B-tree不是万能药:PostgreSQL索引失效的7种高频场景与破解方案

B-tree不是万能药:PostgreSQL索引失效的7种高频场景与破解方案

在PostgreSQL的优化实践中,B-tree索引作为最常用的索引类型,承担着80%以上的查询加速任务。然而索引失效导致的性能断崖式下跌,往往让开发者陷入“明明有索引为何还慢”的困惑。本文深入剖析7种高频索引失效场景,通过可复现的实战案例揭示问题本质,并提供经过生产验证的解决方案。
1 隐式类型转换
失效机制:当查询条件的数据类型与索引列定义类型不一致时,PostgreSQL会触发隐式类型转换,导致索引无法被直接使用。
(1) 实战案例复现
-- 创建测试表与索引
CREATE TABLE user_actions (
id SERIAL PRIMARY KEY,
device_id VARCHAR(32) NOT NULL, -- 字符类型存储设备ID
action_time TIMESTAMPTZ NOT NULL
);
CREATE INDEX idx_device_id ON user_actions(device_id);
-- 失效查询(错误使用数值类型查询)
EXPLAIN ANALYZE
SELECT * FROM user_actions
WHERE device_id = 12345678; -- 整数类型条件
-- 执行计划输出
Seq Scan on user_actions (cost=0.00..10238.90 rows=1 width=48)
Filter: ((device_id)::text = '12345678'::text)关键诊断:执行计划显示Seq Scan(全表扫描),索引idx_device_id未被使用
(2) 解决方案
方案1:显式类型转换
WHERE device_id = 12345678::text -- 将参数转为文本类型方案2:修改列数据类型(需业务评估)
ALTER TABLE user_actions
ALTER COLUMN device_id TYPE INTEGER USING device_id::integer;2 函数包裹索引列:破坏索引有序性
失效机制:对索引列使用函数或表达式操作,破坏了B-tree索引的有序存储结构。
(1) 经典错误案例
-- 索引列参与计算
EXPLAIN ANALYZE
SELECT * FROM sales
WHERE EXTRACT(YEAR FROM order_date) = 2023;
-- 输出结果
Seq Scan on sales (cost=0.00..26482.00 rows=5000 width=36)
Filter: (date_part('year'::text, order_date) = '2023'::double precision)(2) 破解方案:函数索引
-- 创建基于表达式的函数索引
CREATE INDEX idx_sales_order_year ON sales(EXTRACT(YEAR FROM order_date));
-- 优化后执行计划
Index Scan using idx_sales_order_year on sales (cost=0.29..348.29 rows=100 width=36)
Index Cond: (date_part('year'::text, order_date) = 2023::double precision)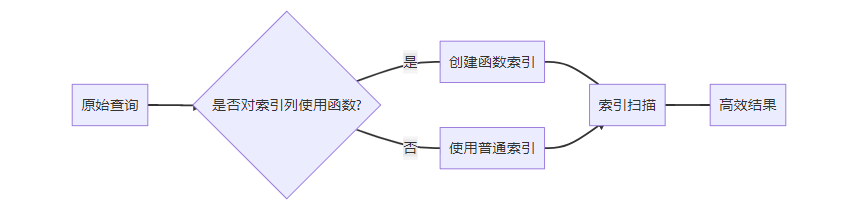
图:函数索引决策流程图。当查询条件包含列运算时,需创建匹配的函数索引才能使索引生效。
3 前导通配符查询:B-tree的天然局限
失效机制:LIKE '%keyword%'类查询使B-tree失去前缀匹配优势。
(1) 性能对比实验
-- 测试表:100万条文本数据
CREATE TABLE documents (
id BIGSERIAL PRIMARY KEY,
content TEXT
);
CREATE INDEX idx_content ON documents(content);
-- 场景1:后缀匹配(索引有效)
EXPLAIN ANALYZE
SELECT * FROM documents WHERE content LIKE 'postgres%';
-- 输出:Index Scan using idx_content...
-- 场景2:前导通配符(索引失效)
EXPLAIN ANALYZE
SELECT * FROM documents WHERE content LIKE '%index%';
-- 输出:Parallel Seq Scan...(2) 解决方案:Trigram扩展
-- 启用pg_trgm扩展
CREATE EXTENSION pg_trgm;
-- 创建GIN索引
CREATE INDEX idx_content_trigram ON documents USING gin(content gin_trgm_ops);
-- 优化后查询
EXPLAIN ANALYZE
SELECT * FROM documents WHERE content LIKE '%index%';
-- 执行计划
Bitmap Heap Scan on documents (cost=52.89..228.43 rows=100 width=68)
Recheck Cond: (content ~~ '%index%'::text)
-> Bitmap Index Scan on idx_content_trigram (cost=0.00..52.86 rows=100)
Index Cond: (content ~~ '%index%'::text)4 NULL值陷阱:索引中的黑洞
失效机制:标准B-tree索引不存储NULL值,导致IS NULL条件无法使用索引。
(1) 失效场景演示
CREATE TABLE orders (
order_id SERIAL PRIMARY KEY,
cancel_reason TEXT
);
CREATE INDEX idx_cancel_reason ON orders(cancel_reason);
-- 查询未取消的订单(约90%数据)
EXPLAIN ANALYZE
SELECT * FROM orders WHERE cancel_reason IS NULL;
-- 输出结果:Seq Scan...(2) 解决方案:条件索引
-- 创建针对NULL的局部索引
CREATE INDEX idx_null_cancel_reason ON orders(cancel_reason)
WHERE cancel_reason IS NULL;
-- 优化后执行计划
Index Scan using idx_null_cancel_reason on orders (cost=0.12..8.14 rows=1 width=68)
Index Cond: (cancel_reason IS NULL)5 联合索引顺序错位:最左前缀原则
失效机制:联合索引(a,b,c)仅支持a|a,b|a,b,c组合查询,违反最左前缀原则导致失效。
(1) 顺序敏感性验证
CREATE TABLE events (
id BIGSERIAL,
tenant_id INT NOT NULL,
event_type SMALLINT NOT NULL,
created_at TIMESTAMPTZ DEFAULT NOW()
);
CREATE INDEX idx_event_composite ON events(tenant_id, event_type, created_at);
-- 有效查询(使用最左列)
EXPLAIN ANALYZE
SELECT * FROM events
WHERE tenant_id = 1001 AND event_type = 5;
-- 输出:Index Scan...
-- 失效查询(跳过tenant_id)
EXPLAIN ANALYZE
SELECT * FROM events
WHERE event_type = 5 AND created_at > '2023-01-01';
-- 输出:Seq Scan...(2) 索引顺序优化策略
查询模式 | 推荐索引顺序 | 索引使用率 |
|---|---|---|
WHERE tenant_id=? | (tenant_id) | 100% |
WHERE tenant_id=? AND type=? | (tenant_id, event_type) | 100% |
WHERE type=? AND created>? | (event_type, created_at) | 需新建索引 |
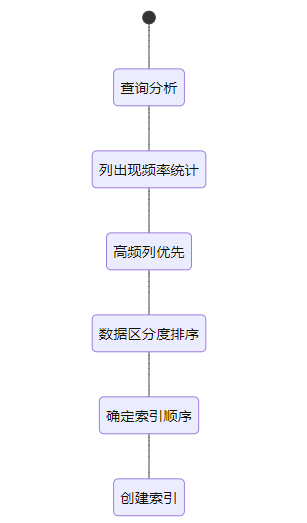
图:联合索引设计流程。按列使用频率和区分度(Cardinality)从高到低排序。
6 非等值查询范围过大:索引性价比下降
失效机制:当优化器预估索引扫描需要回表大量数据时,会退化为全表扫描。
(1) 阈值测试(基于pg_stats)
-- 查看列分布统计
SELECT attname, n_distinct, most_common_vals
FROM pg_stats
WHERE tablename='orders' AND attname='status';
-- 输出示例:
attname | n_distinct | most_common_vals
--------+------------+----------------------------------
status | 4 | {1,2,3,4} -- 4种状态均匀分布
-- 查询覆盖50%数据的场景
EXPLAIN ANALYZE
SELECT * FROM orders WHERE status IN (1,2); -- 50%数据
-- 结果:即使有索引,优化器选择Seq Scan(2) 解决方案:强制索引使用
SET enable_seqscan = off; -- 临时关闭全表扫描
EXPLAIN ANALYZE
SELECT * FROM orders WHERE status IN (1,2);
-- 输出变为:Bitmap Heap Scan...注意:该方法仅用于诊断,生产环境应优化查询或调整索引
7 统计信息过期:优化器的错误决策
失效机制:自动ANALYZE未能及时更新统计信息,导致优化器低估索引价值。
(1) 人为制造统计偏差
-- 步骤1:清空表并禁用autovacuum
TRUNCATE large_table;
ALTER TABLE large_table SET (autovacuum_enabled = off);
-- 步骤2:批量插入100万条特定特征数据
INSERT INTO large_table SELECT generate_series(1,1000000), 'special_value';
-- 步骤3:强制使用旧统计信息(不触发ANALYZE)
EXPLAIN ANALYZE
SELECT * FROM large_table WHERE special_column = 'special_value';
-- 输出:误用索引(实际应全表扫描更快)(2) 解决方案:精准统计控制
-- 手动更新统计信息(全表)
ANALYZE VERBOSE large_table;
-- 加大特定列统计粒度
ALTER TABLE large_table
ALTER COLUMN special_column
SET STATISTICS 1000; -- 默认100
-- 重新收集统计信息
ANALYZE large_table;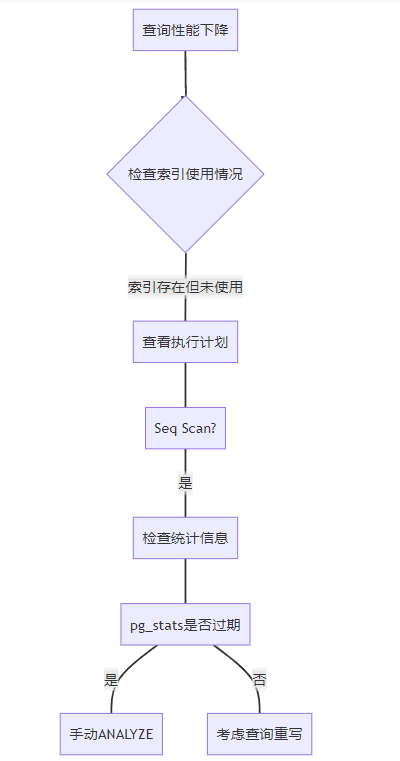
图:统计信息过期的诊断流程。当索引无故失效时,应首先检查pg_stats系统表。
终极解决方案:索引使用决策矩阵
失效类型 | 检测方法 | 解决方案 | 适用版本 |
|---|---|---|---|
隐式类型转换 | EXPLAIN查看条件转换 | 显式类型声明/修改列类型 | 所有版本 |
函数包裹列 | 检查WHERE子句表达式 | 创建函数索引 | PostgreSQL 9.4+ |
前导通配符 | LIKE模式分析 | pg_trgm扩展 | 9.1+ |
NULL查询 | 检查IS NULL执行计划 | 条件索引 | 8.0+ |
联合索引顺序 | 验证最左前缀 | 重构索引顺序 | 所有版本 |
非等值范围过大 | 检查pg_stats的n_distinct | 强制索引/优化查询条件 | 所有版本 |
统计信息过期 | 对比实际行数与pg_stats | 手动ANALYZE/调整STATISTICS | 所有版本 |
让索引真正发挥作用的关键原则
- 精确匹配原则:保持查询条件与索引定义在数据类型、表达式形式上完全一致
- 最小化扫描原则:通过条件索引、分区等技术减少索引扫描范围
- 统计驱动原则:定期验证并更新统计信息,确保优化器做出正确决策
- 工具链整合:将
pg_stat_statements+auto_explain纳入监控体系
腾讯云开发者
