论文精读(二)| 开源软件漏洞感知技术综述


笔者链接:扑克中的黑桃A
专栏链接:论文精读
本文关键词:开源软件; 漏洞感知; 软件安
引
诸位技术同仁:
本系列将系统精读的方式,深入剖析计算机科学顶级期刊/会议论文,聚焦前沿突破的核心机理与工程实现。
通过严谨的学术剖析,解耦研究范式、技术方案及实证方法,揭示创新本质。我们重点关注理论-工程交汇点的技术跃迁,提炼可迁移的方法论锚点,助力诸位的技术实践与复杂问题攻坚,共推领域持续演进。
文献来源
詹奇, 潘圣益, 胡星, 鲍凌峰, 夏鑫. 开源软件漏洞感知技术综述.
软件学报, 2024, 35(1): 19–37.
10.13328/j.cnki.jos.006935doi: 10.13328/j.cnki.jos.006935
已标明出处,如有侵权请联系笔者。
一.解决的问题
开源软件就像一座共享的大厦,无数开发者添砖加瓦,让它越来越宏伟。但这座大厦也藏着不少 “暗门”—— 漏洞。2021 年的 Log4j 漏洞就像一把钥匙,让攻击者轻易闯入了 93% 的企业云端环境,造成巨大损失。这类漏洞并非个例,据 Synopsys 报告,81% 的开源代码库至少包含一个漏洞。如何在漏洞被利用前提前发现?《开源软件漏洞感知技术综述》一文系统梳理了当前的解决方案,从代码分析到社区讨论,再到补丁追踪,全方位构建漏洞防御网。
二.为什么开源软件漏洞更难防?
开源软件的魅力在于 “透明”—— 代码公开、开发过程可见,但这份透明也给漏洞感知带来了特殊挑战。想象一下,传统软件的漏洞就像封闭房间里的老鼠,难发现但也难传播;而开源软件的漏洞就像广场上的老鼠,人人都能看见,攻击者自然也能更快找到并利用。
1. 开源软件的 “双刃剑” 特性
透明性
源代码和开发记录(如缺陷报告、提交日志)完全公开。这就像把房子的设计图贴在门口,攻击者能轻松找到结构弱点,而防御者也能借助众人之力排查隐患。
协同开发
全球开发者共同参与,安全规范难以统一。就像多人合写一篇文章,有人注重语法,有人注重逻辑,难免出现疏漏。
披露延迟
漏洞修复后,正式披露可能延迟数天到数年。这期间,用户 unaware 漏洞存在,相当于房子修好了却没通知住户换锁。
2. 漏洞生命周期中的防御窗口
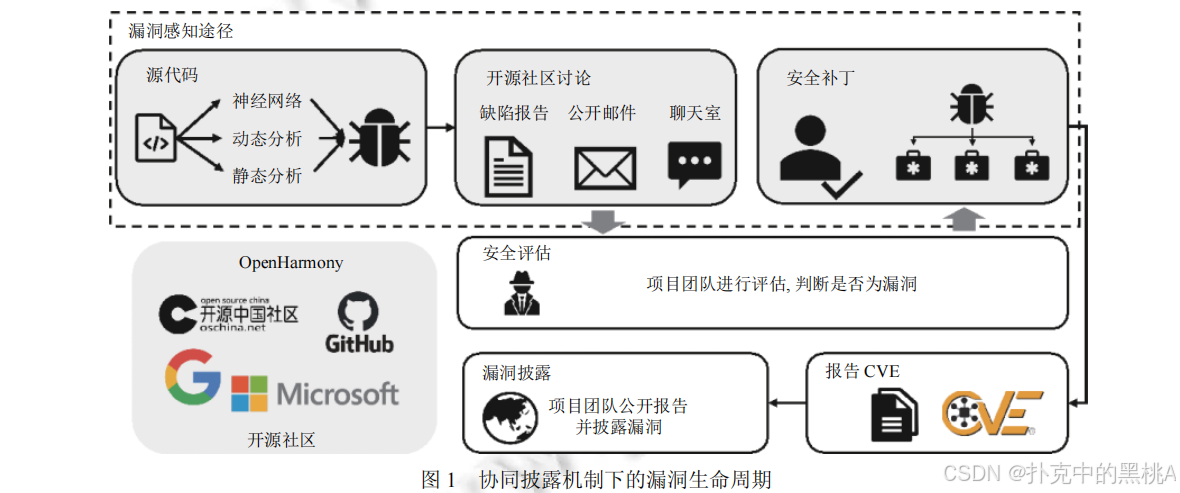
如图 1 所示,在漏洞正式披露前,有三个关键防御窗口:
代码层面:直接扫描源代码,像安检仪一样排查潜在风险。
社区讨论:监测缺陷报告、邮件列表等,从开发者的只言片语中捕捉漏洞信号。
补丁分析:通过代码变更记录,识别隐秘的漏洞修复,相当于从 “补过的墙” 反推哪里曾有破洞。
这篇综述首次从漏洞生命周期角度分类技术,让我们能按图索骥,理解不同阶段的防御手段。
三.基于代码的漏洞感知:像 “体检” 一样扫描代码
代码是漏洞的 “发源地”,直接分析代码就像给软件做体检,通过各种 “检测仪器” 找出潜在病灶。这类技术主要包括机器学习、静态分析、动态分析和混合方法四类。
1. 机器学习:让 AI 学会 “看” 漏洞
机器学习就像训练警犬识别炸药,通过大量样本让模型记住漏洞的 “气味”。近年来,预训练模型和图神经网络成了 “明星警犬”。
图神经网络(GNN)
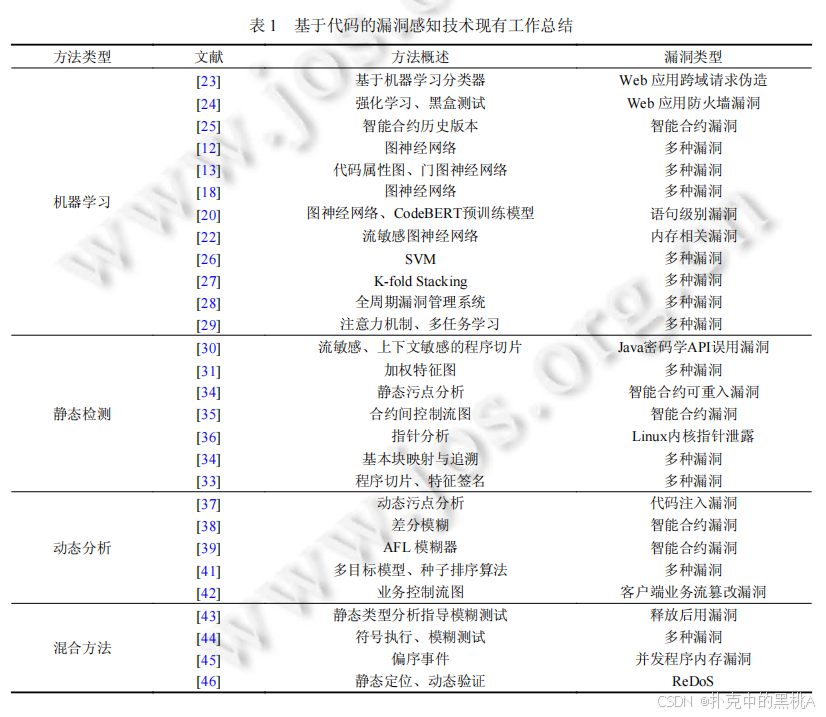
代码的语法和语义关系可以用图表示(如控制流图、数据流图),GNN 能像人看地图一样理解这些关系。例如 2020 年提出的 FUNDED 模型,通过分析程序的语法和控制流,在多语言数据集上的表现远超传统方法【此处插入表 1 中的机器学习部分】。
预训练模型
CodeBERT、GraphCodeBERT 等模型就像 “代码通”,先在海量代码上学习,再微调用于漏洞检测。2022 年的 LineVD 工具结合 CodeBERT 和 GNN,把漏洞检测精度提升到语句级别,F1 值比传统方法提高 105%。
针对特定漏洞
Web 应用的跨站请求伪造(CSRF)、智能合约的重入漏洞等,都有专门的机器学习模型。例如 RAT 工具用强化学习模拟攻击,高效发现 Web 防火墙的漏洞。
2. 静态分析:不运行代码也能找漏洞
静态分析就像 X 光扫描,不启动程序就能看透代码结构。它通过规则或符号推理,找出违反安全规范的片段。
密码学 API 误用检测
2019 年的 CryptoGuard 工具专门检查 Java 代码中加密 API 的使用错误。它像密码学专家一样,能发现 “用 MD5 加密敏感数据” 这类低级错误,在 46 个 Apache 项目中发现 39 个存在加密误用。
智能合约漏洞
2020 年的 Clairvoyance 工具用静态污点分析追踪智能合约中的数据流向,像侦探跟踪线索一样,发现可重入漏洞(攻击者重复调用合约窃取资产的漏洞)。
内核漏洞
2021 年的 KALD 工具聚焦 Linux 内核的指针泄露,通过分析指针流向,判断敏感指针是否会泄露给用户空间,在 Linux 4.14 中发现 73 个相关漏洞。
3. 动态分析:让程序 “动起来” 暴露漏洞
动态分析好比压力测试,通过运行程序并输入特殊数据,观察是否出现异常。模糊测试(Fuzzing)是其中的 “主力部队”。
差分模糊测试
2019 年的 Evmfuzzer 工具同时运行两个以太坊虚拟机(待检测版本和基准版本),对比执行结果差异,像找不同游戏一样发现虚拟机漏洞。
智能合约专用模糊器
2020 年的 sFuzz 针对 Solidity 合约,结合 AFL 策略和多目标优化,能更快覆盖代码分支,发现整型溢出等漏洞。
业务逻辑漏洞
2020 年的 Kim 等人提出的方法,像侦探还原案件一样,分析业务流程中可篡改的关键点,成功绕过 23 个网站的付费墙、广告拦截检测等。
4. 混合方法:取长补短的 “组合拳”
静态分析精准但覆盖范围有限,动态分析全面但效率低,混合方法就像中西医结合,兼顾两者优势。
类型状态引导模糊测试
2020 年的 UAFL 工具先通过静态分析识别 “释放后使用” 漏洞的危险操作序列(如先释放内存再访问),再指导模糊测试生成针对性输入,像导航仪一样引导测试方向。
缺陷驱动混合测试
2020 年的 SAVIOR 工具优先对可能暴露漏洞的代码片段进行符号执行,像医生优先检查症状明显的部位,比传统方法发现更多漏洞。
四.基于开源社区讨论的漏洞感知:从 “闲聊” 中抓漏洞信号
开源社区的讨论就像开发者的 “茶馆”,漏洞信息可能藏在缺陷报告、邮件列表或问答中。这类技术就像监听茶馆对话的情报员,从海量文本中提取漏洞线索。
1. 缺陷报告:从 “报修单” 里找线索
缺陷报告是开发者提交的 “报修单”,有些报修单其实藏着安全漏洞,但常被误标为普通问题。
文本分类模型
2014 年的 Behl 等人用 TF-IDF 提取报告关键词,再用朴素贝叶斯分类,像分拣邮件一样区分安全与非安全报告,准确率达 93.99%。
处理数据噪音
2017 年的 FARSEC 框架发现,有些报告含 “安全” 关键词却不是漏洞(如 “安全模式”),会干扰模型。它像过滤垃圾邮件一样移除这些样本,使误判减少 38%。
引入外部知识
2022 年的 MemVul 模型把 CWE(常见弱点枚举)的漏洞知识融入深度学习,像给模型配备 “漏洞词典”,跨项目检测性能显著提升。

2. 邮件列表与公开讨论:从 “闲聊” 中抓漏洞
邮件列表、GitHub 讨论、问答网站(如 Stack Overflow)中,开发者的只言片语可能泄露漏洞信息。
情感分析
2014 年的 Pletea 等人发现,讨论安全问题时开发者更容易表达负面情绪,像人们谈论麻烦事时语气会变差,这一发现有助于定位敏感讨论。
跨项目通用模型
2021 年的 Oyetoyan 等人从 NVD 等安全数据库提取通用关键词(如 “攻击”“加密”),构建不依赖特定项目的分类模型,像多语言翻译器一样适用于不同项目。
问答网站挖掘
2020 年的 PUMiner 工具专门从 Stack Overflow 挖掘安全相关帖子。它只用少量已知安全帖子(正样本)和大量未标注帖子,像用少量通缉令抓逃犯,F1 分数超过 0.85。
3. 逆向思维:从 “沉默” 中找漏洞
有些漏洞修复遵循严格流程,不在公共频道讨论,这种 “沉默” 反而暴露问题。2020 年的 Ramsauer 等人就用这种思路,对比 Linux 内核的代码提交与公开邮件列表,发现 29 个未公开讨论的安全补丁,比正式披露早 2-179 天,像发现没被提及的维修记录,推测房子曾有隐蔽问题。
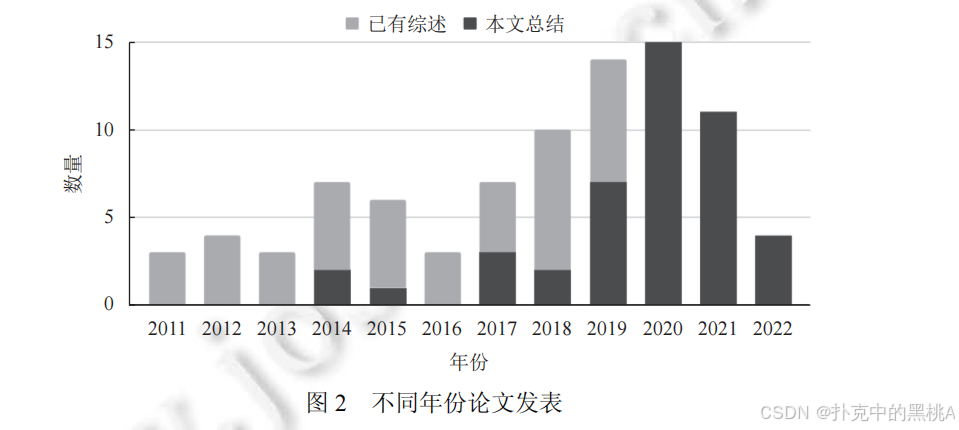
从图 2 可以看出,漏洞感知领域的研究论文数量逐年递增,尤其是 2018 年后增速明显,说明该领域受到越来越多关注。而基于社区讨论和补丁的研究起步较晚(如图 3 所示),仍是待探索的蓝海。
五.基于代码补丁的漏洞感知:从 “修补痕迹” 反推漏洞
漏洞修复补丁就像 “补墙的水泥”,分析补丁能反推哪里曾有 “破洞”。这类技术专注于识别安全补丁,尤其是隐秘修复的补丁。
1. 二进制补丁分析:从机器码中找修补痕迹
有些软件只发布二进制文件,分析其二进制补丁就像通过成品菜的变化推测调料配方。2017 年的 SPAIN 工具能对比补丁前后的二进制函数,定位修改的基本块,像对比修补前后的墙,找出修补位置,并总结出 5 种常见补丁模式(如输入验证、权限检查)。
2. 源码补丁分析:从代码变更中识别安全修复
开源软件的代码提交记录(如 GitHub 的 commit)是分析补丁的金矿,但需要区分安全补丁和普通功能更新。
结合日志和代码
2018 年的 Sabetta 等人分别基于提交日志(自然语言)和代码变更训练分类器,像用两个证人的证词交叉验证,再通过投票机制整合结果,准确率达 80%。
隐秘补丁检测
有些补丁的提交日志刻意隐瞒安全相关内容(如只写 “修复 bug”)。2021 年的 VulFixMiner 工具无视日志,直接用 CodeBERT 分析代码变更的语义,像通过菜的味道变化而非菜单描述,识别出这些隐秘补丁。
跨项目克隆检测
2019 年的 Wang 等人发现,相似项目的漏洞修复也相似。他们用代码克隆技术在 OpenSSL、LibreSSL 等项目中发现 12 个隐秘补丁,像通过邻居家的维修记录,发现自家房子的同类问题。

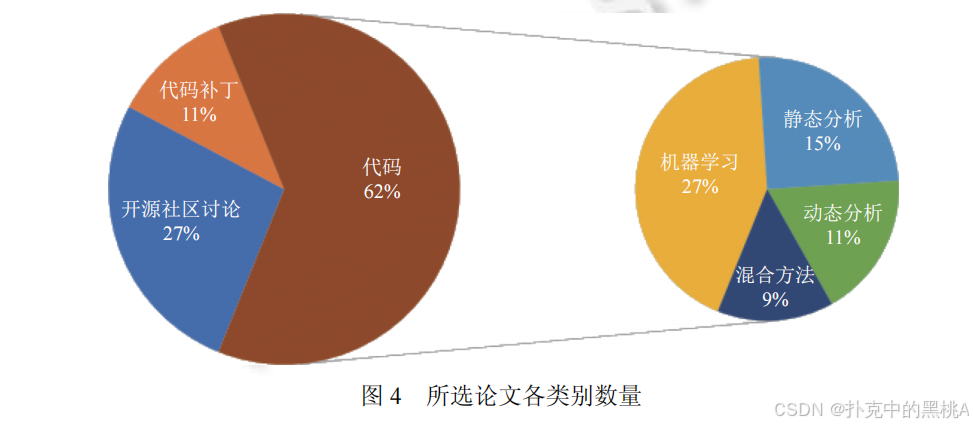
图 4 直观展示了当前研究的分布:基于代码的漏洞感知技术仍是主流(62%),而基于社区讨论和补丁的技术虽占比不高,但增长潜力大,是未来研究的重要方向。
六.实用工具与数据集:漏洞感知的 “弹药库”
工欲善其事,必先利其器。论文整理了近年来的主流工具和数据集,为研究者提供 “弹药”。
1. 开源工具:开箱即用的 “探测器”

CryptoGuard
2019 年发布,专门检测 Java 代码中加密 API 的误用,如用 ECB 模式加密(不安全),在 Apache 项目中发现大量问题。
sFuzz
2021 年发布的智能合约模糊器,支持在线使用,能快速检测 Solidity 合约中的整型溢出、重入等漏洞。
Pluto
2021 年发布,针对跨合约漏洞,通过构建合约间控制流图,像绘制小区地图一样,发现多个合约交互时的漏洞。
2. 数据集:训练模型的 “样本库”

SARD
NIST 维护的权威数据集,包含 C、Java 等多语言漏洞样本,既有真实软件漏洞,也有人工测试用例,像漏洞博物馆。
CodeXGLUE
微软发布的代码智能基准,其中的缺陷检测数据集来自 Linux Kernel 等项目,包含 2 万多个样本,适合训练模型。
CryptoAPI
2021 年发布,含 171 个 Java 加密漏洞样例,对应 16 种常见误用,像加密漏洞的专项题库。
七.当前挑战与未来方向:漏洞感知的 “任重道远”
尽管技术不断发展,开源软件漏洞感知仍面临诸多挑战,也孕育着新的研究机遇。
1. 三大核心挑战
数据集质量差
很多数据集存在标签错误(如安全漏洞被标为普通 bug),就像用错误答案训练学生。2021 年的 Wu 等人发现,修正标签后,简单模型的性能反而超过复杂模型。
误报率高且粒度粗
多数工具只能定位到函数级漏洞,难以精确到具体语句,就像医生只说 “身体有问题” 却不说具体部位。
供应链级感知难
开源软件依赖成百上千个库,某一个库的漏洞可能 “传染” 整个供应链,而现有技术多关注单个项目。
2. 未来研究方向
构建高质量数据集
结合自动标注和人工验证,建立大规模、真实场景的漏洞数据集,像打造精准的 “病历库”。
AI 与程序分析融合
用静态分析提取的代码特征增强 AI 模型,同时用 AI 指导动态测试的输入生成,实现 “1+1>2” 的效果。
全生命周期感知
整合代码、社区、补丁三个阶段的技术,构建从发现到修复的闭环,像给开源软件配备 “24 小时保镖”。
跨语言跨平台扩展
现有技术多针对 C、Java,未来需支持 Python、Go 等更多语言,以及物联网、区块链等新兴平台。
八.总结:漏洞感知是一场 “持久战”
开源软件的漏洞感知就像一场永不停歇的 “攻防战”:攻击者利用开源的透明性寻找漏洞,防御者则借助代码分析、社区监测、补丁追踪构建防线。从 Log4j 到近期的各种漏洞,每一次事件都在推动技术进步。
这篇综述不仅梳理了现有技术,更揭示了一个核心思路:在开源生态中,漏洞感知不能只依赖单一技术,而要结合代码、社区、补丁等多维度信息,形成 “全民皆兵” 的防御网。未来,随着 AI 技术的深入和跨领域融合,我们有望实现更主动、更精准的漏洞感知,让开源软件这座共享大厦更安全、更可靠。
无论是开发者、研究者还是普通用户,了解这些技术都能帮助我们更好地应对开源安全挑战 —— 毕竟,在漏洞面前,没有人是旁观者。
尾
本期技术解构至此。 论文揭示的方法论范式对跨领域技术实践具有普适参考价值。下期将聚焦其他前沿成果,深入剖析其的突破路径。敬请持续关注,共同深挖工程实现脉络,淬炼创新底层逻辑,在学术与工程融合中洞见技术演进规律,推动领域范式持续进化。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-08-08,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号