Adaptive and Robust Query Execution for Lakehouses at Scale(翻译)

Adaptive and Robust Query Execution for Lakehouses at Scale(翻译)

jhonye
发布于 2025-01-17 17:07:25
发布于 2025-01-17 17:07:25
ABSTRACT
许多组织已经接受了“湖仓”数据管理范式,这种范式涉及在开放的、非结构化的数据湖之上构建结构化的数据仓库。这种方法与传统的、封闭的、关系型数据库形成鲜明对比,并为分布式查询处理器的性能和稳定性带来了挑战。首先,在大规模的、开放的湖仓中,处理未策划的数据、高摄入率、外部表或者深度嵌套的模式时,维护完美且最新的表和列统计数据往往是昂贵或浪费的。其次,由于连接词谓词、连接和用户定义函数等固有的基数估计不完美,可能会导致糟糕的查询计划。第三,对于涉及的数据量之大,严格依赖于静态查询计划决策可能导致性能和稳定性问题,例如过量的数据移动、显著的磁盘溢出或高内存压力。为了应对这些挑战,本文介绍了我们对自适应查询执行(AQE)框架的设计、实现、评估和实践,该框架利用查询计划中的自然执行管道中断来收集准确的统计数据,并在运行时重新优化以提升性能和健壮性。在TPC-DS基准测试中,该技术展示了高达25倍的单查询加速。在Databricks,AQE已经在生产环境中成功部署多年。它支持通过关键企业产品如Databricks Runtime、Databricks SQL和Delta Live Tables,每天处理数亿查询和ETL作业,处理数以艾字节计的数据。
INTRODUCTION
现代企业将其大量的原始、结构化、半结构化和非结构化数据存储在可扩展和弹性的数据湖中,如Amazon S3、Azure Data Lake Storage和Google Cloud Storage。这些数据湖存储了通常未经策划的原始数据集,采用如Apache Parquet等开放文件格式。这些数据可以使用多种引擎处理,包括Apache Spark和Presto。然而,数据湖在数据质量、事务特性、治理以及支持复杂分析的能力方面面临挑战。相比之下,数据仓库是一个为查询和分析优化的结构化存储系统。它通常存储结构化和已处理的数据,使其适合业务智能(BI)和报告。数据仓库设计用于高性能查询,但可能难以高效处理大量的原始或非结构化数据。
数据湖仓(Data Lakehouse)的概念应运而生,结合了数据湖和数据仓库的优势,包括数据湖的开放存储格式和对原始数据的支持,以及数据仓库的事务支持和数据治理。Databricks支持主要的开源工业湖仓存储实现,包括Linux Foundation Delta Lake、Apache Iceberg和Delta UniForm。在湖仓中,分布式查询引擎需要支持一系列分析工作负载,包括BI、数据探索、高级分析和ETL(提取、转换、加载)作业。在这种环境下,统计数据往往不可用,或者不如闭合系统(如数据仓库)中的统计数据准确或最新。这需要一种更动态的查询优化和执行方法,如本文提出的解决方案。但首先,我们需要讨论查询优化器在湖仓中面临的挑战。
支持未经策划的原始数据(缺少统计数据)。当组织将数据从数据湖迁移到数据仓库时,数据通常首先通过ETL作业进行清理。这一步骤标准化列值,平展半结构化数据如JSON,舍弃错误值等。结果是适用于快速BI处理的结构化数据集。相反,原始数据往往未经策划,包含很少或没有统计数据。因此,在湖仓查询引擎中,数据属性需要在执行过程中发现,以获得通常由预处理带来的性能优势。
支持外部表(缺少统计数据)。在湖仓范式中,组织可以灵活地使用他们在云端的存储空间来存储表数据,并使用自己的目录或第三方目录服务来管理表元数据。这样,他们可以使用不同的查询引擎来处理不同的工作负载,同时访问相同的数据。然而,在这种情况下,没有直接的方法来确保表元数据中存在统计数据。
支持深度嵌套数据(缺少统计数据)。嵌套的、非规范化的模式在原始和策划的数据集中变得越来越流行,因为它们通过减少复杂的连接来增强可读性。数组、映射和结构等数据类型及其任意递归组合被组织广泛使用。这种深度嵌套的字段通常在解嵌操作后被访问,并可在过滤、连接和聚合等操作中引用。收集数十到数千个数组、结构和映射中深度嵌套字段的统计数据,并在目录中表示这些统计数据,通常是昂贵且不切实际的。
支持快速变化的数据和工作负载(统计数据过期和波动历史)。在许多组织中,来自其产品的数据以惊人的速度被摄入到湖仓中。因此,维护像单个表列直方图这样的最新统计数据是资源消耗的。此外,工作负载可能不时地激增或下降,没有明显的重复模式。因此,从历史查询中学习统计数据并不总是可行的。
支持用户定义函数(UDF)(缺乏基数估计信息)。用户定义函数(包括标量函数、聚合函数和表值函数)在我们的平台上广泛采用,凸显了它们在客户工作负载中的重要性。然而,UDF对查询优化器来说是黑盒子,难以进行准确的基数估计和成本建模。
支持多样化的工作负载(放大糟糕的计划)。在湖仓中,表的大小从兆字节到拍字节不等。因此,优化器的估算错误可能导致错过关键优化,使查询超时,例如在处理大量数据时;低估则可能导致过度激进的查询计划,造成不必要的高内存压力或磁盘溢出。
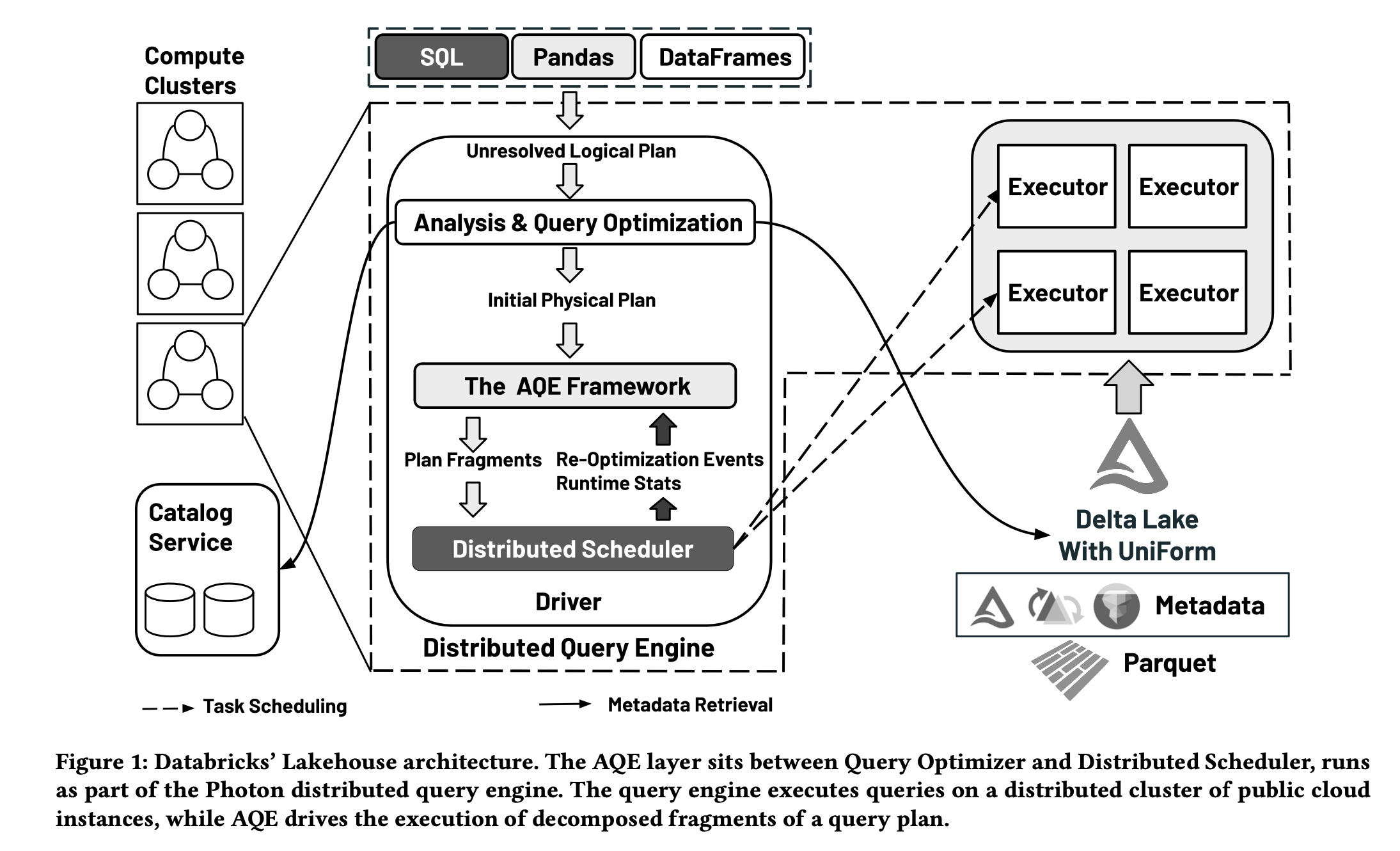
图1
为了应对这些挑战,我们构建了一个自适应查询执行(AQE)框架。其核心思想是在查询执行期间从完成和正在进行的查询计划片段的任务指标中收集统计数据,然后基于这些运行时统计数据重新优化未完成的执行计划片段。AQE层,如图1所示,位于静态查询优化器和分布式调度器之间。它包含了计划表示(4.1节)、事件驱动架构(4.2节)、取消原语(4.3节),以及在分布式查询处理中利用的性能和健壮性机会(5和6节)。结果是,AQE在标准TPC基准查询中实现了高达25倍的单个查询加速,以及每基准高达1.7倍的总体加速(见第7节),这是建立在我们的矢量化Photon执行引擎之上的。今天,AQE已在所有Databricks生产环境中默认启用,每天支持数十亿多样化的湖仓查询和ETL作业,延迟从数十毫秒到几小时不等。虽然动态查询优化的概念在早期的研究原型中已被探索,但我们认为本文描述的是规模最大的成功工业部署之一。
在本文的其余部分,我们将在第2节描述湖仓和Photon的背景,并在第3节详细说明我们对AQE的动机;第4节介绍AQE框架;第5节解释几个重要的性能优化;第6节阐述AQE如何使查询执行更加健壮;然后在第7节中提供定量性能评估以及我们在AQE方面的操作实践;最后,在第8节讨论相关工作,并在第9节总结本文。
BACKGROUND
本节简要介绍了AQE所适用的背景,包括对湖仓和Photon查询引擎的概述。
2.1 数据湖仓
通过结合数据湖和数据仓库的优势,数据湖仓[7]旨在为现代数据驱动的环境中管理和分析多样数据集提供一个更加灵活、可扩展且成本效益高的解决方案。这一概念因组织希望通过一个简单平台充分发挥其数据资产的全部潜力而日益流行。因此,大多数Databricks客户已经在使用Delta或Delta UniForm来管理他们的数据。数据湖仓的主要优势包括:
- 统一的开放存储。湖仓通常使用统一的存储系统,该系统采用开放的数据格式,可以同时容纳原始、未处理的数据(类似数据湖)和结构化、已处理的数据(类似数据仓库)。在工业湖仓中,采用了开源的Parquet格式来存储数据和元数据。这样,组织可以使用任何计算引擎来查询或在现有数据上运行机器学习模型,而无需将数据加载到仓库中。
- 自动数据管理。与数据仓库类似,湖仓通常在云对象存储上提供ACID表存储层。在我们的案例中,Delta Lake和Delta UniForm都支持类似仓库的功能,如ACID事务、时间旅行、审计日志以及对表数据集快速的元数据操作。
- 数据治理。与临时数据湖不同,湖仓通过目录服务纳入了数据治理和元数据管理,以确保数据的质量、安全性和合规性。目录服务可以由核心存储和计算之外的任何第三方运行。
- 弹性且高效的查询处理。在拥有多样工作负载的湖仓中,可以根据需要创建分布式查询引擎实例(即计算集群)来执行这些工作负载,从而节省成本。本文描述的自适应和健壮的查询执行适用于湖仓堆栈中的这一层。
图1提供了查询引擎、目录服务和湖仓存储的高层次视图。
2.2 Databricks Photon查询引擎
Photon[11]最初是一个向量化、单线程查询执行库,现已发展成为一个全功能的新一代分布式查询引擎,支持Databricks的主要产品,包括Databricks Runtime、Databricks SQL和Delta Live Tables。如图1所示,Photon查询引擎的输入包括从SQL文本、Python/Scala DataFrame程序或Pandas程序生成的未解析逻辑计划。分析器从目录服务中检索表元数据,执行语义分析,并将未解析的逻辑计划转换为已解析的逻辑计划。接下来,静态优化器重写已解析的逻辑计划为优化后的逻辑计划,并将其转换为初始物理计划。调度器分配执行任务,这些任务是物理计划片段的并行实例,在执行器上运行。在每个任务中,调用矢量化执行操作符和表达式评估器来处理数据。与大多数其他查询引擎不同,Photon引擎包含了位于静态优化器和调度器之间的AQE(自适应查询执行)框架。AQE在从优化器接收到初始物理计划后,将计划分成片段,协调它们之间的依赖关系,监控它们的进展,并根据执行任务的运行时指标持续调整未完成的计划片段。
PROBLEMS AND ALTERNATIVES
在本节中,我们将讨论分布式湖仓查询引擎中的关键查询计划决策(3.1节),一个带有AQE的运行示例(3.2节),以及与其他方法的详细比较(3.3节)。
3.1 关键查询计划决策
在分布式查询引擎中,查询优化器通常会做出以下决策,这些决策对于单个查询的性能以及引擎的稳定性至关重要:
- 物理操作符选择。广播连接(Broadcast Join)和混洗连接(Shuffled Join)是两种典型的分布式连接算法,它们具有非常不同的性能特征。一个错误的选择可能会导致严重的性能问题甚至稳定性问题,例如,不必要地混洗大量数据或错误地将大量数据广播到所有执行器。
- 并行度。确定最佳的并行度,包括扫描和混洗的并行度,在分布式查询处理中仍然是一个挑战。不当的并行度选择可能会导致严重问题;例如,过高的并行度可以使任务调度器过载和限制。
- 基于数据量进行的权衡。在我们的Photon引擎中,我们开发了几种半连接减少过滤器变体,如动态分区/文件修剪过滤器[23]和布隆过滤器[14],不仅可以加速单个连接,还可以弥补不完美的连接顺序。然而,由于过滤器创建的成本,这些过滤器的选择通常是一个依赖于数据的决策。
- 基于动态数据属性的优化。一系列查询优化取决于数据属性,如空中间关系、单行关系、分区属性和有用顺序。通常,这些数据属性只有在查询执行过程中才能被发现。
- 优雅降级策略。由于预料之外的数据情况,如数据倾斜或中间数据膨胀,可能会导致查询超时(例如,数小时或数天)或在执行器中造成内存压力。因此,优化器可能需要在性能和稳定性之间找到平衡。
3.2 示例查询
在本文的其余部分,我们将使用TPC-H模式中的示例SQL查询(见Listing 1,Q0)作为运行示例来详细阐述问题、概念、思路和优化。对于Q0,AQE试图解决的关键问题包括:

- 符合两个WHERE谓词的客户表中的行数是多少,以及相应的字节大小是多少?(4.1节)
- 我们应该应用哪种半连接减少过滤器变体,即动态文件修剪过滤器还是布隆过滤器?(5.1节)
- 如何利用在执行时发现的动态数据属性来进行进一步的查询优化?(5.2节)
- 应该使用哪种连接算法?(5.3节)
- 运行查询应采用什么样的并行度?(5.4节)
- 如何减轻如数据倾斜和内存压力等问题,对于未预料到的极端数据?(6节)
3.3 AQE的替代方案
静态查询优化器依赖存储的目录统计信息(如通过Analyze Table命令获得的)、基数估计和成本模型(即基数和计划的函数)来做出上述计划决策。增强统计信息、基数估计和成本建模的准确性是自适应查询执行的一个可行替代方案。然而,尽管数据库社区已经努力了几十年,但在传统数据库系统中,基数估计仍然是一个挑战[32]。
- 基数估计。列级统计信息如不同值的数量和直方图可以为直接作用于表列的局部二元比较谓词提供好的估计,但对于结合谓词、带有UDF的谓词和连接谓词,估计误差可能会出现。此外,在复杂查询计划中,这种误差可能会随着多个此类谓词的增加而放大。System R中的一个“著名”基数估计启发式方法[38]是,任何针对未索引表列的等值过滤谓词默认将输入基数减少到1/10。现代优化器在缺乏信息时仍然采用类似的启发式方法。例如,Catalyst开源优化器[8]在没有可用信息时使用最坏情况的基数作为估计。
- 物理计划成本模型。传统的Cascades风格的规划器[25]通常需要一个数字化的物理计划成本来进行搜索空间优先级排序、替代计划比较、分支定界和剪枝。如文献中所述[32],成本模型的误差往往比基数估计的小。然而,即使是“完美”的成本模型也需要与查询执行和硬件特性的演变保持同步。
接下来,我们深入探讨了几种旨在改进湖仓中第1节提到的挑战的静态优化器基数估计的替代方法:
- 采样。大量研究文献[1,17,18]尝试通过采样来改进基数估计,包括随机样本、在线样本、块样本、物化样本和分层样本。在实践中,它们可能在特定场景下有效,例如,对于均匀分布数据的随机样本和针对分层列谓词的分层样本[1]。然而,样本收集的成本和其有效性之间存在固有的权衡。
- 基于历史的基数估计,如LEO原型[40]可能适用于在相对封闭环境中的重复查询工作负载,其中计算和历史存储在单个集群实例中捆绑在一起。然而,湖仓架构在更大规模和更高弹性下运行,这要求计算、存储和目录的分离。因此,在控制平面构建一个单独的历史存储服务可能带来非平凡的工程挑战,如二进制兼容性和RPC延迟。
- 机器学习可能是一个有前景的方向来提高估计的准确性。然而,要在生产中部署它,仍需要大量的工程工作来调整模型,加上调试和解释性的挑战。
值得注意的是,本文描述的自适应查询执行需要在查询的分布式执行过程中存在同步的管道中断器,以便重新优化能够启动并有效执行。一些查询引擎在实现DAG调度器、任务调度器、混洗、连接、聚合和排序的方式中具有这些中断器;其他可能由于设计原因而缺乏这些。Photon引擎的混洗实现就有这样的中断器,最初是为了任务调度和容错的简单性。因此,AQE是天然适配的。从高层次来看,AQE及其替代方案的改进在其演化中是互补的。更好静态查询计划最终可能会放宽对查询执行子系统的限制,而AQE提供了实验其替代方案的最终保障。基于几年前的这些观察,我们优先并执行了自适应查询处理策略。
THE AQE FRAMEWORK
在本节中,我们通过介绍计划片段的表示(4.1节)、重新优化的事件循环(4.2节)以及计划片段的取消和幂等性(4.3节)来介绍AQE框架。
4.1 计划表示
在计划运行时动态调整执行计划片段可能会给执行引擎带来显著的复杂性。为了保持系统的简单性,AQE在逻辑计划和物理计划中集成了特殊的操作符来表示计划片段。这些操作符通过逻辑/物理重写规则或规划器规则启用即时计划修改。类似于我们的静态优化器以及其他几个优化器[8, 37],AQE中的计划是不可变的,重写规则返回新的计划实例。计划表示中的关键概念如下概述:
- QueryStage:QueryStage操作符表示提交给分布式调度器的计划片段。相应的逻辑和物理计划片段被包装在QueryStage中,它作为一个叶节点操作符,类似于表扫描。这确保了封闭的计划片段不会被任何后续的计划重写意外修改,这些重写只打算重新优化查询计划的剩余部分。在当前系统中,QueryStage在混洗边界处被分割。
- LogicalLink:LogicalLink作为从物理操作符到其相应逻辑操作符的反向映射指针。这些链接由物理规划器在初始规划时以及每次AQE重新规划时为每个物理操作符填充。这个映射允许AQE框架将当前的逻辑计划与当前的物理计划同步,以便使用从运行时任务指标推断的最新统计信息对逻辑计划进行重新优化。
- RuntimeStatistics:每个QueryStage可以从运行中的任务指标估计统计数据,或者从已完成任务的指标收集统计数据。这些运行时统计数据,例如字节大小和行数,提供了比传统静态基数估计更准确的洞察。通过LogicalLinks,这些统计数据也可以被输入到逻辑计划中。
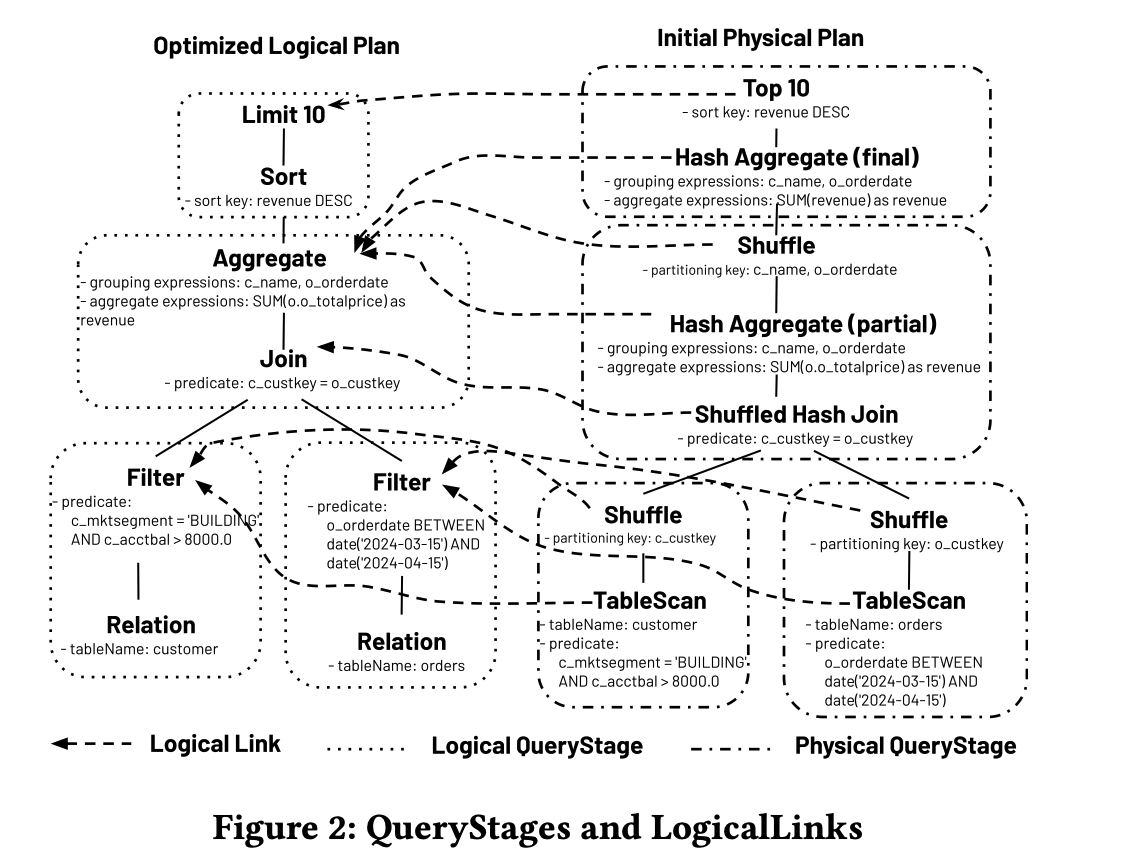
图2
图2 可视化了Q0(Listing 1)初始物理计划中的QueryStage和LogicalLink。运行时统计数据在物理QueryStage中获得,并通过LogicalLinks回填到逻辑计划中。
4.2 AQE重新优化事件循环
1 // Kick off initial QueryStages.
2 LogicalPlan currentPlan = initialPhysicalPlan.logicalLink;
3 List<QueryStage> initialRunnableStages = breakDown(initialPhysicalPlan);
4 initialRunnableStages.foreach(stage => Scheduler.submit(stage));
5 runningStages.addAll(initialRunnableStages);
6 do {
7 // Blocking wait until new re-optimization event
8 // being added into `reOptEventQueue` by producer
9 // threads.
10 Event reOptEvent = reOptEventQueue.take();
11 // Update `runningStages` and `currentPlan`.
12 currentPlan = update(reOptEvent, runningStages,currentPlan);
13 // Call logical rewrite rules to optimize `currentPlan`.
14 LogicalPlan reOptPlan = reOptimize(currentPlan);
15 // Convert `reOptPlan` to a physical plan.
16 PhyiscalPlan currentPhysicalPlan = plan(reOptPlan);
17 // Break down `currentPhysicalPlan` into runnable
18 // QueryStages.
19 List<QueryStage> runnableStages = breakDown(currentPhysicalPlan);
20 // Cancel running QueryStages that are no longer needed.
21 runningStages.diff(runnableStages).foreach(stage => Scheduler.cancel(stage))
22 // Submit new runnable QueryStages to the scheduler.
23 List<QueryStage> runnableNewStages = runnableStages.diff( runningStages)
24 newStagesToRun.foreach(stage => Scheduler.submit(stage));
25 runningStages.addAll(newStagesToRun);
26 } while (hasUncompletedStages());
Listing 2如Listing 2中的代码片段所述,对于给定的查询,AQE的核心是一个while循环,其中循环体监听重新优化事件,重新优化未完成的逻辑计划,为重新优化的逻辑计划重新生成物理计划,将物理计划分解为QueryStage,并将新的可运行QueryStage提交给调度器。请注意,Listing 2 中的第16行调用了相同的静态物理规划器,其中规划器规则(为逻辑操作符选择物理操作符)和物理重写规则(将物理计划重写为更好的计划)都可以被调用。Listing 2中第14行和第16行应用的几条规则根据从运行时统计数据推导出的成本做出决策。典型的重新优化事件包括:
- QueryStage完成:当一个QueryStage成功完成时,它的依赖QueryStage可能能够启动,并且完成的QueryStage的准确运行时统计数据在剩余的逻辑计划中可用,供AQE做出新的优化决策。
- QueryStage失败:当一个QueryStage失败(或超时)时,需要采取措施,要么完全失败查询,要么通过调整查询计划尝试从失败中恢复。
- 基于任务指标的启发式:除了从已完成或失败的QueryStage获得的指标外,来自正在进行的QueryStage的指标对AQE也非常有价值。AQE包括一个指标评估框架,该框架监控运行QueryStage报告的指标,并决定是否或何时需要重新优化。一旦这样的指标变化被认为对优化有利,将向reOptEventQueue提供一个新的重新优化事件。
事件循环的关键在于使用从完成的QueryStage观察到的实际统计数据或从正在运行的QueryStage指标估计的统计数据。这些统计数据是改进未完成查询计划片段关键决策的基础。
让我们用Q0(Listing 1)来详细说明QueryStage完成事件。对于图2中描述的计划,在Listing 2中,第3-4行首先将两个底部的物理QueryStage提交给调度器;当其中一个完成时,重新优化事件在第10行被处理,currentLogicalPlan在第12行用准确的运行时统计数据更新,并在第14行重新优化;最后,新的可运行QueryStage被提交给调度器,循环继续等待新的重新优化事件。
4.3 QueryStage取消和幂等性
在AQE事件循环中(Listing 2),第21行取消不再需要的正在运行的QueryStage。这种情况可能发生在相应的逻辑计划完全被优化掉,或者当一个运行中的QueryStage在重写计划中有一个语义上等效的替代品被认为优越时。这种方法将取消实现从第13到16行调用的逻辑和物理重新优化中抽象出来,简化了重写逻辑。例如,第5节和第6节中概述的所有逻辑重写和规划器规则都利用这种机制来停止正在进行的大型扫描、混洗或磁盘溢出。对于幂等性,完成的QueryStage不会被重新运行,因为它在第13到16行的新逻辑和物理计划中成为了一个叶节点,而第23行确保相同的运行中QueryStage不会被重复提交。
PERFORMANCE OPTIMIZATIONS
在本节中,我们将讨论在AQE中应用的几个重要的性能优化,包括:
- 通过逻辑重写注入半连接减少过滤器变体,如动态分区/文件修剪过滤器(DPPs, DFPs)[23]和布隆过滤器[14](5.1节),以及优化掉不再需要的计划片段(5.2节);
- 一个规划器规则,重新评估并更改静态规划决定,用于选择逻辑Join操作符的连接算法(5.3节);
- 一个动态调整混洗并行度的物理重写(5.4节)。
5.1 逻辑重写:动态连接过滤器
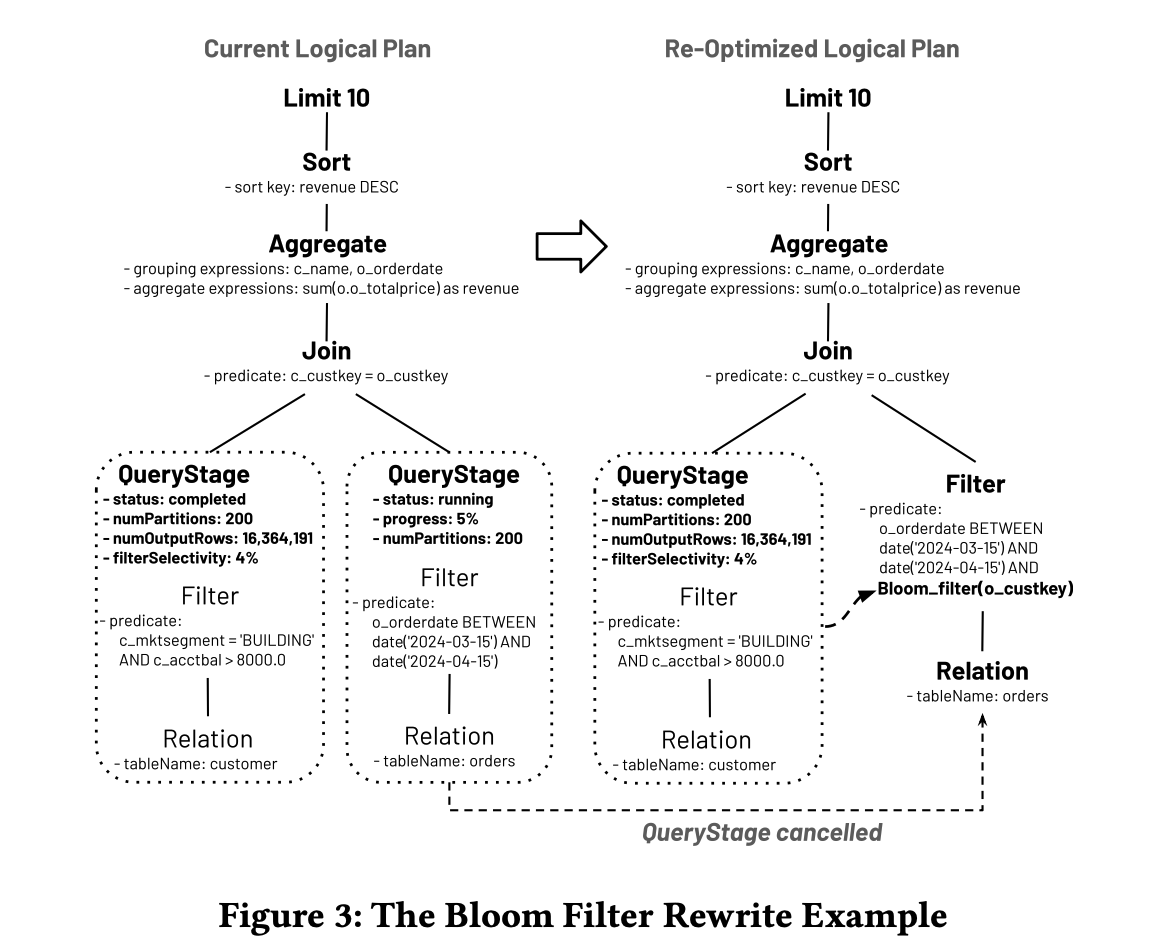
图3
我们已经实现了一个逻辑重写规则来注入动态的半连接减少过滤器变体,包括DPPs、DFPs和布隆过滤器。这个规则已被添加到reOptimize定义中的规则批次中,在Listing 2的第14行被调用。众所周知,这些过滤器不是免费的——创建、聚合、分发和应用它们都涉及到开销。因此,要放置一个过滤器,其减少的磁盘I/O或CPU使用必须超过其创建开销。有了AQE中的运行时统计数据,收益与开销的分析变得更加准确,导致决策比静态优化器更好。让我们以Q0(Listing 1)为例来阐述这个重写规则。在图3中,假设来自客户表的QueryStage在执行过程中首先完成,c_mktsegment = 'BUILDING' AND c_acctbal > 8000.0的实际选择率为4%,过滤器的实际输出行数为16,364,191。同时,来自订单表的QueryStage已完成5%。利用运行时统计数据,重写规则认识到(a)布隆过滤器只需几十兆字节就可达到1%的误报率,并且(b)在订单一侧应用布隆过滤器可以在混洗之前提早丢弃许多行。然后,通过与Join另一侧的预估统计数据比较,该规则决定取消来自订单的QueryStage并注入布隆过滤器是相对便宜但可能值得的。因此,在重写后的计划中,它从已完成的QueryStage构建一个布隆过滤器,并将其应用于订单表的扫描。实际的取消操作在Listing 2的第21行执行,生成另一个来自订单的不同QueryStage之后。
5.2 逻辑重写:动态数据属性
从已完成的QueryStage收集的运行时统计数据在推导实际数据属性方面非常准确,包括空关系和单行关系的场景。因此,我们实现了一个重写规则,以在剩余的逻辑计划中自底向上传播空关系。例如,在内连接的一侧没有行的场景中,规则智能地消除进一步执行连接的需要,并用空关系替代,从而优化查询性能。相同的转换在后序计划遍历中应用,确保所有不必要的操作符都能被优化掉。
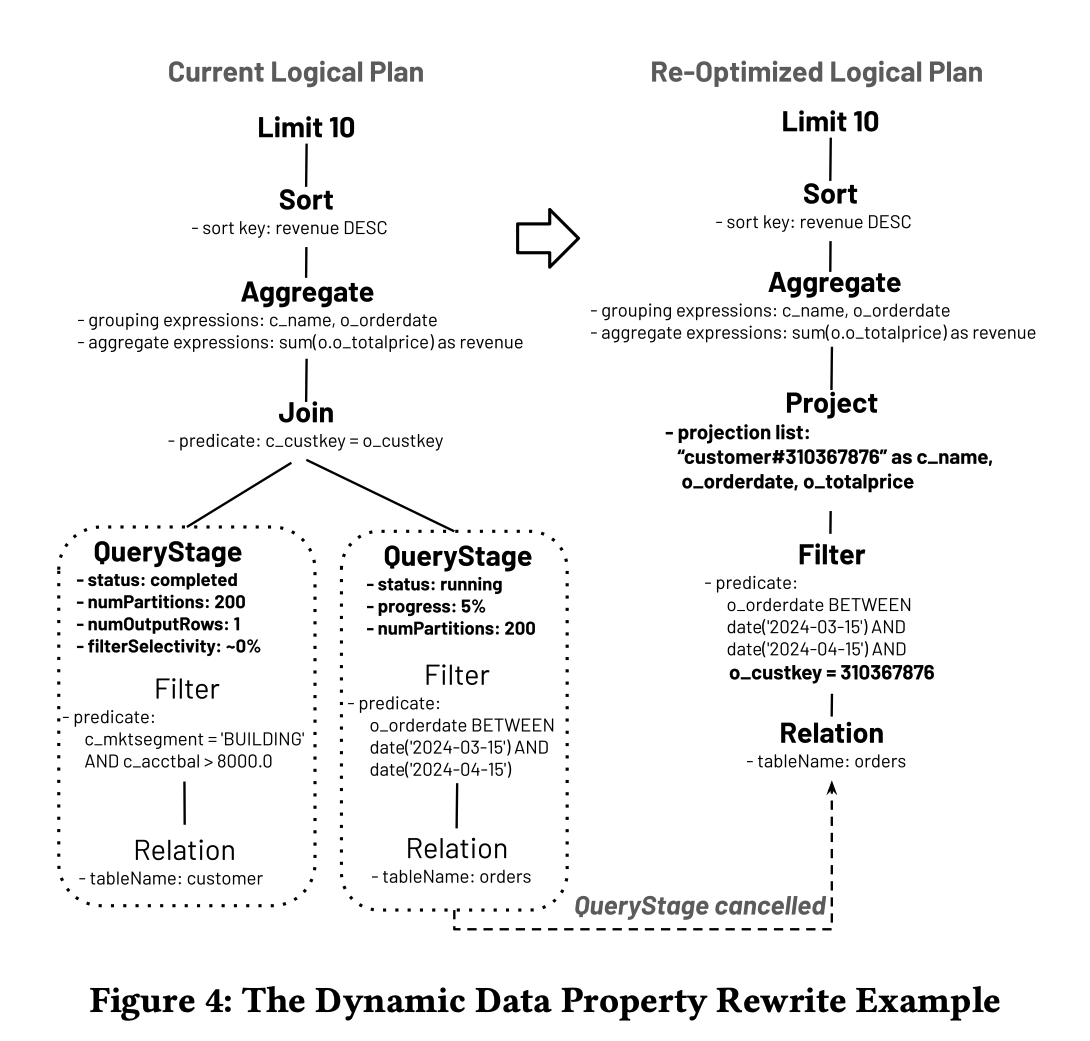
图4
同样,我们有另一个规则,适用于已完成的QueryStage只包含一行的场景。例如,如果底层中间数据只有一行,则可以从计划中省略不必要的操作,如连接、聚合和排序。图4 以Q0(Listing 1)为例进行说明。假设来自客户表的QueryStage只有一个输出行。这个规则将连接条件与常量合并,消除连接操作符,取消来自订单的运行中QueryStage,并向下推送额外的谓词o_custkey = 310367876。推送到表扫描的额外谓词可用于修剪文件以加速查询。
5.3 规划器规则:连接算法重新选择
在Photon查询引擎中,有两种主要的分布式连接算法:广播哈希连接和混洗哈希连接。
- 广播哈希连接。当连接的一侧足够小以至于可以放入单个执行器的内存时,由于其性能优势,通常更倾向于使用广播哈希连接。在这种方法中,较小的一侧(称为构建侧)被广播到所有参与的执行器节点,消除了对另一侧(探测侧)重新分区的需求。需要注意的是,同一个执行器节点上的不同连接线程共享同一构建侧的哈希表和数据,驻留在内存中。
- 混洗哈希连接。与广播哈希连接相反,在混洗连接中,双方在连接前都经历了混洗。在单个执行器上,本地连接算法是Hybrid Hash Join的矢量化实现[11, 39],如果必要,可以优雅地溢出到磁盘。
关于选择哪种连接算法的静态决策是基于估计的,这些估计有时可能导致次优结果。在执行过程中,可能会出现一种情况,起初计划为混洗哈希连接的连接,由于估计表明双方都太大,但实际执行时可能发现一侧足够小以进行广播。在这种情况下,AQE介入以动态改变执行计划,将其转换为广播哈希连接。这种调整避免了大型一侧的昂贵混洗,从而显著提升性能。
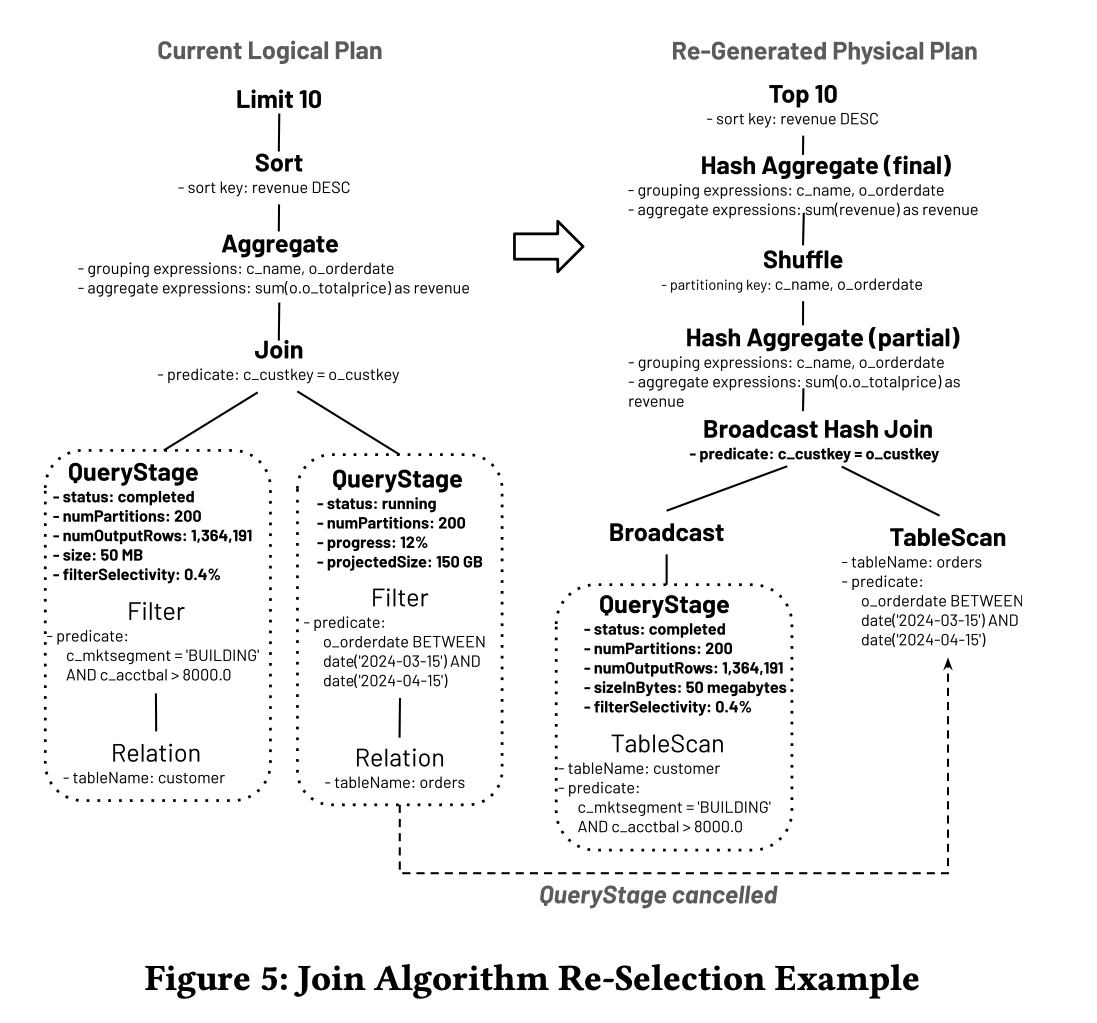
图5
以Q0(Listing 1)为例,假设由于对客户表上谓词的静态选择率高估,初始物理计划采用了混洗哈希连接(如图2所示),而来自该表的QueryStage在执行过程中首先完成,过滤器的实际输出行数为1,364,191,输出大小为50兆字节。此时,当前逻辑计划在图5的左侧展示。由于更新的运行时统计数据和运行中QueryStage的进展,物理规划器中的连接算法选择规则重新选择使用广播哈希连接,如图5 的右侧所示。因此,来自订单的新QueryStage没有混洗,导致根据Listing 2的第21行取消了相应的具有混洗的运行中QueryStage。
对称地,如果静态规划器由于低估而选择了广播哈希连接,可能会在执行过程中导致高内存压力以及高网络带宽消耗。在这种情况下,AQE重新规划可以将其切换为混洗哈希连接,通过避免将大型构建侧发送到所有执行器并加载到内存中,也能提升查询性能。
5.4 物理重写(弹性混洗并行度)
分布式查询引擎中,确定混洗分区的数量是一个重大挑战。一些系统从固定的混洗并行度开始,而其他系统则依赖于复杂的启发式方法。然而,确定最佳分区数量是数据依赖的,并且准确的数据大小,特别是中间阶段的数据大小,在静态查询优化期间通常不可得,这使之特别具有挑战性。这一决策对查询性能有关键影响:
- 并行度不足。在这种情况下,每个混洗消费任务处理大量数据,可能导致不必要的CPU缓存未命中或磁盘溢出(例如,对于连接、聚合和排序等操作符),从而减慢查询速度。
- 过度并行。相反,在这种情况下,可能会有大量小的网络数据获取,导致低效的网络I/O模式。除此之外,过度并行还会导致过多的调度开销,这也是性能下降的另一重要原因。
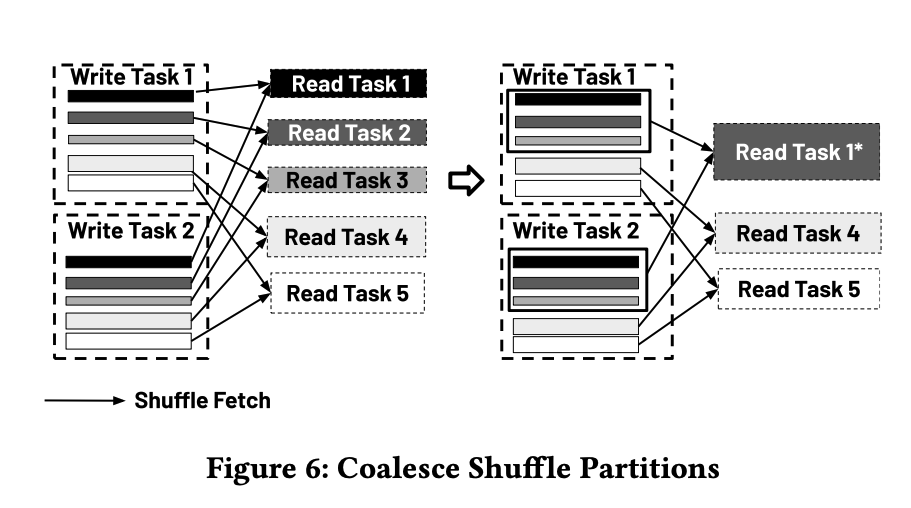
图6
为了解决这个问题,AQE根据ShuffleWrite操作符的输入数据大小计算出一个相对较大的混洗分区数量。然后,一旦ShuffleWrite完成,每个初始分区的实际大小变得可用,AQE基于这些信息能够通过物理重写规则将相邻的小混洗分区合并成更大的分区。该规则修改了ShuffleRead操作符中的分区规范。在我们的查询引擎中,混洗分区在分区编号上是物理连续的,允许“合并”操作在逻辑上进行,而无需额外读取或写入混洗数据。因此,混洗消费任务在“合并”分区上操作,减少了并发网络获取和任务调度开销,从而提高了整体性能。图6展示了一个例子,其中混洗消费任务从5个减少到3个,并发混洗获取从10个(5 × 2)减少到6个(3 × 2)。
ROBUSTNESS
除了性能改进之外,AQE还作为查询引擎健壮性的最后一道防线。虽然在生产环境中稳定性问题并不常见,但能够在不导致查询失败或系统崩溃的情况下实现优雅降级对于企业产品至关重要。本节介绍了三种适应性计划修复措施:广播哈希连接回退(6.1节)、混洗消除回退(6.2节)和数据倾斜处理(6.3节)。在这些情况下,关键步骤是尽早识别到问题的迹象,并将它们作为重新优化事件框架起来,允许AQE介入并缓解潜在问题。
6.1 逻辑重写
广播哈希连接回退 尽管基于实际数据大小的动态连接算法重新选择,但可能仍然会出现以下两种边缘情况,导致执行器在执行广播哈希连接时耗尽内存资源:

- Case 1:一个逻辑连接可以使用混洗哈希连接实现,但查询通过SQL提示试图强制使用广播哈希连接实现。当SQL查询是由工具生成的(通常是BI工具时),用户本身很难修复这些提示。
- Case 2:逻辑连接是一个Null-aware Anti Join[12],用于实现NOT IN子查询。这可以使用广播哈希连接实现,但不能用混洗哈希连接,因为后者并不总是按标准SQL语义产生正确的结果。此外,构建侧和探测侧不能交换。当NOT IN的右侧非空时,如Listing 3所述,有一个昂贵但健壮的计划,但引擎更希望乐观地使用通常更快的广播哈希连接实现。
在这两种情况下,AQE指标框架可以检测到广播哈希连接的构建侧太大,并在执行器实际耗尽内存之前主动触发一个重新优化事件。这个事件封装了即将发生的资源问题。随后,Listing 2的第12行相应地更新currentLogicalPlan,通过重写从易受攻击的广播哈希连接链接的逻辑连接操作符,转换为一个更健壮的计划。
- 对于Case 1,重写的逻辑计划删除连接提示,然后规划器将在Listing 2的第16行选择混洗哈希连接。
- 对于Case 2,同样地,根据Listing 3修改currentLogicalPlan,因为NOT IN的右侧已被确认非空。
当为重写后的计划生成新的QueryStage时,如第4.3节所述,包含易受攻击的广播哈希连接的现有QueryStage会被取消。这确保用户查询可以成功执行,而不是遇到失败。另一种方法是让广播哈希连接操作符进行磁盘溢出,然而,这仍然不是完全健壮的,因为它需要将整个连接构建侧广播到每个执行器,然后溢出到磁盘。例如,一个具有非常大NOT IN右侧的查询可以导致整个系统在查询之外的网络和磁盘稳定性问题。
6.2 规划器规则
混洗消除回退 类似于SCOPE[47]中的混洗消除优化,我们的静态优化器也进行基于成本的混洗消除。在大多数情况下,较少的混洗往往会使查询运行得更快。然而,当对分区列的不同值数量有高估时,这种优化的潜在风险是减少了有效任务并行度。并行度不足的一个症状是过度的磁盘溢出。在极端罕见的情况下,可能会耗尽磁盘配额。

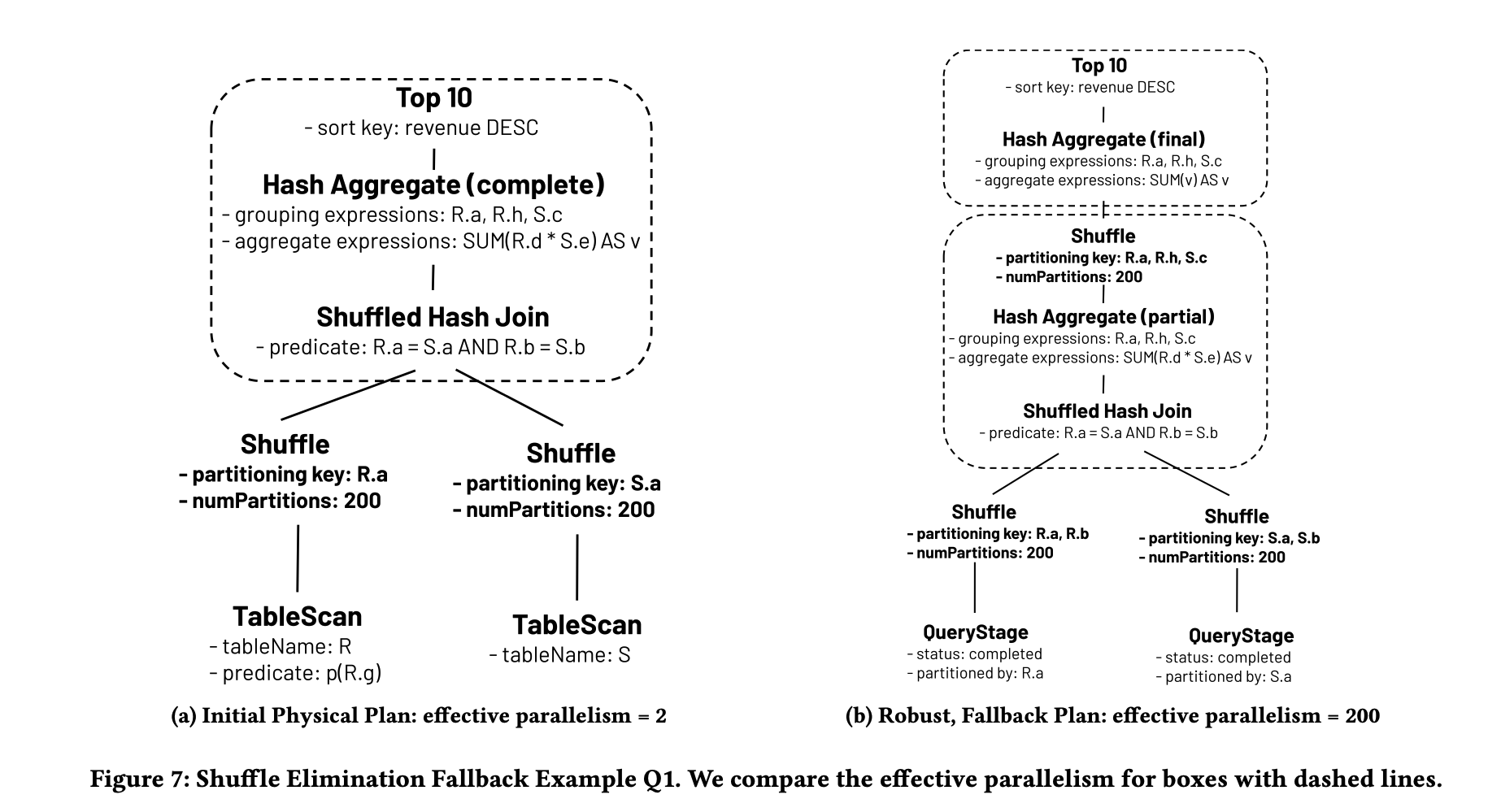
图7(a,b)
我们引用Listing 4中的Q1来说明这种情况。假设在过滤谓词p(R.g)之后,对于R.a的不同值数量有高估。如图7(a)所示,这个高估导致静态优化器选择按R.a和S.a进行分区以执行混洗哈希连接,有效地消除了后续按<R.a, R.h, S.c>进行的哈希聚合的混洗。然而,在执行时,发现R.a只有2个不同值,因此连接后的哈希聚合在所有执行器上只有两个有效的并行任务,无论有多少混洗分区。当按<R.a, R.h, S.c>分组的数量过大时,特别是如果连接谓词导致多对多连接,这可能导致过度溢出。在这种情况下,类似于第6.1节,度量框架在检测到并行度不足时触发一个AQE重新优化事件,使得AQE重新规划禁用混洗消除优化,并生成如图7(b)的回退计划。对于正常情况,回退计划运行速度比初始物理计划慢,因为它有更多的混洗,但通过将有效并行度从2增加到200来拯救Q1。
6.3 物理重写
处理倾斜连接 我们还实现了一个物理规则来处理倾斜的连接键。该规则能够在混洗哈希连接中发现一组连接键上的数据倾斜,这表现在少数分区包含的数据显著多于其他分区。在这种情况下,规则可以通过逻辑上将这些大型消费侧分区分割成更小、更平衡的分区来消除倾斜,优化任务大小以提高性能。这次重写的核心与文献[45]类似,只是它在运行时而不是静态规划时完成。
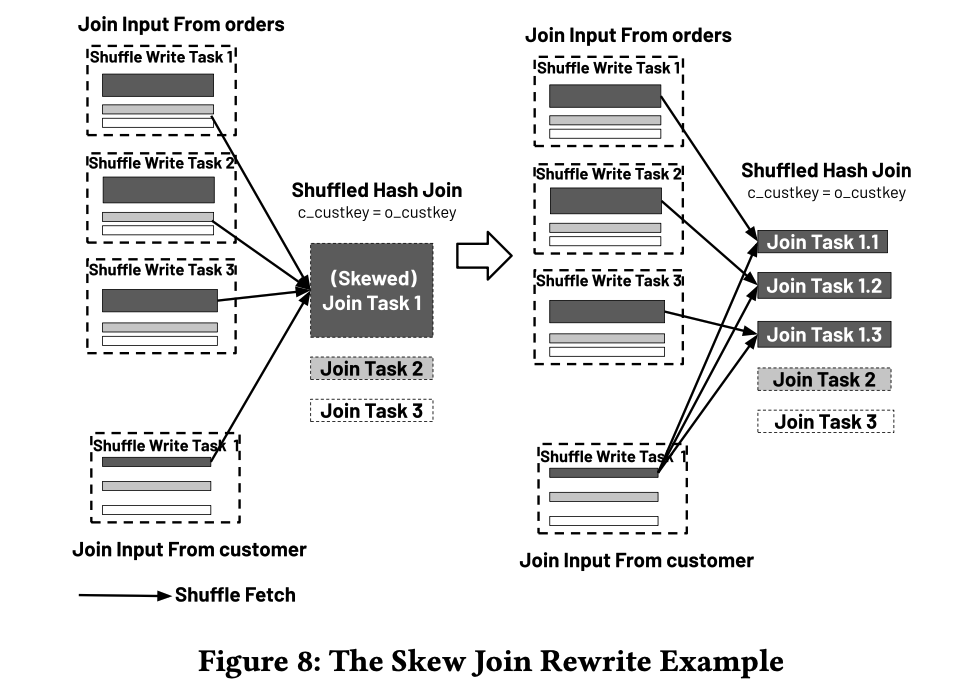
图8
让我们继续使用Q0(Listing 1)来解释这个规则。如图8所示,假设订单表在特定的o_custkey上倾斜,意味着一个客户下单量显著高于其他平均客户。规则通过重写两个ShuffleRead操作符的分区规范,将原本在一个任务中执行的所有包含这个倾斜o_custkey的数据(即图8中的Join Task 1)分拆成新的消费任务(Join Task 1.1到1.3),运行相同的每任务哈希连接实现,连接订单中倾斜分区的一个切片与复制的(三重方式)相应客户分区。
EVALUATIONS AND PRACTICES
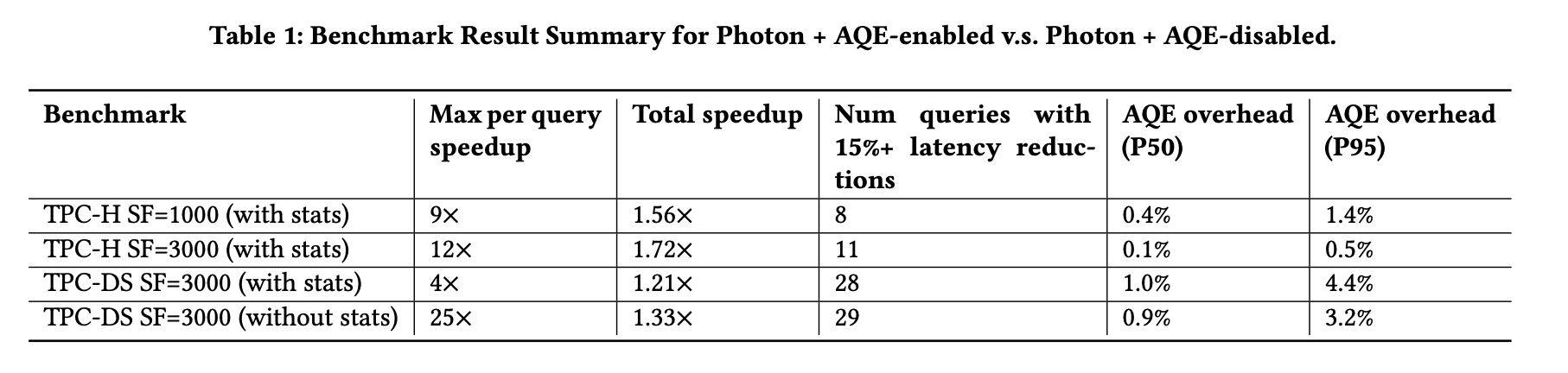
表1
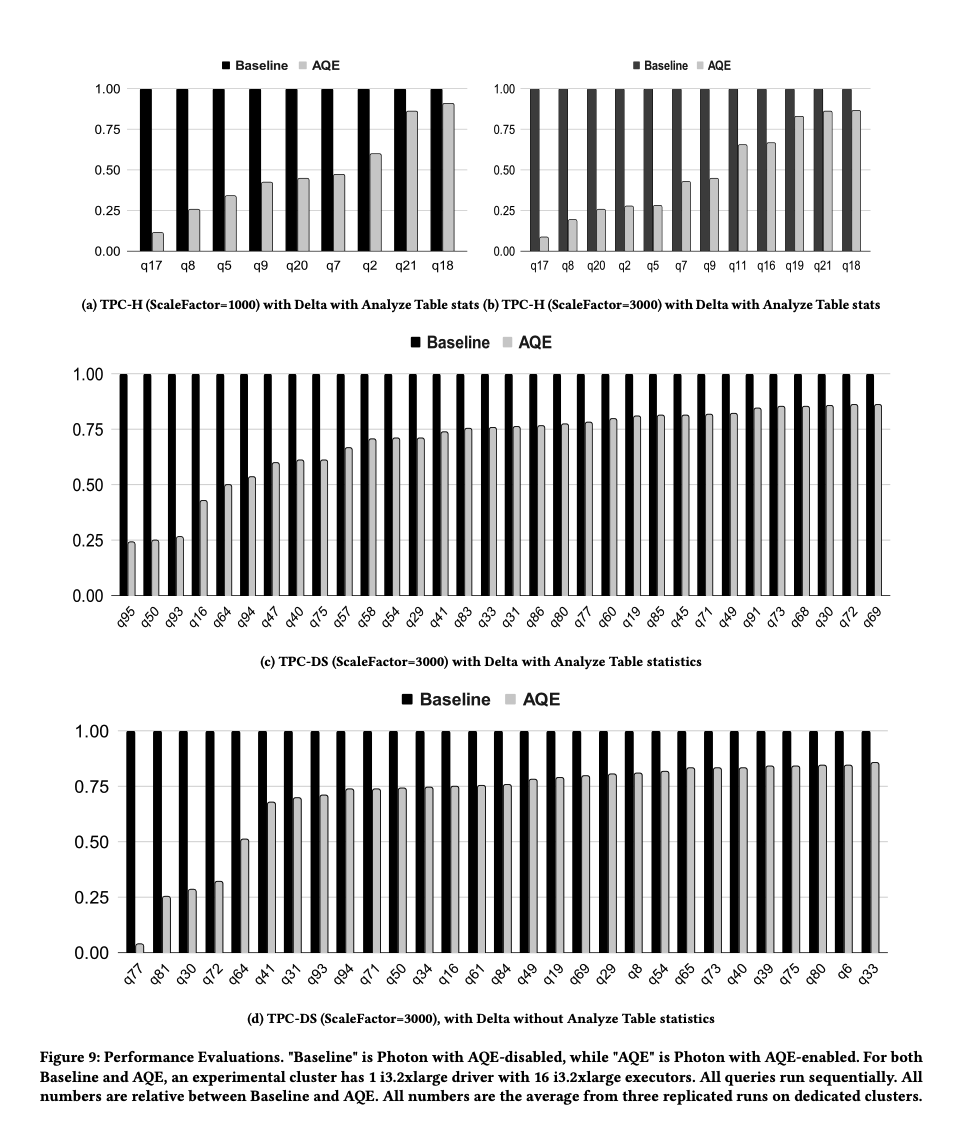
图9
我们在一台具有一个驱动节点的16节点AWS集群上评估了AQE的性能改进。每台节点都是i3.2xlarge实例,配备64GB内存和8个vCPUs(Intel Xeon E5 2686 v4)。我们对不同规模因子(1000和3000)下的TPC-H和TPC-DS基准测试进行了评估,这些数据以Delta格式存储在Amazon S3中,并通过Analyze Table命令预先收集了表和列的统计信息。所有基准测试运行,无论是否启用AQE,都使用了Photon查询引擎。图9展示了所有基准测试中墙钟时间减少15%以上的查询的相对墙钟时间数,基线总是设为1.0。表1总结了关于单个查询加速、总体加速以及查询延迟减少15%或以上的查询数量的基准测试结果。由于TPC基准测试均为均匀分布的数据,观察到的性能增强主要归因于动态连接过滤器(参见第5.1节)、连接算法重新选择(参见第5.3节)和弹性并行度调整(详见第5.4节)。由于所有基准测试都在相同大小的集群上进行,因此预计规模因子为1000的加速效果会小于规模因子为3000的。例如,在较小的数据集上,混洗连接和广播连接之间的性能差异通常较小。
7.2 重新优化开销 重要的是要认识到,Listing 2中的第11至25行可能不会直接影响查询的墙钟时间。这是因为AQE事件循环与实际查询执行是并行操作的,可能在重新优化步骤运行时仍有正在进行的QueryStage。因此,在我们的评估中,我们记录了在没有运行QueryStage时,这些行的墙钟时间作为“重新优化时间”。表1中的最后两列显示了在所有评估的基准测试中,查询延迟中重新优化时间的中位数(P50)和95百分位数(P95)百分比。在表1中,TPC-H的AQE开销低于TPC-DS。这是因为TPC-DS查询通常有更多选择性更强的WHERE谓词用于文件修剪,并且扫描的数据量比TPC-H查询少。
7.3 运营实践 为了支持生产操作,AQE提供了两种调试和可观察性的层级。首先,客户可以通过查询UI访问查询计划演变历史,允许他们跟踪中间查询计划并了解他们的查询是如何执行的。其次,对于内部团队,我们记录了AQE期间的QueryStage统计数据和规则决策,这有助于识别为什么预期的优化没有发生,并突出显示错过的机会。这些日志符合隐私标准,不包含任何客户数据或查询信息。新AQE功能逐步引入生产环境,允许在每一步收集和验证信号。值得注意的是,改进的引擎健壮性(第6节)显著提高了客户对我们产品的满意度,因此降低了我们的运营负担。
相关工作 第3.3节已经详细说明了AQE替代方案的一些缺点。在本节中,我们从三个角度比较了我们的AQE层与相关工作的角色,即(a)分布式查询引擎,(b)静态查询优化技术,(c)动态查询重新优化技术。
分布式查询引擎。传统的、共享无数据仓库(或数据库)如GRACE [24]、Gamma [22]、Teradata [16]、Vertica [30]和Redshift [27]将元数据、存储和计算紧密耦合在一个集群中。共享无架构优化了查询延迟,但缺乏对变化工作负载的弹性,并且由于存储格式、并发控制和数据复制的专有实现,其软件复杂性较高。从2000年代到2010年代,MapReduce [20]及其后继者Spark [5, 46]的出现使得在大数据湖上进行大规模数据处理变得简单、弹性和可扩展。在MapReduce及其相应的开源生态系统Hadoop [3]兴起之后,工业界开发了一系列新的“共享磁盘”查询引擎,如SparkSQL [8]、Impala [29]、F1 Query [37]、BigQuery [13]、Redshift Spectrum [15]、Presto [41]和Snowflake [19]。新的“共享磁盘”架构将存储和计算分离,使用共享的分布式文件系统,这使得查询处理层变得简单和弹性。虽然这些系统最初是为适应数据湖或封闭数据仓库构建的,但通过解决第1节中提出的挑战,它们可以发展为本地支持湖仓。例如,本文描述的工作是SparkSQL的延续,将其性能和稳定性提升到新的水平。
静态查询优化。System R [38]首次引入了使用动态编程的自下而上查询优化器,以选择给定查询的“最佳”计划,根据物理计划的数值成本模型考虑访问路径、连接顺序和有用顺序。作为System R优化器的进步,Cascades [25]是一个涉及自顶向下动态编程的优化器框架,关键组件包括备忘录结构、物理数据属性和需求、搜索空间优先级、探索规则、执行规则和分支定界。值得注意的是,在1990年代末,SQL Server用Cascades风格的架构重建了其查询优化器[34]。为了适应在大数据湖中处理大量数据的需求,SCOPE [47]扩展了SQL Server的优化器以更好地利用分区属性,从而减少执行计划中的不必要数据混洗。当基数估计无懈可击时,工业优化器通常能够找到相当好的物理计划。然而,众所周知,基数估计可能存在数量级的误差[32],估计错误可能导致错过性能改进机会或系统稳定性问题。通过AQE来补充静态优化器,我们的查询引擎对估计错误不那么敏感,并且可以在运行时鲁棒地收敛到“足够好”的执行计划。
动态查询重新优化。尽管动态查询重新优化在工业数据库和查询引擎中尚未广泛采用,但一些研究原型探索了这种方法,一些商业系统则实现了一些想法。INGRES [43]是最早采用动态重新优化的系统。它将连接查询分解为多个单表查询,首先执行它们,存储中间结果,收集统计数据,然后优化和执行连接。随后几款研究原型[28, 33, 36]将剩余的执行计划转换回SQL查询,以便在阻塞操作符边界或人工物化点再次解析、分析和优化。与那些原型相比,我们的AQE框架以更自然的方式建模未完成的计划,以避免对短期运行查询不必要的开销,并支持一种新的取消运行计划片段的原语。Shark原型[44]提出了PDE(部分DAG执行)的概念,它在阶段边界收集运行时统计数据以选择更好的连接算法和处理数据倾斜。AQE可以看作是PDE的延续、扩展和生产化,强调系统简洁性、优化机会和健壮性。Teradata的IPE(增量规划和执行)[42]与AQE有一些相似之处,但IPE文档中描述的优化不如AQE涵盖的范围广泛。BigQuery利用了一个内存中的、阻塞的混洗实现[2]来动态调整混洗接收端的并行度和分区函数。相比之下,第5.4节和第6.3节描述的技术是逻辑上的“合并”和“拆分”操作,不需要再次读取或写入混洗数据,因此不需要在内存中实现混洗。文献[9, 10, 26]提出同时部署替代执行计划,并根据运行时收集的信息将元组路由到适当的操作符中,而不是重新运行优化。Oracle的自适应计划[35]实现了这一研究方向,路由决策基于前几个元组批次做出。然而,我们在第5节和第6节讨论的重新优化比简单切换更复杂,需要全面重写逻辑计划和重新生成物理计划。此外,在分布式查询引擎中运行时部署替代执行计划可能导致任务调度方面的开销和复杂性。在AQE项目初期,我们主动开发并向开源Spark [5]贡献了一些AQE原语。本文描述的系统代表了Spark社区之前努力的超越,专门为Photon [11]分布式查询引擎定制。
CONCLUSION
在本文中,我们介绍了AQE,这是一个自适应且健壮的查询执行框架,具有动态优化套件,支持DatabricksRuntime、DatabricksSQL和DeltaLiveTables。这一框架有效地解决了在数据湖仓环境中静态查询优化器面临的主要挑战,包括缺乏目录统计、基数估计的不完美和成本模型的不准确。我们已经将AQE集成到我们的生产环境中,每天处理数以亿计的查询跨越数艾字节的数据。这种默认部署不仅显著提升了我们产品的性能,还增强了它们的整体稳定性。据我们所知,AQE标志着首个在工业规模上运行全功能动态查询优化的系统的开创性成就。
ACKNOWLEDGMENTS
We would like to thank Intel Corporation for funding the initial exploration of the adaptive query execution idea and prototype with Apache Spark, as well as Spark committers who contributed to the AQE module in open-source Spark.
REFERENCES
[1] Sameer Agarwal, Barzan Mozafari, Aurojit Panda, Henry Milner, Samuel Madden, and Ion Stoica. 2013. BlinkDB: queries with bounded errors and bounded response times on very large data. In Proc. ACM EuroSys. 29–42.
[2] Hossein Ahmadi. 2016. In-memory query execution in Google Big- Query. https://cloud.google.com/blog/products/bigquery/in-memory-query- execution-in-google-bigquery. Last accessed: July 18, 2024.
[3] Apache Hadoop. 2008. https://hadoop.apache.org/. Last accessed: July 18, 2024.
[4] Apache Iceberg. 2020. https://iceberg.apache.org/. Last accessed: July 18, 2024.
[5] Apache Spark. 2010. https://spark.apache.org/. Last accessed: July 18, 2024.
[6] Michael Armbrust, Tathagata Das, Sameer Paranjpye, Reynold Xin, Shixiong Zhu, Ali Ghodsi, Burak Yavuz, Mukul Murthy, Joseph Torres, Liwen Sun, Peter A. Boncz, Mostafa Mokhtar, Herman Van Hovell, Adrian Ionescu, Alicja Luszczak, Michal Switakowski, Takuya Ueshin, Xiao Li, Michal Szafranski, Pieter Senster, and Matei Zaharia. 2020. Delta Lake: High-Performance ACID Table Storage over Cloud Object Stores. Proc. VLDB Endow 13, 12 (2020), 3411–3424. [7] Michael Armbrust, Ali Ghodsi, Reynold Xin, and Matei Zaharia. 2021. Lake- house: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics. In CIDR.
[8] Michael Armbrust, Reynold S. Xin, Cheng Lian, Yin Huai, Davies Liu, Joseph K. Bradley, Xiangrui Meng, Tomer Kaftan, Michael J. Franklin, Ali Ghodsi, and Matei Zaharia. 2015. Spark SQL: Relational Data Processing in Spark. In Proc. ACM SIGMOD. 1383–1394.
[9] Ron Avnur and Joseph M. Hellerstein. 2000. Eddies: Continuously Adaptive Query Processing. In Proc. ACM SIGMOD. 261–272.
[10] Shivnath Babu, Pedro Bizarro, and David J. DeWitt. 2005. Proactive reoptimization with Rio. In Proc. ACM SIGMOD. 936–938.
[11] Alexander Behm, Shoumik Palkar, Utkarsh Agarwal, Timothy Armstrong, David Cashman, Ankur Dave, Todd Greenstein, Shant Hovsepian, Ryan Johnson, Arvind Sai Krishnan, Paul Leventis, Ala Luszczak, Prashanth Menon, Mostafa Mokhtar, Gene Pang, Sameer Paranjpye, Greg Rahn, Bart Samwel, Tom van Bus- sel, Herman Van Hovell, Maryann Xue, Reynold Xin, and Matei Zaharia. 2022. Photon: A Fast Query Engine for Lakehouse Systems. In Proc. ACM SIGMOD. 2326–2339.
[12] Srikanth Bellamkonda, Rafi Ahmed, Andrew Witkowski, Angela Amor, Mohamed Zait, and Chun-Chieh Lin. 2009. Enhanced subquery optimizations in oracle. Proc. VLDB Endow. 2, 2 (2009), 1366–1377.
[13] BigQuery. 2015. https://cloud.google.com/bigquery/docs. Last accessed: July 18, 2024.
[14] Burton H. Bloom. 1970. Space/time trade-offs in hash coding with allowable errors. Commun. ACM 13, 7 (1970), 422–426.
[15] Mengchu Cai, Martin Grund, Anurag Gupta, Fabian Nagel, Ippokratis Pandis, Yannis Papakonstantinou, and Michalis Petropoulos. 2018. Integrated Querying of SQL database data and S3 data in Amazon Redshift. IEEE Data Eng. Bull. 41, 2, 82–90.
[16] John Catozzi and Sorana Rabinovici. 2001. Operating System Extensions for the Teradata Parallel VLDB. In Proc. VLDB Endow. 679–682.
[17] Surajit Chaudhuri, Gautam Das, and Utkarsh Srivastava. 2004. Effective use of block-level sampling in statistics estimation. In Proc. ACM SIGMOD. 287–298.
[18] Surajit Chaudhuri, Bolin Ding, and Srikanth Kandula. 2017. Approximate query processing: No silver bullet. In Proc. ACM SIGMOD. 511–519.
[19] Benoit Dageville, Thierry Cruanes, Marcin Zukowski, Vadim Antonov, Artin Avanes, Jon Bock, Jonathan Claybaugh, Daniel Engovatov, Martin Hentschel, Jiansheng Huang, Allison W. Lee, Ashish Motivala, Abdul Q. Munir, Steven Pelley, Peter Povinec, Greg Rahn, Spyridon Triantafyllis, and Philipp Unterbrunner. 2016. The Snowflake Elastic Data Warehouse. In Proc. ACM SIGMOD. 215–226.
[20] Jeffrey Dean and Sanjay Ghemawat. 2004. MapReduce: Simplified Data Process- ing on Large Clusters. In Proc. USENIX OSDI. 137–150.
[21] Delta UniForm. 2023. https://www.databricks.com/blog/delta-uniform-universal- format-lakehouse-interoperability. Last accessed: July 18, 2024.
[22] David J. DeWitt, Shahram Ghandeharizadeh, Donovan A. Schneider, Allan Bricker, Hui-I Hsiao, and Rick Rasmussen. 1990. The Gamma Database Ma- chine Project. IEEE Trans. Knowl. Data Eng. 2, 1 (1990), 44–62.
[23] DFP. 2020. Faster SQL Queries on Delta Lake with Dynamic File Prun- ing. https://www.databricks.com/blog/2020/04/30/faster-sql-queries-on-delta- lake-with-dynamic-file-pruning.html. Last accessed: July 18, 2024.
[24] Shinya Fushimi, Masaru Kitsuregawa, and Hidehiko Tanaka. 1986. An Overview of The System Software of A Parallel Relational Database Machine GRACE. In Proc. VLDB Endow. 209–219.
[25] Goetz Graefe. 1995. The Cascades Framework for Query Optimization. IEEE Data Eng. Bull. 18, 3 (1995), 19–29.
[26] Goetz Graefe and Karen Ward. 1989. Dynamic Query Evaluation Plans. In Proc. ACM SIGMOD. 358–366.
[27] Anurag Gupta, Deepak Agarwal, Derek Tan, Jakub Kulesza, Rahul Pathak, Stefano Stefani, and Vidhya Srinivasan. 2015. Amazon Redshift and the Case for Simpler Data Warehouses. In Proc. ACM SIGMOD. 1917–1923.
[28] Navin Kabra and David J. DeWitt. 1998. Efficient Mid-Query Re-Optimization of Sub-Optimal Query Execution Plans. In Proc. ACM SIGMOD. 106–117.
[29] Marcel Kornacker, Alexander Behm, Victor Bittorf, Taras Bobrovytsky, Casey Ching, Alan Choi, Justin Erickson, Martin Grund, Daniel Hecht, Matthew Jacobs, Ishaan Joshi, Lenni Kuff, Dileep Kumar, Alex Leblang, Nong Li, Ippokratis Pandis, Henry Robinson, David Rorke, Silvius Rus, John Russell, Dimitris Tsirogiannis, Skye Wanderman-Milne, and Michael Yoder. 2015. Impala: A Modern, Open- Source SQL Engine for Hadoop. In Proc. CIDR.
[30] Andrew Lamb, Matt Fuller, Ramakrishna Varadarajan, Nga Tran, Ben Vandiver, Lyric Doshi, and Chuck Bear. 2012. The Vertica Analytic Database: C-Store 7 Years Later. Proc. VLDB Endow. 5, 12 (2012), 1790–1801.
[31] Linux Foundation Delta Lake. 2020. https://delta.io. Last accessed: July 18, 2024.
[32] Guy Lohman. 2014. Is Query Optimization a “Solved” Problem?. In ACM SIGMOD Blog.
[33] Volker Markl, Vijayshankar Raman, David E. Simmen, Guy M. Lohman, and Hamid Pirahesh. 2004. Robust Query Processing through Progressive Optimiza- tion. In Proc. ACM SIGMOD. 659–670.
[34] Benjamin Nevarez. 2011. Inside the SQL Server Query Optimizer. Simple Talk Publishing. [35] Oracle Adaptive Plan. 2013. Adaptive Plans in Oracle Database 12c. https://oracle- base.com/articles/12c/adaptive-plans-12cr1. Last accessed: July 18, 2024.
[36] Christina Pavlopoulou, Michael J. Carey, and Vassilis J. Tsotras. 2022. Revisit- ing Runtime Dynamic Optimization for Join Queries in Big Data Management Systems. In Proc. EDBT. 1:1–1:12.
[37] Bart Samwel, John Cieslewicz, Ben Handy, Jason Govig, Petros Venetis, Chanjun Yang, Keith Peters, Jeff Shute, Daniel Tenedorio, Himani Apte, Felix Weigel, David Wilhite, Jiacheng Yang, Jun Xu, Jiexing Li, Zhan Yuan, Craig Chasseur, Qiang Zeng, Ian Rae, Anurag Biyani, Andrew Harn, Yang Xia, Andrey Gubichev, Amr El-Helw, Orri Erling, Zhepeng Yan, Mohan Yang, Yiqun Wei, Thanh Do, Colin Zheng, Goetz Graefe, Somayeh Sardashti, Ahmed M. Aly, Divy Agrawal, Ashish Gupta, and Shivakumar Venkataraman. 2018. F1 Query: Declarative Querying at Scale. Proc. VLDB Endow. 11, 12 (2018), 1835–1848.
[38] Patricia G. Selinger, Morton M. Astrahan, Donald D. Chamberlin, Raymond A. Lorie, and Thomas G. Price. 1979. Access Path Selection in a Relational Database Management System. In Proc. ACM SIGMOD. 23–34.
[39] Leonard D Shapiro. 1986. Join processing in database systems with large main memories. ACM Transactions on Database Systems (TODS) 11, 3 (1986), 239–264.
[40] Michael Stillger, Guy M. Lohman, Volker Markl, and Mokhtar Kandil. 2001. LEO - DB2’s LEarning Optimizer. In Proc. VLDB Endow. 19–28.
[41] Yutian Sun, Tim Meehan, Rebecca Schlussel, Wenlei Xie, Masha Basmanova, Orri Erling, Andrii Rosa, Shixuan Fan, Rongrong Zhong, Arun Thirupathi, Nikhil Collooru, Ke Wang, Sameer Agarwal, Arjun Gupta, Dionysios Logothetis, Kostas Xirogiannopoulos, Amit Dutta, Varun Gajjala, Rohit Jain, Ajay Palakuzhy, Prithvi Pandian, Sergey Pershin, Abhisek Saikia, Pranjal Shankhdhar, Neerad Somanchi, Swapnil Tailor, Jialiang Tan, Sreeni Viswanadha, Zac Wen, Biswapesh Chattopad- hyay, Bin Fan, Deepak Majeti, and Aditi Pandit. 2023. Presto: A Decade of SQL Analytics at Meta. Proc. ACM SIGMOD 1, 2 (2023), 189:1–189:25.
[42] Teradata IPE. 2024. Incremental Planning and Execution. https: //docs.teradata.com/r/Enterprise_IntelliFlex_VMware/SQL- Request- and- Transaction- Processing/Query- Rewrite- Statistics- and- Optimization/Teradata- Optimizer-Processes. Last accessed: July 18, 2024.
[43] Eugene Wong and Karel Youssefi. 1976. Decomposition - A Strategy for Query Processing. ACM Transactions on Database Systems (TODS) 1, 3 (1976), 223–241.
[44] Reynold Xin, Josh Rosen, Matei Zaharia, Michael J Franklin, Scott Shenker, and Ion Stoica. 2013. Shark: SQL and rich analytics at scale. In Proc. ACM SIGMOD. 13–24.
[45] Yu Xu, Pekka Kostamaa, Xin Zhou, and Liang Chen. 2008. Handling data skew in parallel joins in shared-nothing systems. In Proc. ACM SIGMOD. 1043–1052.
[46] Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael J. Franklin, Scott Shenker, and Ion Stoica. 2012. Re- silient Distributed Datasets: A Fault-tolerant Abstraction for In-memory Cluster Computing. In Proc. USENIX NSDI. 15–28.
[47] Jingren Zhou, Per-Åke Larson, and Ronnie Chaiken. 2010. Incorporating parti- tioning and parallel plans into the SCOPE optimizer. In Proc. IEEE ICDE. 1060– 1071.
本文系外文翻译,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文系外文翻译,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号