pandas 快速上手系列:自定义 dataframe

pandas 快速上手系列:自定义 dataframe

用户4945346
发布于 2024-05-27 20:19:38
发布于 2024-05-27 20:19:38
这是该系列的第 2 篇文章,上篇文章介绍了 pandas 中的核心概念,文章链接Python 中的 pandas 快速上手之:概念初识,本篇主要介绍了 pandas 读取数据的方法,用字典 dict 、csv、json 作为演示,还讲解了 dataframe 的输出自定义,包括行列索引的定制化以及数据类型的转换,希望对你有所帮助。

读取方法
pandas 支持读取多种数据源,它可以解析字典 dict、csv、json 等格式的文件或数据。
读取字典dict
In [1]: import pandas as pd
...:
...: # 创建一个字典
...: data = {'Name':['Alice', 'Bob', 'Claire'],
...: 'Age':[25, 30, 35],
...: 'City':['New York', 'Los Angeles', 'Chicago']}
...:
...: # 从字典创建DataFrame
...: df = pd.DataFrame(data)
...: print(df)输出:
Name Age City
0 Alice 25 New York
1 Bob 30 Los Angeles
2 Claire 35 Chicago读取 json
import pandas as pd
# 从JSON文件创建DataFrame
df = pd.read_json('data.json')
print(df)
读取 csv

代码如下
import pandas as pd
csv_path = "full_canbus_00000_merge.csv"
df = pd.read_csv(csv_path)
print(df)输出:
timestamp ... ros time
0 1660710058700550656 ... 1.660710e+09
1 1660710058800525056 ... 1.660710e+09
2 1660710058900476672 ... 1.660710e+09
3 1660710059000497408 ... 1.660710e+09
4 1660710059100544768 ... 1.660710e+09
... ... ... ...
1735 1660710232400549376 ... 1.660710e+09
1736 1660710232500513536 ... 1.660710e+09
1737 1660710232600539648 ... 1.660710e+09
1738 1660710232700497408 ... 1.660710e+09
1739 1660710232800486656 ... 1.660710e+09自定义dataframe
上面 csv 有很多表头,但是 print 输出的只有timestamp、ros time两列,中间省略的很多,默认情况下, pandas 在打印 DataFrame 时,如果列数超过一定阈值就会用省略号...代替中间的列。这样做是为了防止输出内容过于冗长。
但在某些场景下,我们可能需要查看 DataFrame 的全部列,此时就可以使用将该阈值设置为None
pd.set_option('display.max_columns', None)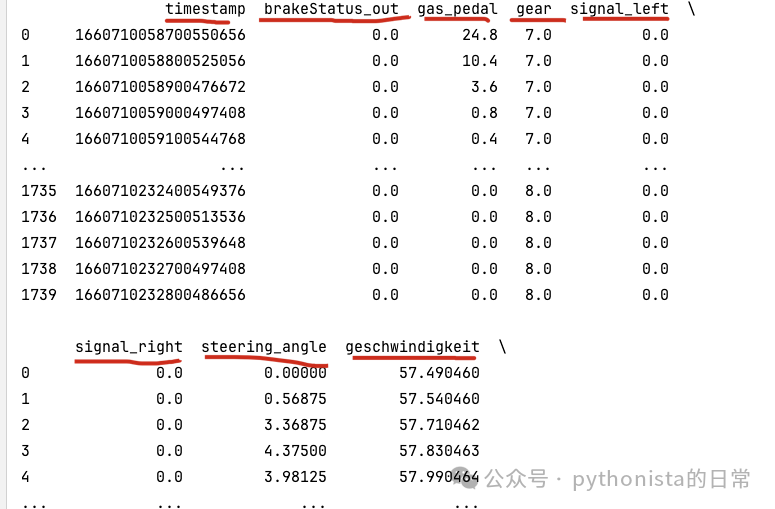
隐藏行索引
如果希望不展示左侧的行索引可以这样设置

df.to_string(index=False)修改列名
如果希望更改行索引和列索引名称,可以使用 rename 方法,
import pandas as pd
csv_path = "full_canbus_00000_merge.csv"
df = pd.read_csv(csv_path,)
columns_dict = {
"timestamp": "time"
}
# print(df.to_string(index=False))
index_dict = {
0: 'new_row_0',
1: 'new_row_1'
}
print(df.rename(index=index_dict, columns=columns_dict))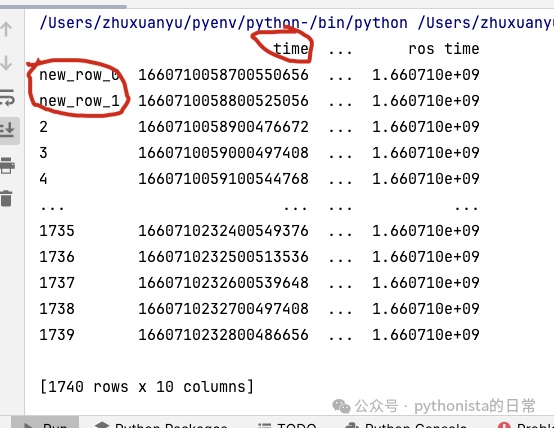
强制转换
可以通过设置 dtype 这个属性来控制列数据的类型,下面是将整数型的 ros time 列转成字符串类型
import pandas as pd
csv_path = "full_canbus_00000_merge.csv"
print(pd.read_csv(csv_path))
print(" 分割线-------------")
print(pd.read_csv(csv_path, dtype={"signal_left": int, "ros time": str}))
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-05-17,如有侵权请联系 cloudcommunity@tencent.com 删除
本文分享自 pythonista的日常 微信公众号,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文参与 腾讯云自媒体同步曝光计划 ,欢迎热爱写作的你一起参与!
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号