SPSS用K均值聚类KMEANS、决策树、逻辑回归和T检验研究通勤出行交通方式选择的影响因素调查数据分析

SPSS用K均值聚类KMEANS、决策树、逻辑回归和T检验研究通勤出行交通方式选择的影响因素调查数据分析

拓端
发布于 2025-03-17 18:42:12
发布于 2025-03-17 18:42:12
原文下载链接:http://tecdat.cn/?p=27587
某交通工程专业博士生想要研究不同因素对通勤交通方式选择的影响,对成都两个大型小区(高端和普通)居民分别进行了出行调查,各调查了300人(点击文末“阅读原文”获取完整文件数据)。
其中
Distance:居住地离上班地的距离(公里)
Pincome:个人年收入(万元)
Hincome:家庭年收入(万元)
Age:年龄
Gender:性别(0:女;1:男)
Car:家庭拥有汽车的数量
Education:教育水平(1:初中及以下;2:高中;3:专科;4:本科;5:研究生)
Job:工作类型(1:公司职员;2:工厂工人;3:公务员;4:个体;5:事业单位;6:其他)
People:家里人口数量
Children:家里未成年人数量
Housing:房屋拥有类型(0:租房;1:买房)
Area:房屋居住面积(平方米)
Mode:主要通勤出行方式(1:汽车;2:公共交通;3:电动自行车;4:其他)
但是小区的编号忘记记录下来。
任务:
- 判断每个变量时数值型变量还是分类型变量,数组型的计算其均值和方差,分类型的列出每类的频率。
数值型变量为:
Distance:居住地离上班地的距离(公里)
Pincome:个人年收入(万元)
Hincome:家庭年收入(万元)
Age:年龄
Car:家庭拥有汽车的数量
People:家里人口数量
Children:家里未成年人数量
Area:房屋居住面积(平方米)

分类型变量为:
Gender:性别(0:女;1:男)
Education:教育水平(1:初中及以下;2:高中;3:专科;4:本科;5:研究生)
Job:工作类型(1:公司职员;2:工厂工人;3:公务员;4:个体;5:事业单位;6:其他)
Housing:房屋拥有类型(0:租房;1:买房)
Mode:主要通勤出行方式(1:汽车;2:公共交通;3:电动自行车;4:其他)
分类型变量为:
Gender:性别(0:女;1:男)
Education:教育水平(1:初中及以下;2:高中;3:专科;4:本科;5:研究生)
Job:工作类型(1:公司职员;2:工厂工人;3:公务员;4:个体;5:事业单位;6:其他)
Housing:房屋拥有类型(0:租房;1:买房)
Mode:主要通勤出行方式(1:汽车;2:公共交通;3:电动自行车;4:其他)
- 判断每个受访者所在的小区。
根据居住地距离 ,我们使用kmean聚类将样本分成2个类别,并保存结果到小区变量中。
结果如图所示。
聚类中心结果如下
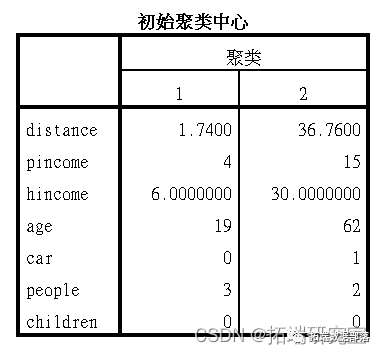
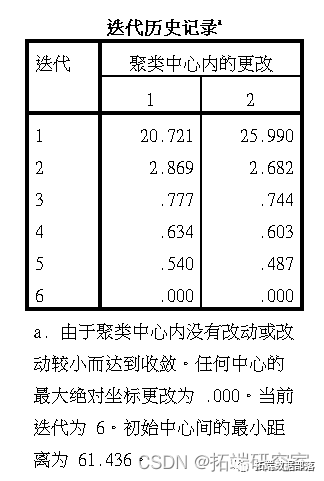
每个样本的聚类信息:
- 分析不同小区居民的平均出行距离、平均家庭收入、年龄分布、性别分布、家庭人口数和受教育程度有什么区别吗?
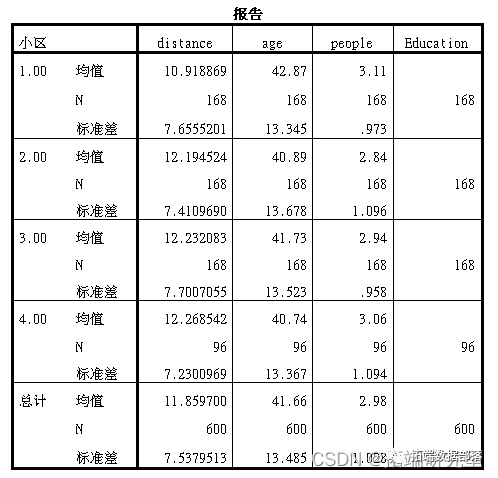
从均值比较的结果来来看,第1个类别的工作里小区工作距离较短,第三个类别年龄较小,第一个小区家庭人口较大,教育水平第四个小区较低。
然后对不同聚类类别的数据进行独立样本t检验。
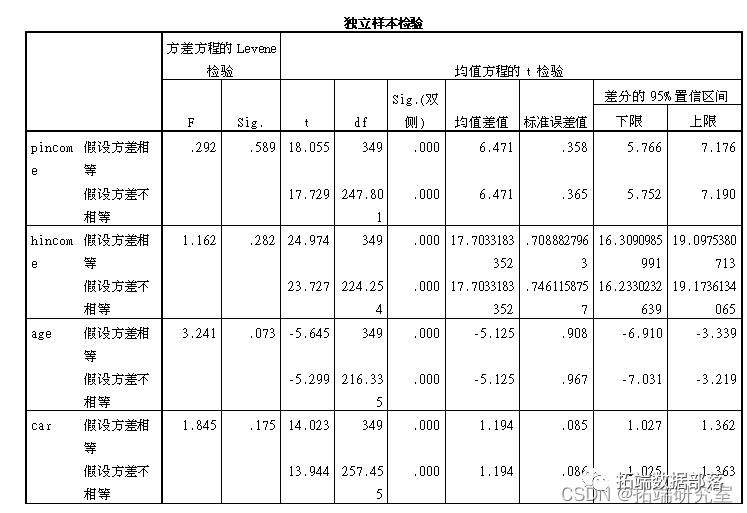
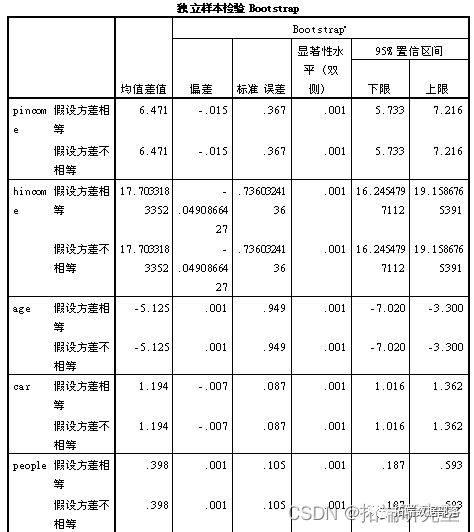
由上表中的结果:distance的sig>0.05,可知:distance无显著区别。
- 对每个小区分别建模(逻辑回归和决策树),看哪个模型对出行方式选择的拟合更好(比较模型在检验样本里的表现,而不是训练样本),并分析各个变量如何影响通勤交通方式的选择。
首先对1区的样本进行决策树模型

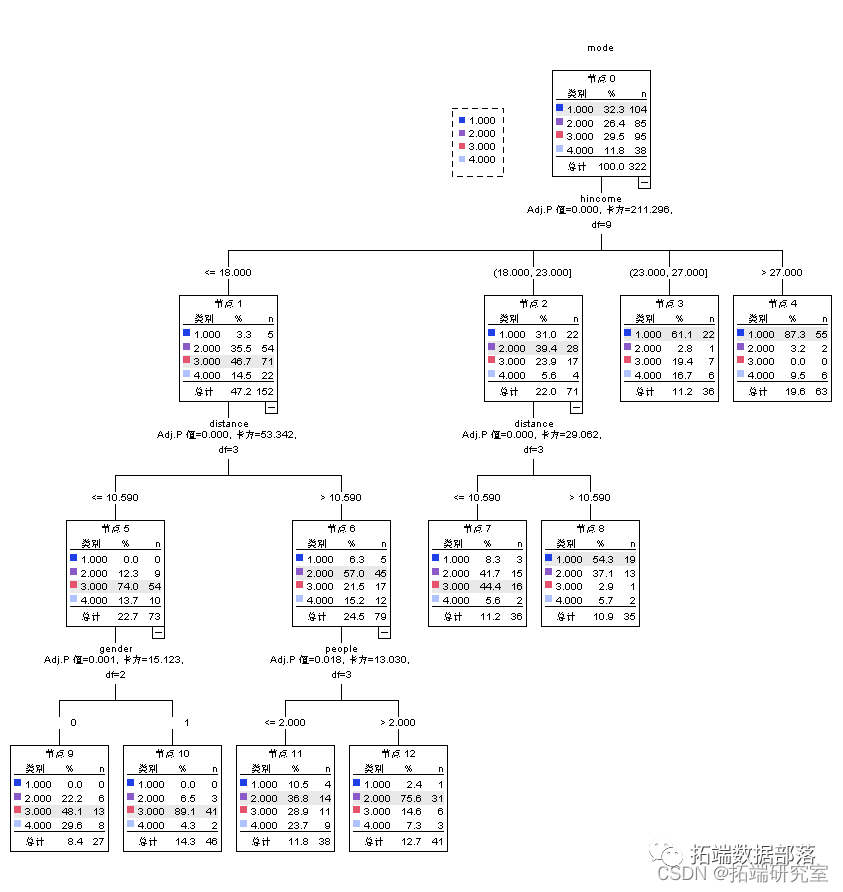
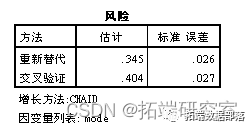
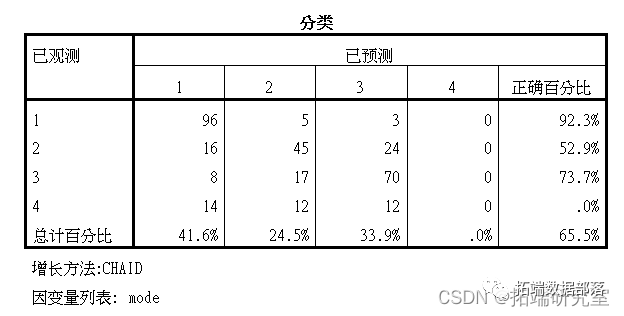
可以看到距离 收入、家庭人口数和性别对出行方式有较大的影响,男性出行以电动车为主,女性也有一部分以公交出行为主,从家庭人口数来看,大于2人的家庭出行以公交车为主。
然后使用逻辑回归进行预测
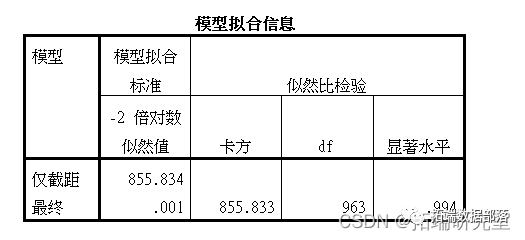

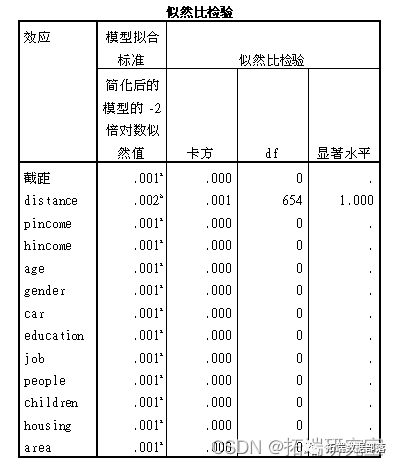
由结果来看整个逻辑回归的表达式是显著的;由“似然比检验”表格可知所有变量的显著性水平均小于0.05,可知自变量对于因变量mode都是显著的;而在参数估计中可得,自变量的显著性水平较低,即这些变量和mode是有关系的。
对2区出行数据进行决策树模型分析
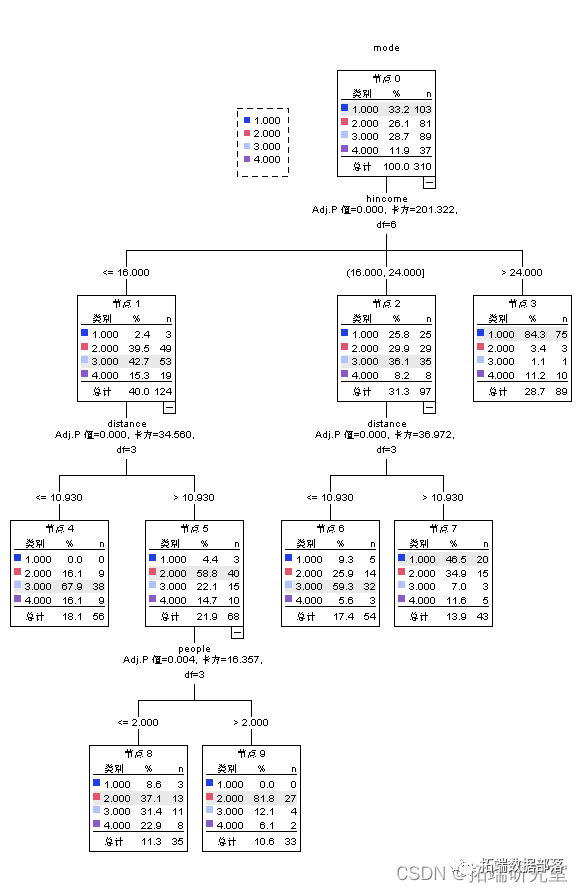
从结果来看,决策树分类模型可以看到区2的出行方式主要受到距离的影响。若距离较大,则出行方式以汽车和电瓶车为主,若距离较小,则以公交车为主。
对区2的出行数据进行逻辑回归
由结果来看整个逻辑回归的表达式是显著的;由“似然比检验”表格可知所有变量的显著性水平均小于0.05,可知自变量对于因变量mode都是显著的;而在参数估计中可得,自变量的显著性水平较低,即这些变量和mode是有关系的。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-03-14,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号