大数据工程师技术之Hive环境集成实践


Hive环境配置
Hive是数据仓库中最常用的一个组件, 但是第一代的Hive的执行引擎是MapReduce,运行起来比较慢, 后面Hive的执行引擎用的比较多的有Tez,Spark
Hive on Spark 核心组件是Hive, 只是把运行的执行引擎替换为了Spark内存计算框架, 提高的程序运行的效率
其中Hive主要负责数据的存储以及SQL语句的解析
Spark on Hive 核心组件是Spark, 只是把Spark的的数据存储使用Hive以及元数据管理使用Hive, Spark负责SQL的解析并且进行计算
在这里我们采用Hive-on-Spark的设计架构
安装Hive环境
使用编译好的源码软件
# 上传安装文件
apache-hive-3.1.2-bin.tar.gz
# 解压到指定目录
tar -zxvf apache-hive-3.1.2-bin.tar.gz -C /bigdata/server/
# 创建软链接
ln -s apache-hive-3.1.2-bin hive配置环境变量
# vim /etc/profile.d/custom_env.sh
## hive
export HIVE_HOME=/bigdata/server/hive
export PATH=$PATH:$HIVE_HOME/bin同步环境变量 xsync /etc/profile.d/custom_env.sh
加载环境变量 source /etc/profile
修改配置文件
创建配置文件 hive-site.xml
<configuration>
<-- 元数据存储的数据库配置 -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://biz01:3306/hive?useSSL=false</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<-- 数据文件存储的目录配置 -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<-- 去掉metastore的校验 -->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<-- 设置thrift的访问端口 hiveserver2 -->
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<-- 设置hiveserver2绑定的主机 -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop03</value>
</property>
<-- 禁用权限认证 -->
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<-- hive客户端配置, 显示表头信息 -->
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<-- hive客户端配置, 显示当前数据库 -->
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
</configuration>初始化元数据信息
需要将mysql的jar包放到hive/lib目录下
mysql-connector-java-5.1.27-bin.jar 上传过去
schematool -initSchema -dbType mysql -verbose-- 解决元数据中文乱码
# 设置注释中文乱码的问题 在MySQL的元数据库设置
alter table COLUMNS_V2 modify column COMMENT varchar(256) character set utf8;
alter table TABLE_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
alter table PARTITION_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
alter table PARTITION_KEYS modify column PKEY_COMMENT varchar(4000) character set utf8;
alter table INDEX_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;测试环境
启动hive客户端
bin/hive
image.png
2. 创建一张测试表
create table student(id int, name string);通过insert插入测试数据
insert into student values(100,'wolf');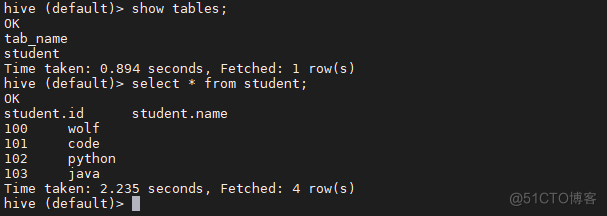
image.png
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2024-05-11,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号