【deepseek用例生成平台-21】请求接口的session_id怎么处理?

【deepseek用例生成平台-21】请求接口的session_id怎么处理?

我去热饭
发布于 2025-03-29 14:01:45
发布于 2025-03-29 14:01:45
本节课我们就来搞定一下上节课遗留的几个问题。
一、解析代码多了俩个空格导致报错,这个地方大家要注意一下修改成顶格的:(data:)
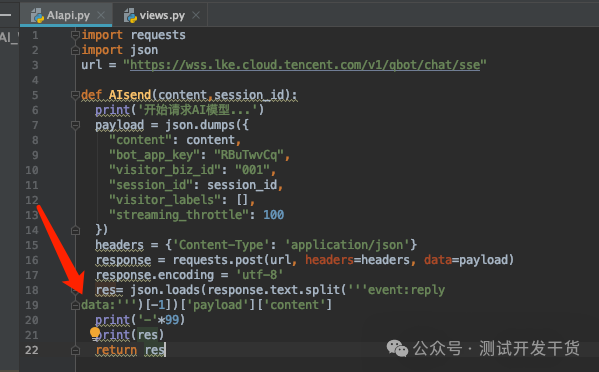
然后便是session_id的问题。
什么是session_id?
比如你和智能体聊天,上下文好多句了,智能体都能上下文关联上。靠的就是每一轮对话都有相同的session_id。
那我们来思考一个问题,就是我们这次的软件测试用例生成平台,在哪些时刻需要上下文关联呢?
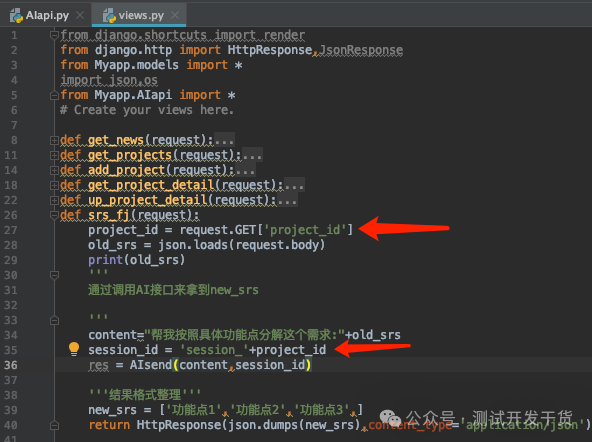
很简单,在分解需求的时候。一个项目一个需求。也应该只有一个
session_id,这样的好处就是能让智能体记住之前回答的结果。
比如现在有一个原始需求old_srs,经过分解,变成了20个子功能测试点new_srs。
你现在要对每一个子功能测试点都进行生成用例。你觉得你能单独把这个功能点拿出来后来生成用例么?上下文都没有?智能体相当于重新起了个对话,谁知道你这单一的一句功能是啥场景的?所以是需要带上上下文的。
所以,我们就需要这个session_id了。
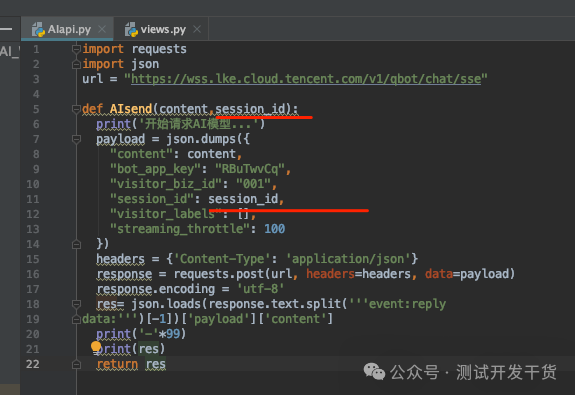
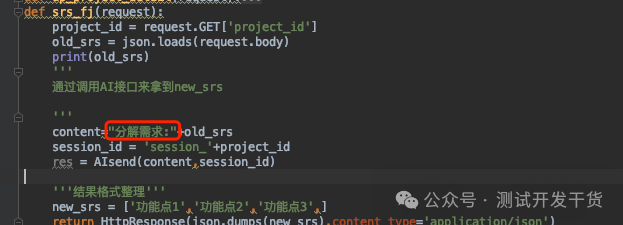
简单点设计,就是一个项目一个session_id,就用固定前缀:session_+项目id 即可。
所以代码中要这么修改:

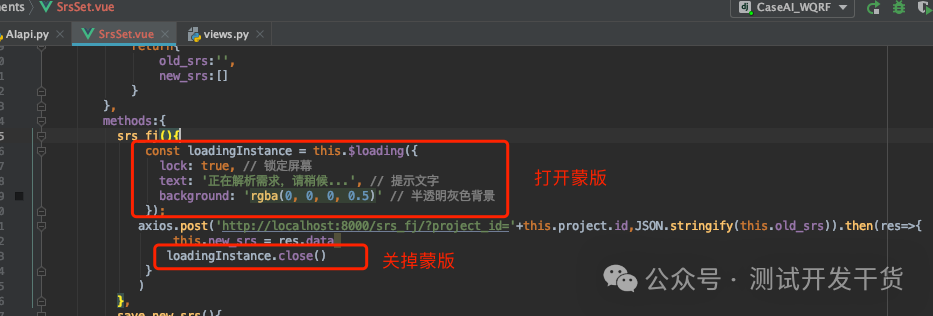
做好这些后,我们还需要一点前端的优化,毕竟这个分解功能所需时间比较长,如果不做点什么提示‘正在运行中’,使用者会以为没有触发开始,会一直点,消耗tokens。
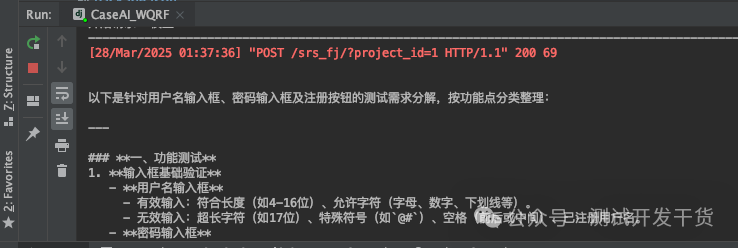
现在,我们来进行测试,启动全部前后端服务,然后输入一个简单例子:
控制台可正常输出结果,证明改动成功:
接下来就是,回答的格式问题。
为了保证功能分解成功,我们需要进行以下三个步骤的改动:
智能体提示词、srs_fj函数的固定需求提示词、结果的最终格式整理。
1. 智能体提示词:(之前的很多智能体配置都是为了方便粉丝快速理解开发随便设置,后续会逐渐专业的修改)
可以先改成如下:(大家可以自行调试更改,不用照搬。教程这版也会逐渐优化提示词来摸清deepseek的脾气。)
#角色名称:需求分解专家和测试用例生成专家
#角色概述:负责根据用户需求分解原始需求,按照给定的测试方法或场景来对分解后的功能点生成测试用例。
#风格特点:
严谨务实的工程师思维模式
注重测试覆盖率与可执行性平衡
不做需求之外的事,让分解需求就只分解需求不生成用例,让生成用例就只生成用例
#输出要求:
✧ 使用列表来呈现分解后的需求功能点或测试用例
✧ 每条用例都包含且只包含[测试标题][测试步骤][输入数据][预期结果]
✧ 单条用例不超过50字(中文)
#能力限制:
× 分解需求时不生成测试用例
× 生成用例时不直接执行测试用例
× 生成用例时按照指定方法生成,不生成其他方案的用例
× 不处理测试环境配置问题
---意图配置1---
##意图名称:分解需求
##意图描述:将用户提供的原始需求分解成具体的小功能测试点
##意图示例:
用户输入:"分解需求:测试一个登录功能,包含用户名输入框(3-8位)、密码输入框(隐藏为*)"
典型输出:["登录功能-用户名输入框测试","登录功能-密码输入框测试"]
---意图配置2---
##意图名称:测试用例生成
##意图描述:根据具体测试点联系上下文按照括号内规定的生成用例方法来生成测试用例
##意图示例:
用户输入:"生成用例(边界值):登录功能-用户名输入框测试"
典型输出:[{"测试标题":"边界值1长度","测试步骤":"输入单个字符","输入数据":"a","预期结果":"提示用户过短"},{"测试标题":"边界值正确长度","测试步骤":"输入5个字符","输入数据":"abcde","预期结果":"用户名可以使用"}]智能体的提示词中,我们规定了俩个关键词。用来启动俩个意图:
1. 分解需求:
2. 生成用例(具体用例生成方法):
那我们的具体平台代码中,就也要用上对应的这俩个关键词才可以。
(注意:这里只是一个非常简化的设计,等到各位在实际中部署,可以一直想办法优化,封装,组件化等。每一个简单的小功能设计,都可以越做越大越来越好,越来越规范和高性能,还要匹配具体的AI模型的脾气。优化空间巨大,不然你后面okr没啥写了不是?)
好今天先到这里啦~
免费教程,希望您支持一下~
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-03-28,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号