大型电商平台如何抗住亿级流量之布隆过滤器



前言
很久没写文章了,今天来学习下大名鼎鼎的 布隆过滤器 。
正文
什么是布隆过滤器
这个牛轰轰的神器是布隆这位大牛在 1970 年发明的,是一个二进制向量数据结构,当时专门解决数据查询问题。可以用来告诉你 某样东西一定不存在或者可能存在。
相比于传统的 List、Set、Map 等数据结构,它更高效、占用空间更少,但是缺点是其返回的结果是概率性的,而不是确切的。
布隆过滤器有什么用
说起布隆过滤器的作用可以大家可能首先想到的就是Redis缓存穿透,那我们先来说说什么是缓存穿透?
你肯定上过京东、淘宝这样的购物网站,不知有没有注意过:在我们日常开发中,其实每一个页面的 URL 网址是和具体的商品对应的。
比如说,当前我标红的 857,就是我们商品的 sku 编号,你可以理解为是这个商品型号的唯一编码。这里商品编号为 857,那显示的页面自然也是对应的内容。
比如在 618 当天,数亿网友 shopping 剁手时,商城应用同时收到海量请求,要求访问、下单、支付,这时机器如何顶得住呢?这就涉及我们系统的架构了,来看一下。
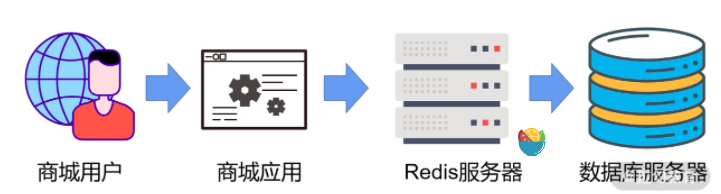
首先作为商城的用户,他发起一个请求,比如这里还是要查看 857 号的商品。
这时作为商城应用程序,它会向后台的 Redis 缓存服务器进行查询。
如果缓存数据库中没有 857 号的商品数据,我们程序就需要在后台的数据库服务器中进行查询,并且填充至 Redis 服务器,这是一个正常的操作流程。
那么在长时间积累后,我们的缓存服务器里面的数据可能就是这个样子的。为了好理解,这里我假设商城有 1000 件商品,编号从 1~1000。
此时此刻作为商城用户,如果查询 857 号商品时,商城应用就不再需要从 MySQL 数据库中进行数据提取,直接从 Redis 服务器中将数据提取并返回就可以了。因为 Redis 它是基于内存的,无论是从吞吐量还是处理速度来说,都要比传统的 MySQL 数据库快很多倍。
随着时间不断积累,那么在 Redis 的服务器中应该会存储编号从 1~1000 的所有商品数据缓存。
Redis 面临的安全隐患:缓存穿透
大家请注意当前缓存中只有 1~1000 号数据。 假设如果是同行恶意竞争,或者由第三方公司研发了爬虫机器人,在短时间内批量的进行数据查询,而这些查询的编号则是之前数据库中不存在的,比如现在看到的 8888、8889、8890 这些都是不存在的。
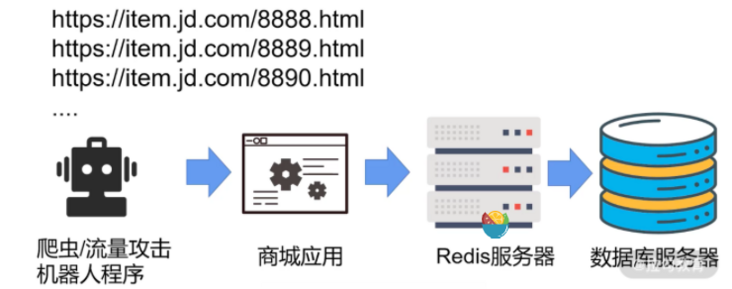
此时我们系统就会遇到一个重大的安全隐患:因为商城应用在向后台 Redis 查询时,由于缓存中没有这条数据,它就进而到了数据库服务器中进行查询。
【无效请求超高并发,会导致崩溃】
要知道数据库服务器对于瞬时超高并发的访问承载能力并不强。所以在短时间内,由爬虫机器人或者流量攻击机器人发来的这些无效的请求,都会瞬间的灌入到数据库服务器中,对我们的系统的性能造成极大的影响,甚至会产生系统崩溃。
而这种绕过 Redis 服务器,直接进入后台数据库查询的攻击方式,我们就称之为缓存穿透。
对于小规模的缓存穿透是不会对我们系统产生大的影响,但如果是缓存穿透攻击则又是另外一码事了。缓存穿透攻击,是指恶意用户在短时内大量查询不存在的数据,导致大量请求被送达数据库进行查询,当请求数量超过数据库负载上限时,使系统响应出现高延迟甚至瘫痪的攻击行为,就是缓存穿透攻击。

预防缓存穿透“神器”:布隆过滤器
在架构设计时有一种最常见的设计被称为布隆过滤器,它可以有效减少缓存穿透的情况。其主旨是采用一个很长的二进制数组,通过一系列的 Hash 函数来确定该数据是否存在。
这么说可能有些晦涩,我们通过一系列的图表演示你就明白了。
布隆过滤器本质上是一个 n 位的二进制数组。你也知道二进制只有 0 和 1 来表示,针对于当前我们的场景。这里我模拟了一个二进制数组,其每一位它的初始值都是 0。

而这个二进制数组会被存储在 Redis 服务器中,那么这个数组该怎么用呢?
1.若干次 Hash 来确定其位置
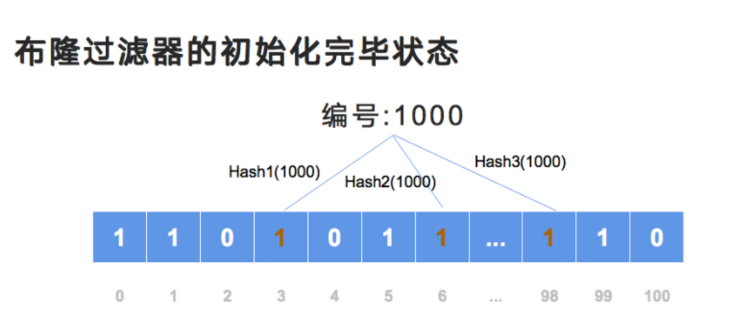
刚才我们提到作为当前的商城,假设有 1000 个商品编号,从 1~1000。作为布隆过滤器,在初始化的时候,实际上就是对每一个商品编号进行若干次 Hash 来确定它们的位置。
(1)1 号商品计算
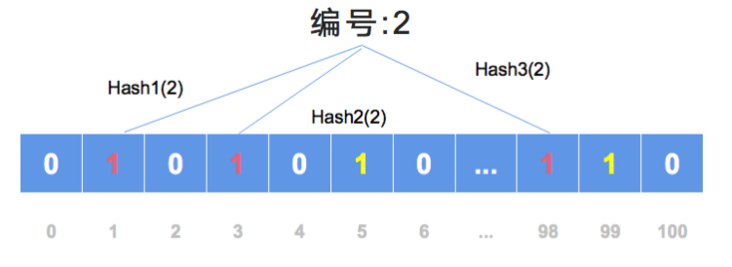
比如说针对于当前的“1”编号,我们对其执行了三次 Hash。所谓 Hash 函数就是将数据代入以后确定一个具体的位置。
Hash 1 函数:它会定位到二进制数组的第 2 位上,并将其数值从 0 改为 1;
Hash 2 函数:它定位到索引为 5 的位置,并将从 0 改为 1;
Hash 3 函数:定位到索引为 99 的位置上,将其从 0 改为 1。

(2)2 号商品计算
那 1 号商品计算完以后,该轮到 2 号商品。2 号商品经过三次 Hash 以后,分别定位到索引为 1、3 以及 98 号位置上。
(3)1000 号商品计算
此时 2 号商品也处理完了,我们继续向后 3、4、5、6、7、8 直到编号达到了最后一个 1000,当商品编号 1000 处理完后,他将索引为 3、6、98 设置为 1。
2.布隆过滤器在电商商品中的实践
作为布隆过滤器,它存储在 Redis 服务器中该怎么去使用呢?这就涉及我们日常开发中对于商品编号的比对了。
(1)先看一个已存在的情况
比如,此时某一个用户要查询 858 号商品数据。都知道 858 是存在的,那么按照原始的三个 Hash 分别定位到了 1、5 和 98 号位,当每一个 Hash 位的数值都是 1 时,则代表对应的编号它是存在的。

(2)再看一个不存在的情况
例如这里要查询 8888。8888 这个数值经过三次 Hash 后,定位到了 3、6 和 100 这三个位置。此时索引为 100 的数值是 0,在多次 Hash 时有任何一位为 0 则代表这个数据是不存在的。
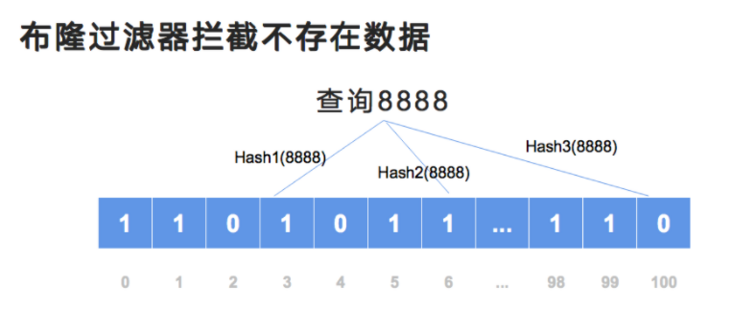
简单总结一下:如果布隆过滤器所有 Hash 的值都是 1 的话,则代表这个数据可能存在。
注意我的表达:它是可能存在;但如果某一位的数值是 0 的话,它是一定不存在的。
布隆过滤器设计之初,它就不是一个精确的判断,因为布隆过滤器存在误判的情况。
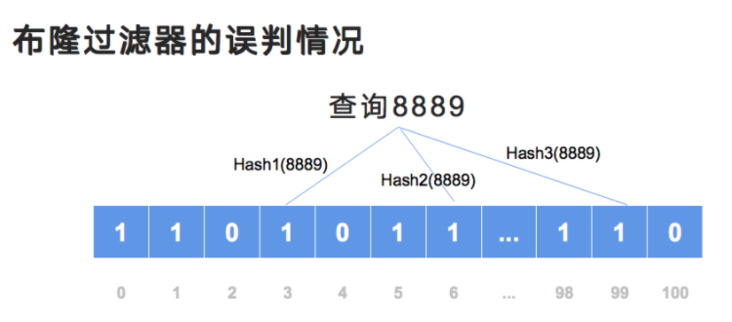
(3)最后看一个误判情况
来看一下当前的演示:比如现在我要查询 8889 的情况,经过三次 Hash 正好每一位上都是 1。尽管在数据库中,8889 这个商品是不存在的;但在布隆过滤器中,它会被判定为存在。这就是在布隆过滤器中会出现的小概率的误判情况。
3.如何减少布隆过滤器的误判?
关于减少误判的产生,方法有两个:
第一个是增加二进制位数。在原始情况下我们设置索引位到达了 100,但是如果我们把它放大 1 万倍,到达了 100 万,是不是 Hash 以后的数据会变得更分散,出现重复的情况就会更小,这是第一种方式。
第二个是增加 Hash 的次数。其实每一次 Hash 处理都是在增加数据的特征,特征越多,出现误判的概率就越小。
现在我们是做了三次 Hash,那么如果你做十次,是不是它出现误判的概率就会小非常多?但是在这个过程中,代价便是 CPU 需要进行更多运算,这会让布隆过滤器的性能有所降低。
讲到这里,想必你对布隆过滤器应该有所了解了。但是在我们开发过程中,我们如何去使用布隆过滤器?来咱们看一下。
开发中,如何使用布隆过滤器?
1.布隆过滤器在 Java 中的应用
其实作为 Java 积累了这么多年,像布隆过滤器这种经典的算法,早就为我们进行了封装和集成。在 Java 中提供了一个 Redisson 的组件,它内置了布隆过滤器,可以让程序员非常简单直接地去设置布隆过滤器。

上面代码是Redisson的使用办法,在前几行代码,用来设置Redis服务器的服务地址及端口号。
而后面关键的地方在这里,我们实例化一个布隆过滤器对象,后面的参数指代 Redis 使用哪个 key 来保存布隆过滤器数据?
下面这句话非常关键,作为当前的布隆过滤器,这里需要调用 tryInit 方法,它有两个参数:
第一个参数是代表初始化的布隆过滤器长度,长度越大,出现误判的可能性就越低。
而第二个 0.01 则代表误判率最大允许为 1%,在我们以前的项目中通常也是设置为 1%。如果把这个数值设置太小,虽然会降低误判率,但会产生更多次的 Hash 操作,会降低系统的性能(正是刚刚讲过的),因此 1% 也是我所建议的数值。
当把布隆过滤器初始化以后,我们便可以通过 add 方法,往里边去添加数据。所谓添加数据,就是将数据进行多次 Hash,将对应位从 0 变为 1 的过程。例如,现在我们把编号 1 增加进去,之后可以通过布隆过滤器的 contains 方法来判断当前这个数据是否存在。
我们输入 1,它输出 true;而输入了不存在的 8888,则输出 false。
请注意:这两个结果的含义是不同的。
如果输出 false,则代表这个数据它是肯定不存在的;
但是如果输出 true 的时候,它有 1% 的概率可能不存在,因为布隆过滤器它存在误判的情况。
以上便是布隆过滤器在 Java 中的应用,但是布隆过滤器如果要运用在项目中又该变成什么样子?它的处理流程是什么?
2.布隆过滤器在项目中的应用
咱们看一下布隆过滤器在项目中的使用流程,其实就归结成以下三部分:

第一个部分是在应用启动时,我们去初始化布隆过滤器。例如将 1000 个、1 万个、10 万个商品进行初始化,完成从 0 到 1 的转化工作。
之后便是当用户发来请求时,会附加商品编号,如果布隆过滤器判断编号存在,则直接去读取存储在 Redis 缓存中的数据;如果此时 Redis 缓存没有存在对应的商品数据,则直接去读取数据库,并将读取到的信息重新载入到 Redis 缓存中。这样下一次用户在查询相同编号数据时,就可以直接读取缓存了。
另外一种情况是,如果布隆过滤器判断没有包含编号,则直接返回数据不存在的消息提示,这样便可以在 Redis 层面将请求进行拦截。
你可能会有疑惑,既然布隆过滤器存在误判率,那出现了误判该怎么办呢?
其实在大多数情况下,我们出现误判也不会对系统产生额外的影响。因为像刚才我们设置 1% 的误判率,1 万次请求才可能会出现 100 次误判的情况。我们已经将 99% 的无效请求进行了拦截,而这些漏网之鱼也不会对我们系统产生任何实质影响。
延伸问题:初始化后,对应商品被删怎么办? 最后还有一个延伸的小问题:假如布隆过滤器初始化后,对应商品被删除了,该怎么办呢?这是一个布隆过滤器的小难点。
因为布隆过滤器某一位的二进制数据,可能被多个编号的 Hash 位进行引用。比如说,布隆过滤器中 2 号位是 1,但是它可能被 3、5、100、1000 这 4 个商品编号同时引用。这里是不允许直接对布隆过滤器某一位进行删除的,否则数据就乱了,怎么办呢?
这里业内有两种常见的解决方案:
- 定时异步重建布隆过滤器。比如说我们每过 4 个小时在额外的一台服务器上,异步去执行一个任务调度,来重新生成布隆过滤器,替换掉已有的布隆过滤器。
- 计数布隆过滤器。在标准的布隆过滤器下,是无法得知当前某一位它是被哪些具体数据进行了引用,但是计数布隆过滤器它是在这一位上额外的附加的计数信息,表达出该位被几个数据进行了引用。(如果你对计数布隆过滤器有兴趣的话,可以查看Counting Bloom Filter 的原理和实现)
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2024-01-11,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号