【C++】二叉搜索树(搜索二叉树)


本篇聊聊二叉搜索树,二叉树基本知识的详细讲解在【数据结构】二叉树 。
1.二叉树搜索的概念及性能
1.1 概念
⼆叉搜索树⼜称⼆叉排序树,它有可能是⼀棵空树,或者是具有以下性质的⼆叉树:
- 若它的左⼦树不为空,则左⼦树上所有结点的值都⼩于或等于根结点的值
- 若它的右⼦树不为空,则右⼦树上所有结点的值都⼤于或等于根结点的值
- 它的左右⼦树也分别为⼆叉搜索树
- ⼆叉搜索树中可以⽀持插⼊相等的值,也可以不⽀持插⼊相等的值, 具体看使⽤场景 定义
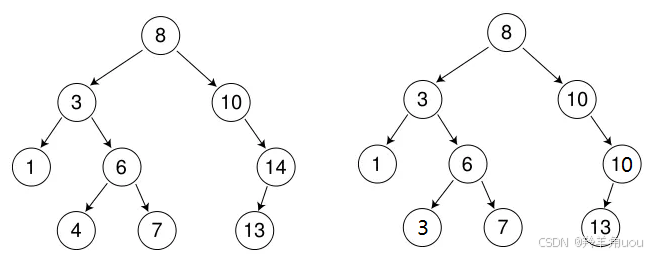
1.2 性能分析
N是节点个数。
- 最优情况下:⼆叉搜索树为完全⼆叉树(或者接近完全⼆叉树),其⾼度为:
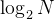
\log _{2}N
- 最坏情况下:⼆叉搜索树退化为单⽀树(或者类似单⽀),其⾼度近似为节点个数:

N
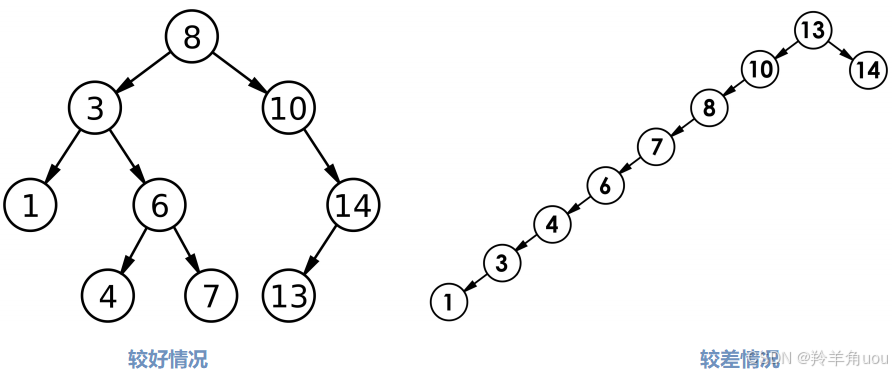
所以综合⽽⾔⼆叉搜索树增删查改时间复杂度为:
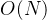
O(N)
那么这样的效率显然是⽆法满⾜我们需求的,我们后续课程需要继续讲解⼆叉搜索树的变形,平衡⼆叉搜索树、AVL树和红⿊树,才能适⽤于我们在内存中存储和搜索数据。
另外需要说明的是,⼆分查找也可以实现 O(log2 N) 级别的查找效率,但是⼆分查找有两⼤缺陷:
1. 需要存储在⽀持下标随机访问的结构中,并且有序。
2. 插⼊和删除数据效率很低,因为存储在下标随机访问的结构中,插⼊和删除数据⼀般需要挪动数
据。
这⾥也就体现出了平衡⼆叉搜索树的价值。
2.二叉搜索树的实现
2.1 准备工作
新建头文件BSTree.h和源文件test.cpp,一个放代码实现,一个测试这些代码。

在BSTree.h里先建立一下二叉搜索树的节点的结构,放一些需要用到的头文件。
#pragma once
#include <iostream>
using namespace std;
template<class K>
struct BSTNode //节点
{
K _key; //节点值
BSTNode<K>* _left; //左孩子
BSTNode<K>* _right;//右孩子
BSTNode(const K& key)//构造函数
:_key(key)
, _left(nullptr)
, _right(nullptr)
{}
};然后在BSTree.h里开始实现二叉搜索树的结构。
template<class K>
class BSTree //二叉搜索树
{
};在BSTree类里面改一下BSTNode<k>的名字,然后放成员变量,成员变量就一个根节点。
template<class K>
class BSTree //二叉搜索树
{
typedef BSTNode<K> Node;
private:
Node* _root = nullptr;
};改名的写法还可以像下面这句代码写,在现阶段两者没区别。
using Node = BSTNode<K>; //用using改名现在准备工作做好了。
2.2 插入数据
二叉搜索树的插⼊逻辑如下:
- 树为空,则直接新增结点,赋值给root指针。
- 树不为空,按⼆叉搜索树性质,插⼊值⽐当前结点⼤往右⾛,插⼊值⽐当前结点⼩往左⾛,找到空位置,插⼊新结点。
- 如果⽀持插⼊相等的值,插⼊值跟当前结点相等的值可以往右⾛,也可以往左⾛,找到空位置,插⼊新结点。(要注意的是要保持逻辑⼀致性,插⼊相等的值不要⼀会往右⾛,⼀会往左⾛)。
比如下面这颗二叉搜索树,我们现在往里插入一个16吧。
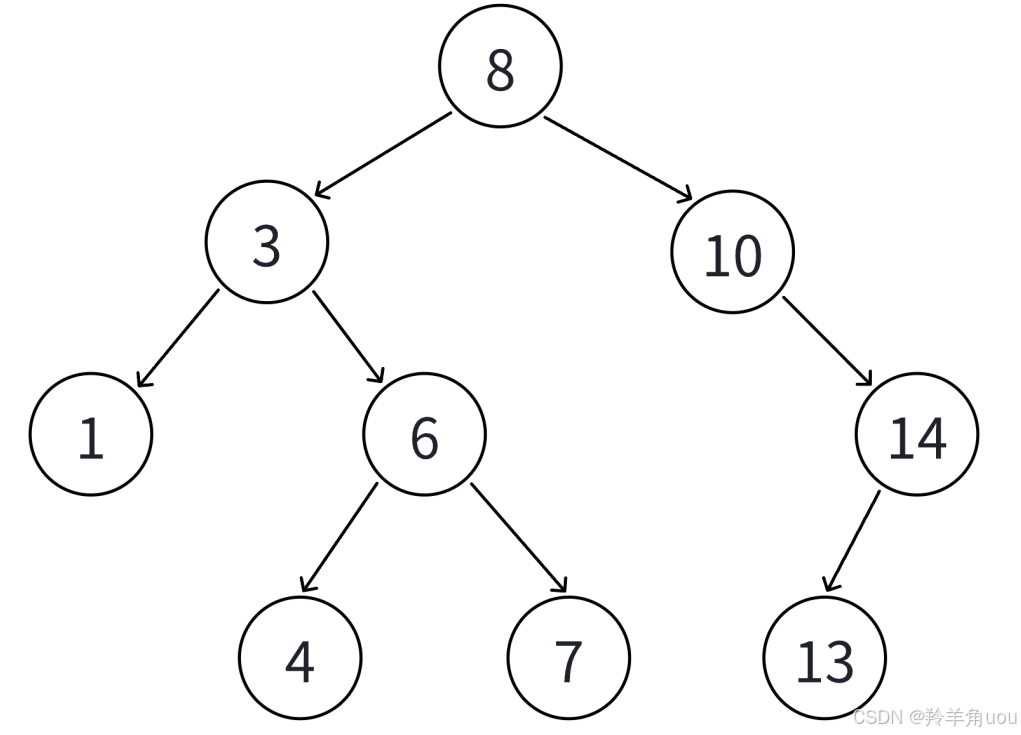
16比8大,往右边放;16比10大,往右边放;16比14大,往右边放;14没有右节点,所以16就是14的右孩子。
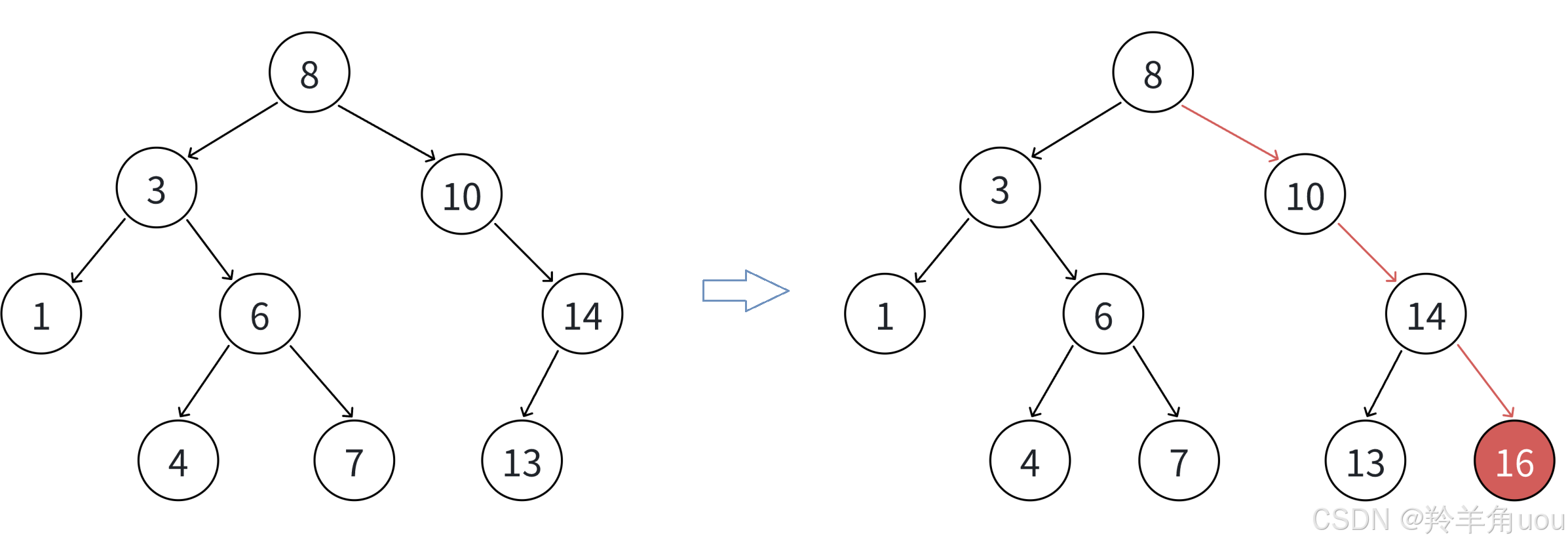
再比如我们现在插入一个4。4比8小,往左边放;4比3大,往右边放;4比6小,往左边放;4等于4,假设相等默认往左边放。
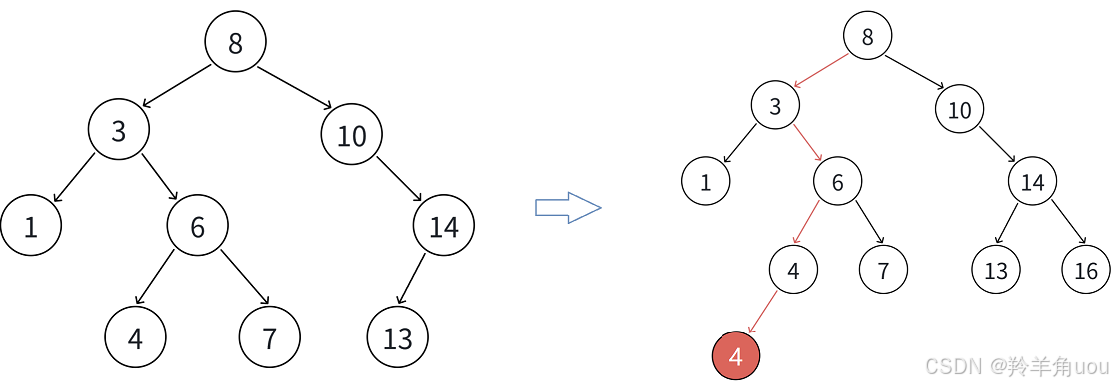
这是允许相同数据插入的情况,我们也可以不允许相同数据插入。
在BSTree类里public实现,代码如下。
public:
bool Insert(const K& key) //插入数据
{
if (_root == nullptr)
_root = new Node(key);
Node* cur = _root;
Node* parent = NULL;
while (cur)
{
if (cur->_key > key) //插入值小于根节点,左走
{
parent = cur; //先记录当前根节点
cur = cur->_left; //移动cur
}
else if (cur->_key < key)//插入值大于根节点,右走
{
parent = cur; //先记录当前根节点
cur = cur->_right; //移动cur
}
else //插入值等于根节点,不给插入
return false;
}
cur = new Node(key);
if (parent->_key > key) //插入值小于自己的根节点,放左边
parent->_left = cur;
else
parent->_right = cur;
return true;
}这是相同数据不允许插入的写法,如果说你想相同数据允许插入,改一下while循环里面的代码逻辑就可以了。
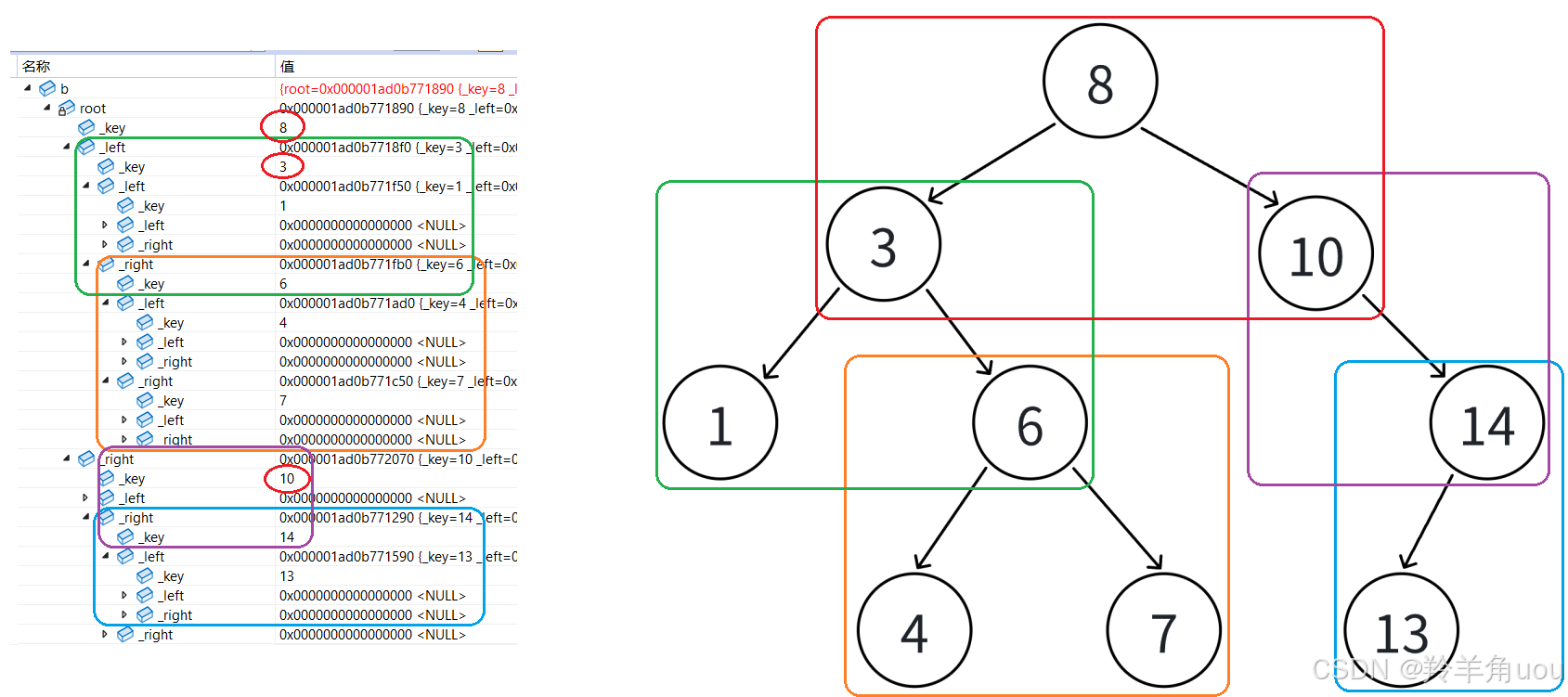
在test.cpp里检测一下。
#include "BSTree.h"
int main()
{
int a[] = { 8, 3, 1, 10, 6, 4, 7, 14, 13, 1 };
BSTree<int> b;
for (auto e : a) //用范围for把数组全插入
{
b.Insert(e);
}
return 0;
}
这里调试观察不太方便,我们写一个中序遍历来打印看吧。
在BSTree类里private实现,代码如下。
void _Inorder(const Node* root) //中序遍历
{
if (root == nullptr)
return;
_Inorder(root->_left);
cout << root->_key << ' ';
_Inorder(root->_right);
}由于根节点_root是私有的,在类外不能访问,但是在类内可以,所以我们在BSTree类里public实现下面这个函数。
void Inorder() //中序遍历
{
_Inorder(_root);
cout << endl;
}再在test.cpp里检测一下,用中序遍历刚刚创建的二叉搜索树。
int main()
{
int a[] = { 8, 3, 1, 10, 6, 4, 7, 14, 13, 1 };
BSTree<int> b;
for (auto e : a) //用范围for把数组全插入
{
b.Insert(e);
}
b.Inorder(); //中序遍历
return 0;
}
可以发现我们虽然有两个1,但是只插入了一个。
2.3 查找数据
二叉搜索树的查找逻辑如下:
- 从根开始⽐较,查找x,x⽐根的值⼤则往右边⾛查找,x⽐根值⼩则往左边⾛查找。
- 最多查找⾼度次,如果⾛到空还没找到,则这个值不存在。
- 如果不⽀持插⼊相等的值,找到x即可返回
- 如果⽀持插⼊相等的值,意味着有多个x存在,⼀般要求查找中序的第⼀个x。
在BSTree类里public实现,代码如下。
bool Find(const K& x)
{
if (_root == nullptr)
{
cout << "NULL" << endl;
return false;
}
Node* cur = _root;
while (cur)
{
if (cur->_key > x)
cur = cur->_left;
else if (cur->_key < x)
cur = cur->_right;
else
{
cout << "Find:" << x << endl;
return true;
}
}
cout << "Didn't find" << endl;
return false;
}在test.cpp里检测一下。
int main()
{
int a[] = { 8, 3, 1, 10, 6, 4, 7, 14, 13, 1 };
BSTree<int> b;
for (auto e : a) //用范围for把数组全插入
{
b.Insert(e);
}
b.Inorder(); //中序遍历
b.Find(2);
b.Find(3);
return 0;
}
2.4 删除数据
二叉搜索树的删除逻辑如下:
- ⾸先查找元素是否在⼆叉搜索树中,如果不存在,则返回false。
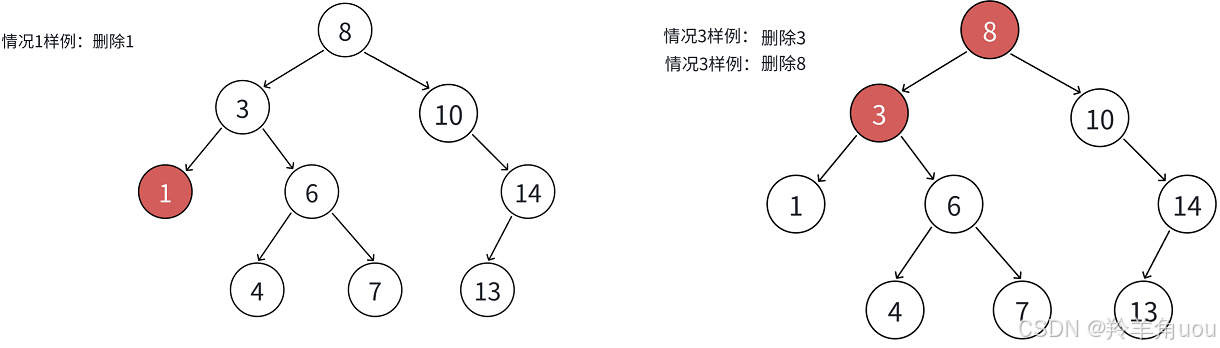
- 如果查找元素存在则分以下三种情况分别处理:
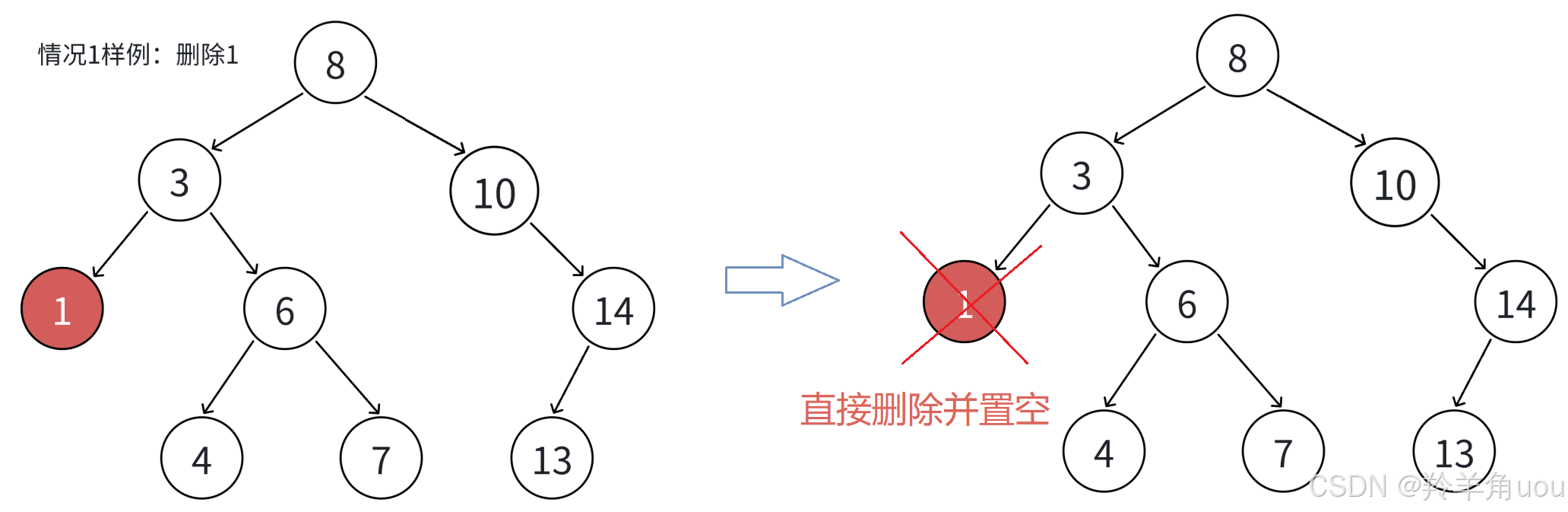
- 要删除结点N左右孩⼦均为空
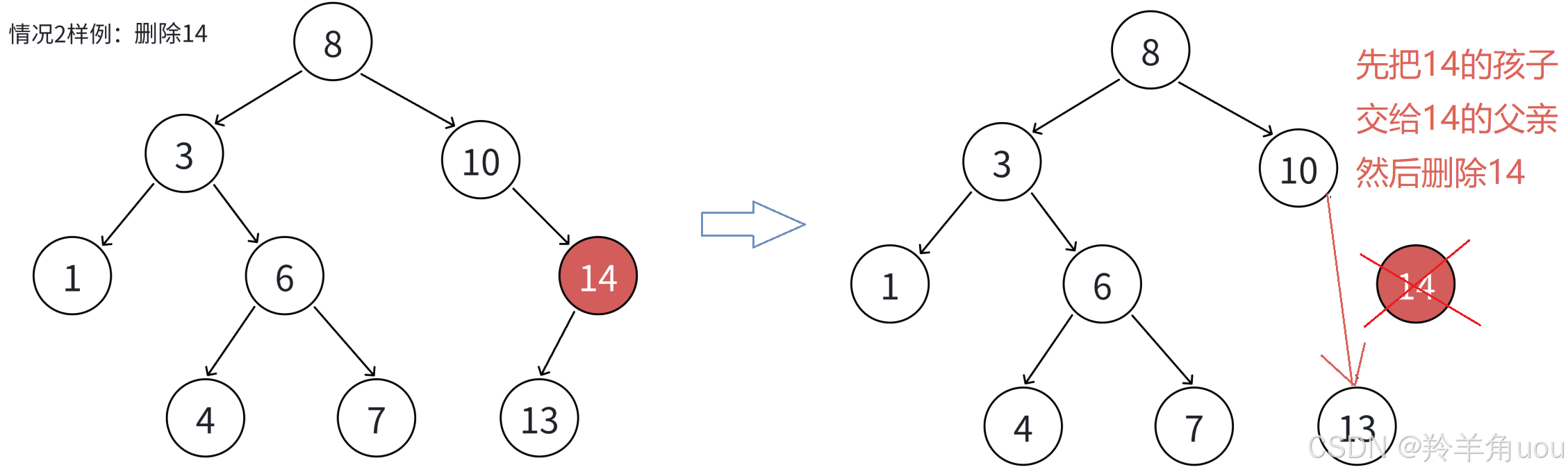
- 要删除的结点N左右其中一个孩子为空
- 要删除的结点N左右孩⼦结点均不为空
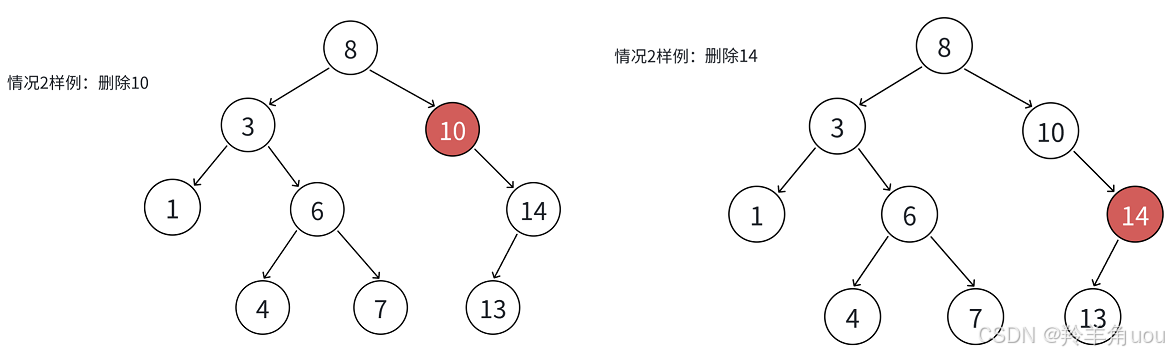
应对上面三种情况,做出如下解决方法:
- 左右孩⼦均为空时,把N结点的⽗亲对应孩⼦指针指向空,直接删除N结点
- 其中一个孩子为空时,把N结点的⽗亲对应孩⼦指针指向N的右孩⼦或左孩子,直接删除N结点
- 左右孩⼦结点均不为空时,⽆法直接删除N结点,因为N的两个孩⼦⽆处安放,只能⽤替换法删除:找N左⼦树的值最⼤结点R(最右结点)或者N右⼦树的值最⼩结点R(最左结点)替代N,因为这两个结点中任意⼀个,放到N的位置,都满⾜⼆叉搜索树的规则。
替代N的意思就是N和R的两个结点的值交换,转⽽变成删除R结点,R结点符合情况2,可以直接删除。
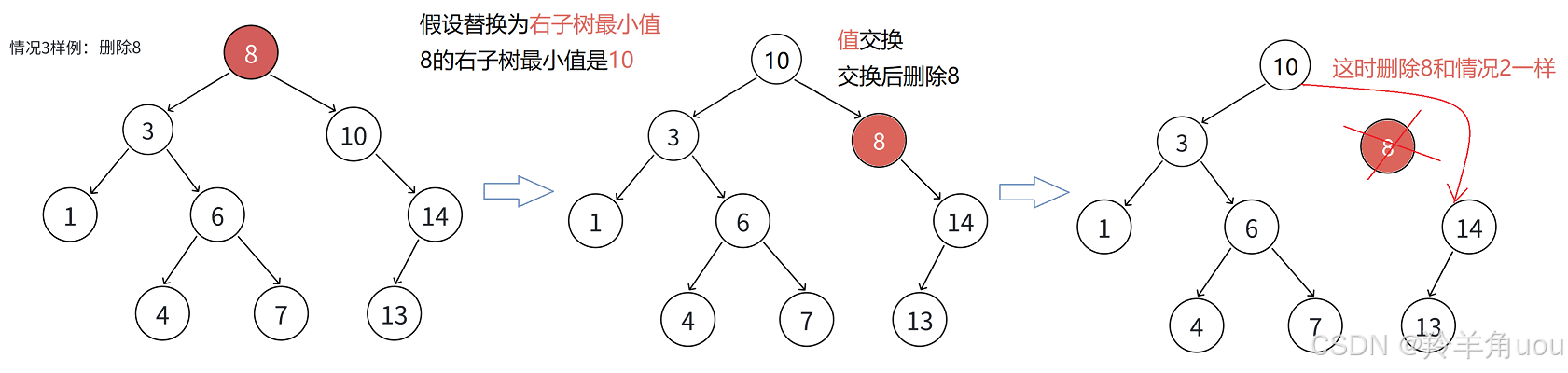
现在我们就可以分情况写代码了。
bool Erase(const K& key) //删除数据
{
if (_root == nullptr) //空树,没什么删的
return false;
if (_root->_left == nullptr && _root->_right == nullptr)//特殊处理的情况
{
delete(_root);
_root = nullptr;
}
else //正常情况
{
Node* cur = _root;
Node* parent = cur;
while (cur) //先找到要删除的节点
{
if (cur->_key > key)
{
parent = cur;
cur = cur->_left;
}
else if (cur->_key < key)
{
parent = cur;
cur = cur->_right;
}
else //此时找到了要删除的值
break;
}
if (cur == nullptr) //如果删的数据二叉树里根本没有
return false;
if (cur->_left && cur->_right) //左右都不为空
{
Node* min = cur->_right; //和右子树最小值替换
while (min->_left)
{
parent = min;
min = min->_left;
}
cur->_key = min->_key;
cur = min;
}
//交换之后删除节点的逻辑和下面一致
//左右都为空的情况也符合下面的逻辑
if (cur->_left == nullptr) //左为空,右不为空
{
if (parent->_key > cur->_key)
parent->_left = cur->_right;
else
parent->_right = cur->_right;
delete(cur);
cur = nullptr;
}
else //右为空,左不为空
{
if (parent->_key > cur->_key)
parent->_left = cur->_left;
else
parent->_right = cur->_left;
delete(cur);
cur = nullptr;
}
}
return true;
}在test.cpp里检测一下。
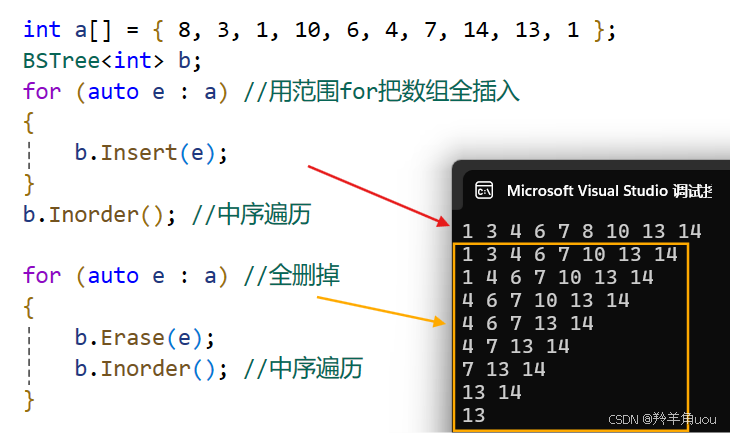
int a[] = { 8, 3, 1, 10, 6, 4, 7, 14, 13, 1 };
BSTree<int> b;
for (auto e : a) //用范围for把数组全插入
{
b.Insert(e);
}
b.Inorder(); //中序遍历
for (auto e : a) //全删掉
{
b.Erase(e);
b.Inorder(); //中序遍历
}
删除的思路就是前面说过的,但是代码的实现有很多种,而且删除也比较复杂,要耐心分析。
3.⼆叉搜索树key和key/value使⽤场景
3.1 key搜索场景
只有key作为关键码,结构中只需要存储key即可,关键码即为需要搜索到的值,搜索场景 只需要判断key在不在 。key的搜索场景实现的⼆叉树搜索树⽀持增删查,但是 不⽀持修改 ,修改key破坏搜索树结构了。
- 场景1:⼩区⽆⼈值守⻋库,⼩区⻋库买了⻋位的业主⻋才能进⼩区,那么物业会把买了⻋位的业主的⻋牌号录⼊后台系统,⻋辆进⼊时扫描⻋牌在不在系统中,在则抬杆,不在则提⽰⾮本⼩区⻋辆,⽆法进⼊。
- 场景2:检查⼀篇英⽂ 章单词拼写是否正确,将词库中所有单词放⼊⼆叉搜索树,读取⽂章中的单词,查找是否在⼆叉搜索树中,不在则波浪线标红提⽰。
3.2 key/value搜索场景
每⼀个关键码key,都有与之对应的值value,value可以任意类型对象。树的结构中(结点)除了需要存储key还要存储对应的value, 增/删/查还是以key为关键字 ⾛⼆叉搜索树的规则进⾏⽐较,可以快速查找到key对应的value。key/value的搜索场景实现的⼆叉树搜索树⽀持修改,但是 不⽀持修改key ,修改key破坏搜索树性质了, 可以修改value 。
- 场景1:简单中英互译字典,树的结构中(结点)存储key(英⽂)和vlaue(中⽂),搜索时输⼊英⽂,则同时查找到了英⽂对应的中⽂。
- 场景2:商场⽆⼈值守⻋库,⼊⼝进场时扫描⻋牌,记录⻋牌和⼊场时间,出⼝离场时,扫描⻋牌,查找⼊场时间,⽤当前时间-⼊场时间计算出停⻋时⻓,计算出停⻋费⽤,缴费后抬杆,⻋辆离场。
- 场景3:统计⼀篇⽂章中单词出现的次数,读取⼀个单词,查找单词是否存在,不存在这个说明第⼀次出现,(单词,1),单词存在,则++单词对应的次数。
3.3 key/value⼆叉搜索树代码实现
我们用命名空间与key的代码隔开。
namespace key_value
{
template<class K, class v>
struct BSTNode //节点
{
K _key;
v _v;//节点值
BSTNode<K, v>* _left; //左孩子
BSTNode<K, v>* _right;//右孩子
BSTNode(const K& key, const v& v)//构造函数
:_key(key)
,_v(v)
, _left(nullptr)
, _right(nullptr)
{
}
};
template<class K, class v>
class BSTree //二叉搜索树
{
using Node = BSTNode<K, v>;
public:
bool Insert(const K& key, const v& v) //插入数据
{
if (_root == nullptr)
_root = new Node(key, v);
Node* cur = _root;
Node* parent = NULL;
while (cur) //不支持相同数据插入
{
if (cur->_key > key) //插入值小于根节点,左走
{
parent = cur; //先记录当前根节点
cur = cur->_left; //移动cur
}
else if (cur->_key < key)//插入值大于根节点,右走
{
parent = cur; //先记录当前根节点
cur = cur->_right; //移动cur
}
else //插入值等于根节点,不给插入
return false;
}
cur = new Node(key, v);
if (parent->_key > key) //插入值小于自己的根节点,放左边
parent->_left = cur;
else
parent->_right = cur;
return true;
}
void Inorder() //中序遍历
{
_Inorder(_root);
cout << endl;
}
Node* Find(const K& key)
{
Node* cur = _root;
while (cur)
{
if (cur->_key < key)
{
cur = cur->_right;
}
else if (cur->_key > key)
{
cur = cur->_left;
}
else
{
return cur;
}
}
return nullptr;
}
bool Erase(const K& key) //删除数据
{
if (_root == nullptr) //空树,没什么删的
return false;
if (_root->_left == nullptr && _root->_right == nullptr)
{
delete(_root);
_root = nullptr;
}
else
{
Node* cur = _root;
Node* parent = cur;
while (cur) //先找到要删除的节点
{
if (cur->_key > key)
{
parent = cur;
cur = cur->_left;
}
else if (cur->_key < key)
{
parent = cur;
cur = cur->_right;
}
else //此时找到了要删除的值
break;
}
if (cur == nullptr) //删的数据 树里根本没有
return false;
if (cur->_left && cur->_right) //左右都不为空
{
Node* min = cur->_right; //和右子树最小值替换
while (min->_left)
{
parent = min;
min = min->_left;
}
cur->_key = min->_key;
cur = min;
}
//交换之后删除节点的逻辑和下面一致
//左右都为空的情况也符合下面的逻辑
if (cur->_left == nullptr) //左为空,右不为空
{
if (parent->_key > cur->_key)
parent->_left = cur->_right;
else
parent->_right = cur->_right;
delete(cur);
cur = nullptr;
}
else //右为空,左不为空
{
if (parent->_key > cur->_key)
parent->_left = cur->_left;
else
parent->_right = cur->_left;
delete(cur);
cur = nullptr;
}
}
return true;
}
private:
void _Inorder(const Node* root) //中序遍历
{
if (root == nullptr)
return;
_Inorder(root->_left);
cout << root->_key << ":" << root->_v << endl;
_Inorder(root->_right);
}
Node* _root = nullptr;
};
}测试几个样例。模拟单词查找的情景。
int main()
{
key_value::BSTree<string, string> dict;
//BSTree<string, string> copy = dict;
dict.Insert("left", "左边");
dict.Insert("right", "右边");
dict.Insert("insert", "插⼊");
dict.Insert("string", "字符串");
string str;
while (cin >> str)
{
auto ret = dict.Find(str);
if (ret)
{
cout << "->" << ret->_v << endl;
}
else
{
cout << "无此单词,请重新输入" << endl;
}
}
return 0;
}
计数的场景。
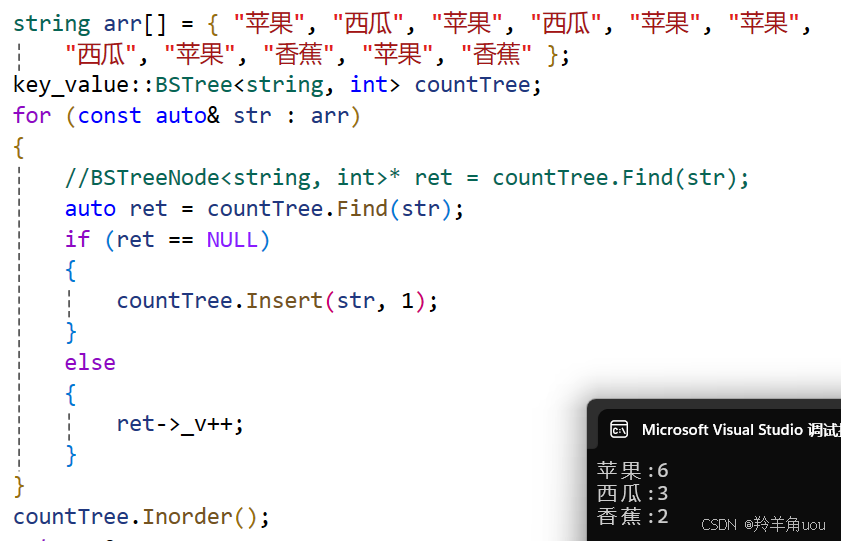
int main()
{
string arr[] = { "苹果", "西瓜", "苹果", "西瓜", "苹果", "苹果",
"西瓜", "苹果", "香蕉", "苹果", "香蕉" };
key_value::BSTree<string, int> countTree;
for (const auto& str : arr)
{
// 先查找⽔果在不在搜索树中
// 1、不在,说明⽔果第⼀次出现,则插⼊<⽔果, 1>
// 2、在,则查找到的结点中⽔果对应的次数++
//BSTreeNode<string, int>* ret = countTree.Find(str);
auto ret = countTree.Find(str);
if (ret == NULL)
{
countTree.Insert(str, 1);
}
else
{
ret->_v++;
}
}
countTree.Inorder();
return 0;
}
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-02-11,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号