多种差异分析方法识别微生物标记物
原创
多种差异分析方法识别微生物标记物
原创
生信学习者
修改于 2024-06-12 07:53:02
修改于 2024-06-12 07:53:02
欢迎大家关注全网生信学习者系列:
- WX公zhong号:生信学习者
- Xiao hong书:生信学习者
- 知hu:生信学习者
- CDSN:生信学习者2
介绍
识别组间差异物种是微生物领域常见的数据分析。我们采用三类不同的差异分析方法来发现显著差异的微生物物种,它们分别是:
- Linear Discriminant Analysis of Effect Size (LefSe).
- Microbiome Multivariable Association with Linear Models (Maaslin2).
- Analysis of Composition of Microbiomes with Bias Correction (ANCOM-BC).
LefSe是一种基于有监督的线性判别筛选差异物种的方法;Maaslin2是一种基于线性回归算法鉴定差异物种的方法;ANCOM-BC是一种校正样本之间绝对丰度偏差和零值膨胀等后再发现差异物种的方法。
我们将以LefSe识别出的差异物种作为基准,合并另外两种方法的差异结果,最后以柱状图展示结果。
安装MicrobiomeAnalysis包
- MicrobiomeAnalysis可提供下面分析使用的函数
if (!requireNamespace(c("remotes", "devtools"), quietly=TRUE)) {
install.packages(c("devtools", "remotes"))
}
remotes::install_github("HuaZou/MicrobiomeAnalysis")加载R包
knitr::opts_chunk$set(message = FALSE, warning = FALSE)
library(tidyverse)
library(MicrobiomeAnalysis)
library(Maaslin2)
library(ANCOMBC)
library(phyloseq)
library(ggpubr)
# rm(list = ls())
options(stringsAsFactors = F)
options(future.globals.maxSize = 1000 * 1024^2)
# group & color
sex_grp <- c("Male", "Female")
sex_col <- c("#F28880", "#60C4D3")
lf_grp <- c("None", "Mild", "Moderate", "Severe")
lf_col <- c("#803C08", "#F1A340", "#2C0a4B", "#998EC3")导入数据
数据来自于Zeybel_2022的肠道微生物数据,大家通过以下链接下载:
- 百度网盘链接:https://pan.baidu.com/s/1XW7otwFzDO3DslVa7Ai5_g
- 提取码: 请关注WX公zhong号生信学习者后台发送 微生物差异分析 获取提取码
phy <- readRDS("Zeybel_2022_gut_MGS_ps.RDS")
phy
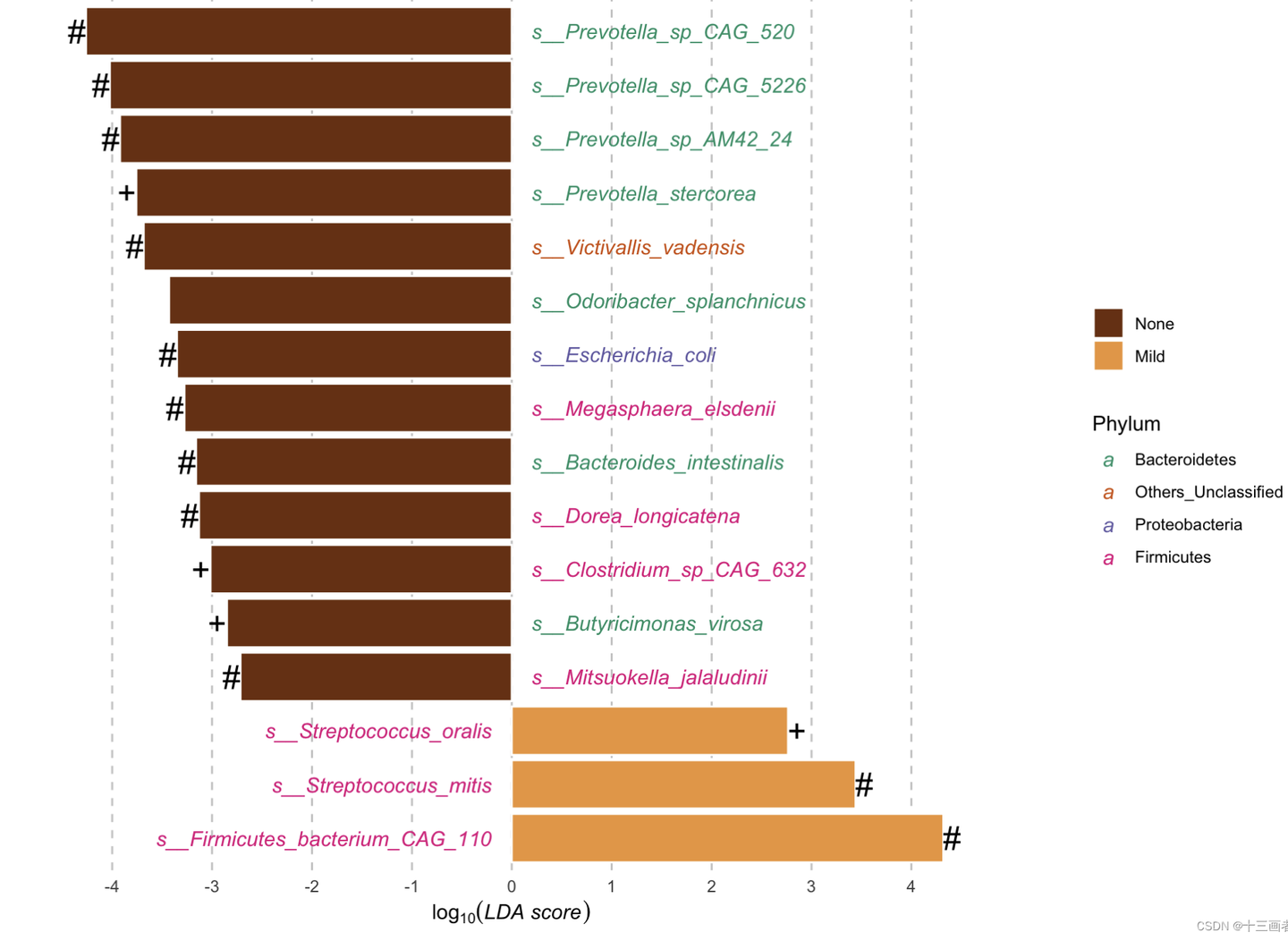
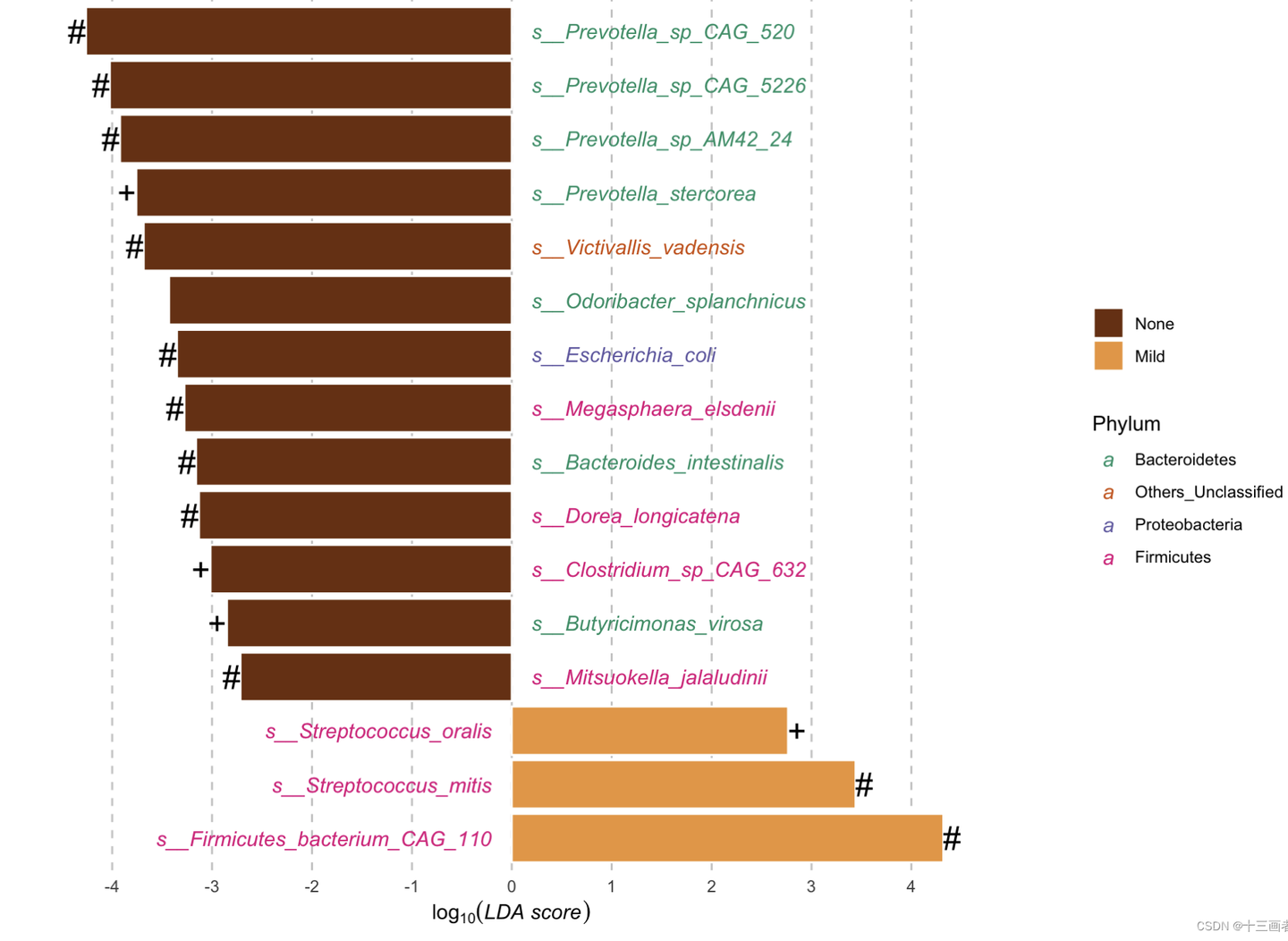
结果:
- Differential abundance of metagenomic species measured by linear discriminant analysis of effect size (LefSe) according to the LiverFatClass group.
- LDA; Linear discriminant analysis.
- + Multivariate analysis (ANCOM-BC & Maaslin2) with a false discovery rate (FDR) adjusted p-value < 0.8.
- * Multivariate analysis (Maaslin2) with a false discovery rate (FDR) adjusted p-value < 0.8.
- # Multivariate analysis (ANCOM-BC) with a false discovery rate (FDR) adjusted p-value < 0.8.
总结
- 三种差异分析方法筛选出来的物种(以lefse作为基准)的交集相对较多(高于50%);
- 三种差异方法,Maaslin2方法相对最严苛,筛选出的差异物种较少,而lefse和ANCOM-BC则筛选出较多物种。lefse没有考虑到多重检验校正,ANCOM-BC使用零膨胀以及校正样本间差异方法,这导致了更多差异物种被识别出来。需要注意点是,从后面单个物种的箱线图能看出,需要对物种出现率进行严格的过滤,可避免出现低出现率物种被识别出来(根据研究目的选择恰当的过滤参数)。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号