【RL】强化学习入门:从基础到应用


本篇文章是博主强化学习RL领域学习时,用于个人学习、研究或者欣赏使用,并基于博主对相关等领域的一些理解而记录的学习摘录和笔记,若有不当和侵权之处,指出后将会立即改正,还望谅解。文章强化学习: 强化学习(1)---《【RL】强化学习入门:从基础到应用》
【RL】强化学习入门:从基础到应用
1. 引言
强化学习(Reinforcement Learning, RL)是机器学习的一个重要分支,它使得智能体通过与环境的互动来学习如何选择最优动作,以最大化累积奖励。近年来,随着深度学习技术的发展,强化学习取得了显著的进展,尤其在复杂任务中的表现令人瞩目。
2. 强化学习的基本概念
采用猫抓老鼠来简单介绍一下
想象一下,有一只猫在一个房间里追逐老鼠。猫可以在房间内移动(例如,上、下、左、右),并试图捕捉到老鼠。每当猫靠近老鼠时,它会得到正反馈(奖励),而如果猫远离老鼠,则会受到负反馈(惩罚)。猫通过这种方式不断调整自己的策略,以便更有效地捕捉老鼠。

2.1 代理(Agent)与环境(Environment)
在强化学习中,代理是执行动作的实体,而环境则是代理所处的外部系统。代理通过观察环境的状态并采取行动,与环境进行交互。
2.2 状态(State)、动作(Action)与奖励(Reward)
- 状态(S):环境在某一时刻的描述。
- 动作(A):代理在当前状态下可以采取的行为。
- 奖励(R):代理执行动作后,环境返回给代理的反馈,用于衡量动作的好坏。
3. 强化学习的目标
强化学习的目标是学习一个策略,使得代理在长期内获得的累积奖励最大化。
强化学习流程图如下:
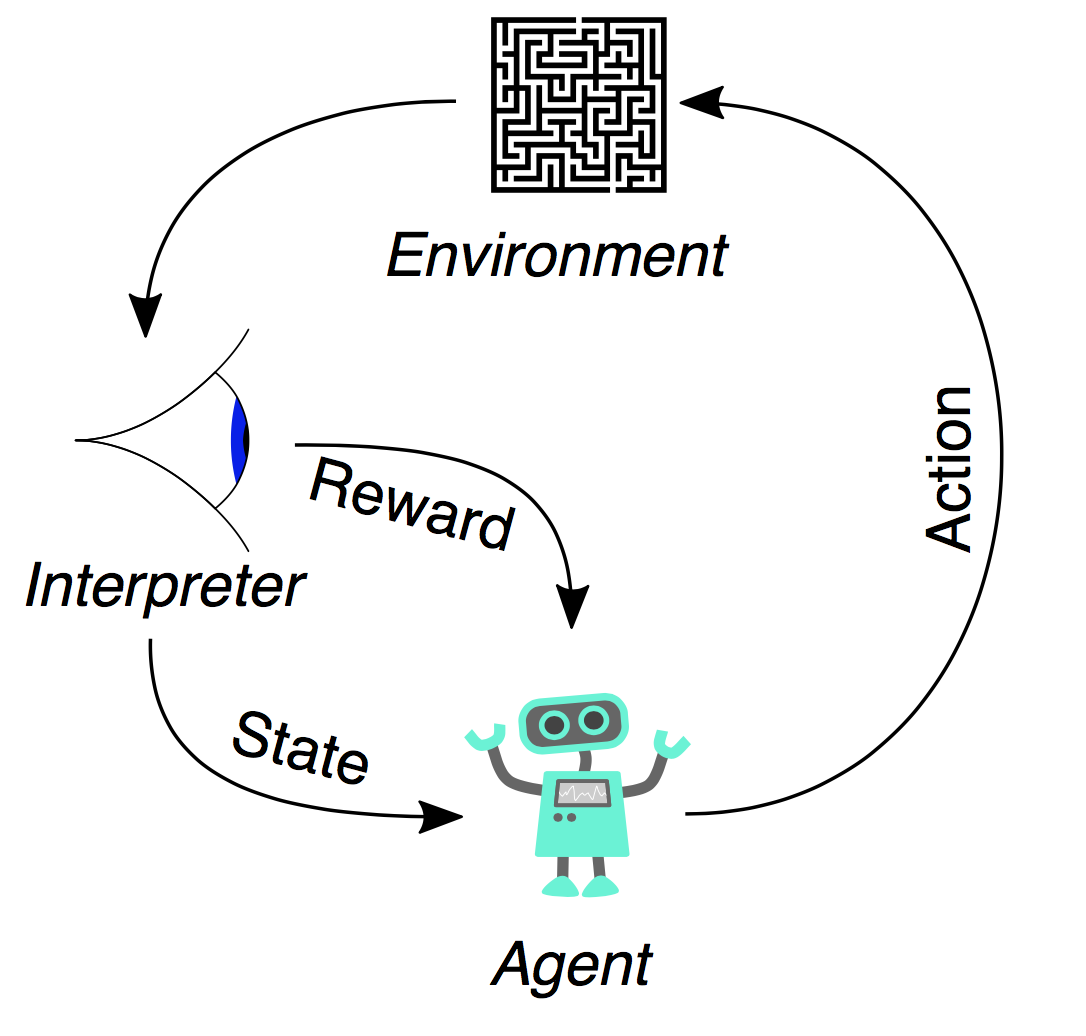
4. 马尔可夫决策过程(MDP)
4.1 MDP定义
马尔可夫决策过程是正式描述强化学习问题的工具。它由五个元素组成:
- 状态集 ( S )
- 动作集 ( A )
- 状态转移概率 ( P(s'|s,a) )
- 奖励函数 ( R(s,a) )
- 折扣因子 ( \gamma )
4.2 状态转移与奖励函数
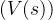
( V(s) )
状态转移概率描述了在状态 ( s ) 下执行动作 ( a ) 后转移到新状态 ( s' ) 的概率。而奖励函数则返回执行该动作后获得的即时奖励。
5. 值函数与策略
5.1 值函数(Value Function)
值函数用于评估状态或状态-动作对的“好坏”。我们定义一个状态值函数 ( V(s) ) 和一个动作值函数 ( Q(s, a) )。
![[ V(s) = \mathbb{E} \left[ \sum_{t=0}^{\infty} \gamma^t R_t | S_0 = s \right] ]](https://developer.qcloudimg.com/http-save/yehe-11391358/f8309b87c494c7e7d856e57475830d37.png)
[ V(s) = \mathbb{E} \left[ \sum_{t=0}^{\infty} \gamma^t R_t | S_0 = s \right] ]
![[ Q(s, a) = \mathbb{E} \left[ \sum_{t=0}^{\infty} \gamma^t R_t | S_0 = s, A_0 = a \right] ]](https://developer.qcloudimg.com/http-save/yehe-11391358/7a9bd0c2311c055265e40f12ce945f6e.png)
[ Q(s, a) = \mathbb{E} \left[ \sum_{t=0}^{\infty} \gamma^t R_t | S_0 = s, A_0 = a \right] ]
5.2 策略(Policy)
策略是从状态到动作的映射,可以是确定性的(每个状态对应一个动作)或随机性的(每个状态对应一个动作概率分布)。
5.3 Q值(Q-value)
Q值表示在状态 ( s ) 下执行动作 ( a ) 后,未来可能获得的累积奖励。通过优化Q值,我们可以找到最优策略,使得在每个状态下选择的动作能最大化预期奖励。
![[ Q(s, a) = R(s, a) + \gamma \sum_{s'} P(s'|s,a) V(s') ]](https://developer.qcloudimg.com/http-save/yehe-11391358/c5a5724f67afec2cbea5783860ed009d.png)
[ Q(s, a) = R(s, a) + \gamma \sum_{s'} P(s'|s,a) V(s') ]
其中:
- ( R(s, a) ) 是在状态 ( s ) 下执行动作 ( a ) 得到的即时奖励。
- ( \gamma ) 是折扣因子,用于权衡当前奖励与未来奖励的重要性。
- ( P(s'|s,a) ) 是从状态 ( s ) 执行动作 ( a ) 转移到状态 ( s' ) 的概率。
6. 强化学习算法
强化学习有多种算法,这里我们介绍几种主要的方法:
6.1 动态规划
动态规划方法依赖于环境模型,适用于已知状态转移和奖励函数的情况。动态规划的基本思想是利用已知的状态值估计来更新其他状态值,常用的方法包括价值迭代和策略迭代。
价值迭代
价值迭代通过反复更新所有状态的值,直到收敛:
![[ V_{k+1}(s) = \max_a \left( R(s,a) + \gamma \sum_{s'} P(s'|s,a)V_k(s') \right) ]](https://developer.qcloudimg.com/http-save/yehe-11391358/dc48d563d1584dc9384135507ae74bd3.png)
[ V_{k+1}(s) = \max_a \left( R(s,a) + \gamma \sum_{s'} P(s'|s,a)V_k(s') \right) ]
策略迭代
策略迭代则交替进行策略评估和策略改进,直到策略不再改变。
6.2 蒙特卡罗方法
蒙特卡罗方法基于实际经验进行学习,不需要环境模型。它通过多次模拟来估计状态值或动作值,利用历史数据计算平均奖励。
![[ V(s) = \frac{1}{N} \sum_{i=1}^{N} G_i ]](https://developer.qcloudimg.com/http-save/yehe-11391358/09855793afbd900a37a6781f070bfedb.png)
[ V(s) = \frac{1}{N} \sum_{i=1}^{N} G_i ]
其中 ( G_i ) 是从状态 ( s ) 开始的回报,( N ) 是经历过的样本数。
6.3 时序差分学习
时序差分学习结合了动态规划和蒙特卡罗方法,在每一步更新中利用当前估计来调整值函数。主要的两种方法是Q学习和SARSA。
6.3.1 Q学习
Q学习是一种无模型的离线学习算法,通过不断更新Q值表来学习最优策略。其更新公式为:
![[ Q(s, a) \leftarrow Q(s, a) + \alpha \left( R + \gamma \max_{a'} Q(s', a') - Q(s, a) \right) ]](https://developer.qcloudimg.com/http-save/yehe-11391358/1963373ca23b48df4441bf67b02488ce.png)
[ Q(s, a) \leftarrow Q(s, a) + \alpha \left( R + \gamma \max_{a'} Q(s', a') - Q(s, a) \right) ]
其中 ( \alpha ) 是学习率。
6.3.2 SARSA
SARSA(State-Action-Reward-State-Action)是一种在线学习方法,更新过程考虑了代理所采取的具体动作。其更新公式为:
![[ Q(s, a) \leftarrow Q(s, a) + \alpha \left( R + \gamma Q(s', a') - Q(s, a) \right) ]](https://developer.qcloudimg.com/http-save/yehe-11391358/040626f3770190fe454a928a191171a1.png)
[ Q(s, a) \leftarrow Q(s, a) + \alpha \left( R + \gamma Q(s', a') - Q(s, a) \right) ]
[Python] Q-learning实现
""" Q-learning实现
时间:2024.07.27
环境:gym-taxi
作者:不去幼儿园
"""
import numpy as np # 导入NumPy库,用于数值计算
import random # 导入random库,用于随机数生成
import gym # 导入OpenAI Gym库
# 创建Taxi环境并指定渲染模式为人类可视化
env = gym.make("Taxi-v3", render_mode="human")
# 超参数设置
num_episodes = 1000 # 训练的总轮数
learning_rate = 0.1 # Q学习的学习率
discount_factor = 0.99 # 折扣因子,用于未来奖励计算
exploration_prob = 1.0 # 初始探索概率
exploration_decay = 0.995 # 探索概率衰减率
min_exploration_prob = 0.01 # 最小探索概率
# 初始化Q表,行表示状态,列表示动作,初始值为0
q_table = np.zeros([env.observation_space.n, env.action_space.n])
# 开始Q-learning算法的主循环
for episode in range(num_episodes):
state, _ = env.reset() # 重置环境并获取初始状态
done = False # 设置done标志,表示当前回合未结束
while not done: # 当回合未结束时循环
# 根据探索策略选择动作
if random.uniform(0, 1) < exploration_prob:
action = env.action_space.sample() # 随机选择一个动作(探索)
else:
action = np.argmax(q_table[state]) # 选择Q值最大的动作(利用)
# 执行动作并获取反馈
next_state, reward, done, truncated, info = env.step(action) # 解包五个返回值
# 更新Q值
q_table[state][action] += learning_rate * (
reward + discount_factor * np.max(q_table[next_state]) - q_table[state][action]
)
# 打印当前获得的奖励
print(f'Episode {episode}, Step Reward: {reward}')
# 更新当前状态
state = next_state
# 衰减探索概率
exploration_prob = max(min_exploration_prob, exploration_prob * exploration_decay)
# 测试学习效果
total_reward = 0 # 总奖励初始化为0
state, _ = env.reset() # 重置环境以开始测试
done = False # 设置done标志,表示测试回合未结束
while not done: # 当测试回合未结束时循环
action = np.argmax(q_table[state]) # 选择Q值最大的动作
next_state, reward, done, truncated, info = env.step(action) # 执行动作并解包返回值
total_reward += reward # 累加总奖励
# 渲染当前状态以进行可视化
env.render()
# 打印每一步获得的奖励
print(f'Step Reward: {reward}')
# 输出测试的总奖励
print(f'Total reward: {total_reward}')
env.close() # 关闭环境[Results] 运行结果
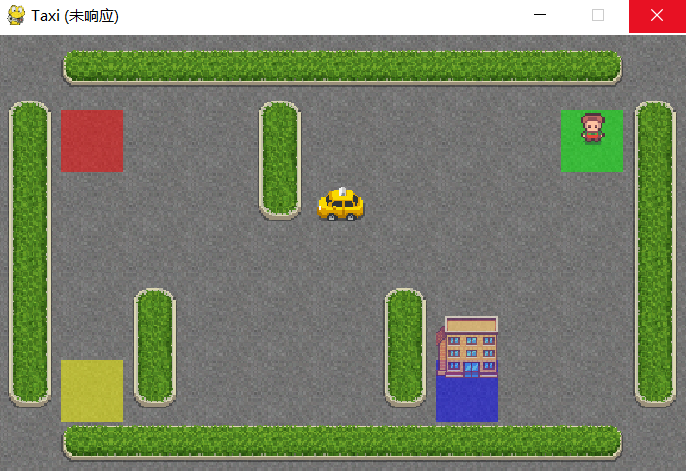
[Notice] 注意事项
在Gym 0.26.2版本中,env.reset()和env.step(action)的返回值都发生了变化。具体来说:
env.reset()现在返回一个包含状态和额外信息的元组。env.step(action)函数只返回四个值:next_state, reward, done, info。- 在其他版本可能
step()方法返回的内容是一个包含五个元素的元组:(next_state, reward, done, info)出现错误:AssertionError: Something went wrong with pygame. This should never happen. - 表明在调用
render方法时出现了问题,主要是因为需要指定渲染模式。Gym 在某些版本中要求在创建环境时明确指定渲染模式,以便正确地显示图形。
解决办法:
- 1.指定渲染模式:当您创建环境时,使用
render_mode参数来确定所需的渲染方式。例如:
env = gym.make("Taxi-v3", render_mode="human") # 使用人类可视化的方式 常见的 render_mode 选项包括:
"human":以用户友好的方式显示环境。如果运行在没有图形界面的服务器上,可能会失败。"rgb_array":返回一个 RGB 数组,可以用于绘图或其他处理
2.确保 Pygame 安装正常:由于 Taxi 环境使用 Pygame 进行渲染,请确保您的系统上已正确安装 Pygame。在 Anaconda 环境中安装 Pygame 的命令为:
pip install pygame文章若有不当和不正确之处,还望理解与指出。由于部分文字、图片等来源于互联网,无法核实真实出处,如涉及相关争议,请联系博主删除。如有错误、疑问和侵权,欢迎评论留言联系作者,或者私信联系作者。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2024-07-27,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号