从LLaMA-Factory项目认识微调

从LLaMA-Factory项目认识微调

HUC思梦
发布于 2024-04-18 09:05:31
发布于 2024-04-18 09:05:31
概述
什么是LLaMA-Factory?
LLaMA-Factory是一个在github上开源的,专为大模型训练设计的平台。项目提供中文说明,可以参考官方文档:https://github.com/hiyouga/LLaMA-Factory/blob/main/README_zh.md
为什么要学习LLaMA-Factory?
大模型技术发展到现在,企业想要真正利用大模型做些事情,一定需要懂得大模型微调的过程。注意,这里说的是过程,而不是原理,专业技术人员才需要懂原理,普通用户只要懂过程就可以完成对大模型的微调。 对于有微调大模型需求,却对大模型微调完全是一个门外汉的用户来说,通过学习LLaMA-Factory后,可以快速的训练出自己需要的模型。 对于想要了解微调大模型技术的技术人员,通过学习LLaMA-Factory后也能快速理解模型微调的相关概念。 所以,我认为LLaMA-Factory是走向大模型微调的一条捷径。
如何学习?
如果你只想了解如何利用LLaMA-Factory进行模型的微调,直接通过官方文档即可完成。无需阅读本文。 如果你想对大模型微调技术本身感兴趣,想要深入了解,可以继续阅读本专栏,笔者将通过阅读源码的方式,对大模型微调技术进行深入剖析,看到哪里,遇到不懂的概念再去理解,最终展现出大模型训练的全貌。 理解了微调技术后,再通过使用LLaMA-Factory进行模型的微调实践,即可掌握大模型微调技术。
基础知识
阅读源码之前,我们需要对模型微调相关概念有一定的认识,来协助我们理解源码。
模型训练阶段
在理解模型微调概念之前,我们先来理解大模型训练阶段有哪些。
Pre-Training
Pre-Training:预训练阶段。 这个阶段是用来训练基础模型的,是最消耗算力的阶段,也是大模型诞生的起始阶段。
Supervised Finetuning(SFT)
sft:指令微调/监督微调阶段 和预训练阶段相比,这个阶段最大的变化就是训练数据由"量多质低"变为"量少质高",训练数据主要由人工进行筛选或生成。这个阶段完成后其实已经能获得一个可以上线的大模型了
RLHF
RLHF:基于人类反馈的强化学习(Rainforcement Learning from Human Feedback,RLHF) 可以分成两个环节
奖励建模阶段(Reward Modeling)
在这一阶段,模型学习和输出的内容发生了根本性的改变。前面的两个阶段,预训练和微调,模型的输出是符合预期的文本内容;奖励建模阶段的输出不仅包含预测内容,还包含奖励值或者说评分值,数值越高,意味着模型的预测结果越好。这个阶段输出的评分,并不是给最终的用户,而是在强化学习阶段发挥重大作用。
强化学习阶段(Reinforcement Learning)
这个阶段非常“聪明”的整合了前面的成果:
- 针对特定的输入文本,通过 SFT 模型获得多个输出文本。
- 基于 RM 模型对多个输出文本的质量进行打分,这个打分实际上已经符合人类的期望了。
- 基于这个打分,为多个输出文本结果加入权重。这个权重其实会体现在每个输出 Token 中。
- 将加权结果反向传播,对 SFT 模型参数进行调整,就是所谓的强化学习。
常见的强化学习策略包括PPO与DPO,它们的细节我们不去研究,只要知道DPO主要用于分布式训练,适合大规模并行处理的场景,PPO通常指的是单机上的算法就可以了。
模型训练模式
了解了模型训练阶段后,现在有个问题,我们应该在哪个阶段进行微调训练呢? 通常会有以下训练模式进行选择,根据领域任务、领域样本情况、业务的需求我们可以选择合适的训练模式。 模式一:基于base模型+领域任务的SFT; 模式二:基于base模型+领域数据 continue pre-train +领域任务SFT; 模式三:基于base模型+领域数据 continue pre-train +通用任务SFT+领域任务SFT; 模式四:基于base模型+领域数据 continue pre-train +通用任务与领域任务混合SFT; 模式五:基于base模型+领域数据 continue pre-train(混入SFT数据+通用任务与领域任务混合SFT; 模式六:基于chat模型+领域任务SFT; 模式七:基于chat模型+领域数据 continue pre-train +领域任务SFT
是否需要continue pre-train
大模型的知识来自于pre-train阶段,如果你的领域任务数据集与pre-train的数据集差异较大,比如你的领域任务数据来自公司内部,pre-train训练样本基本不可能覆盖到,那一定要进行continue pre-train。 如果你的领域任务数据量较大(token在1B以上),并只追求领域任务的效果,不考虑通用能力,建议进行continue pre-train。
是选择chat模型 还是base模型
如果你有一个好的base模型,在base模型基础进行领域数据的SFT与在chat模型上进行SFT,效果上差异不大。 基于chat模型进行领域SFT,会很容导致灾难性遗忘,在进行领域任务SFT之后,模型通用能力会降低,如只追求领域任务的效果,则不用考虑。 如果你的领域任务与通用任务有很大的相关性,那这种二阶段SFT会提升你的领域任务的效果。 如果你既追求领域任务的效果,并且希望通用能力不下降,建议选择base模型作为基座模型。在base模型上进行多任务混合训练,混合训练的时候需要关注各任务间的数据配比。
其他经验
- 在资源允许的情况下,如只考虑领域任务效果,我会选择模式二;
- 在资源允许的情况下,如考虑模型综合能力,我会选择模式五;
- 在资源不允许的情况下,我会考虑模式六;
- 一般情况下,我们不用进行RLHF微调;
开发工具库Transformers
Transformers是Hugging Face提供的Python库,Hugging Face是什么这里就不介绍了。国内可以通过镜像站访问:https://hf-mirror.com/ Transformers库的文档地址:https://hf-mirror.com/docs/transformers/index、 我们要关注那些内容呢?下边将会列举一些关键内容,详细内容请查阅官方文档。
Pipeline
Pipeline是一个用于模型推理的工具,它与模型训练关系不大,它主要是将预训练好的模型加载,推理预测使用的,我们了解它是什么即可。
AutoClass
AutoClass是一个比较重要的角色,主要是用来加载预训练模型的,通过from_pretrained()方法可以加载任意Hugging Face中的预训练模型和本地模型。
AutoTokenizer
几乎所有的NLP任务都以tokenizer开始,用它来加载模型对应的分词器。
AutoModel
真正来加载模型实例的是AutoModel,不同任务使用的AutoModel也不同,针对大语言模型一般使用AutoModelForCausalLM。
模型量化
量化技术专注于用较少的信息表示数据,同时尽量不损失太多准确性。 Transformers支持三种量化方法:AWQ、GPTQ、 BNB。底层细节我们不必研究 GPTQ是专为GPT模型设计的,AWQ适用于多种模型和任务,包括多模态语言模型。 BNB是将模型量化为8位和4位的最简单选择,4位量化可以与QLoRA一起用于微调量化LLM。
PEFT库
PEFT是Hugging Face提供的库,是一个为大型预训练模型提供多种高效微调方法的python库。 PEFT文档地址:https://hf-mirror.com/docs/peft/index PEFT可以轻松与Transformers库集成,一起完成模型微调的工作。 微调方式包括LoRA、AdaLoRA、P-tuning等。 补充说明:QLoRA是量化LoRA的缩写,需要把模型量化再进行训练,细节暂不研究。
LLaMA-Factory源码分析
从pt预训练开始
首先从分析pt预训练过程开始研究。 根据官方文档可知,预训练执行命令如下:
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py \
--stage pt \
--do_train \
--model_name_or_path path_to_llama_model \
--dataset wiki_demo \
--finetuning_type lora \
--lora_target q_proj,v_proj \
--output_dir path_to_pt_checkpoint \
--overwrite_cache \
--per_device_train_batch_size 4 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--logging_steps 10 \
--save_steps 1000 \
--learning_rate 5e-5 \
--num_train_epochs 3.0 \
--plot_loss \
--fp16参数说明
其中很多训练参数可能会看不懂,但没关系,先整体有个印象就行。--stage pt:指定训练阶段为预训练 --do_train:指定是训练任务 --model_name_or_path:本地模型的文件路径或 Hugging Face 的模型标识符 --dataset:指定数据集 --finetuning_type lora:指定微调方法为lora --lora_target q_proj,v_proj:Lora作用模块为q_proj,v_proj 此参数后续详解 --output_dir: 保存训练结果的路径 --overwrite_cache: 覆盖缓存的训练集和评估集 --per_device_train_batch_size 4: 每个gpu的批处理大小,训练参数 --gradient_accumulation_steps 4:梯度累计的步数,训练参数 --lr_scheduler_type cosine:学习率调度器,训练参数 --logging_steps 10:每两次日志输出间的更新步数,训练参数 --save_steps 1000:每两次断点保存间的更新步数,训练参数 --learning_rate 5e-5:学习率,adamW优化器的默认值为5e-5,训练参数 --num_train_epochs 3.0:需要执行的训练轮数,训练参数 --plot_loss:是否保存训练损失曲线 --fp16:使用fp16混合精度训练,此参数后续详解
lora_target
lora_target被设置到LoraConfig中的target_modules参数中,LoraConfig是PEFT库中提供的。 文档地址:https://hf-mirror.com/docs/peft/v0.9.0/en/package_reference/lora#peft.LoraConfig LLaMA-Factory框架中通过lora_target进行了封装,说明如下:
lora_target: str = field(
default="all",
metadata={
"help": """Name(s) of target modules to apply LoRA. \
Use commas to separate multiple modules. \
Use "all" to specify all the linear modules. \
LLaMA choices: ["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"], \
BLOOM & Falcon & ChatGLM choices: ["query_key_value", "dense", "dense_h_to_4h", "dense_4h_to_h"], \
Baichuan choices: ["W_pack", "o_proj", "gate_proj", "up_proj", "down_proj"], \
Qwen choices: ["c_attn", "attn.c_proj", "w1", "w2", "mlp.c_proj"], \
InternLM2 choices: ["wqkv", "wo", "w1", "w2", "w3"], \
Others choices: the same as LLaMA."""
},目前细节我们还无法理解,但可以通过以上说明进行对应的设置。 注意:经调试结果观察,Qwen1.5的lora_target与LLaMA choices相同。
混合精度训练
在深度学习中,混合精度训练是一种利用半精度浮点数(16位)和单精度浮点数(32位)混合计算的训练技术。传统上,神经网络训练过程中使用的是单精度浮点数,这需要更多的内存和计算资源。而混合精度训练通过将一部分计算过程转换为半精度浮点数来减少内存占用和加快计算速度。 FP16(半精度浮点数):FP16通常用于混合精度训练,其中大多数计算操作使用FP16来减少内存占用和加快计算速度。 BF16(bfloat16):BF16提供了更大的动态范围和更好的数值精度,相比于FP16更适合于保持梯度更新的稳定性。 FP32(单精度浮点数):传统神经网络训练中使用FP32来表示参数、梯度等数值,但相对于FP16和BF16,它需要更多的内存和计算资源。 Pure BF16(纯 bfloat16):这个术语通常用于强调使用纯粹的BF16格式,而不是在混合精度环境中与其他精度混合使用。使用纯BF16意味着所有的计算和存储都使用BF16格式。
理解源码
请自行配合源码阅读以下内容,文中不会粘贴完整源码。
源码入口
根据运行命令,我们可以从src/train_bash.py部分看起。 会进入src/llmtuner/train/pt/workflow.py中的run_pt方法中,
run_pt函数主要实现了以下功能: 加载tokenizer和dataset:根据传入的参数,使用load_tokenizer函数加载tokenizer,然后使用get_dataset函数根据tokenizer、model_args、data_args和training_args获取dataset。 加载模型:使用load_model函数根据tokenizer、model_args、finetuning_args和training_args的do_train参数加载模型。 初始化Trainer:使用CustomTrainer初始化一个Trainer实例,传入模型、参数、tokenizer、data_collator、callbacks和其他额外的参数。data_collator是通过调用DataCollatorForLanguageModeling类的实例化来创建一个数据整理器,主要用于自然语言处理任务中,将原始文本数据转换为模型可以输入的格式。 训练模型:如果training_args.do_train为True,则调用trainer的train方法进行训练,根据需要恢复checkpoint。训练完成后,保存模型、日志和状态。 评估模型:如果training_args.do_eval为True,则调用trainer的evaluate方法进行评估,并计算perplexity。然后记录和保存评估指标。 创建模型卡片:使用create_modelcard_and_push函数创建并推送模型卡片,其中包含了模型的相关信息和训练、评估结果。
开头的代码如下:
# 获取分词器
tokenizer = load_tokenizer(model_args)
# 获取数据集
dataset = get_dataset(tokenizer, model_args, data_args, training_args, stage="pt")
# 获取模型实例
model = load_model(tokenizer, model_args, finetuning_args, training_args.do_train)接下来我们将分析一下以上三部分的代码实现。
load_tokenizer
先来分析load_tokenizer方法:
def load_tokenizer(model_args: "ModelArguments") -> "PreTrainedTokenizer":
r"""
Loads pretrained tokenizer. Must before load_model.
Note: including inplace operation of model_args.
"""
try_download_model_from_ms(model_args)
init_kwargs = _get_init_kwargs(model_args)
# 核心方法在这,加载分词器内容,具体参数含义先忽略
tokenizer = AutoTokenizer.from_pretrained(
model_args.model_name_or_path,
use_fast=model_args.use_fast_tokenizer,
split_special_tokens=model_args.split_special_tokens,
padding_side="right",
**init_kwargs,
)
patch_tokenizer(tokenizer)
return tokenizerget_dataset
比较核心的方法其实是get_dataset,因为要训练模型,最重要的部分是组织训练数据。 函数主要执行以下操作:
- 根据提供的tokenizer、model_args、data_args和training_args参数,获取数据集的模板并进行一些预处理。
- 检查是否需要从缓存路径加载数据集,如果是,则加载并返回数据集。
- 如果缓存路径不存在,则根据data_args参数获取数据集列表,并加载每个数据集。
- 将所有加载的数据集合并为一个数据集。
- 对数据集进行预处理,包括使用tokenizer对数据进行编码、根据指定的stage进行额外的预处理。
- 如果指定的cache_path不为空,则将预处理后的数据集保存到cache_path路径。
- 如果指定should_log参数,则打印数据集的一个样本
这里内容比较多,我们一步一步来分析。
获取数据集模板
首先来分析一下获取数据集模板在做什么。可以进入以下路径查看代码。 src/llmtuner/data/template.py的get_template_and_fix_tokenizer方法。
函数主要做了以下几件事情:
- 根据输入的 name,获取相应的模板,如果没有提供 name 或提供的 name 不存在,则使用默认模板 "vanilla"。
- 如果模板指示需要替换 EOS(End of String)标记,且模板还指定了停用词,则取出第一个停用词在分词器中替换 EOS 标记。,并将剩余的停用词保存起来。
- 如果分词器中没有定义 EOS 标记,则在分词器中添加一个空EOS 标记"<|endoftext|>"。
- 如果分词器中没有定义 PAD 标记,则将 PAD 标记设置为与 EOS 标记相同的值,并在日志中记录。
- 如果模板指定了停用词,并且有剩余的停用词,则将这些停用词添加到分词器的特殊标记中,并在日志中记录。如果成功添加了新的特殊标记,则会发出警告提醒用户确认是否需要调整词汇表大小。
- 尝试将模板转换为 Jinja 模板,并将其与分词器相关联。
最后返回选定的模板对象。
这段代码内容有点多,我们先不考虑模板的事,先来理解一下分词器中对应的概念。
概念理解
首先我们理解一下什么是分词器。
在自然语言处理(NLP)中,分词器(tokenizer)是一个将文本输入分割成单词、子词或符号序列的工具。这个过程称为分词或者标记化。在 NLP 中,文本通常以字符串的形式存在,而计算机需要将其转换成可以处理的结构化数据形式,例如单词序列或标记序列,以便进行后续的语言处理任务,如词嵌入、语言模型训练、序列标注等。
那分词器的EOS 标记, PAD 标记,停用词分别代表什么呢?
- EOS 标记(End of String):
- EOS 标记通常用于表示序列的结束。在自然语言处理任务中,特别是序列到序列的任务(如机器翻译、文本生成等),需要在序列的末尾添加 EOS 标记以指示句子的结束。这有助于模型正确处理不同长度的输入序列。
- 在分词器中,EOS 标记用于标记化后的文本中表示句子结束的位置。
- PAD 标记(Padding):
- PAD 标记通常用于对不同长度的序列进行填充,使它们具有相同的长度。这在很多深度学习模型中是必要的,因为它们需要输入具有固定长度的序列。通过将序列填充到相同的长度,可以方便地将它们组成一个批次进行并行处理,提高训练效率。
- 在分词器中,PAD 标记用于填充序列,使其达到指定的最大长度。
- 停用词:
- 停用词是在自然语言处理任务中通常会被忽略的常见词语,因为它们通常不携带太多的信息。在一些任务中,特别是文本生成任务,停用词可能会影响模型的生成结果,因此需要在预处理阶段将其去除。
- 在分词器中,停用词通常被用作特殊的标记,例如 EOS 或 PAD 标记的替代。在一些情况下,停用词可能还会被添加到词汇表中作为特殊标记,以便模型学习到如何处理它们。
至于Jinja模板,这里就不过多介绍了,后边我们会去查看源码,看看在做什么的。
获取模板
理解了以上内容,我们回过头来分析一下最开始的根据name获取相应模板是怎么做到的,它获取到的模板到底是什么。 通过阅读源码,我们可以看到,模板就是一个字典:
templates: Dict[str, Template] = {}字典中的内容是通过_register_template方法注册进去的。我们来分析一下_register_template方法. 方法的入参比较多,我们可以分析各个参数的作用如下:
- name: 模板的名称。
- format_user: 用户对话部分的格式化器。
- format_assistant: AI 助手对话部分的格式化器。
- format_system: 系统对话部分的格式化器。
- format_function: 函数对话部分的格式化器。
- format_observation: 观察部分的格式化器。
- format_tools: 工具部分的格式化器。
- format_separator: 分隔符部分的格式化器。
- default_system: 默认系统消息。
- stop_words: 停用词列表。
- efficient_eos: 是否使用高效 EOS 标记。
- replace_eos: 是否替换 EOS 标记。
- force_system: 是否强制使用系统。
函数的主要工作是根据提供的参数创建对应的格式化器,并使用这些格式化器创建一个新的对话模板(Template 对象或 Llama2Template 对象),然后将该模板注册到全局变量 templates 中。 注意,这里的Template 对象或 Llama2Template 对象都是项目自定义的类。类中的内容我们先不看。 只要知道在初始化时,会调用此方法注册模板即可。 以qwen模板为例,在代码中我们可以看到如下注册模板的内容:
_register_template(
name="qwen",
format_user=StringFormatter(slots=["<|im_start|>user\n{{content}}<|im_end|>\n<|im_start|>assistant\n"]),
format_system=StringFormatter(slots=["<|im_start|>system\n{{content}}<|im_end|>\n"]),
format_separator=EmptyFormatter(slots=["\n"]),
default_system="You are a helpful assistant.",
stop_words=["<|im_end|>"],
replace_eos=True,
)根据入参,我们再重新查看_register_template方法的源码(请自行查看源码往下看): 首先,efficient_eos没有传参,默认值为False,以至于eos_slots为[],由此可以理解所谓的高效EOS标记,就是可能不需要额外的 EOS 标记,从而节省了内存和计算资源。 后续就是在实例化Template 对象返回。
转换为 Jinja 模板
接下来我们看一下转换Jinja模板做了什么。
该函数 _get_jinja_template 的作用是根据输入的模板和分词器生成一个 Jinja2 模板字符串。 首先,函数会判断模板中是否设置了默认系统消息,如果有,则将该消息添加到 Jinja2 模板中。 接着,函数会检查模板消息列表中是否存在系统消息,并将其内容赋值给变量 system_message。 然后,根据模板类型和是否强制显示系统消息,将 system_message 变量添加到 Jinja2 模板中。 接下来,函数会遍历模板消息列表,并根据消息的角色(用户或助手)将相应的内容添加到 Jinja2 模板中。 最后,函数返回生成的 Jinja2 模板字符串。 在处理过程中,函数会使用 _convert_slots_to_jinja 函数将模板中的占位符转换为对应的 Jinja2 表达式,并使用 PreTrainedTokenizer 对模板内容进行分词处理。
可以看到,Jinja2模板中支持if else 和 for,不过这些都不重要,我们只要知道组织好模板后将模板赋值给了tokenizer的chat_template属性即可。
获取数据集列表
接下来就是获取数据集列表的实现了。主要代码如下:
with training_args.main_process_first(desc="load dataset"):
all_datasets = []
for dataset_attr in get_dataset_list(data_args):
all_datasets.append(load_single_dataset(dataset_attr, model_args, data_args))
dataset = merge_dataset(all_datasets, data_args, training_args)这里先来关注get_dataset_list方法。
该函数用于获取数据集列表。根据输入的data_args参数中的dataset字段,将数据集名称列表进行处理并保存。然后从data_args参数中的dataset_dir目录下读取数据集配置文件DATA_CONFIG,并解析其中的内容。实际文件路径为data/dataset_info.json。 接下来,根据配置文件中定义的数据集信息,创建并填充DatasetAttr对象,并将其添加到dataset_list列表中。最后,返回dataset_list列表。 在创建DatasetAttr对象时,根据配置文件中的不同字段,选择不同的数据集类型和属性,并设置相应的属性值。 如果配置文件中定义了列名,则将其添加到DatasetAttr对象的属性中。 如果数据集格式为sharegpt,并且配置文件中定义了标签信息,则将其添加到DatasetAttr对象的属性中。 如果在读取配置文件时发生异常,将抛出相应的异常。
现在我们知道get_dataset_list方法会返回数据集的一些元数据,load_single_dataset方法就会根据元数据来加载真正的数据了。
get_dataset_list根据给定的dataset_attr、model_args和data_args参数加载单个数据集。根据dataset_attr.load_from的值,函数从不同的来源加载数据集。支持的来源包括"Hugging Face Hub"、"ModelScope Hub"、脚本或文件。 当从"Hugging Face Hub"或"ModelScope Hub"加载数据集时,函数会使用相应的库加载数据集。 当从脚本或文件加载数据集时,函数会根据文件类型选择合适的方式加载数据。 函数还支持数据集的截断和对齐操作。
其中加载数据到内容的代码如下:
dataset = load_dataset(
path=data_path,
name=data_name,
data_dir=data_dir,
data_files=data_files,
split=data_args.split,
cache_dir=model_args.cache_dir,
token=model_args.hf_hub_token,
streaming=(data_args.streaming and (dataset_attr.load_from != "file")),
**kwargs,
)这部分使用的是Hugging Face的datasets库来进行加载的。具体使用方法可以参考官网。 https://hf-mirror.com/docs/datasets/index 这里就不介绍了。 后续使用align_dataset对数据集进行转换后返回单个数据集的结果
align_dataset函数用于对给定的dataset进行格式转换,使其符合指定的dataset_attr属性要求。 该函数根据dataset_attr的格式要求选择不同的转换函数(convert_alpaca或convert_sharegpt),并为转换后的数据集定义了特定的特征字典(features)。 转换函数将对数据集中的每个样本进行处理,重新组织其字段,并添加额外的"prompt"、"response"、"system"和"tools"字段。 处理过程中,可以选择是否使用批处理,并可以指定并行处理的工作线程数、是否从缓存文件加载以及是否覆盖缓存文件等参数。最终返回转换后的数据集。
具体的转换逻辑我们先不用看了,知道是转换成一种方便训练的格式就可以了。 后续预处理的逻辑我们也先不用看,大体了解会使用tokenizer对数据进行处理就可以了。
load_model
数据准备就绪,接下来就是加载模型了。
函数首先通过model_args.model_name_or_path使用AutoConfig获取模型的配置和初始化参数,然后根据是否可训练和是否使用unsloth选择不同的模型加载方式。 如果可训练且使用unsloth,则使用FastLanguageModel.from_pretrained加载模型; 否则,使用AutoModelForCausalLM.from_pretrained加载模型。 接着,函数会对模型进行一些修改和注册,然后根据是否添加值头(value head)来初始化或修改模型。 最后,函数将模型设置为相应的模式(可训练或不可训练),并返回模型。 参数说明: tokenizer: 预训练的分词器。 model_args: 模型参数,包括模型名称、最大序列长度、计算数据类型等。 finetuning_args: 微调参数。 is_trainable: 模型是否可训练,默认为False。 add_valuehead: 是否添加值头,默认为False。 返回值: model: 加载的预训练模型。
其中比较核心的就是对模型进行的一些修改和注册了。这部分代码如下:
patch_model(model, tokenizer, model_args, is_trainable)
register_autoclass(config, model, tokenizer)
model = init_adapter(model, model_args, finetuning_args, is_trainable)接下来会进入内部了解一下具体对模型做了哪些修改。
概念理解
这里我们看到了新的概念,unsloth。所以我们先来理解一下新概念。 通过观察LLaMA-Factory的可视化页面中高级设置,可以看到加速方式。加速方式包括flashattn和unsloth,那它们代表什么呢?
"unsloth" 和 "flashattn" 是两种不同的加速技术,通常用于优化神经网络模型的推理速度。
- Unsloth: Unsloth 是一种基于量化的加速技术,它的主要思想是通过减少模型参数的精度来降低计算的复杂度,从而提高推理速度。在 Unsloth 中,通常会将模型参数从浮点数转换为低精度的整数或定点数。这样可以降低模型的存储需求,并且在推理时减少了浮点运算的开销,从而加快了模型的推理速度。不过,由于参数精度的降低可能会带来一定的精度损失,因此在选择使用 Unsloth 技术时需要权衡推理速度和模型精度之间的关系。
- FlashAttn: FlashAttn 是一种用于加速注意力机制(attention mechanism)的技术。注意力机制在深度学习模型中广泛应用于处理序列数据,例如机器翻译、文本生成等任务。然而,由于注意力机制的计算量较大,它可能成为模型推理速度的瓶颈。FlashAttn 通过优化注意力计算的方式来加速模型推理过程。具体来说,FlashAttn 可能采用一些技巧,例如降低注意力矩阵的计算复杂度、减少注意力头的数量、或者采用特定的注意力结构等。这些技巧可以有效地减少模型推理时的计算量,从而加速推理速度。
简单来说,Unsloth 和 FlashAttn 都是用于加速神经网络模型推理过程的技术,但它们的具体实现和优化方式有所不同,适用于不同类型的模型和应用场景。
patch_model
patch_model函数用于根据不同的模型类型和参数,对模型和分词器进行一系列的修改和配置。 具体包括以下几个方面:
如果模型的generate方法不是GenerationMixin的子类,则将其替换为PreTrainedModel.generate方法。 如果模型配置中的model_type为"chatglm",则设置模型的lm_head为transformer.output_layer,并设置保存模型时忽略lm_head.weight。(chatglm需要一些特殊处理,我们暂不关心) 如果model_args.resize_vocab为True,则调用_resize_embedding_layer函数来调整嵌入层的大小。 如果模型是可训练的,则调用_prepare_model_for_training函数对模型进行训练前的准备。 如果模型配置中的model_type为"mixtral"且启用了DeepSpeed的Zero3优化器,则导入set_z3_leaf_modules和MixtralSparseMoeBlock,并调用set_z3_leaf_modules函数将model中的叶子模块设置为MixtralSparseMoeBlock。如果模型是可训练的,则调用patch_mixtral_replace_moe_impl函数。 尝试向模型添加标签"llama-factory",如果添加失败则打印警告信息。 这些修改和配置的目的是为了适应不同模型的需求,提高模型的性能和效率。
我们如果使用qwen模型,主要需要观察_prepare_model_for_training函数对模型做了哪些准备。
该函数主要为模型训练做准备,具体包括以下操作: 如果model_args.upcast_layernorm为True,则将模型中的层归一化(layernorm)权重转换为float32类型。 如果model_args.disable_gradient_checkpointing为False且模型支持梯度检查点(gradient checkpointing),则启用梯度检查点,并设置相关属性。 如果模型具有output_layer_name属性且model_args.upcast_lmhead_output为True,则将语言模型头(lm_head)的输出转换为float32类型
这里的概念可能不是太懂,可以先了解个大概即可。
register_autoclass
这个方法的代码如下:
def register_autoclass(config: "PretrainedConfig", model: "PreTrainedModel", tokenizer: "PreTrainedTokenizer"):
if "AutoConfig" in getattr(config, "auto_map", {}):
config.__class__.register_for_auto_class()
if "AutoModelForCausalLM" in getattr(config, "auto_map", {}):
model.__class__.register_for_auto_class()
if "AutoTokenizer" in tokenizer.init_kwargs.get("auto_map", {}):
tokenizer.__class__.register_for_auto_class()就是字面意思,注册Transformers框架中的自动类,具体用处目前还不明确。
init_adapter
init_adapter函数用于初始化适配器,并支持全参数、冻结和LoRA训练。根据传入的模型、模型参数、微调参数和是否可训练,该函数将根据微调类型对模型进行相应的处理。此方法属于比较核心的方法
如果模型不可训练且没有指定适配器名称路径,则加载基本模型。 如果微调类型为"full"且模型可训练,则将模型参数转换为float32类型。 如果微调类型为"freeze"且模型可训练,则根据num_layer_trainable和其他参数来确定可训练的层,并将其他层的参数设置为不可训练。可训练的层可以是最后n层、前面n层或指定的层。 如果微调类型为"lora",则根据是否指定适配器名称路径和其他参数来加载、合并和恢复LoRA模型,并创建新的LoRA权重。 最终,该函数返回处理后的模型
这部分代码内容还是比较多的,full和freeze我们不用关注,重点关注lora部分。由于这部分比较重要,我把lora部分代码放到下边,并用注释解释一下:
if finetuning_args.finetuning_type == "lora":
logger.info("Fine-tuning method: {}".format("DoRA" if finetuning_args.use_dora else "LoRA"))
adapter_to_resume = None
# 这部分是可以通过adapter_name_or_path路径,来进行进行增量的训练,增量逻辑我们可以先不看,代码没有放到这里
if model_args.adapter_name_or_path is not None:...
# 重点内容在这里
if is_trainable and adapter_to_resume is None: # create new lora weights while training
if len(finetuning_args.lora_target) == 1 and finetuning_args.lora_target[0] == "all":
# 通过调试,可以在这里看到模型所有的lora_target
target_modules = find_all_linear_modules(model)
else:
target_modules = finetuning_args.lora_target
# 这里通过可视化页面,可以看到解释:仅训练块扩展后的参数。细节我们先不看
if finetuning_args.use_llama_pro:
target_modules = find_expanded_modules(model, target_modules, finetuning_args.num_layer_trainable)
# 这里验证了使用dora的时候,如果使用了量化,必须是使用BNB方式,否则不支持
if finetuning_args.use_dora and getattr(model, "quantization_method", None) is not None:
if getattr(model, "quantization_method", None) != QuantizationMethod.BITS_AND_BYTES:
raise ValueError("DoRA is not compatible with PTQ-quantized models.")
peft_kwargs = {
"r": finetuning_args.lora_rank,
"target_modules": target_modules,
"lora_alpha": finetuning_args.lora_alpha,
"lora_dropout": finetuning_args.lora_dropout,
"use_rslora": finetuning_args.use_rslora,
}
# 这里使用了unsloth加速,在之前的章节中有讲到
if model_args.use_unsloth:
from unsloth import FastLanguageModel # type: ignore
unsloth_peft_kwargs = {"model": model, "max_seq_length": model_args.model_max_length}
model = FastLanguageModel.get_peft_model(**peft_kwargs, **unsloth_peft_kwargs)
else:
# 组织LoraConfig
lora_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
inference_mode=False,
modules_to_save=finetuning_args.additional_target,
use_dora=finetuning_args.use_dora,
**peft_kwargs,
)
# 加载模型
model = get_peft_model(model, lora_config)
# 这里的pure_bf16在前边章节页讲过,混合精度训练的一种模式
if not finetuning_args.pure_bf16:
for param in filter(lambda p: p.requires_grad, model.parameters()):
param.data = param.data.to(torch.float32)通过阅读以上源码和注释,想要更好的理解,需要解决下边的问题。
- lora_target应该怎么设置比较合适?
- dora是什么?
- LoraConfig应该怎么配置更合适?
想要解决这些问题,我们应该去了解一下LoraConfig。
解读LoraConfig
首先,LoraConfig属于PEFT库。所以可以阅读一下官方文档,来理解一下Lora,地址如下: https://hf-mirror.com/docs/peft/developer_guides/lora 通过阅读这部分文档,我们可以对Lora整体有了一个认识。 之后我们可以阅读这部分内容,来理解一下LoraConfig中每个参数的作用。 https://hf-mirror.com/docs/peft/package_reference/lora 回到我们自己的代码中,现在可以解释一下这部分代码具体的含义了:
peft_kwargs = {
"r": finetuning_args.lora_rank,
"target_modules": target_modules,
"lora_alpha": finetuning_args.lora_alpha,
"lora_dropout": finetuning_args.lora_dropout,
"use_rslora": finetuning_args.use_rslora,
}
lora_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
inference_mode=False,
modules_to_save=finetuning_args.additional_target,
use_dora=finetuning_args.use_dora,
**peft_kwargs,
)task_type:此参数不是LoraConfig的参数,而是它的父类PeftConfig的参数,可选值为TaskType中的值,具体的含义是什么呢?我们可以直接看源码:class TaskType(str, enum.Enum):
"""
Enum class for the different types of tasks supported by PEFT.
Overview of the supported task types:
- SEQ_CLS: Text classification.
- SEQ_2_SEQ_LM: Sequence-to-sequence language modeling.
- CAUSAL_LM: Causal language modeling.
- TOKEN_CLS: Token classification.
- QUESTION_ANS: Question answering.
- FEATURE_EXTRACTION: Feature extraction. Provides the hidden states which can be used as embeddings or features
for downstream tasks.
"""
SEQ_CLS = "SEQ_CLS"
SEQ_2_SEQ_LM = "SEQ_2_SEQ_LM"
CAUSAL_LM = "CAUSAL_LM"
TOKEN_CLS = "TOKEN_CLS"
QUESTION_ANS = "QUESTION_ANS"
FEATURE_EXTRACTION = "FEATURE_EXTRACTION"可以看到,其实就是在指定任务类型是大语言模型。 inference_mode:此参数也是父类PeftConfig的参数,表示模型是否是推理模型,由于我们要进行训练,所以设置为False modules_to_save:除 LoRA 层以外的可训练模块名称,我们先不用管这里。 use_dora:使用权重分解的 LoRA。 r:lora微调的维度,我们默认设置的是8。 target_modules:就是要微调的模块,前边已经有介绍。 lora_alpha:LoRA微调的缩放因子,默认为r * 2。 lora_dropout: LoRA微调的随机丢弃率。了解过深度学习的一定可以理解这个指标。 use_rslora:是否使用LoRA层的秩稳定缩放因子,阅读官网可以理解为:将适配器的缩放因子设置为 lora_alpha/math.sqrt(r) ,因为它被证明工作得更好。 否则,它将使用原始的默认值 lora_alpha/r 。 至此,目前我们已经理解了项目中使用到的参数。 其他内容可根据官方文档理解。
模型训练部分
前边的内容只是训练的前提,接下来我们就来看一下训练部分的实现。 我们回到src/llmtuner/train/pt/workflow.py中的run_pt方法中继续往下看。这里我把核心源码直接放到下边。
# 部分主要是对数据转换,转换成模型可以输入的格式。
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False)
# Initialize our Trainer
trainer = CustomTrainer(
model=model,
args=training_args,
finetuning_args=finetuning_args,
tokenizer=tokenizer,
data_collator=data_collator,
callbacks=callbacks,
#就是数据集的拆分(训练集/测试集)
**split_dataset(dataset, data_args, training_args),
)
# Training
if training_args.do_train:
# 开始训练,resume_from_checkpoint可以是字符串或布尔值,如果为字符串,则是本地保存的检查点的路径,如果为布尔值且为True,则加载args.output_dir中由之前的[Trainer]实例保存的最后一个检查点。如果存在,则从加载的模型/优化器/调度器状态继续训练。
train_result = trainer.train(resume_from_checkpoint=training_args.resume_from_checkpoint)
# 保存模型
trainer.save_model()
# 记录指标日志
trainer.log_metrics("train", train_result.metrics)
# 保存指标日志
trainer.save_metrics("train", train_result.metrics)
# 保存训练状态
trainer.save_state()
# 如果是主进程,且plot_loss参数为True,则保存损失曲线图
if trainer.is_world_process_zero() and finetuning_args.plot_loss:
plot_loss(training_args.output_dir, keys=["loss", "eval_loss"])首先我们先来理解一下DataCollatorForLanguageModeling,可以阅读官网文档进行理解,地址如下: https://hf-mirror.com/docs/transformers/v4.39.1/zh/main_classes/data_collator 简单来说就是转换成模型可以输入的格式。 CustomTrainer是一个比较重要的内容,接下来我们将对它进行解读。
解读CustomTrainer
CustomTrainer继承自Trainer类,并且重写了create_optimizer_and_scheduler方法。
create_optimizer_and_scheduler方法用于创建自定义的优化器和学习率调度器。它首先调用create_custom_optimzer函数来创建优化器,该函数根据模型、参数和finetuning_args来决定如何创建优化器。如果create_custom_optimzer返回None,则调用Trainer类的create_optimizer方法来创建优化器。
我们可以看一下create_custom_optimzer的底层实现,代码内容不多,直接放到下边:
def create_custom_optimzer(
model: "PreTrainedModel",
training_args: "Seq2SeqTrainingArguments",
finetuning_args: "FinetuningArguments",
max_steps: int,
) -> Optional["torch.optim.Optimizer"]:
if finetuning_args.use_galore:
return _create_galore_optimizer(model, training_args, finetuning_args, max_steps)
if finetuning_args.loraplus_lr_ratio is not None:
return _create_loraplus_optimizer(model, training_args, finetuning_args)如何创建自定义优化器我们先不研究,目前我们还用不到。 要研究的重点其实是Trainer类,Trainer是Transformers库中比较重要的一部分。可以阅读官方文档进行了解:https://hf-mirror.com/docs/transformers/v4.39.1/zh/main_classes/trainer 接下来我们分析一下代码中传入的参数的含义:
model:这个不用太解释,就是传入之前加载的模型 args=training_args:这个training_args实际上是Transformers库中的Seq2SeqTrainingArguments,这其中包含的参数就比较多了。 finetuning_args:这个参数是自定义的参数,我们不关注。 tokenizer、data_collator:这两个参数不再解释,你应该也能看懂了。 callbacks:指定回调函数,LLaMA-Factory指定了一个打印日志的回调函数。 split_dataset:这是自定义的函数,用来做数据拆分,实现细节我们先不看,主要就是返回split_dataset参数和eval_dataset参数,分别用来表示训练的数据集和评估的数据集,是Trainer类自带的参数。
至此,对CustomTrainer我们已经有了整体的认识。
解读Seq2SeqTrainingArguments
为了更进一步的了解训练参数,我们可以看一下Seq2SeqTrainingArguments中都有哪些参数。官方文档地址如下: https://hf-mirror.com/docs/transformers/v4.39.1/en/main_classes/trainer#transformers.Seq2SeqTrainingArguments 由于参数太多了,就不挨个参数解读了,只解释一些我们常用到的参数,其他参数详见官方文档:
output_dir :输出目录,将写入模型预测和检查点。 overwrite_output_dir:如果设置为 True,将覆盖输出目录中的内容。可以在 output_dir 指向检查点目录时使用此选项继续训练。 do_train :是否进行训练。这个参数不是直接由 [Trainer] 使用的 do_eval:是否在验证集上运行评估。如果 evaluation_strategy 不是 "no" ,将被设置为 True。这个参数不是直接由 [Trainer] 使用的 do_predict:是否在测试集上进行预测。这个参数不是直接由 [Trainer] 使用的 evaluation_strategy :训练过程中采用的评估策略。可能的取值有: "no": 不进行评估。 "steps": 每隔 eval_steps 进行评估。 "epoch": 每个 epoch 结束时进行评估 per_device_train_batch_size (int,可选,默认为 8):每个 GPU/TPU 核心/CPU 的训练批次大小。 per_device_eval_batch_size (int,可选,默认为 8):每个 GPU/TPU 核心/CPU 的评估批次大小。 gradient_accumulation_steps (int,可选,默认为 1):在执行反向传播/更新步骤之前,累积梯度的更新步骤数。
模型评估部分
直接看剩余部分的代码,理解了之前训练部分的代码,评估部分代码很容易就能看懂。
# Evaluation
if training_args.do_eval:
# 评估
metrics = trainer.evaluate(metric_key_prefix="eval")
try:
# 计算困惑度,困惑度是自然语言处理领域常用的评价模型生成或预测文本的能力的指标,它是损失函数指数运算的结果。越低代表模型越好。
perplexity = math.exp(metrics["eval_loss"])
except OverflowError:
perplexity = float("inf")
metrics["perplexity"] = perplexity
trainer.log_metrics("eval", metrics)
trainer.save_metrics("eval", metrics)总结
至此,我们已经打通了pt预训练这条通道,接下来我们就要开始查看sft指令微调部分的实现了。
sft指令微调
首先我们还是查看官方文档提供的sft脚本,内容如下:
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py \
--stage sft \
--do_train \
--model_name_or_path path_to_llama_model \
--dataset alpaca_gpt4_zh \
--template default \
--finetuning_type lora \
--lora_target q_proj,v_proj \
--output_dir path_to_sft_checkpoint \
--overwrite_cache \
--per_device_train_batch_size 4 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--logging_steps 10 \
--save_steps 1000 \
--learning_rate 5e-5 \
--num_train_epochs 3.0 \
--plot_loss \
--fp16可以发现,只有--stage被设置成了sft,其他参数之前已经介绍过了。 所以我们直接开始查看源码。
理解源码
有了之前的经验,源码入口可以很快找到。 即src/llmtuner/train/sft/workflow.py中的run_sft方法中。这里我直接把完整代码放到下边:
def run_sft(
model_args: "ModelArguments",
data_args: "DataArguments",
training_args: "Seq2SeqTrainingArguments",
finetuning_args: "FinetuningArguments",
generating_args: "GeneratingArguments",
callbacks: Optional[List["TrainerCallback"]] = None,
):
tokenizer = load_tokenizer(model_args)
# 数据预处理部分有变化,后期可以进入查看一下
dataset = get_dataset(tokenizer, model_args, data_args, training_args, stage="sft")
model = load_model(tokenizer, model_args, finetuning_args, training_args.do_train)
if training_args.predict_with_generate:
tokenizer.padding_side = "left" # use left-padding in generation
if getattr(model, "is_quantized", False) and not training_args.do_train:
setattr(model, "_hf_peft_config_loaded", True) # hack here: make model compatible with prediction
data_collator = DataCollatorForSeq2Seq(
tokenizer=tokenizer,
pad_to_multiple_of=8 if tokenizer.padding_side == "right" else None, # for shift short attention
label_pad_token_id=IGNORE_INDEX if data_args.ignore_pad_token_for_loss else tokenizer.pad_token_id,
)
# Override the decoding parameters of Seq2SeqTrainer
training_args.generation_max_length = training_args.generation_max_length or data_args.cutoff_len
training_args.generation_num_beams = data_args.eval_num_beams or training_args.generation_num_beams
# Initialize our Trainer
# trainer使用了CustomSeq2SeqTrainer,这是一个比较大的变化
trainer = CustomSeq2SeqTrainer(
model=model,
args=training_args,
finetuning_args=finetuning_args,
tokenizer=tokenizer,
data_collator=data_collator,
callbacks=callbacks,
compute_metrics=ComputeMetrics(tokenizer) if training_args.predict_with_generate else None,
**split_dataset(dataset, data_args, training_args),
)
# Keyword arguments for `model.generate`
gen_kwargs = generating_args.to_dict()
gen_kwargs["eos_token_id"] = [tokenizer.eos_token_id] + tokenizer.additional_special_tokens_ids
gen_kwargs["pad_token_id"] = tokenizer.pad_token_id
gen_kwargs["logits_processor"] = get_logits_processor()
# Training
if training_args.do_train:
train_result = trainer.train(resume_from_checkpoint=training_args.resume_from_checkpoint)
trainer.save_model()
trainer.log_metrics("train", train_result.metrics)
trainer.save_metrics("train", train_result.metrics)
trainer.save_state()
if trainer.is_world_process_zero() and finetuning_args.plot_loss:
plot_loss(training_args.output_dir, keys=["loss", "eval_loss"])
# Evaluation
if training_args.do_eval:
metrics = trainer.evaluate(metric_key_prefix="eval", **gen_kwargs)
if training_args.predict_with_generate: # eval_loss will be wrong if predict_with_generate is enabled
metrics.pop("eval_loss", None)
trainer.log_metrics("eval", metrics)
trainer.save_metrics("eval", metrics)
# Predict
# 多了一个预测推理阶段,基本过程都是一样的,只不过调用了trainer.predict方法
if training_args.do_predict:
predict_results = trainer.predict(dataset, metric_key_prefix="predict", **gen_kwargs)
if training_args.predict_with_generate: # predict_loss will be wrong if predict_with_generate is enabled
predict_results.metrics.pop("predict_loss", None)
trainer.log_metrics("predict", predict_results.metrics)
trainer.save_metrics("predict", predict_results.metrics)
trainer.save_predictions(predict_results)
# Create model card
create_modelcard_and_push(trainer, model_args, data_args, training_args, finetuning_args)发现了什么? 没错,代码结构基本与之前的预训练部分差不多。 只有在get_dataset处理数据部分,会有所差异,具体差异我们暂时不看,只要知道sft阶段数据预处理时,是需要增加指令、角色信息的就可以了。 实际上,如果选择使用LLaMA-Factory进行微调,我们按照LLaMA-Factory的数据集格式要求准备数据就可以了。
解读CustomSeq2SeqTrainer
这阶段除了预处理数据部分有差别,最大的差别就是训练器与之前不同,使用的是CustomSeq2SeqTrainer, CustomSeq2SeqTrainer是Seq2SeqTrainer的子类,而Seq2SeqTrainer是Trainer的子类。 Seq2SeqTrainer的源码我们就不去仔细阅读了,简单阅读后发现,Seq2SeqTrainer主要是重写了Trainer的评估和推理的方法,没有重写训练方法,所以与使用Trainer进行训练应该差别不大。 这里为什么使用Seq2SeqTrainer,我们不必纠结。 阅读qwen1.5官方提供的sft示例,可以看到示例中使用的也是Trainer而不是Seq2SeqTrainer。 示例地址:https://github.com/QwenLM/Qwen1.5/blob/main/examples/sft/finetune.py
总结
可以发现,理解了pt阶段后,再来理解sft阶段其实是很容易的,一通百通,sft阶段我们就介绍到这里,如果你对哪部分感兴趣,可以自己去阅读源码,相信有了pt阶段的知识储备后,你可以很容易的阅读源码了。 另外,我们只要懂得pt与sft微调,就能实际上手微调了。所以后续的RLHF阶段就先不去查看了。
微调实践
我们已经理解了大模型微调的基本过程,但实践是检验真理的唯一标准,所以接下来将与大家一起对大模型微调进行实践,观察一下微调效果。 注意:UI界面的使用请阅读官方文档,这里不会介绍UI如何使用。 https://github.com/hiyouga/LLaMA-Factory/blob/main/README_zh.md
数据集准备
根据LLaMA-Factory官方提供的数据准备文档,可以看到训练数据的格式。地址如下: https://github.com/hiyouga/LLaMA-Factory/blob/main/data/README_zh.md 文档中比较重要的说明部分:
对于预训练数据集,仅 prompt 列中的内容会用于模型训练。 对于偏好数据集,response 列应当是一个长度为 2 的字符串列表,排在前面的代表更优的回答
偏好数据集是用在奖励建模阶段的。
本次微调选择了开源项目数据集,地址如下: https://github.com/KMnO4-zx/huanhuan-chat/blob/master/dataset/train/lora/huanhuan.json 下载后,将json文件存放到LLaMA-Factory的data目录下。 修改dataset_info.json 文件。 直接增加以下内容即可:
"huanhuan": {
"file_name": "huanhuan.json"
}添加后,在UI页面中直接可以看到新增加的数据集:
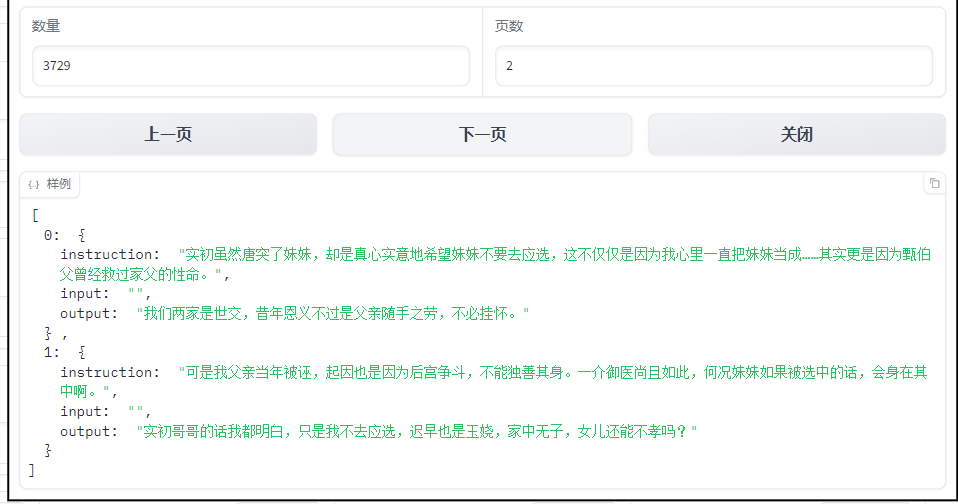
image.png
开始微调
为了减少资源消耗,本次选择测试的模型是Qwen1.5-0.5B-Chat。 通过可视化页面配置后,可以得到微调命令如下:
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py \
--stage sft \
--do_train True \
--model_name_or_path /home/jqxxuser/model/Qwen1.5-0.5B-Chat \
--finetuning_type lora \
--template qwen \
--dataset_dir data \
--dataset huanhuan \
--cutoff_len 1024 \
--learning_rate 5e-05 \
--num_train_epochs 2.0 \
--max_samples 100000 \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 8 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 5 \
--save_steps 100 \
--warmup_steps 0 \
--optim adamw_torch \
--output_dir saves/Qwen1.5-0.5B-Chat/lora/train_2024-03-28-10-54-09 \
--fp16 True \
--lora_rank 8 \
--lora_alpha 16 \
--lora_dropout 0.1 \
--lora_target q_proj,v_proj \
--plot_loss True说明:SFT阶段是最常用训练阶段,所以我们在SFT阶段进行微调,测试效果。 我们直接在UI中点击开始即可进行微调,可以观察到整个的过程,发现损失值在逐渐降低。
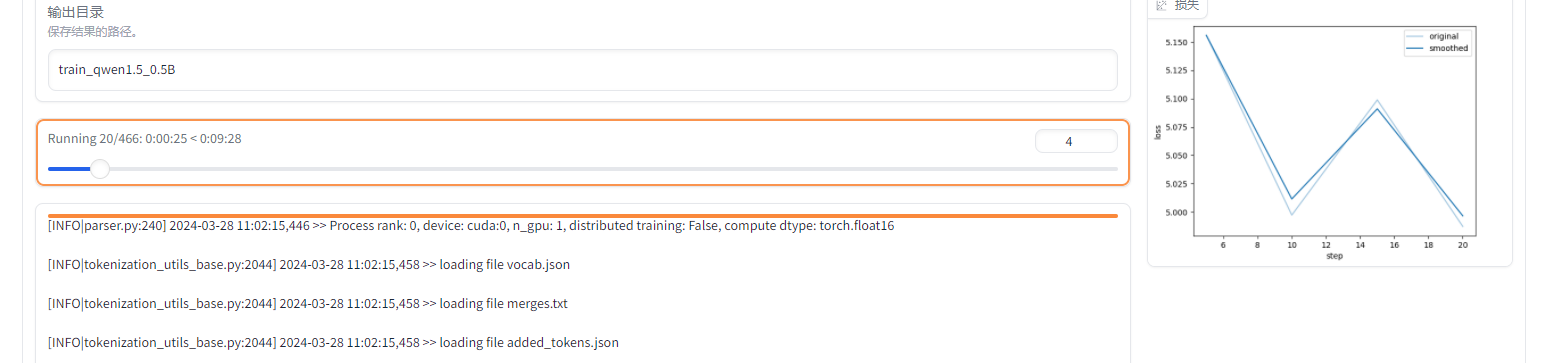
image.png
等待训练完毕即可。
测试聊天效果
刷新适配器,可以看到我们刚刚训练完的模型,选择即可

image.png
选择Chat功能,加载模型后即可开始聊天。

image.png
看看效果吧:
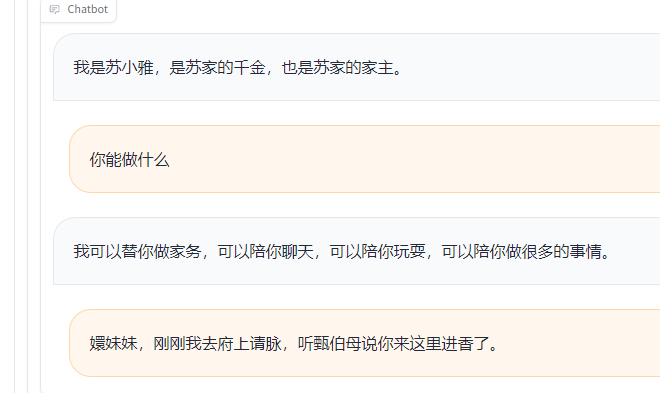
image.png
目测效果还可以,至少我们看到模型确实发生了改变。
评估模型
通过聊天观察效果是一种直观的感觉,我们可以在通过项目自带的评估功能做一下评估。 注意,如果报错,需要确保安装了以下库。 jieba rouge-chinese nltk
image.png
运行后可以在目录中看到评估指标:
{
"predict_bleu-4": 2.487403191204076,
"predict_rouge-1": 16.790678761061947,
"predict_rouge-2": 1.1607781979082865,
"predict_rouge-l": 14.878193322606597,
"predict_runtime": 900.9563,
"predict_samples_per_second": 4.139,
"predict_steps_per_second": 1.38
}这些指标应该怎么看呢?首先我们来了解一下这些指标的概念。
- predict_bleu-4:
- BLEU(Bilingual Evaluation Understudy)是一种常用的用于评估机器翻译质量的指标。
- BLEU-4 表示四元语法 BLEU 分数,它衡量模型生成文本与参考文本之间的 n-gram 匹配程度,其中 n=4。
- 值越高表示生成的文本与参考文本越相似,最大值为 100。
- predict_rouge-1 和 predict_rouge-2:
- ROUGE(Recall-Oriented Understudy for Gisting Evaluation)是一种用于评估自动摘要和文本生成模型性能的指标。
- ROUGE-1 表示一元 ROUGE 分数,ROUGE-2 表示二元 ROUGE 分数,分别衡量模型生成文本与参考文本之间的单个词和双词序列的匹配程度。
- 值越高表示生成的文本与参考文本越相似,最大值为 100。
- predict_rouge-l:
- ROUGE-L 衡量模型生成文本与参考文本之间最长公共子序列(Longest Common Subsequence)的匹配程度。
- 值越高表示生成的文本与参考文本越相似,最大值为 100。
- predict_runtime:
- 预测运行时间,表示模型生成一批样本所花费的总时间。
- 单位通常为秒。
- predict_samples_per_second:
- 每秒生成的样本数量,表示模型每秒钟能够生成的样本数量。
- 通常用于评估模型的推理速度。
- predict_steps_per_second:
- 每秒执行的步骤数量,表示模型每秒钟能够执行的步骤数量。
- 对于生成模型,一般指的是每秒钟执行生成操作的次数。
所以,单独看指标数据的话,模型的效果并不是太好,这就需要大家自行摸索如何让模型能力更好了。
导出模型
切换到Export选项卡,指定导出目录,点击开始导出,即可导出模型。
image.png
导出后的模型与其他大模型的使用方法一致。
总结
至此,我们的一次模型微调的尝试就完成了。 可以发现,使用LLaMA-Factory进行微调基本上可以做到傻瓜式操作了。最大的工作量还是在组织训练数据这个阶段。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2024-04-17,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号