美国知名大学开授China数据库理论,你没看错!

美国知名大学开授China数据库理论,你没看错!

AustinDatabases
发布于 2025-04-09 16:23:16
发布于 2025-04-09 16:23:16
Austindatabases公众号已经开启了,AI 文章分析,AI 文章问答,比如你想知道AustinDatabases 里面,说了多少种数据库,那些是讲 MySQL,那些是PostgreSQL, 那些是OB ,POLARDB ,MongoDB ,SQL Server, 阿里云的,问他他会列出来,同时如果有问题不明白,可以将文章的文字粘贴到公众号提供的专用AI ,公众号将通过众多文章(目前1300多篇)来进行尝试性的解释。使用方法,直接到微信公众号中点击服务,选择AI问答。如下示例
图片
人外有人,天外有天,这句话可能是我今年的口头禅了,最近有老师给我一些信息,个人看属于,氢弹级别,美国著名大学加州Berkeley---世界数据库系统的摇篮,CS286--2024春季研究生数据库系统的课程,正式将PolarDB 云原生数据库低延迟一致性读的原理,写入到正式的课程中,且开始教授它,世界顶尖的学府的学生也能学到数据库业界最先进的技术。希望国内的大学课程也可以与时俱进,在讲授20年前的数据库理论的同时,也可以把国产现代数据库的原理和学生们讲一讲,终究洋人崇中媚中,咱们崇洋媚外这话可是不好听。
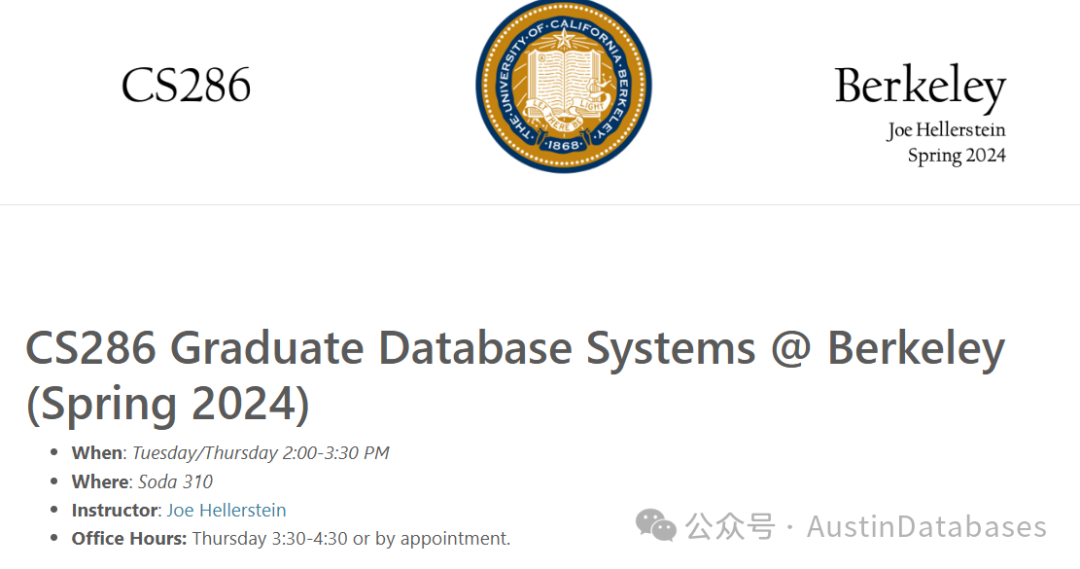
美国加州博纳克利大学数据库系统--研究生课程
美国加州博纳克利大学数据库系统--研究生课程

PolarCB的SCC研究正式在课上讲授
PolarCB的SCC研究正式在课上讲授
想想,这所大学诞生过,Ingres、PostgreSQL、Oracle、DB2等这些数据库,算是数据库系统的摇篮,数据库理论的圣殿。在数据库研究生的课程中开始教授PolarDB的理论,这次我们国产数据库翻身了。让我不得不把这篇,我之前翻译过的论文再次的好好的又读了一遍。(想和我一起在读一遍这篇PolarDB-SCC 白皮书的可以在文尾连接区下载PDF)
PolarDB-SCC: A Cloud-Native Database Ensuring Low Latency for Strongly Consistent Reads
首先我们要确定的是PolarDB 无论是PolarDB for MySQL 还是 PolarDB for PostgreSQL,这两种云原生数据库,均具有在实际业务中完成读写分离的瞬时主从节点数据一致的能力,我们可以简单理解为,主从没有延迟,从节点在主节点写入数据后,可以立即读出写入的数据,与此同时能提供比MySQL,PostgreSQL 单机更好的性能和多种复杂的功能,如行列混存,数据压缩,数据加密,数据归档命令内部执行,并行SQL查询等能力。
这些传统数据库脑仁疼的问题--如读写节点数据只能承诺最终一致性的问题,被彻底的解决了,且是中国的国产数据库系统解决的这一问题。
开发者在之前的数据库系统中遇到数据库的读写分离中最大的问题---主从节点数据的一致性无法满足时效性的要求,不是只能达到最终一致性,要不就是数据虽然可以从从库读出写库数据,但要付出主节点的性能损失,属于鱼和熊掌不可兼得。
在PolarDB中,开发和架构将不在因为在写节点写入数据后无法立刻在读节点读出数据,从而要做的一系列架构的调整和开发的代码结构的变动,这一切再PolarDB都不需要在考虑,开发专心搞好业务逻辑开发就好,之前架构人员在MySQL上的所做的需要都作废了,这些工作如下:
1 要明确主从读取数据的一致性级别的问题
2 读写分离的策略,针对业务进行改造要分辨那些业务必须写库写,写库读,那些写库写,读库读的大量业务改造。
3 处理主从延迟所带来的方法,如延迟告警,强制读取写库,业务重试机制,数据校验工作。
这将大大减少开发的成本和业务开发的复杂性,及架构设计的成本和复杂性。
那么什么技术,让国际最重要的数据库系统理论发明的“基地”来教授中国PolarDB的数据库理论给他们的加州博纳克利大学的研究生,我们来看看:
这个关键性的技术难题在PolarDB中被这三点解决
1 分层修改跟踪器:(Hierarchical Modification Tracker, HMT)在全局、表级和页级三个粒度上跟踪读写节点的修改时间戳。当只读节点需要进行强一致性读取时,它会首先检查全局级别的时间戳,然后是表级和页级的时间戳。一旦某个级别满足要求(即只读节点在该级别的数据是最新的),就可以直接处理请求,而无需检查下一个级别。只有当页级时间戳不满足时,才需要等待相关页面的日志应用完成. 这种细粒度的跟踪避免了等待所有内存数据更新完成造成的开销。
2 线性Lamport时间戳:(Linear Lamport Timestamp, LLT)为了减少只读节点频繁地从读写节点获取时间戳的操作,PolarDB-SCC 在只读节点上设计了一种线性 Lamport 时间戳。只读节点在从读写节点获取一次时间戳后,可以本地缓存该时间戳,并在后续的某些读取请求中直接重用该时间戳,从而减少网络和通信开销。
3 基于 RDMA 的数据传输:利用高速的 RDMA(Remote Direct Memory Access)网络 进行日志传输和时间戳获取。RDMA 可以提供低延迟的网络通信,并绕过读写节点的 CPU 来进行远程内存访问,从而降低网络开销和读写节点的 CPU 使用率。
其中论文还论述了PolarDB云原生数据库保证读写一致性的整套理论,通过写节点每次写入操作后返回一个日志的LSN号,给代理节点,代理节点将同一个事物中的后续请求都发给只读节点前,会检查只读节点上已经应用的最高LSN,确保读取节点的数据已经包含了之前的写入数据。
而读写节点强一致并不是重点,而是起点,因为在读写节点强一致的基础下,数据库真弹性的能力,最大可以一次性瞬间弹出16个读节点以应对突发的读请求。基本上百分之90%以上的读问题都可以在PolarDB上解决,而那些假的弹性,如基于K8S那样的技术的假弹性,只能在这样的技术面前,下跪。
https://cs286berkeley.net/Lecture%2023%20Cloud%20OLTP.html
我们反过来看看上面具体Berkeley大学的研究生课程中,具体对PolarDB-Scc理论秉持的是一个什么态度。
1 在CS286课程中,质疑了Aurora 的“Stale RO copies! What? Is that OK?” 这表明在云 OLTP 中,如何保证只读副本的数据不落后于主节点是一个重要的变化和挑战。这与 OLAP 系统更能容忍一定程度的数据延迟不同。CS286讨论了 PolarDB-SCC 解决“Stale reads suck”的问题中所做的努力,强调了强一致性的重要性在OLTP业务中的重要性。
2 在CS286课程中对事务处理的低延迟要求描述中提到OLTP 系统通常需要处理大量的并发事务,并对每个事务的响应时间有严格的要求。课程提到了commit-wait 和 read-wait 等保证一致性的简单方法,但同时也指出了它们会导致事务本身的高延迟,这在 OLTP 中是不可接受的。PolarDB-SCC 的目标就是确保低延迟的强一致性读取。
3 在CS286课程中,还提到读写分离架构下的挑战 许多云原生数据库采用读写分离架构,即将读请求分发到只读节点,写请求发送到主节点。CS286中提到的 “Single-mastered databases! What? Is that OK?” 以及后续关于如何处理只读副本一致性的讨论,都反映了这种架构在 OLTP 中带来的特有挑战。如何在保证数据一致性的前提下,充分利用只读节点来扩展读性能,是云 OLTP 需要重点考虑的问题,截止到目前只有PolarDB 做到了。
4 在CS286课程中,弹性伸缩的需求和单Master的影响中提到云环境的弹性是其重要特性,课程中提出“Elasticity is available: what shall we use it for and how? Impact of single-master”,暗示了如何在 OLTP 系统中利用弹性,以及单Master架构可能带来的限制。例如,在需要强一致性的场景下,如果只读节点数据过时,可能无法简单地通过增加只读节点来扩展读性能. PolarDB-SCC 的设计目标之一就是实现真正的可扩展性和弹性,允许根据应用负载动态增加或减少只读节点的数量,同时保证强一致性。
所以,我一直强调,RDS的弹性是假的,K8S在云上搭建的MYSQL OR POSTGRESQL 系统谈弹性都是垃圾,这点是做实了,这在CS286这么课程中的总结上面的第四点印证了,加州博纳克利大学的教授知名数据库业界学者 Joseph M. Hellerstein,估计也是这么看的。
当然这门课程在这一章节里面还提到了,故障容错,快速修复,工作负载于LaaS定价模型,等等,这些后面我都会去好好的看看和学习,让我们记住这些先进技术的发明者的名字吧!

本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-04-06,如有侵权请联系 cloudcommunity@tencent.com 删除
本文分享自 AustinDatabases 微信公众号,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文参与 腾讯云自媒体同步曝光计划 ,欢迎热爱写作的你一起参与!
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号