载不均衡
- 微软引入Dropout式专家随机丢弃,防止门控网络过早固化
3.3.3 阶段3:开放生态(2023至今)
- 开源引爆点:Mistral AI的Mixtral 8x7B(2023.12)首次在消费级GPU集群证明MoE的高性价比
- 多模态融合:Google的V-MoE(Vision MoE)将专家划分应用于图像patch处理,在ImageNet上节省30%FLOPs
3.4 未来挑战的冰山一角
- 动态弹性:如何在运行时自动增减专家数量(类似Kubernetes Pod扩缩容)
- 量子化困境:专家参数因稀疏激活导致的非稳态分布,使8-bit量化精度损失达4.2倍于稠密模型
- 伦理风险:门控网络的黑盒机制可能引发知识来源不可追溯性危机
四、模型结构
混合专家模型(MoE)是一种稀疏门控制的深度学习模型,它主要由一组专家模型和一个门控模型组成。MoE的基本理念是将输入数据根据任务类型分割成多个区域,并将每个区域的数据分配一个或多个专家模型。每个专家模型可以专注于处理输入这部分数据,从而提高模型的整体性能。
MoE架构的基本原理非常简单明了,它主要包括两个核心组件:GateNet和Experts。GateNet的作用在于判定输入样本应该由哪个专家模型接管处理。而Experts则构成了一组相对独立的专家模型,每个专家负责处理特定的输入子空间。
五、门控网络
混合专家模型中“门”是一种稀疏门网络,它接收单个数据元素作为输入,然后输出一个权重,这些权重表示每个专家模型对处理输入数据的贡献。一般是通过softmax门控函数通过专家或token对概率分布进行建模,并选择前K个。
门控网络的稀疏性设置存在一些挑战。例如,在混合专家模型 (MoE) 中,尽管较大的批量大小通常有利于提高性能,但当数据通过激活的专家时,实际的批量大小可能会减少。比如,假设我们的输入批量包含 10 个令牌, 可能会有五个令牌被路由到同一个专家,而剩下的五个令牌分别被路由到不同的专家。这导致了批量大小的不均匀分配和资源利用效率不高的问题。
那我们应该如何解决这个问题呢?一个可学习的门控网络 (G) 决定将输入的哪一部分发送给哪些专家 (E):
在这种设置下,虽然所有专家都会对所有输入进行运算,但通过门控网络的输出进行加权乘法操作。但是,如果 G (门控网络的输出) 为 0 会发生什么呢?如果是这种情况,就没有必要计算相应的专家操作,因此我们可以节省计算资源。那么一个典型的门控函数是什么呢?一个典型的门控函数通常是一个带有 softmax 函数的简单的网络。这个网络将学习将输入发送给哪个专家。
Shazeer 等人的工作还探索了其他的门控机制,其中包括带噪声的 TopK 门控 (Noisy Top-K Gating)。这种门控方法引入了一些可调整的噪声,然后保留前 k 个值。具体来说:
- 添加一些噪声
2. 选择保留前 K 个值
3. 应用 Softmax 函数
这种稀疏性引入了一些有趣的特性。通过使用较低的 k 值 (例如 1 或 2),我们可以比激活多个专家时更快地进行训练和推理。为什么不仅选择最顶尖的专家呢?最初的假设是,需要将输入路由到不止一个专家,以便门控学会如何进行有效的路由选择,因此至少需要选择两个专家。
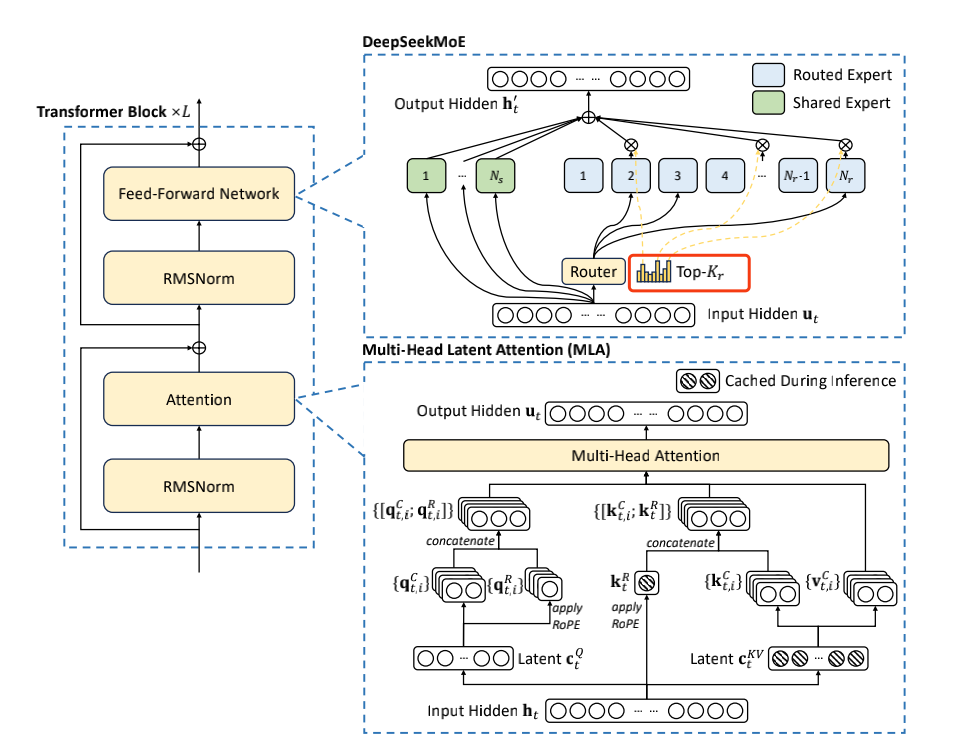
在这里插入图片描述
从DeepSeek V3的技术报告中看到的架构图中,MoE中的门控网络对应的是DeepSeekMoE的Router模块,也可以得知DeepSeek是采用的带噪声的TopK门控网络。
5.1 传统门控网络与DeepSeek路由器模块的设计差异
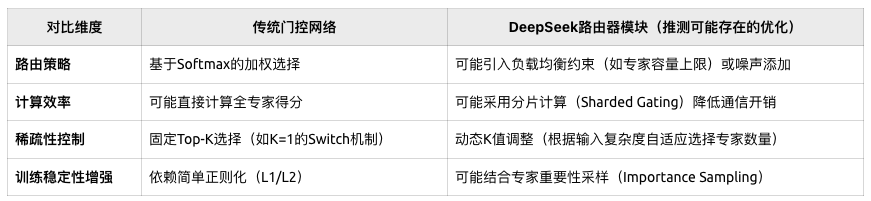
在这里插入图片描述
举例说明:
在Google的Switch Transformer中,门控网络采用Top-1严格稀疏(每个输入只需激活一个专家),而DeepSeek可能的路由器模块可能更灵活(如动态负载均衡)。
5.2 DeepSeek路由器模技术创新点
- 分布式路由:将路由决策拆解到多个子模块(如分层次专家集群)。
- 轻量化设计:用低秩矩阵分解(Low-Rank Factorization)压缩路由器参数。
- 混合路由信号:结合输入特征与外部元信息(如用户ID、任务类型)联合决策。
5.3 为什么要添加噪声呢?
这是为了专家间的负载均衡!正如之前讨论的,如果所有的令牌都被发送到只有少数几个受欢迎的专家,那么训练效率将会降低。在通常的混合专家模型 (MoE) 训练中,门控网络往往倾向于主要激活相同的几个专家。这种情况可能会自我加强,因为受欢迎的专家训练得更快,因此它们更容易被选择。为了缓解这个问题,引入了一个 辅助损失,旨在鼓励给予所有专家相同的重要性。这个损失确保所有专家接收到大致相等数量的训练样本,从而平衡了专家之间的选择。
六、专家
6.1 专家类型定义
- Share专家(全时激活的共享专家)
- 角色:全局特征处理器
- 行为:每个输入Token必须流经Share专家,类似于一个"基础服务层"(Base Layer)
- 特点:参数固定参与所有计算,捕获通用语义模式
- Router专家(动态路由选择的领域专家)
- 角色:特化特征增强器
- 行为:仅激活与当前Token最相关的k个Router专家
- 特点:每个专家专注不同语义域,形成分治协作的增强网络
6.2 双轨计算流程
6.2.1 Share路径的基础处理
每个Token自动经过Share专家的前向传播:
6.2.2 Router路径的动态筛选
Phase 1 - 亲和度分组预选
- 将全部Router专家划分为个组(例如每个组含8个专家)
- 对每个组执行局部打分: 其中线性投影层将Token隐空间映射到专家匹配度空间
- 选择总分最高的个组(例如前4组)
Phase 2 - 组内专家精筛
- 在预选组中独立计算各专家的原始亲和度
- 对各组内的专家执行组内排序,选取局部专家
- 跨组合并所有候选专家,保留全局个高亲和力专家
Phase 3 - 激活与加权
- 对被选中的k个Router专家执行前向计算
- 对它们的输出按亲和度进行Softmax加权: 其中为温度系数,控制分布锐度
- 生成Router路径的集成输出:
6.3 双路径融合
最终MoE层输出的合成策略:
其中为可学习的融合系数或在训练中渐进增长的增强因子(例如从0到1的线性缩放)
6.4 DeepSeekMoE架构
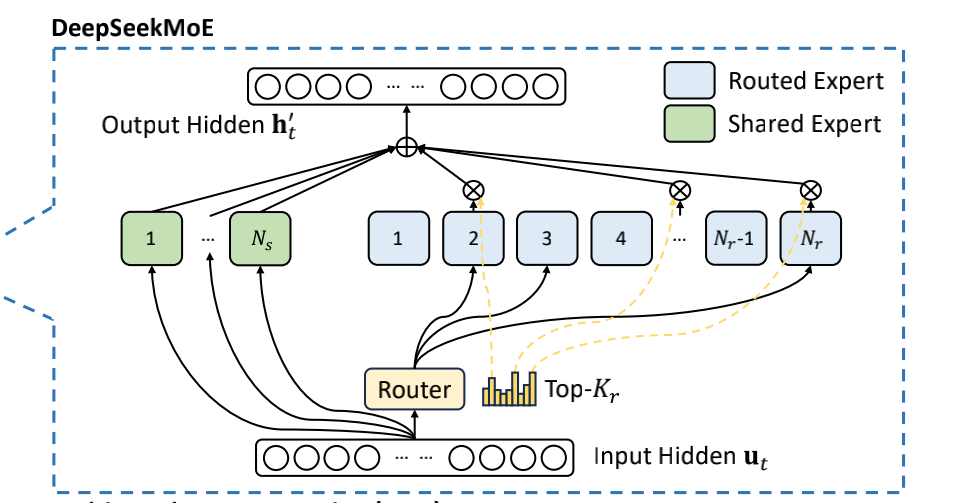
在这里插入图片描述
通过上面专家类型定义、双轨计算流程、双路径融合的讲解,再结合DeepSeekMoE的架构图,对于DeepSeek的专家设计也就清晰了。
6.4 创新设计要点
- 分层路由机制 通过分组粗筛降维(例如从64专家到4组),减少了全局排序的计算代价。数学上,筛选复杂度从降
- 共享基底稳定性 Share专家作为默认通路,即使Router路径完全失效(如亲和度全为0),模型仍保有基础表征能力
- 硬件友好设计 分组筛选适合GPU的SIMD并行结构(组内可并行计算),同时降低GPU显存的峰值占用量
欢迎大家关注我的公众号【老周聊架构】,AI、大数据、云原生、物联网等相关领域的技术知识分享。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-03-23,如有侵权请联系 cloudcommunity@tencent.com 删除
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号