无比强大的机器学习扩展包MLxtend
原创

公众号:尤而小屋 编辑:Peter 作者:Peter
大家好,我是Peter~
今天给大家介绍一个强大的机器学习建模扩展包:mlxtend。
mlxtend(machine learning extensions,机器学习扩展)是一个用于日常数据分析、机器学习建模的有用Python库。
mlxtend可以用作模型的可解释性,包括统计评估、数据模式、图像提取等。mlxtend是一个Python第三方库,用于支持机器学习和数据分析任务。
本文关键词:机器学习、mlxtend、聚类、分类、回归、模型可视化
1 MLxtend主要功能
MLxtend主要功能包含:
- 数据处理
- 数据:提供了数据集加载和预处理的功能,方便用户处理各种格式的数据集。
- 预处理:包括数据清洗、标准化、归一化等,确保数据质量,提高模型性能等
- 特征选择
- 基于特征重要性的方法:这种方法通过评估各个特征对模型预测能力的贡献度来选择特征。
- 递归特征消除:这是一种通过递归地考虑越来越小的特征子集来选择特征的方法。
- 基于特征子集搜索的方法:这种方法通过搜索最优特征子集来选择特征,通常使用启发式或优化技术来实现。
- 模型评估
- 分类器:提供了多种分类算法的实现,帮助用户进行分类任务的建模和评估。
- 聚类器:提供了多种聚类算法,用于无监督学习中的样本分组。
- 回归器:提供了回归分析的工具,用于预测连续值输出。
- 评估方法:提供了模型性能评估的方法,如交叉验证、得分指标等。
- 数据可视化
- 绘图:提供了丰富的绘图功能,帮助用户在数据探索和分析过程中可视化数据分布和模型结果。
- 图像:支持图像数据的处理和分析,扩展了机器学习在视觉领域的应用。
官方学习地址:https://rasbt.github.io/mlxtend/
2 导入库
In 1:
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.gridspec as gridspec
import itertools
from sklearn.linear_model import LogisticRegression # 逻辑回归分类
from sklearn.svm import SVC # SVC
from sklearn.ensemble import RandomForestClassifier # 随机森林分类
from mlxtend.classifier import EnsembleVoteClassifier # 从mlxtend导入集成投票表决分类算法
from mlxtend.data import iris_data # 内置数据集
from mlxtend.plotting import plot_decision_regions # 绘制决策边界
import warnings
warnings.filterwarnings('ignore')3 MLxtend分类案例
提供一个分类模型相关的入门案例:
3.1 导入数据
In 2:
X, y = iris_data()
X = X[:, [0,2]] # 所有行,选择2个列
X[:3]Out2:
array([[5.1, 1.4],
[4.9, 1.4],
[4.7, 1.3]])In 3:
y[:3]Out3:
array([0, 0, 0])3.2 初始化多个分类器
In 4:
# 建立3个基线分类器
clf1 = LogisticRegression(random_state=0)
clf2 = RandomForestClassifier(random_state=0)
clf3 = SVC(random_state=0, probability=True) # 输出概率值3.3 使用集成投票表决分类器EnsembleVoteClassifier
In 5:
eclf = EnsembleVoteClassifier(
clfs=[clf1,clf2,clf3], # 使用3个基分类器
weights=[2,1,1], # 赋予权重
voting="soft" # 使用软投票方式
)3.4 绘制决策边界
绘制分类器的决策边界:
In 6:
list(itertools.product([0, 1],repeat=2)) # 计算笛卡尔积Out6:
[(0, 0), (0, 1), (1, 0), (1, 1)]In 7:
labels = ['Logistic Regression','Random Forest','RBF kernel SVM','Ensemble']
fig = plt.figure(figsize=(14, 10))
gs = gridspec.GridSpec(2, 2)
for clf, lab, grd in zip([clf1, clf2, clf3, eclf], # 分类器
labels, # 分类器名称
# 设置图片的位置:[0,0],[0,1],[1,0],[1,1]
itertools.product([0, 1],repeat=2)):
clf.fit(X,y)
ax = plt.subplot(gs[grd[0], grd[1]]) # 子图
fig = plot_decision_regions(X=X,
y=y,
clf=clf,
legend=2)
plt.title(lab) # 标题
plt.show()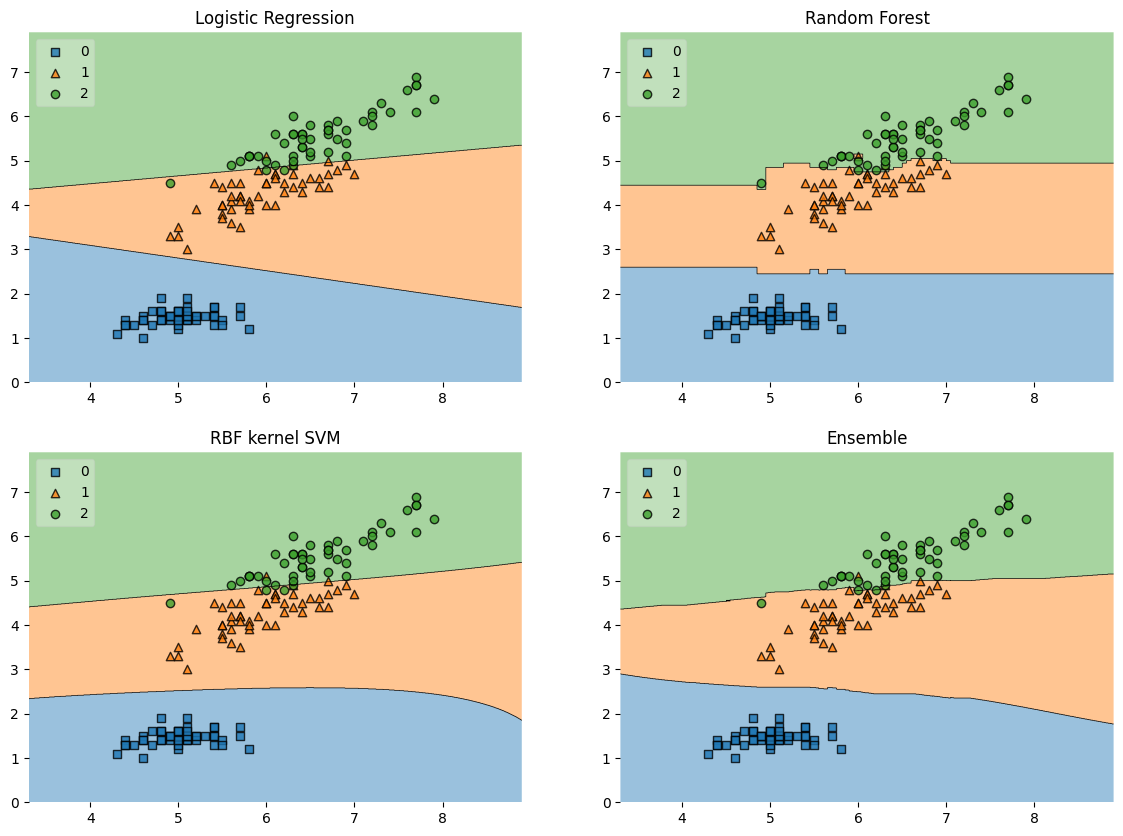
4 MLxtend回归案例
MLxtend内置了线性回归的算法LinearRegression
https://rasbt.github.io/mlxtend/user_guide/regressor/LinearRegression/

4.1 direct(默认)
LinearRegression类中有个参数method,取值不同:direct(默认)、qr(QR decomopisition)、svd(Singular Value Decomposition)、sgd(Stochastic Gradient Descent)
In 8:
import numpy as np
import matplotlib.pyplot as plt
from mlxtend.regressor import LinearRegression
# 模拟数据:从一维变成二维,使用np.newaxis函数
X = np.array([ 1.0, 2.1, 3.6, 4.2, 6])[:, np.newaxis]
y = np.array([ 1.0, 2.0, 3.0, 4.0, 5.0])
ne_lr = LinearRegression() # 默认方法
ne_lr.fit(X, y)
#print('Intercept: %.2f' % ne_lr.b_) # 截距
#print('Slope: %.2f' % ne_lr.w_[0]) # 斜率
def lin_regplot(X, y, model):
plt.scatter(X, y, c='blue')
plt.plot(X, model.predict(X), color='red')
return None
lin_regplot(X, y, ne_lr)
plt.show()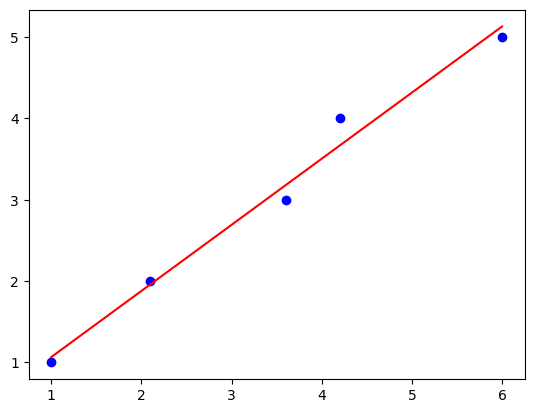
4.2 QR decomposition(QR分解)
In 9:
import numpy as np
import matplotlib.pyplot as plt
from mlxtend.regressor import LinearRegression
X = np.array([ 1.0, 2.1, 3.6, 4.2, 6])[:, np.newaxis]
y = np.array([ 1.0, 2.0, 3.0, 4.0, 5.0])
ne_lr = LinearRegression(method="qr") #
ne_lr.fit(X, y)
def lin_regplot(X, y, model):
plt.scatter(X, y, c='blue')
plt.plot(X, model.predict(X), color='red')
return None
lin_regplot(X, y, ne_lr)
plt.show()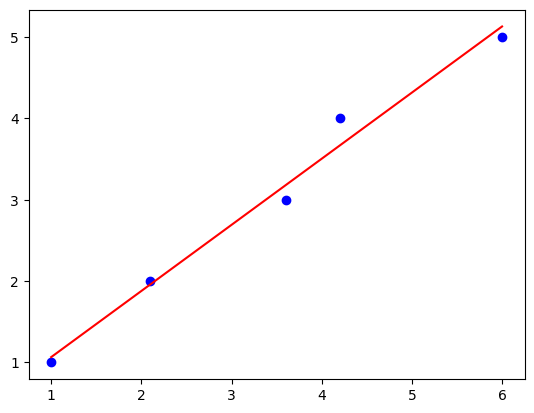
4.3 Gradient Descent-梯度下降
In 10:
import numpy as np
import matplotlib.pyplot as plt
from mlxtend.regressor import LinearRegression
X = np.array([ 1.0, 2.1, 3.6, 4.2, 6])[:, np.newaxis]
y = np.array([ 1.0, 2.0, 3.0, 4.0, 5.0])
gd_lr = LinearRegression(method='sgd',
eta=0.005,
epochs=100,
minibatches=1, # 必须和method="sgd"联用
random_seed=123,
print_progress=3)
gd_lr.fit(X, y)
def lin_regplot(X, y, model):
plt.scatter(X, y, c='blue')
plt.plot(X, model.predict(X), color='red')
return
lin_regplot(X, y, gd_lr)
plt.show()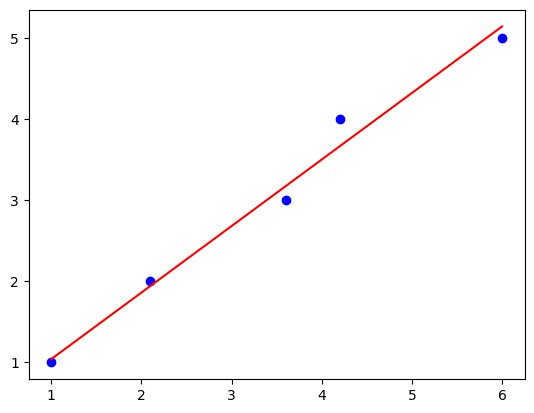
绘制损失函数值cost随迭代次数epochs的变化情况:
In 11:
plt.plot(range(1, gd_lr.epochs+1), gd_lr.cost_)
plt.xlabel('Epochs')
plt.ylabel('Cost')
plt.ylim([0, 0.2])
plt.tight_layout()
plt.show() 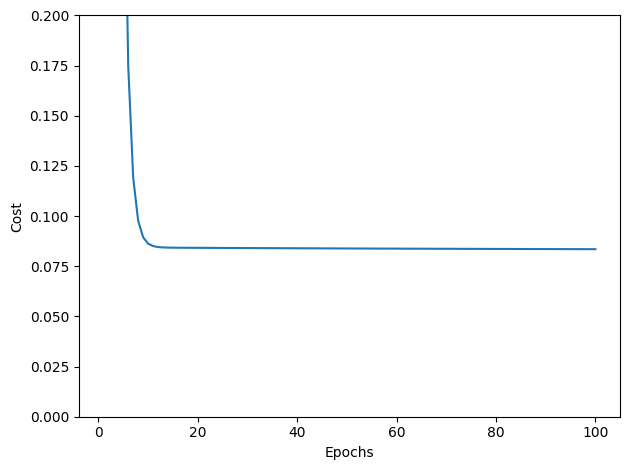
5 MLxtend聚类案例
mlxtend内置的是K-means算法
5.1 导入数据
In 12:
import matplotlib.pyplot as plt
from mlxtend.data import three_blobs_data
X, y = three_blobs_data()
X[:3]Out12:
array([[2.60509732, 1.22529553],
[0.5323772 , 3.31338909],
[0.802314 , 4.38196181]])In 13:
yOut13:
array([1, 2, 2, 2, 1, 2, 2, 1, 0, 2, 1, 0, 0, 2, 2, 0, 0, 1, 0, 1, 2, 1,
2, 2, 0, 1, 1, 2, 0, 1, 0, 0, 0, 0, 2, 1, 1, 1, 2, 2, 0, 0, 2, 1,
1, 1, 0, 2, 0, 2, 1, 2, 2, 1, 1, 0, 2, 1, 0, 2, 0, 0, 0, 0, 2, 0,
2, 1, 2, 2, 2, 1, 1, 2, 1, 2, 2, 0, 0, 2, 1, 1, 2, 2, 1, 1, 1, 0,
0, 1, 1, 2, 1, 2, 1, 2, 0, 0, 1, 1, 1, 1, 0, 1, 1, 2, 0, 2, 2, 2,
0, 2, 1, 0, 2, 0, 2, 2, 0, 0, 2, 1, 2, 2, 1, 1, 0, 1, 0, 0, 0, 0,
1, 0, 0, 0, 2, 0, 1, 0, 2, 2, 1, 1, 0, 0, 0, 0, 1, 1])5.2 数据可视化
In 14:
plt.scatter(X[:, 0], X[:, 1], c='black')
plt.show()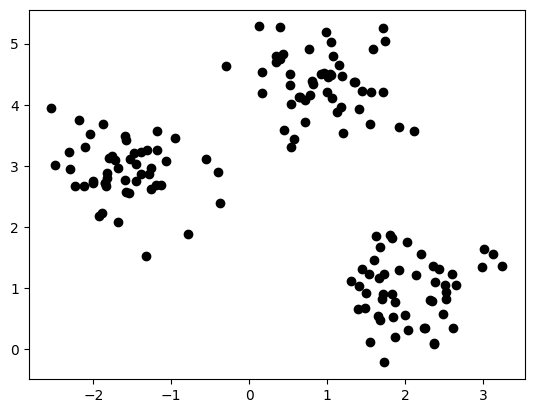
5.3 计算聚类质心
In 15:
from mlxtend.cluster import Kmeans
km = Kmeans(k=3, # 聚类数
max_iter=50, # 最大迭代次数
random_seed=1, # 随机种子
print_progress=3 # 每隔3次打印进度
)
km.fit(X)
Iteration: 2/50 | Elapsed: 00:00:00 | ETA: 00:00:00Out15:
<mlxtend.cluster.kmeans.Kmeans at 0x281b745ff10>In 16:
km.iterations_ # 打印聚类的迭代次数Out16:
2In 17:
km.centroids_ # 打印聚类的中心Out17:
array([[-1.5947298 , 2.92236966],
[ 2.06521743, 0.96137409],
[ 0.9329651 , 4.35420713]])5.4 聚类可视化
In 18:
# 聚类结果
y_clust = km.predict(X)
# 簇群1
plt.scatter(X[y_clust == 0, 0],
X[y_clust == 0, 1],
s=50,
c="lightgreen",
marker="s",
label="cluster1"
)
# 簇群2
plt.scatter(X[y_clust == 1, 0],
X[y_clust == 1, 1],
s=50,
c="orange",
marker="o",
label="cluster2"
)
# 簇群3
plt.scatter(X[y_clust == 2, 0],
X[y_clust == 2, 1],
s=50,
c="lightblue",
marker="v",
label="cluster3"
)
# 绘制聚类质心
plt.scatter(km.centroids_[:,0],
km.centroids_[:,1],
s=250,
marker='*',
c='red',
label='centroids')
plt.legend(loc='lower left',
scatterpoints=1
)
plt.grid()
plt.show()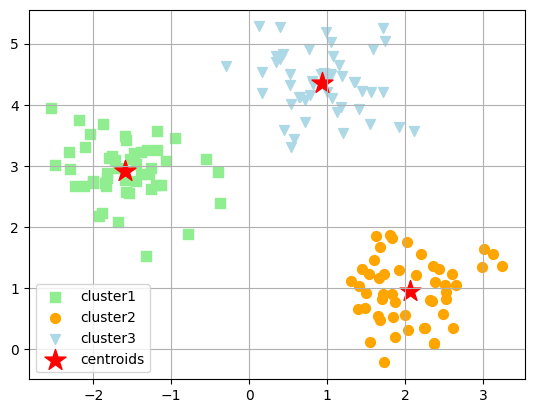
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号