吴恩达:AI 智能体工作流


省流版:
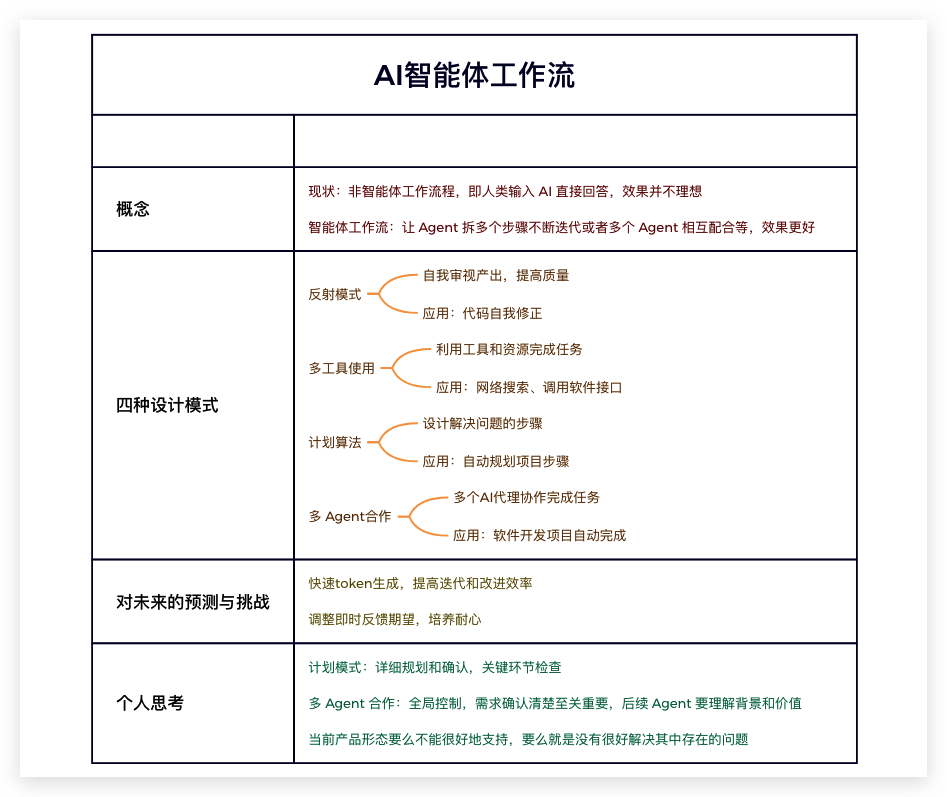
一、背景
吴恩达近日做了题为《What’s next for AI agentic workflows ft》的非常有价值的分享。
1.1 Agent 工作流
分享中指出不用 Agent 工作流时通过一次对话得到答案,效果往往不是很好。通过智能体工作流进行步骤拆分不断迭代,效果会更好。

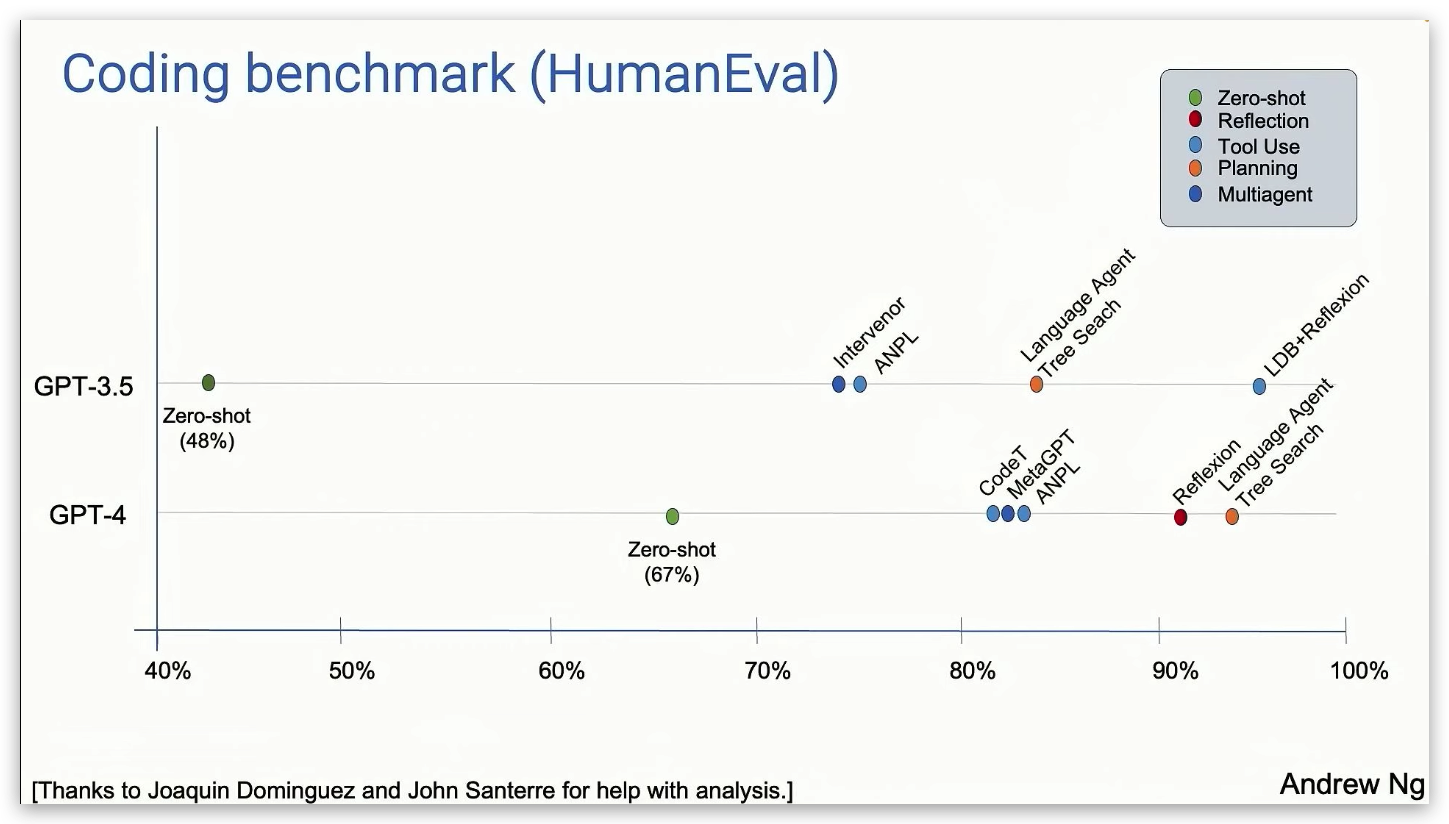
代码基准测试中 GPT 3.5 准确率为 48% ,而 GPT-4 的准确率是 67%。但是加入智能体工作流的方式,GPT 3.5 甚至可以比单纯使用 GPT-4 的表现更好。
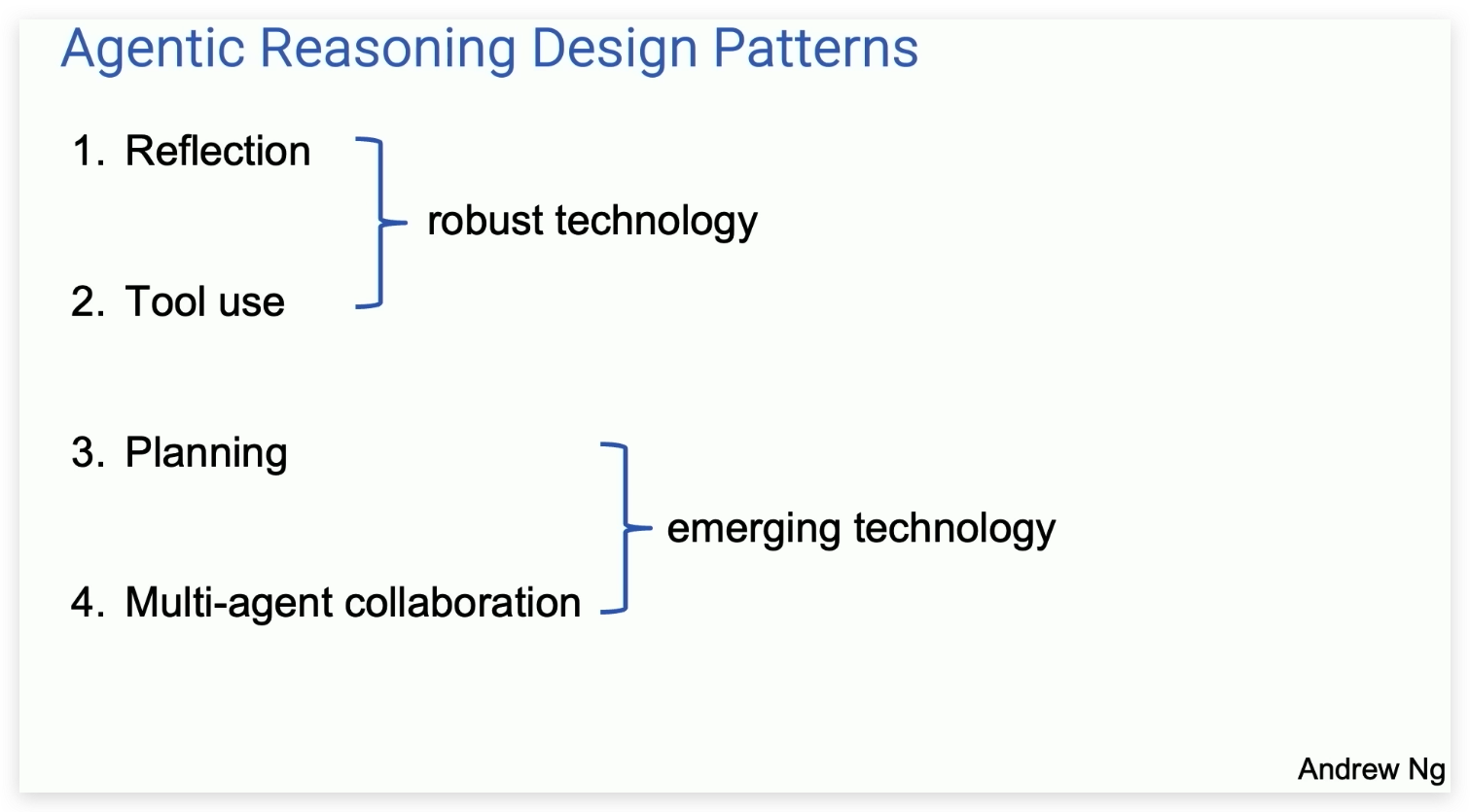
1.2 四种设计模式
在分享中他提出 AI 智能体的四种设计模式。

反思(Reflection): LLM 检查自己的工作,以提出改进方法。
使用工具(Tool use):LLM 拥有网络搜索、代码执行或任何其他功能来帮助其收集信息、采取行动或处理数据。
规划(Planning):LLM 提出并执行一个多步骤计划来实现目标。
多智能体协作(Multi-agent collaboration):多个 AI 智能体一起工作,分配任务并讨论和辩论想法,提出比单个智能体更好的解决方案。
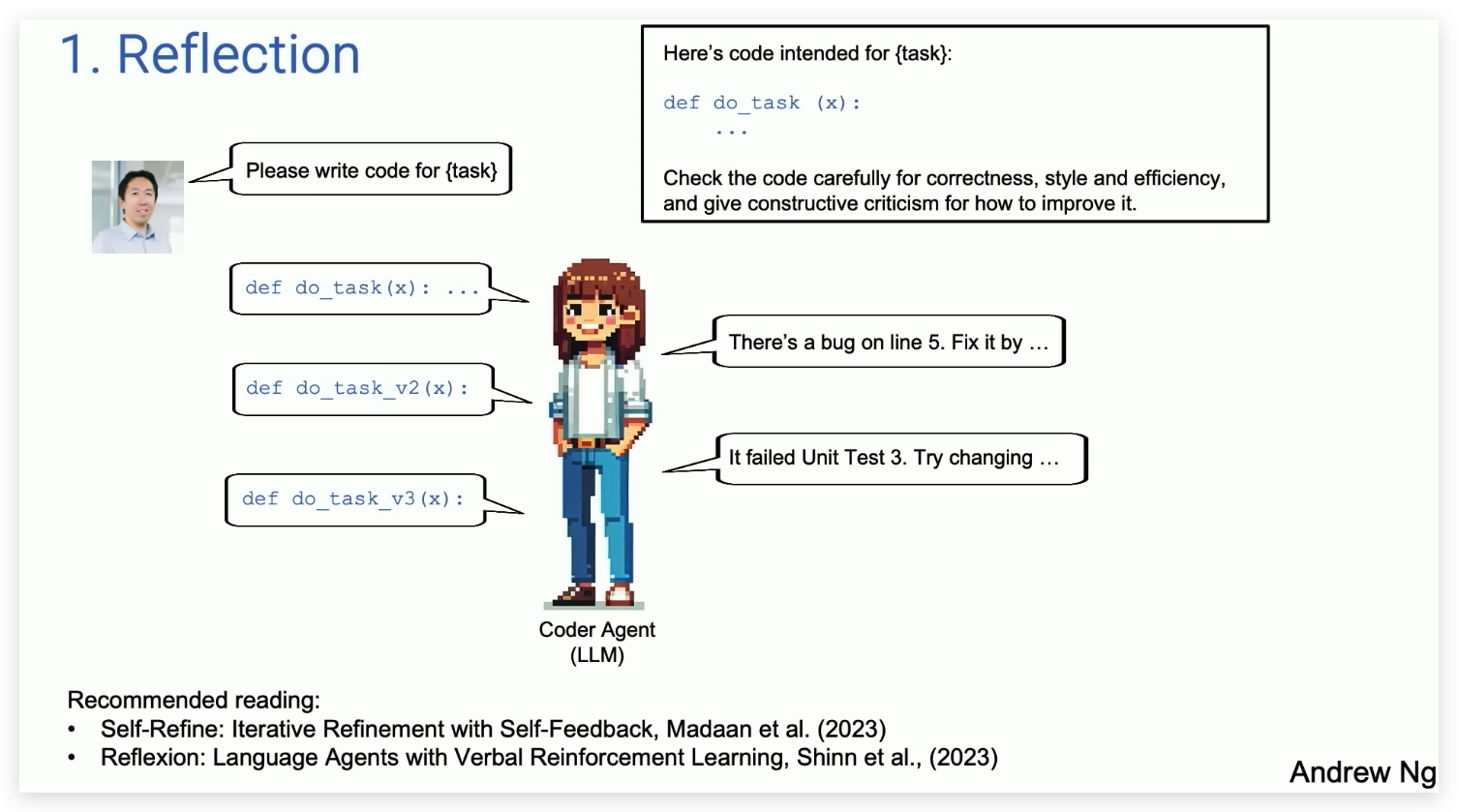
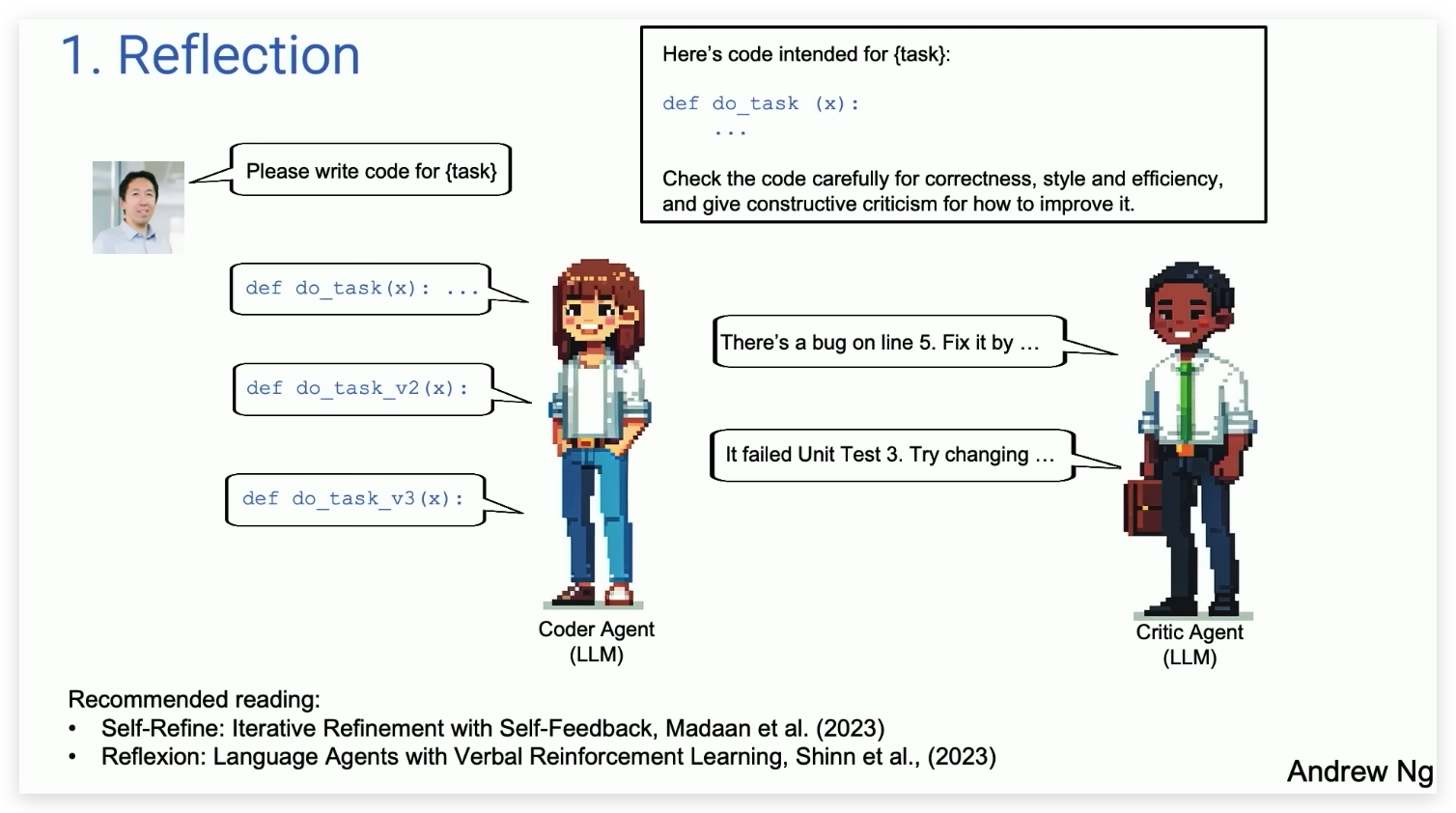
1. 反思(Reflection)
- 定义:反思模式允许 AI 代理自我审视其产出,评估正确性、效率和构造质量。通过这种方式,AI 能够识别并修正自身产出中的错误,从而提高最终产物的质量。
- 相关论文:
- 应用实例:一个典型的应用是代码编写。AI 首先生成代码,然后再次审视这段代码,检查是否有逻辑错误或可以优化的地方,并据此进行修改。这种自我修正的过程可能循环进行多次,直到代码达到预期的标准。
2. 多工具使用(Tool Use)
- 定义:这种模式指的是AI代理能够利用多种工具和资源来完成任务,例如进行网络搜索、调用其他软件接口等。这扩展了AI的能力,使其不仅限于单一任务或领域。

- 相关论文:
- 应用实例:在处理需要外部信息或特定领域工具的任务时,AI 代理可以先识别出所需的工具或信息源,然后获取并应用这些资源来完成任务。比如,生成一段代码前,先通过网络搜索相关的算法或逻辑。
3. 计划算法(Planning)
- 定义:计划算法使AI代理能够设计一系列有序的步骤来解决复杂问题,这通常涉及到前瞻性思维和策略规划。

- 相关论文:
- 应用实例:AI 代理可以根据给定的目标自动规划出实现路径,比如在开发一个新项目时,AI能够规划出研究、设计、编码、测试等一系列步骤,并自动执行这一计划,甚至在遇到问题时重新规划以绕过障碍。
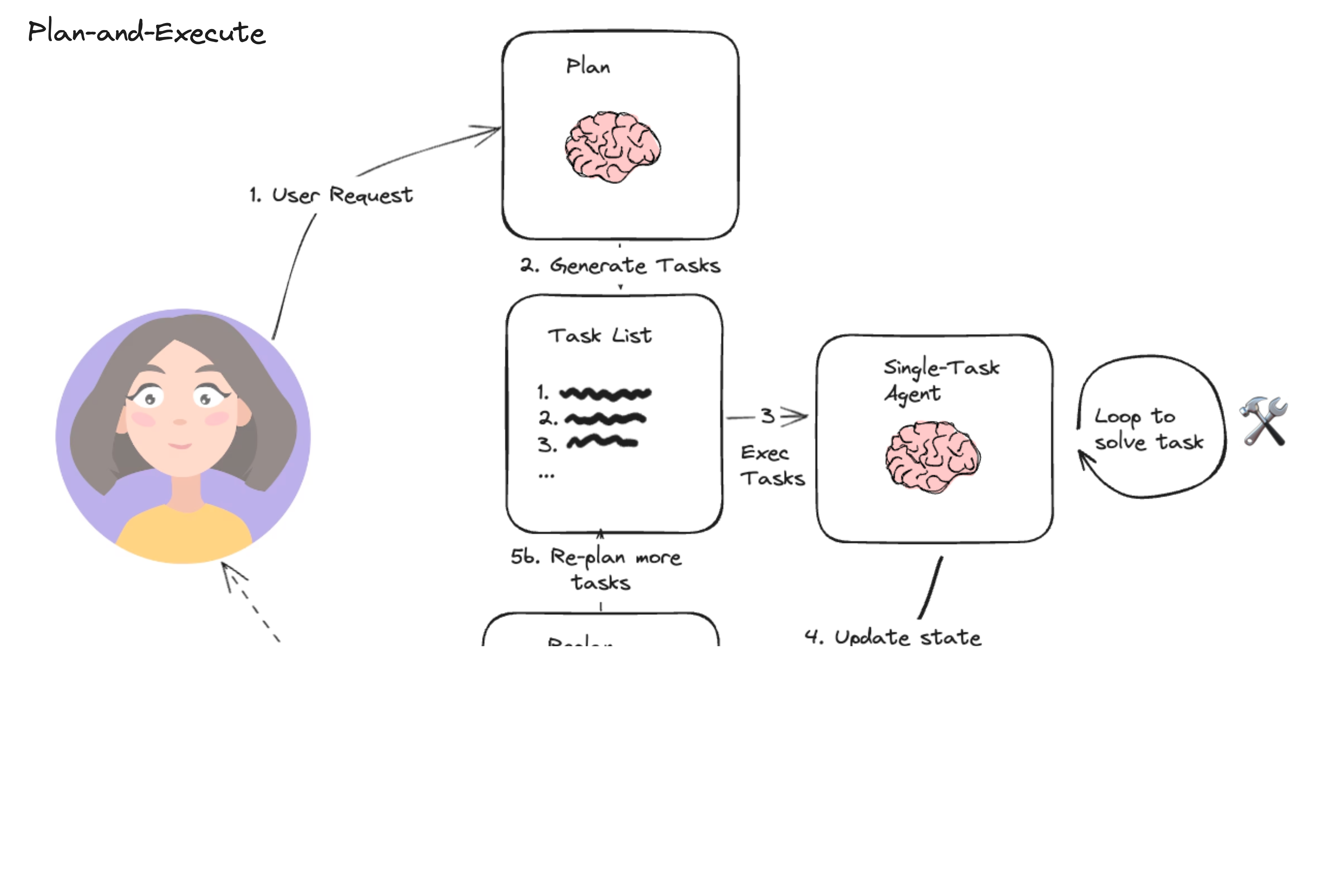
图片来源:https://nbviewer.org/github/langchain-ai/langgraph/blob/main/examples/plan-and-execute/plan-and-execute.ipynb
相关 AI 工具:https://agentgpt.reworkd.ai/zh
4. 多 Agent 合作(Multi-agent Collaboration)
- 定义:这种模式涉及到多个 AI 代理相互协作,每个代理可能负责不同的任务或扮演不同的角色,通过协作来解决问题或完成任务。

图中引用的是 :ChatDev 的例子。
- 相关论文:
- 应用实例:在软件开发的场景中,一个 AI 代理可能扮演项目经理的角色,负责规划项目和分配任务,另一个 AI 代理扮演开发者角色,负责编写代码,还有的 AI 代理可能专注于测试和代码审查。这些代理通过相互协作,能够自动完成一个软件开发项目。
每种设计模式都体现了AI代理工作流在提高任务处理效率、增强问题解决能力方面的潜力,预示着AI技术在复杂任务处理和自动化方面的未来发展方向。
二、对未来的预测与挑战
吴教授预测,智能体工作流将在未来几年内极大扩展 AI 的能力边界。

他强调了快速的 token 生成的重要性,认为这将支持更有效的迭代和改进过程。同时,他提到了对于即时反馈期望的调整,指出在使用AI智能体工作流时,我们需要学会耐心等待。
三、我的一些思考
3.1 关于计划模式
对于计划模式:虽然 Agent 能够比较容易识别“错误”,但有些并不是错误而是和目标偏离的情况不容易被发现,导致最终执行的结果不符合预期。对于这种任务,应该在执行之前进行详细的规划和确认,就像软件工程师在写代码之前就需要先做技术方案并评审一样。在执行过程中也要在关键的环节进行检查和确认,避免到最后环节才发现问题返工重做。

就像在执行过程中关键环节的检查和确认一样,你在旅途中可能设立几个检查点来确认是否还在正确的路线上,装备是否齐全,和队伍是否完好。如果你等到到达露营地后才发现忘记带帐篷或食物,那么整个露营计划可能都要泡汤,就像在项目的最后阶段才发现问题,需要返工重做一样,不仅耽误时间还可能增加成本。
3.2 关于多 Agent 合作模式
对于多 Agent 合作模式:理论上分工明确各司其职,就可以做好。但应该有一个 Agent 能够把控全局或者后续 Agent 不仅要干好自己的活还应该了解做事的背景和价值,以便更好地做事情。对于多代 Agent 合作模式,一个非常重要的点是在开始前最好需求的对齐,避免产出不符合预期的软件浪费很多计算资源。

3.3 关于产品形态
现在的 AI 平台还没有跟上这些设计模式,如让同一个平台的多个 Agent 之间,甚至不同平台的 Agent 之间可以非常好地交流协作。现在的很多 AI 平台并没有解决这些设计模式中的一些问题,如自动计划算法,如何在任务执行中间进行检查,避免有一个步骤走偏后面越来越离谱。
四、总结
Agent 工作流让大语言模型发挥出更大价值。文中提出的四种设计模式对 Agent 发展提供了非常重要的指导,值得继续探索。当然,四种设计模式落地过程中还存在诸多问题,需要警惕和克服。当前的产品形态还不能非常好地支撑这些模式,还还很长的路要走。
实战技巧参见:《用扣子/Coze 揭秘吴恩达的4种 AI Agent 设计模式》
各种各样的 Agent 产品合集:https://github.com/e2b-dev/awesome-ai-agents
参考资料:
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2024-04-12,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号