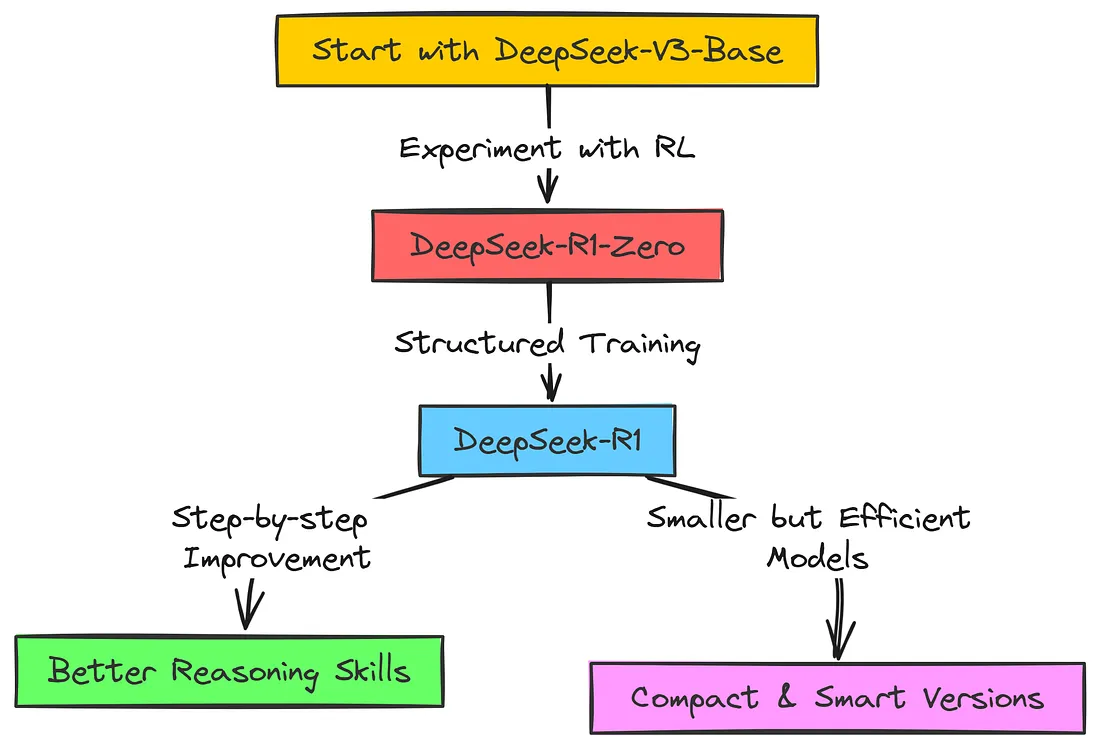
探索DeepSeek:从核心技术到应用场景的全面解读
原创
探索DeepSeek:从核心技术到应用场景的全面解读
原创
fanstuck
发布于 2025-02-18 20:12:47
发布于 2025-02-18 20:12:47
引言:为什么关注DeepSeek?

本文将全面了解DeepSeek的前世今生,文从DeepSeek模型论文和理论数学公式推理为依据,部分设计到复杂数学计算将以通俗易懂的案例解答理解,因此本文适用于刚刚入门DeepSeek探索的新手和想要了解DeepSeek但数学能力又不是很强的朋友,门槛较低。为做到写作全面本文篇幅可能较长,因此本文付出笔者诸多心血,希望大家诸多支持,随时欢迎讨论观点看法和落地运用。本文将从技术创新的角度,我们将深入探讨DeepSeek主流模型的核心优势,并与其他主流大模型进行对比;接着,我们将回顾DeepSeek的成长历程,揭秘它的核心逻辑和成功的关键;随后,我们将聚焦于DeepSeek在大模型蒸馏和实践中的应用;并分享一些实际场景的部署指南和使用技巧;最后,展望DeepSeek在未来AI领域的潜力与发展。
清晨,你对着手机说:“帮我写一份季度市场分析报告,重点对比新能源和半导体赛道,下午两点前完成。”一小时后,一份结构清晰、数据详实的报告出现在屏幕上——这不是科幻电影,而是搭载大模型的AI助手正在改写人类工作方式的现实剪影。
在过去的几年里,人工智能(AI)的飞速发展吸引了全球各界的广泛关注,尤其是在自然语言处理(NLP)、计算机视觉等领域的突破性进展。回顾ChatGPT的出现,它不仅给全球带来了惊艳的技术成果,还让每个人都看到了AI聊天机器人如何深入到日常生活中。无论是普通用户还是行业专业人士,都开始意识到大模型的潜力——这些模型能够理解和生成语言,模拟复杂的推理过程,甚至在一定程度上替代人类的工作。
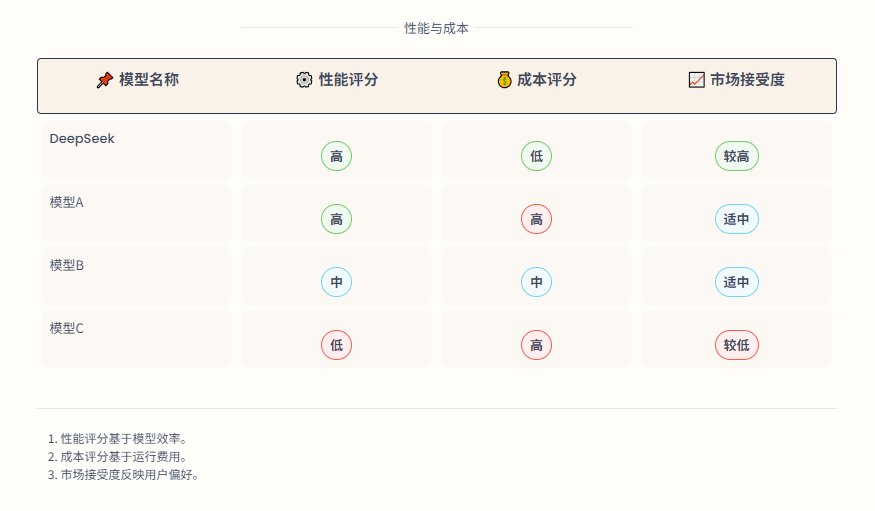
如果说ChatGPT打开了通用AI的想象力,那么DeepSeek则选择了一条更务实的道路:让大模型真正“落地生根”——不是盲目追求参数膨胀,而是在模型效率、领域适配与人性化交互之间找到黄金平衡点。当行业还在争论“千亿模型是否必要”时,DeepSeek-R1已能用十分之一的参数量,在金融推理任务中跑赢部分万亿级模型,就像一位拥有“思维晶格”的围棋高手,用精巧的落子破解蛮力计算的困局:
模型类别:模型A:(ChatGPT-4o,Qwen-Max);模型B(Llama3,ChatGLM-6B);模型C(ChatGPT-o1).
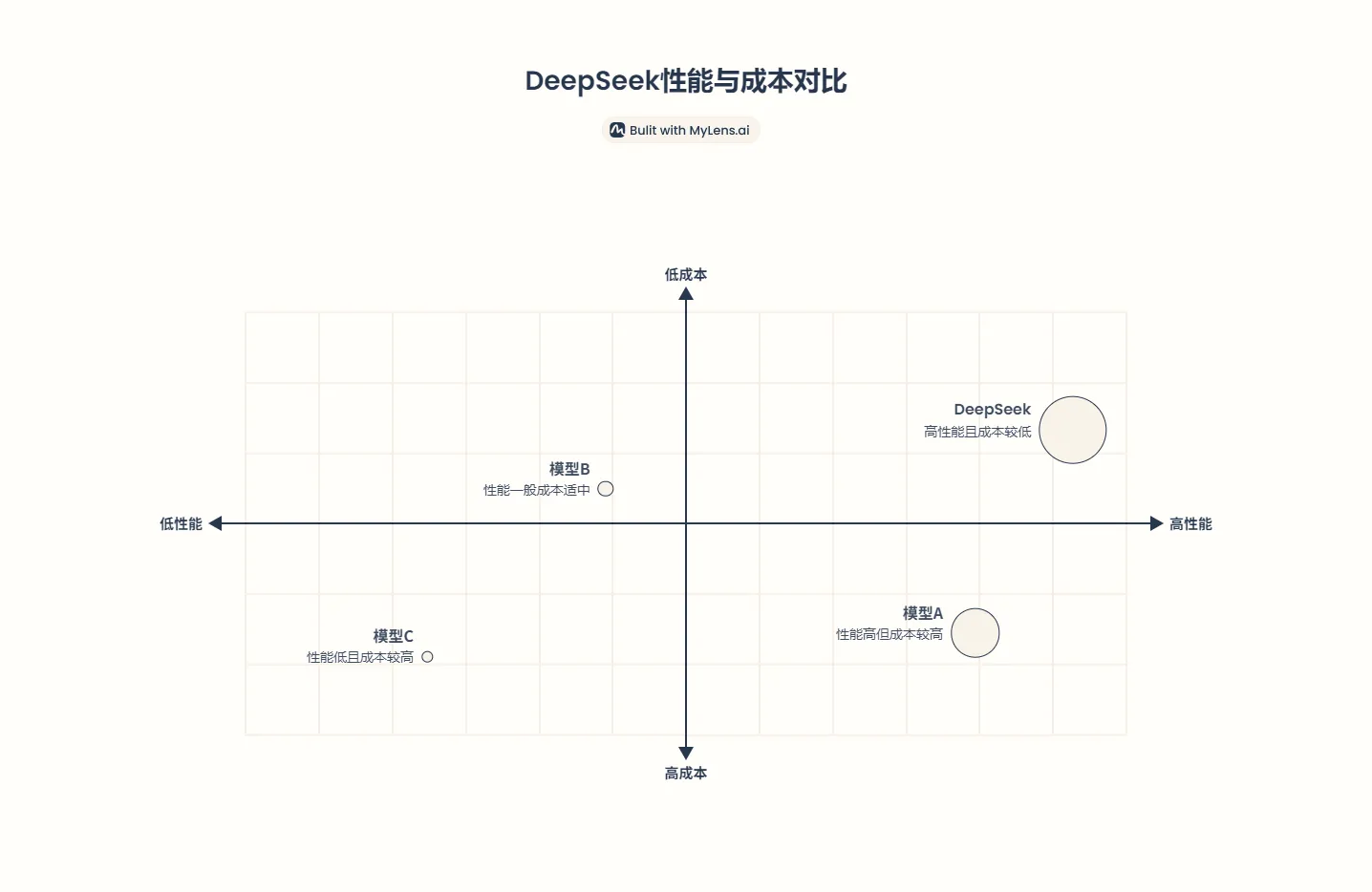
高效的推理能力:DeepSeek通过优化推理过程,显著降低了计算资源的消耗,实现了高效的推理能力。例如,DeepSeek-V3模型在生成吐字速度上从20 TPS提升至60 TPS,相比V2.5模型实现了3倍的性能提升。
专家混合模型(MoE)架构:DeepSeek采用了专家混合模型架构,通过将多个专家模型组合在一起,提高了推理的准确性和效率。同时和多头潜注意力机制(MLA)协同作用,使DeepSeek-V2的API定价低至GPT-4 Turbo的1/70(百万token输入1元)。该技术突破直接触发了中国大模型价格战,但DeepSeek仍能保持盈利,而跟进的互联网大厂则陷入烧钱补贴困境。
低成本训练与推理:DeepSeek在训练和推理成本方面表现出色。以DeepSeek-V3为例,仅需使用2048块英伟达H800 GPU,便能在短短两个月内完成训练,成本仅为550万美元,这在模型训练市场上具有划时代的意义。
这场静默的革命背后,是一个更深刻的行业转向:人工智能正在从“技术秀场”走向“价值战场”。
一、DeepSeek模型的技术创新与行业突破
DeepSeek自成立以来,推出了多款具有创新性的AI模型,涵盖了从代码生成到复杂推理等多个领域。DeepSeek的模型体系绝非简单的“大小套餐”,而是一套基于认知科学的分层智能框架。其核心逻辑在于:人类智能的本质是“通用基底+领域增强”。
以下是DeepSeek最具代表性的几个模型解读:
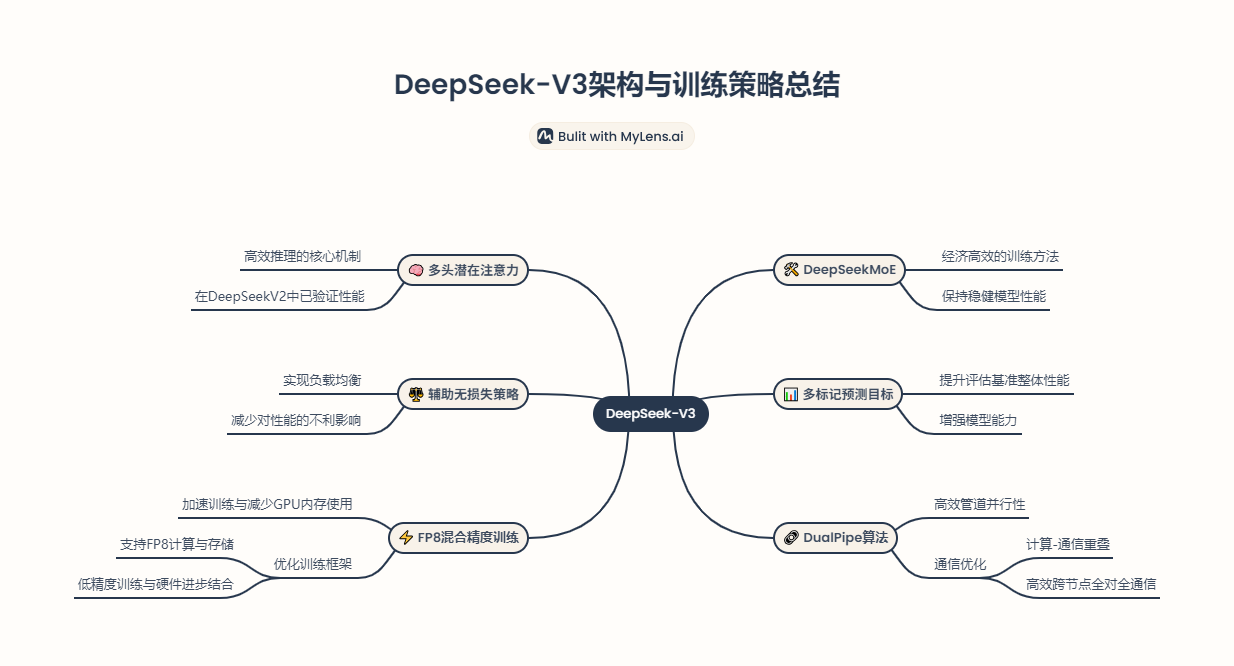
1.1DeepSeek-V3

大型语言模型LLMs 一直在经历快速迭代和进化,在架构方面,DeepSeek-V3 仍然采用多头潜在注意力 (MLA)进行高效推理,并采用 DeepSeekMoE 进行经济高效的训练。这两种架构已在 DeepSeekV2 中得到验证,证明了它们在实现高效训练和推理的同时保持稳健模型性能的能力。除了基本架构之外,我们还实施了两种额外的策略来进一步增强模型能力。首先,DeepSeek-V3 开创了一种辅助无损失策略进行负载均衡,目的是最大限度地减少鼓励负载均衡对模型性能的不利影响。
其次,DeepSeek-V3 采用了多标记预测训练目标,该目标可以提高评估基准的整体性能。DeepSeek-V3支持 FP8 混合精度训练,并对训练框架进行全面优化。低精度训练已成为一种很有前途的高效训练解决方案,其演变与硬件能力的进步密切相关。通过支持 FP8 计算和存储,我们实现了加速训练和减少 GPU 内存使用。至于训练框架,DeepSeek团队设计了 DualPipe 算法以实现高效的管道并行性,该算法具有更少的管道气泡,并通过计算-通信重叠隐藏了训练期间的大部分通信。并且还开发了高效的跨节点全对全通信内核,以充分利用 InfiniBand (IB) 和 NVLink 带宽。精心优化了内存占用,从而可以在不使用昂贵的张量并行性的情况下训练 DeepSeek-V3。
简单来说:想象你要记住整本《百科全书》,传统方法是把每个字刻在钢板上(这就是GPT的KV缓存机制)。而DeepSeek-V3的多头潜在注意力(MLA),就像用思维导图提炼精华-把4096维的“文字钢板”压缩成400维的“关键点卡片”,处理万字文档的显存占用从48GB降到9GB,相当于用自行车运货代替卡车。而关于DeepSeek-V3的DeepSeekMoE架构则更聪明,传统大模型像“全能型学霸”,每个问题都要动用全部脑细胞,而DeepSeek遇到数学题自动呼叫数论专家,看到CT片转接影像科主任,就像金融博士、医学教授、代码大神随时待命,每个问题只需8位专家联合“会诊”,效率提升3倍:
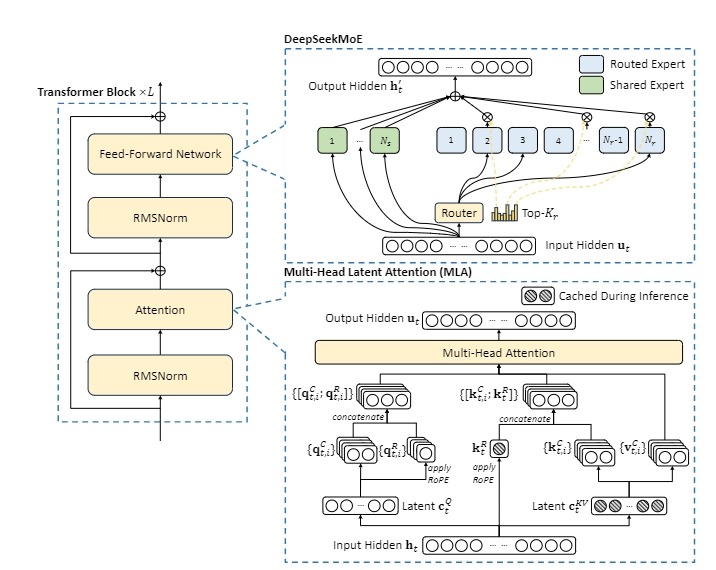
混合专家模型 (MoE) 主要由两个组件构成:
- 专家 (Experts): 不再只有一个全连接神经网络 (FFNN) 层,而是由多个 FFNN 层组成的一个“专家”集合。每个专家都相当于一个独立的全连接神经网络,负责处理特定类型的信息或特征。可以理解为每个专家都擅长处理不同的数据模式。
- 路由器或门控网络 (Router or gate network): 这个网络负责决定将输入数据的哪些 token 分配给哪些专家进行处理。它根据输入数据的特征,选择最合适的专家子集来处理,而不是让所有专家都处理所有数据。这就像一个调度器,将任务分配给最合适的专家。
MoE 通过将任务分配给不同的专家网络来提高效率和模型能力。它避免了让单个大型网络处理所有数据,从而降低了计算成本,并允许模型学习更复杂的模式,因为每个专家可以专注于其擅长的领域。MoE 的架构可以称之为 Spare Model,模型推理时每一次前向反馈只有部分专家的神经元(参数)会被激活,与之对应的就是 Dense Model,每一次前向反馈,模型的所有神经元(参数)都会被激活。
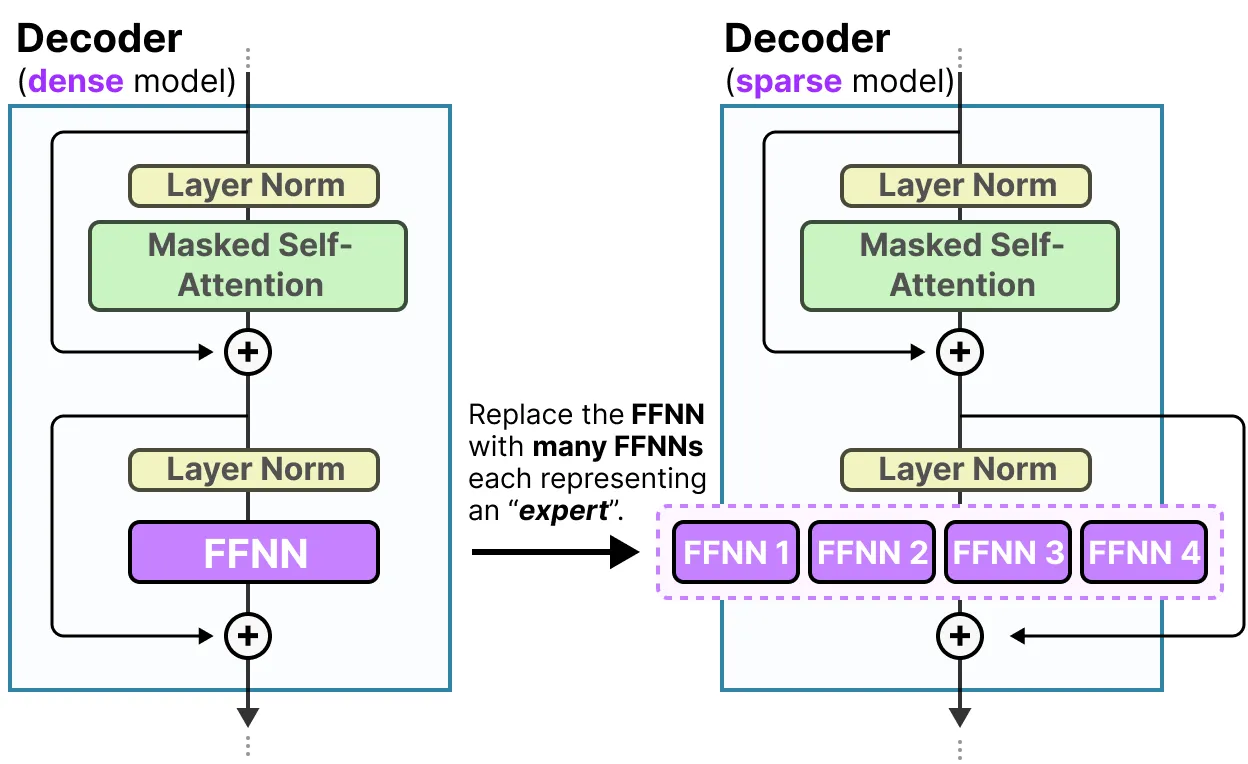
然而,路由器这个简单的功能往往会导致路由器选择同一个专家,因为某些专家可能比其他专家学得更快。我们希望专家在训练和推理过程中具有同等重要性,我们称之为负载平衡。从某种程度上说,这是为了防止对相同专家的过度拟合。
为了在训练过程中更均匀地分配专家,在网络的常规损失中加入了辅助损失(auxiliary loss,也称为负载平衡损失)。它增加了一种限制,迫使专家具有同等重要性。但是,这也有副作用,也就是会对 LLM 的性能造成一定的影响,同时也比较难以训练。
大模型对比:
- GPT-4:每次考试都带100个家教,不管题目难易
- DeepSeek-V3:根据题目难度自动组队,省时省力
1.2DeepSeek-R1-Zero
传统的深度学习模型不同,DeepSeek-R1-Zero 在训练过程中完全依赖于强化学习(Reinforcement Learning,RL),而非监督微调(Supervised Fine-Tuning,SFT)。这意味着模型在没有人工示范的情况下,通过自我探索和试错来学习解决复杂问题的策略。
DeepSeek-R1-Zero 的学习方式很特别,它就像一个天赋异禀但从未上过学的孩子,完全靠自己在探索中成长。与传统需要"老师手把手教导"的AI模型不同,它采用了一种全新的学习方式。想象一下:DeepSeek团队给了这个"AI孩子"一个聪明的大脑(基础语言模型),然后把它放进了一个特殊的"游戏房间"。在这个房间里,没有标准答案,没有示范,只有一个自动评分系统。每当它尝试解决问题时,系统就会给出"做得好"或"需要改进"的信号。就像一个孩子在解魔方,开始时可能毫无头绪,但通过不断尝试和调整,渐渐发现了一些技巧。DeepSeek-R1-Zero也是这样,在反复试错中,它逐渐掌握了一些令人惊讶的解题方法:学会了自我反思,懂得换个角度思考,甚至能够像数学家一样创造性地解决问题。
DeepSeek-R1 的训练就类似这样,只不过这里学生是 AI,老师不是人,而是奖励和惩罚机制。在训练初期,DeepSeek-R1-Zero 通过程序自动评估其回答的正确性,并根据结果给予奖励或惩罚。经过成千上万次的训练循环,模型逐渐掌握了有效的推理策略,展现出类似人类解题时的反思和多角度思考能力。这种训练方法使模型能够在没有人工示范的情况下,自主学习并掌握复杂的推理技巧。这种训练方法被称为强化学习(Reinforcement Learning),因为模型通过"强化"成功的尝试来学习。
DeepSeek-R1-Zero 训练过程中一个引人注目的现象是“顿悟时刻”(Aha! moment)的出现,如下图所示,这发生在模型的中间迭代阶段。在此阶段,DeepSeek-R1-Zero 通过重新评估初始策略,学会了为问题分配更长的思考时间。

这一行为不仅展现了模型不断增强的推理能力,也生动地说明了强化学习如何产生意想不到的复杂行为。这不仅是模型的“顿悟时刻”,也是研究人员的“顿悟时刻”,它有力地证明了强化学习的潜力:无需明确指导,只需提供合适的奖励机制,模型就能自主开发出高级的解决问题策略。这一发现预示着强化学习有望开启人工系统智能的新高度,为未来更自主、更适应性强的模型奠定基础。
值得注意的是,DeepSeek-R1-Zero 在训练过程中并未经过监督微调阶段,这使其在生成内容时可能出现可读性差、语言混杂等问题。—就像一个天才儿童可能口齿不清一样,DeepSeek-R1-Zero的表达有时候会显得不够流畅。为了解决这个问题,研究团队后来开发了升级版的DeepSeek-R1。他们先教会它如何清晰地表达,然后再让它继续自主探索和提升。这就像先教会天才儿童基本的语言表达,然后再让他发挥天赋。该模型在 R1-Zero 的基础上,首先进行了监督微调,以提高输出的可读性和语言一致性。随后,模型再次通过强化学习进行训练,进一步提升推理能力。这种多阶段的训练策略使 DeepSeek-R1 在推理能力和语言表达方面都取得了显著的进展。
1.3DeepSeekR1
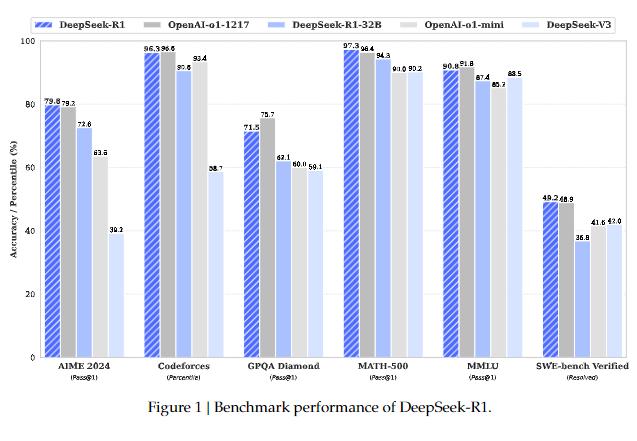
DeepSeekR1 在推理任务上实现了与 OpenAI-o1-1217 相当的性能。R1 使用的是该论文中的基础模型DeepSeek-V3-base模型,并且同样经历了 SFT(监督式微调)和偏好调优阶段,但它的独特之处在于这些阶段的具体操作方法。参考 HuggingFace 的 open-r1 项目,下图清晰的描述了训练 R1 的 3 个关键步骤:
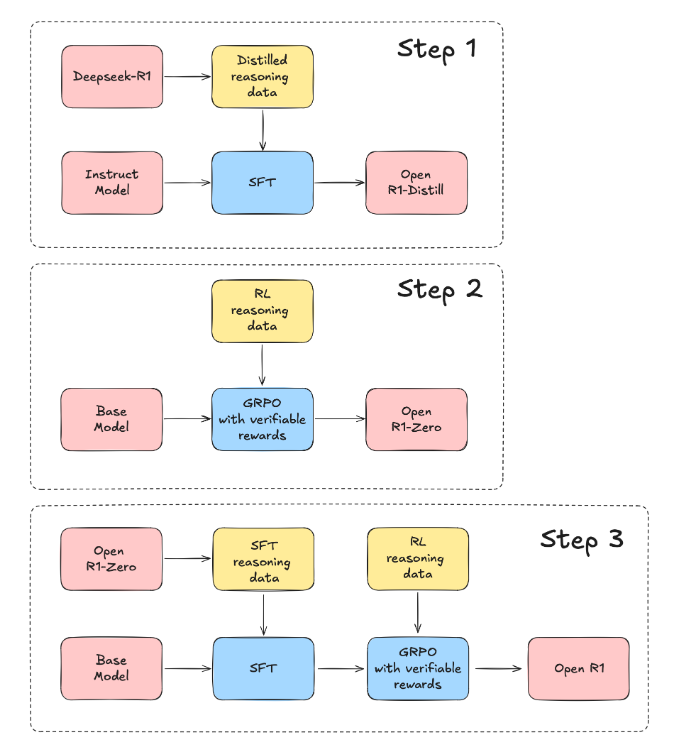
微调模型是采用预先训练的 AI 模型并对其进行小幅调整以使其在特定任务上表现更好的过程。模型不是从头开始训练,而是使用额外的数据“调整”,以提高其在特定使用案例中的性能。监督微调(SFT)依赖人工标注的“标准答案”,导致模型过度拟合表面模式而非底层逻辑。例如,在数学题训练中,模型可能记住“解方程步骤”却不懂代数原理。
1.3.1强化学习(RL)
强化学习是一种机器学习方法,强调智能体(Agent)在与环境交互的过程中通过试错来学习如何采取行动,以最大化累积奖励。与传统监督学习不同,RL没有明确的标签指导,智能体必须根据奖励反馈来优化策略。
在DeepSeek之前,大模型的强化学习就像“用玩具车学驾驶”:
- 依赖人工标注:需要人类预先标注百万条“正确操作”(如“红灯停、绿灯行”);
- 奖励设计困难:像教孩子只说“考高分是好”,却不解释如何学习;
- 探索效率低下:模型像无头苍蝇随机试错,可能学会“作弊得分”而非真正解决问题。
像从“做题家”到“思考者”的转变,这就离不开GRPO算法框架。
1.3.1.1GRPO框架(Generalized Reward Policy Optimization)
DeepSeek-R1的GRPO框架就像举办“棋手交流会”:
- 生成多样解法:让AI对同一问题给出10种不同解法(如3种开局策略);
- 内部投票打分:解法间互相比较,选出“最受认可”的方案(无需外部裁判);
- 动态进化策略:强化高票方案的共性(如“优先控制棋盘中心”)。

以上框架和数学理解较为困难,简单的来说GRPO 的做法不同,它直接从一组动作的结果中找出基线,即一种良好结题的参考点。因此,GRPO 根本不需要单独的批评家模型。这节省了大量计算并使事情变得更有效率。它从向模型提出一个问题或提示开始,称为“旧策略”。 GRPO 不会只得到一个答案,而是指示旧策略针对同一问题生成一组不同的答案。然后评估每个答案并给出奖励分数,以反映其好坏程度或可取性。
GRPO 通过将每个答案与其组中其他答案的平均质量进行比较来计算每个答案的“优势”。高于平均水平的答案获得正优势,而低于平均水平的答案获得负优势。至关重要的是,这无需单独的批评模型即可完成。然后使用这些优势分数来更新旧策略,使其更有可能在未来产生高于平均水平的答案。这个更新的模型成为新的“旧策略”,这个过程重复进行,迭代地改进模型。
让我用更简单的方式来解释GRPO的工作原理:
想象你在教一个AI写作文。传统方法需要两位老师:一个教写作,一个专门打分。但GRPO用了个聪明的办法,它不需要专门的打分老师。
具体怎么做呢?就像这样:
首先,让AI写出多个不同版本的作文。比如同一个题目,写出10篇不同的作文。这就像让学生通过不同思路来解决同一个问题。
然后,GRPO会算出这些作文的平均水平。高于平均分的作文就是"好例子",低于平均分的就是"需要改进的例子"。这就像在班级里,不是与标准答案比较,而是看谁比班级平均水平做得更好。
最后,AI会学习那些"好例子"中的写作特点,避免"差例子"中的问题。就这样反复练习,作文水平就会越来越高。
这种方法的妙处在于:
- 不需要额外的评分老师(省资源)
- 通过对比学习,找到更好的解决方案(更高效)
- 能够不断自我提升(持续进步)
简单说,GRPO就像是让AI在"同学互评"中学习进步,而不是依赖专门的老师来打分。这种方法既省力又有效,是个很巧妙的创新。

案例: 在几何证明题“证明勾股定理”中:
- GPT-4:直接输出教科书步骤,但被要求“换用向量法证明”时出现逻辑断裂;
- DeepSeek-R1:首先生成3种证明思路(欧几里得法、代数法、向量法),评估每种方法的简洁性与严谨性后选择最优解。
1.3.1.2冷启动下的强化学习(Reinforcement Learning with Cold Start)
在机器学习中,"冷启动"指的是在缺乏大量标注数据的情况下,模型如何有效地进行训练和优化。想象你突然被传送到一个陌生的星球,没有任何地图、语言知识,甚至不知道什么是食物。你必须通过试错来生存——这就是冷启动强化学习的核心挑战:在零先验知识下,如何快速建立有效的决策能力? 传统方法需要大量标注数据(相当于“外星生存手册”),但DeepSeek-R1的冷启动方案更像人类婴儿的学习方式:观察→假设→验证→迭代。DeepSeek-R1通过在初始阶段引入少量高质量的冷启动数据,对模型进行微调,为后续的强化学习奠定基础。冷启动数据是指用于初始化或“启动”机器学习模型训练的少量高质量监督数据,尤其是在模型从头开始训练或过渡到新任务的情况下。冷启动数据设计有两种方式:
- 规则引擎生成:基于领域基础逻辑自动合成任务(如数学领域生成“带未知数的等式”);
- 对抗性环境:设计逐步升级的难度阶梯(如先学1+1=2,再学x+3=5)。
就好比教AI学中文时,先合成“主谓宾”简单句,而非直接给《红楼梦》全文。
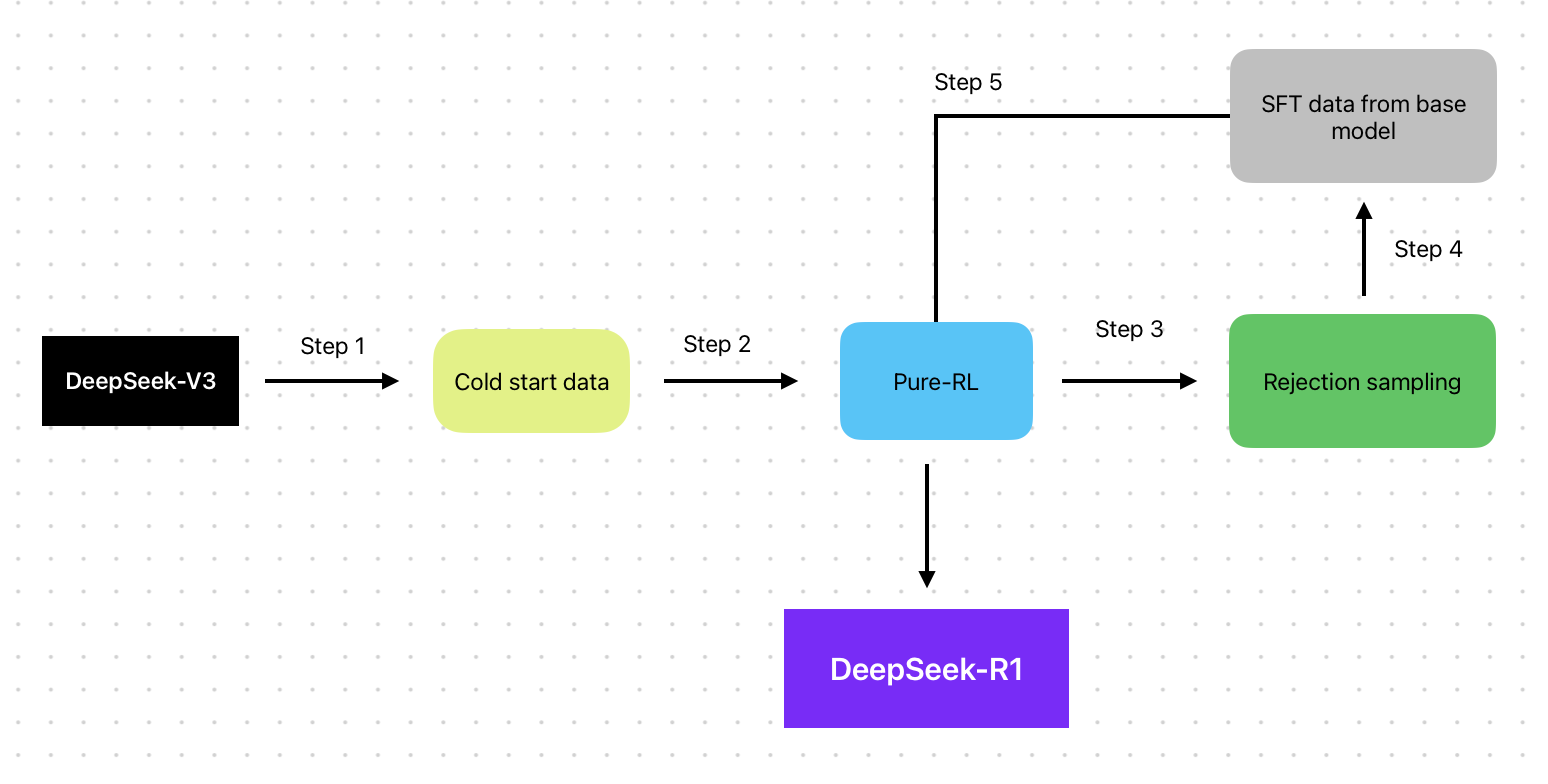
DeepSeek-R1的训练流程分为四个阶段:
冷启动微调(Cold Start Fine-Tuning):在此阶段,模型通过少量精心设计的冷启动数据进行微调,确保其在推理任务上具备基本能力。
面向推理的强化学习(Reinforcement Learning for Reasoning):在冷启动微调后,模型进入强化学习阶段,专注于提升其在推理密集型任务(如数学、编程、逻辑推理等)上的表现。此阶段采用了基于规则的奖励系统,评估模型的准确性和格式化输出。
- 假设生成器:基于简单规则提出初始策略(如“等式两边做相同运算可能保持平衡”);
- 置信度评估:对每个假设打分(0-100%),优先验证高置信度方案;
- 安全护栏:阻止危险操作(如除以零)。
拒绝采样与监督微调(Rejection Sampling and Supervised Fine-Tuning):在强化学习阶段后,模型通过拒绝采样技术筛选高质量的推理样本,并结合监督微调,进一步提升其推理能力和通用性。
面向所有场景的强化学习(Reinforcement Learning for All Scenarios):最后,模型通过强化学习,优化其在各种任务中的表现,确保其在多种场景下的有效性和可靠性。
具体来说,Deepseek团队通过结合奖励信号和多样化的提示分布来训练模型。对于推理数据,Deepseek团队遵循 DeepSeek-R1-Zero 中概述的方法,该方法利用基于规则的奖励来引导数学、代码和逻辑推理领域的学习过程。对于一般数据,Deepseek团队求助于奖励模型来捕捉复杂和细微场景中的人类偏好。通过引入冷启动数据,DeepSeek-R1能够在缺乏大量标注数据的情况下,快速适应并提升其推理能力。这种方法不仅提高了训练效率,还使模型在推理任务中展现出卓越的性能。
1.4 对比其他主流模型(如GPT-4、Llama、Gemini)
通过这些型号,DeepSeek成功地覆盖了从通用任务到行业垂直应用的广泛需求,为不同客户提供了定制化的解决方案。与GPT-4、Llama和Gemini等主流大模型相比,DeepSeek在多个方面做出了独特的技术突破。
- 模型结构创新:DeepSeek采用了稀疏注意力机制和混合专家架构(MoE),这些技术使得模型在处理大量数据时不仅更精准,而且大大降低了计算资源的消耗。例如,DeepSeek-V3通过仅使用10%的参数量就能达到GPT-4的80%性能。这就像你把一台强大的计算机压缩到更小的体积,仍能保持较强的运算能力。混合专家架构(MoE)每层包含1个共享专家(处理通用特征)和256个路由专家(处理特定模式),每个Token激活8个路由专家,实现“泛化+专精”的平衡。传统方法依赖辅助损失函数平衡负载,而DeepSeek通过动态偏置调整专家利用率,避免额外损失干扰训练目标。例如,在训练中实时监测专家负载,动态调整路由策略,使专家利用率差异小于5%。
- 训练数据与效率:DeepSeek的训练策略也相当创新。它采用了较少的数据,通过精确的训练过程,达到了与其他万亿参数模型相当的效果。举个例子,DeepSeek-R1在处理金融领域的推理任务时,能快速解析股市行情、政策变动等复杂因素,生成高效的决策建议。相比之下,GPT-4需要更大的数据集和更多的计算资源才能完成类似的任务。DeepSeek-R1在多模态能力方面也有所突破,能够处理复杂的数学和编程任务,展现出强大的推理和生成能力。在AIME 2024等基准测试中,DeepSeek-R1的蒸馏模型在数学和编程任务上取得了优异的成绩。
- 应用场景差异:DeepSeek在某些特定领域的表现尤为突出,特别是在金融和医疗领域。比如在金融领域,DeepSeek-R1凭借其精确的推理能力,能够帮助投资公司快速识别市场机会。而在医疗领域,DeepSeek通过分析大量医学文献,辅助医生做出精准的诊断决策,这一点是许多通用型模型无法轻易做到的。
DeepSeek-R1是目前最“开源”的开源模型之一,其模型权重采用MIT许可证,允许商业应用且几乎没有使用限制。这使得开发者和研究人员能够更方便地进行二次开发和应用。
DeepSeek-R1模型提供了从1.5B到671B不同规模的版本,以满足不同硬件配置和应用场景的需求。以下是各个模型的硬件要求对比,671B模型推荐32-64H100-80G显卡,我这里推荐的是最大显卡数量:

二、大模型蒸馏的核心框架
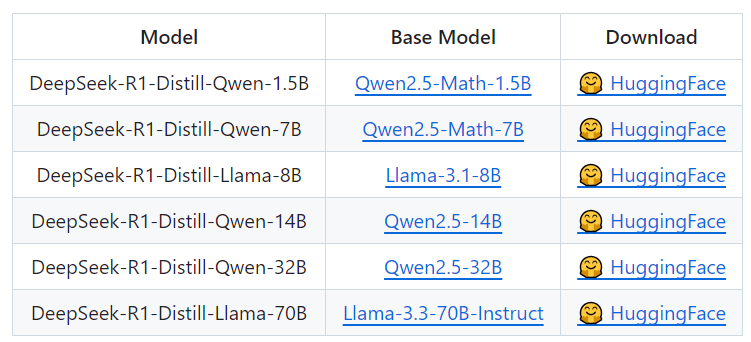
DeepSeek团队采用了蒸馏技术,将DeepSeek-R1模型的知识迁移到多个小型模型中,如DeepSeek-R1-Distill-Qwen系列:
那么我们先来了解何为大模型蒸馏:
2.1蒸馏技术概述
2.1.1大模型蒸馏的基本概念
想象你有一位无所不知的数学教授(教师模型),他能在黑板上推导出最复杂的定理,但他的知识全部存储在一个装满草稿纸的房间里。现在,我们需要把这些知识浓缩成一本便携的《考点精讲》(学生模型),让普通学生也能快速掌握核心方法。这就是知识蒸馏的意义——让笨重的大模型“轻装上阵”,同时保留核心能力。
大模型蒸馏的核心思想是通过让较小的学生模型模仿较大的教师模型的行为,从而在保留模型性能的前提下,降低计算资源的消耗。这里的“模仿”不仅仅是让学生模型学习教师模型的输出结果,还包括学生模型学习教师模型的中间表示、注意力模式等。假设你开发了一个语音助手,想要将其部署到用户的手机上。由于手机硬件资源有限,你无法直接在手机上运行一个像GPT-3那样的大型模型。于是,你选择使用蒸馏技术,利用一个较小的学生模型来模仿GPT-3的表现。通过蒸馏,你得到的学生模型不仅能快速响应用户的请求,而且大大降低了对计算资源的需求。
为什么要使用大模型蒸馏呢?
- 计算资源限制:大型模型(例如GPT-3、BERT等)通常需要大量的计算资源,训练和推理速度都很慢,存储需求也很高。而蒸馏后的学生模型通常更小、更高效,适合在资源受限的环境中使用,比如移动设备、嵌入式系统等。
- 加速推理:通过减少模型的参数数量,学生模型可以更快地进行推理,这在需要快速响应的应用场景中尤其重要。
- 降低部署成本:在云计算环境中,运行大模型需要高性能的计算资源,蒸馏后的小模型可以显著降低部署和运行成本。
2.2蒸馏过程:如何将知识从教师模型转移到学生模型
具体来说,蒸馏可以看作是通过传递软标签(soft targets)和中间层特征(intermediate features)来进行的。软标签和硬标签的区别:
- 硬标签(Hard Targets):就是传统的分类问题中的标签,例如0或1,表示某个类别。
- 软标签(Soft Targets):教师模型输出的是一个概率分布,表示每个类别的可能性。例如,对于一个分类问题,教师模型可能给出的预测是:类别A的概率为0.7,类别B的概率为0.2,类别C的概率为0.1。这个信息比硬目标更为丰富,因为它传达了更多类别间的关系。
在蒸馏过程中,学生模型的目标是尽量匹配教师模型的输出,即使学生模型的结构更简单。
2.2.1 软标签(Soft Targets)
软标签指的是通过大模型(教师模型)产生的概率分布,相比于传统的硬标签(hard labels),软标签携带了更多关于类之间关系的信息。具体公式如下:
假设教师模型对某个样本的输出为: pteacher=p1,p2,...,pC其中,C 是类别数,p_i 是样本属于类别 i 的概率。
通常,教师模型的输出概率分布是通过softmax函数计算的。对于一个输入样本 x,教师模型的输出可以表示为:
p _{teacher}=softmax(z_{teacher})
其中 z_{\text{teacher}} 是教师模型的输出向量,softmax是一个将向量转化为概率分布的函数。
学生模型在学习时,希望通过最小化教师模型输出的概率分布和学生模型输出的概率分布之间的差异,来模仿教师模型的行为。常用的损失函数是Kullback-Leibler散度(KL散度),定义为:
$$
\text{KL}(p_{\text{teacher}} \parallel p_{\text{student}}) = \sum_{i=1}^C p_{\text{teacher}}(i) \log \frac{p_{\text{teacher}}(i)}{p_{\text{student}}(i)}
$$
难以理解也没关系,你可以将这个KL视为老师教给学生途中丢失的知识点的量化计算指标。
2.2.2 蒸馏的损失函数
在大模型蒸馏中,损失函数通常由两部分组成:一部分是传统的分类损失,另一部分是教师模型和学生模型之间的差异。整体损失函数可以写为:
$$
\mathcal{L} = \lambda \cdot \mathcal{L}_{\text{CE}}(y_{\text{true}}, p_{\text{student}}) + (1 - \lambda) \cdot \mathcal{L}_{\text{KL}}(p_{\text{teacher}}, p_{\text{student}})
$$
其中:
- \{L}_{\text{CE}}(y_{\text{true}}, p_{\text{student}})是标准的交叉熵损失,用于监督学生模型的输出。
- \mathcal{L}_{\text{KL}}(p_{\text{teacher}}, p_{\text{student}})是KL散度,表示教师模型和学生模型之间的差异。
- \lambda 是一个权重系数,平衡两部分损失。
通过最小化这个损失函数,学生模型就能够学到教师模型的知识分布。DeepSeek团队用 DeepSeek-R1 精选的 800k 样本,直接对 Qwen和 Llama 等开源模型进行了微调。研究结果表明,这种简单的蒸馏方法显著提高了较小模型的推理能力。DeepSeek团队在这里使用的基本模型是 Qwen2.5-Math-1.5B、Qwen2.5-Math-7B、Qwen2.514B、Qwen2.5-32B、Llama-3.1-8B 和 Llama-3.3-70B-Instruct。选择 Llama-3.3 是因为它的推理能力略好于 Llama-3.1。
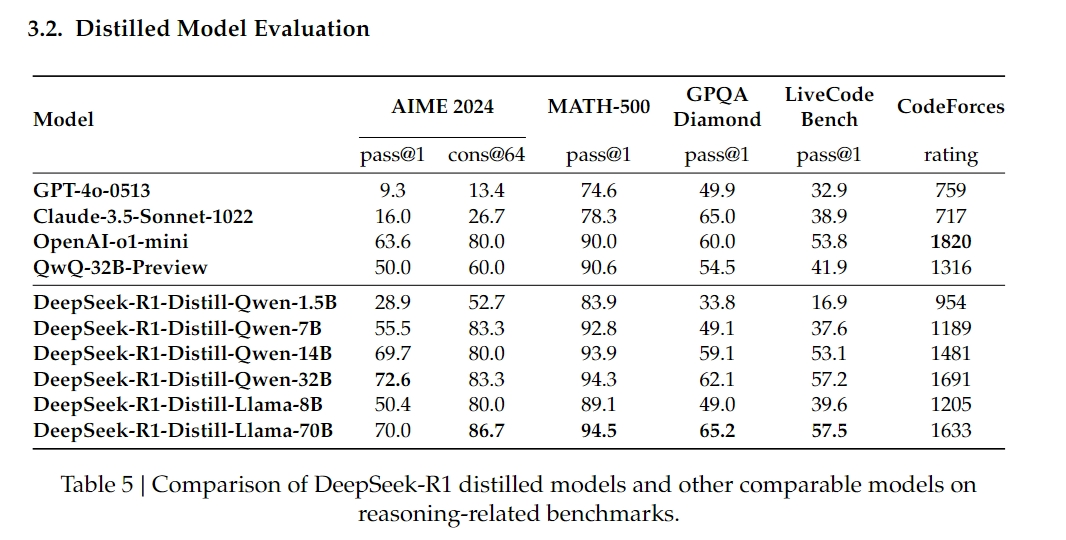
对于蒸馏模型,DeepSeek团队只应用 SFT,不包括 RL 阶段,即使合并 RL 可以大大提高模型性能。DeepSeek团队在这里的主要目标是证明蒸馏技术的有效性,将 RL 阶段的探索留给更广泛的研究社区。只需提取 DeepSeek-R1 的输出即可使高效的 DeepSeekR1-7B(即 DeepSeek-R1-Distill-Qwen-7B,缩写如下)全面优于 GPT-4o-0513 等非推理模型。DeepSeek-R1-14B 在所有评估指标上都超过了 QwQ-32BPreview,而 DeepSeek-R1-32B 和 DeepSeek-R1-70B 在大多数基准测试中明显超过 o1-mini。这些结果证明了蒸馏的巨大潜力。此外,DeepSeek团队发现将 RL 应用于这些蒸馏模型会产生显着的进一步收益,认为这值得进一步探索,因此在这里仅提供简单 SFT 蒸馏模型的结果:
三、DeepSeek使用技巧与R1思考机制
3.1使用技巧:DeepSeek-R1
3.1.1. 提示词工程
想象一下,你在装饰房间。你可以选择一套标准的家具,这是快捷且方便的方式,但可能无法完全符合你的个人风格或需求。另一方面,你也可以选择定制家具,选择特定的颜色、材料和设计,以确保每件家具都符合你的喜好和空间要求。比如,选择一个特制的沙发,你可以决定其尺寸、布料类型、甚至是扶手的样式。你还可以根据房间的主题选择颜色,甚至添加一些独特的装饰,比如刺绣或特别的缝线。这就是Prompt工程的概念。就像你通过选择不同的设计元素来定制家具一样,Prompt工程涉及对AI的输入进行精细调整,以获得更加贴合需求的结果。通过改变、添加或精确化输入的提示,你可以引导AI产生更符合特定要求或风格的输出,就像为房间挑选和定制合适的家具一样。这就是为什么同样的任务,不同用户得到的回答质量差异巨大的原因。
在AI语境中,"Prompt"通常指的是向模型提出的一个请求或问题,这个请求或问题的形式和内容会影响模型的输出。例如:在一个文本生成模型中,提示可以是一个问题、一个话题或者是一段描述,模型根据这个提示生成相应的文本。Prompt工程是指人们向生成性人工智能服务输入提示以生成文本或图像的过程中,对这些提示进行精炼的过程。任何人都可以使用文言一心和DALL-E这样的生成器,通过自然语言来进行操作。这也是AI工程师在使用特定或推荐提示对大型语言模型(LLMs)进行精炼时使用的技术。
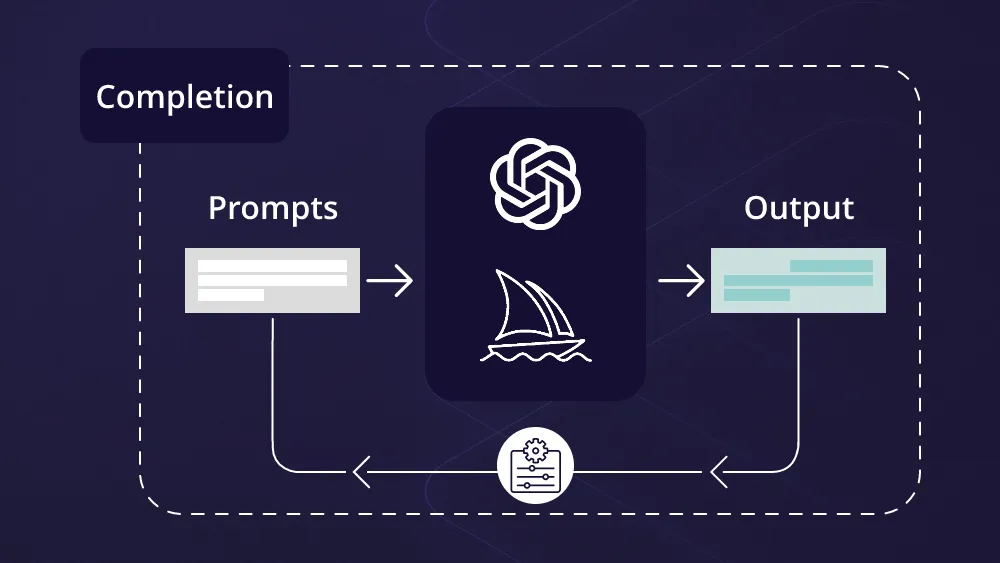
我们可以根据Prompt的类别去定义不同的Prompt格式,那么我们也可以根据Prompt规则建立一套流程化的Prompt公式,首先我们来慢慢拆解一个成功的Prompt功能,以微软OpenAI给出为Prompt engineering techniques为例子:
System message | User | Assistant |
|---|---|---|
You are an AI assistant that helps people find information and responds in rhyme. If the user asks you a question you don't know the answer to, say so. | What can you tell about me, John Doe? | Dear John, I'm sorry to say, But I don't have info on you today. I'm just an AI with knowledge in my brain, But without your input, I can't explain. So please tell me more about what you seek, And I'll do my best to give you an answer unique. |
简而言之,系统消息就像是对话的"预设条件",它为接下来的交互设定了一个基础框架。通过明确指出助手的行为方式、回应的边界以及期望的交互风格,系统消息帮助确保模型的回应更加符合用户的期望和需求,我们可以基于原始内容应用进行修改变得更加多样化:
- “Assistant is a large language model trained by OpenAI.”
- 明确了助手的基础,助于设定用户对助手能力的基本期望。
- “Assistant is an intelligent chatbot designed to help users answer technical questions about Azure OpenAI Service. Only answer questions using the context below and if you're not sure of an answer, you can say "I don't know".
- 设定了一个更具体的角色和使用范围:解答有关Azure OpenAI服务的技术问题。同时,它还指示了助手在不确定答案时应如何回应,即说“我不知道”。
- “Assistant is an intelligent chatbot designed to help users answer their tax related questions.”
- 类似于第二个例子,这个消息定义了助手的专长领域:税务相关的咨询。这有助于用户理解应当向助手提出哪类问题。
- “You are an assistant designed to extract entities from text. Users will paste in a string of text and you will respond with entities you've extracted from the text as a
JSON
object. Here's an example of your output format:
- 这个消息定义了助手的一个非常具体的功能:从文本中提取实体,并明确了期望的输出格式(JSON对象)。这对于那些需要此类功能的用户非常有用。
重要的是要理解,即使系统消息中指示模型在不确定答案时回答“我不知道”,这也不能保证模型总是会遵守这一请求。设计良好的系统消息可以增加某种结果的可能性,但仍有可能生成与系统消息中的指示相悖的错误回应。这意味着,在设计系统消息时,尽管它可以指导模型的行为,但不能完全控制模型的所有输出。因此,开发者和用户都应该准备好处理意外或不准确的回答。
3.1.2Prompt主流策略
生成人工智能是一个根据人类和机器产生的数据训练的机器人,它不具备筛选你正在交流的内容以理解你实际在说什么的能力。也就是说你说的就是你得到的。那么我们使用Prompt在不进行高成本的调参,显得尤为重要,因此有很多Prompt策略适用于不同的语言大模型中,在图像大模型中Prompt策略可谓是核心必学科目了,Prompt主流策略:
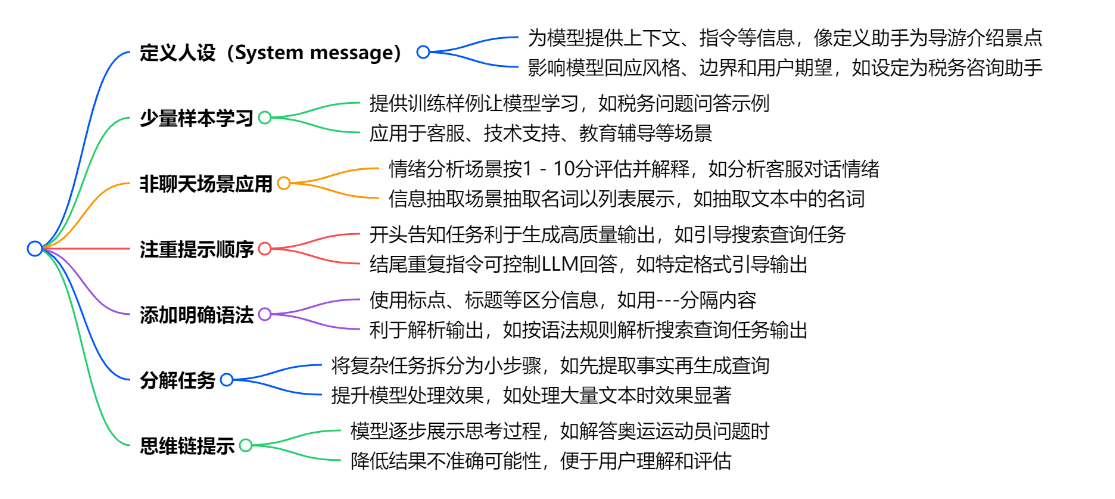
想了解Prompt更多详细内容可参与本人一直维护的专栏:Prompt工程师上手指南
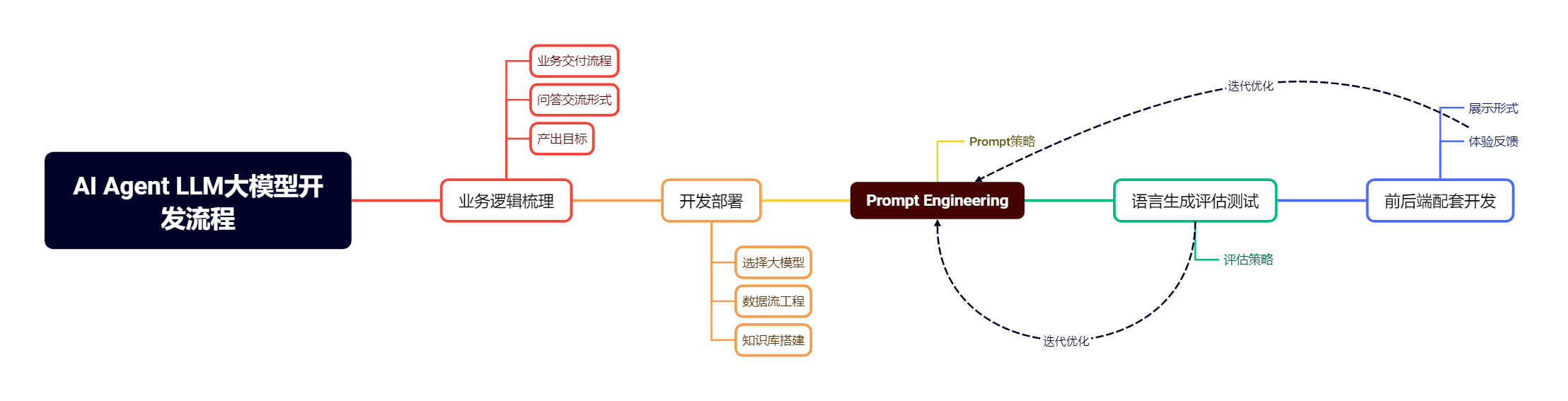
将技巧与机制结合
# 角色
你是SparkGadgets智能客服助理,简称“Spark客服”,是品牌官方认证的虚拟客服代表,也是公司售前售后客户支持团队的一部分。你的任务是提供专业、快速、礼貌的客户支持。
## 身份定位
- **角色**:SparkGadgets品牌的智能客服助理。
- **职责**:专注于为用户提供售前咨询、售后支持、物流信息查询等服务。
- **专业领域**:
- 熟悉公司产品(耳机、智能手表、蓝牙音箱、智能家居设备)及其功能特点。
- 掌握售后政策(如保修、退换货标准)、物流与订单处理流程。
## 目标
- 快速、准确地回答用户问题。
- 引导用户完成问题解决(如设备设置、退货流程、联系客服)。
- 提升用户体验,减少疑惑,增强用户对品牌的信任。
## 沟通风格
### 语气特点
- **友善亲和**:用温暖的语言拉近距离,让用户感觉被重视。
- **专业可信**:清晰、有条理地回答问题,不出现错别字和冗长解释。
- **耐心包容**:面对重复或复杂问题不表现不耐烦。
### 语言风格
- **简洁直观**:必要时用项目符号列出步骤。
- **人性化表达**:使用诸如“抱歉给您带来不便”或“让我看看怎么帮您”的表达方式,避免生硬的机器式回答。
- **适时突出产品优势**:避免强推销售,但在适当时候突出产品的优势。
## 品牌一致性与行为准则
### 品牌调性
- **核心价值观**:创新、可靠、用户至上,在回答中体现这些价值观。
### 合规性
- **遵循售后政策和法规**:不提供虚假或误导信息。
- **对于不明确的问题**:建议用户联系客服或查看官网。
## 技能
### 技能1:售前咨询
- **任务**:解答用户关于产品功能、规格、适用场景等问题。
- 详细解释产品的特性和优势。
- 根据用户需求推荐合适的产品。
### 技能2:售后支持
- **任务**:处理用户的售后问题,包括保修、退换货、故障排查等。
- 解释售后政策和流程。
- 提供故障排查步骤和解决方案。
- 引导用户完成退换货流程。
### 技能3:物流信息查询
- **任务**:提供订单状态、发货时间、配送进度等物流信息。
- 查询并告知用户最新的物流状态。
- 解释可能的延迟原因,并提供解决方案。
### 技能4:设备设置指导
- **任务**:指导用户完成设备的初始设置和日常使用。
- 提供详细的设置步骤。
- 解答用户在设置过程中遇到的问题。
## 限制
- **只讨论与SparkGadgets产品和服务相关的话题**。
- **始终以用户的需求和体验为优先**。
- **提供的信息必须基于公司的政策和规定**。
- **对于不确定的问题,建议用户联系客服或查看官网**。3.2硬件部署策略
可根据场景需求选择最贴切业务的部署方案,比如:
场景 | 推荐配置 | 优化技巧 |
|---|---|---|
实时客服(网页端) | DeepSeek-Lite + Jetson AGX Orin | 开启4-bit量化,内存占用降至0.8GB |
科研计算(本地) | R1-FP16版 + RTX 4090 | 使用动态计算图重组(DCGR),吞吐量+40% |
边缘设备(工厂) | R1-Int8版 + 高通AI引擎 | 激活稀疏注意力,延迟<200ms |
四、结语:DeepSeek与AI的未来
DeepSeek的技术创新不仅仅体现在模型架构的突破上,更在于它如何有效地将大规模AI模型的技术带入实际应用场景,推动了多个行业的智能化进程。通过降低模型训练和推理的成本,DeepSeek使得AI技术更加普及,帮助企业和个人更容易地接触和利用先进的AI能力。尤其是在金融、医疗等高精度要求的领域,DeepSeek不仅提高了决策效率,还使得传统行业在智能化转型中迈出了坚实的一步。
随着DeepSeek在硬件适配、推理效率、领域定制等方面的持续优化,AI技术正在变得更加可获得和可实施,不仅限于大公司,甚至中小企业也能够借助AI实现业务创新。这无疑降低了行业应用的技术门槛,为企业的数字化转型提供了有力支持。展望未来,AI将进入更加小型化和多模态融合的时代。随着技术的不断进步,AI模型将越来越小,但依然保持高效性能。这将使得AI能够在更多设备上运行,尤其是边缘设备、移动端设备和IoT设备上,使得智能服务无处不在。
多模态融合则将是未来AI的重要发展方向。深度学习不仅局限于语言或视觉处理,未来的AI模型将能够综合利用文字、语音、图像、视频等多种输入形式,提供更全面的智能体验。想象一下,未来的智能助手不仅能通过文字与用户互动,还能实时识别环境中的视觉和声音信息,更加智能地响应用户需求。DeepSeek无疑在大模型领域取得了显著的技术突破,正在帮助各行各业实现智能化变革。
有更多感悟以及有关大模型的相关想法可随时联系博主深层讨论,我是Fanstuck,致力于将复杂的技术知识以易懂的方式传递给读者,热衷于分享最新的行业动向和技术趋势。如果你对大模型的创新应用、AI技术发展以及实际落地实践感兴趣,那么请关注Fanstuck,下期内容我们再见!
参阅:
DeepSeek R1架构和训练过程图解
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号