SparkSQL 如何选择 join 策略


一、前言
Join 操作是大数据分析领域必不可少的操作,本文将从原理层面介绍 SparkSQL 支持的五大连接策略及其应用场景。
SparkSQL 内置了五种连接策略,如下所示
1、Broadcast Hash Join(BHJ)
2、Shuffle Hash Join
3、Shuffle Sort Merge Join(SMJ)
4、Cartesian Product Join
5、Broadcast Nested Loop Join(BNLJ)
二、影响策略选择因素
(1)是否为等值连接
等值连接是在连接条件中只有 equals 比较,非等值连接包含除 equals 以外的任何比较,例如 >,<,>=,<=。对于非等值连接,SparkSQL 只支持 Broadcast Nested Loop Join 和 Cartesian Product Join。其他的连接策略都支持等值连接。
(2)用户自定义的连接提示(hint)
Spark 3.0 支持以下的提示(在 hints.scala 文件中):
BROADCAST, SHUFFLE_MERGE, SHUFFLE_HASH, SHUFFLE_REPLICATE_NL
(3)连接的数据集大小
连接策略的选择最重要的因素就是数据集的大小,核心策略就是避免 shuffle 和 排序操作,这些操作非常昂贵,对查询的性能影响较大。
三、流程图
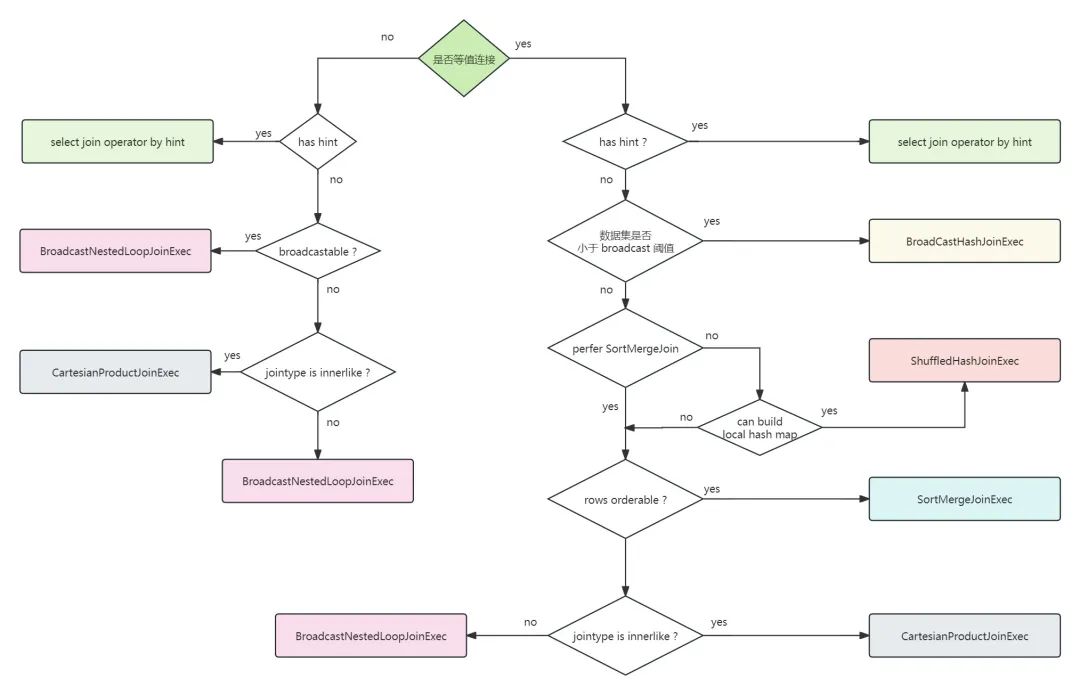
绘制了一个流程图来描述 Spark SQL 是如何选择连接策略的:
四、策略选择过程
首先判断是否为等值连接,会进入不同的主流程。
1、等值连接
(1)开发人员指定的连接提示(hint)具有最高的优先权
对于 BROADCAST 提示,选择 Broadcast Hash Join 策略,当 BROADCAST 提示在连接的两边都被指定时,选择数据集较小的那一边;
对于 SHUFFLE_HASH 提示,选择 Shuffle Hash Join 策略,当 SHUFFLE_HASH 提示在连接两边都被指定时,选择数据集较小的那一边;
对于 SHUFFLE_MERGE 提示,如果连接键是可排序的,选择 Shuffle Sort Merge Join 策略;
对于 SHUFFLE_REPLICATE_NL 提示,如果连接类型时内部连接,选择 Cartesian Product Join 策略。
(2)接下来判断数据集的大小
当连接数据集中至少有一方小到可以收集到 driver 端,然后广播到每个 executor 时,Broadcast Hash Join 是首选策略。可以被广播的数据集的阈值大小默认是 10M,可以通过 spark.sql.autoBroadcastJoinThreshold 参数来配置,基于 driver 和 executor 端的可用内存。
当 BroadcastExchange 操作符被执行时,它首先将数据集 collect 到 driver 端,然后 广播到所有的 Executor 节点。注意数据集的行数不能超过 MAX_BROADCAST_TABLE_ROWS (3.4亿行),否则会无法广播。
在 Executor 端,广播的数据集被用作连接的 buildTable,而最初存在于 executor 的数据集,即连接的大表,被用作连接的 StreamTable,连接过程中遍历 StreamTable,在 buildTable 中查找匹配的行。
(3)如果选择 BroadcastHash 策略没有被满足,则判断是否将 Shuffle Sort Merge Join 策略设置为首选,由 spark.sql.join.preferSortMergeJoin 参数控制,默认为 true。
如果这个参数被显式设置了 false,则判断是否使用 Shuffle Hash Join 策略的条件:至少有一个连接数据集需要小到足以建立一个 hash table(使的较小的数据集可以加载到内存中)。其大小应该小于广播阈值和 shuffle 分区数的乘积
private def canBuildLocalHashMap(plan: LogicalPlan): Boolean = {
plan.stats.sizeInBytes < conf.autoBroadcastJoinThreshold * conf.numShufflePartitions
}
另外较大的数据集至少应该是较小数据集大小的3倍以上,此时收益比较大
private def muchSmaller(a: LogicalPlan, b: LogicalPlan): Boolean = {
a.stats.sizeInBytes * 3 <= b.stats.sizeInBytes
}
Shuffle Hash Join 执行时,会对两个数据集进行 shuffle,以便将两边数据集中,具有相同连接键的行放在同一个 executor 中。较小的数据集作为 buildTable,较大的数据集作为 StreamTable。
(4)如果以上条件没有被满足,则开始判断是否使用 Shuffle Sort Merge Join 为了使用基于排序的连接算法,连接键必须是可排序的
Shuffle Sort Merge Join 不需要将任何数据集装入内存,所以连接数据集大小没有限制。基于排序的连接算法没有基于 hash 的连接快,但它通常比嵌套循环的连接算法表现更好,因此基于性能和灵活性的双重考虑,Sort Merge Join 是一个折中的方案。
Shuffle Sort Merge Join 也需要对连接的数据集进行shuffle,以便将两边数据集中具有相同连接键的行放在同一个 Executor 中,此外,每个分区的数据都需要按连接键进行升序排序。
两个连接数据集中的任何一个都可以作为 buildTable 或者 streamTable 使用。当一个数据集被作为 streamTable 时,它被按顺序逐行迭代。对于每个 streamTable 行,buildTable 也是按顺序逐行搜索的,由于它们都是排了序的,当连接过程转义到下一行的 streamTable 时,buildTable 不必从第一行开始,而只需要从上一个匹配到的行继续搜索即可。
(5)如果 Shuffle Sort Merge Join 策略的条件没有被满足,并且 joinType 是 InnerLinke,则会使用 Cartesian Product Join 策略,可能通常没有定义连接条件。笛卡尔积会非常慢,并且容易 oom,要慎重使用;
(6)如果以上条件都没有满足,则会选择 BroadcastNestedLoopJoin ,此时会将 streamTable 和 buildTable 进行嵌套循环
private def innerJoin(relation: Broadcast[Array[InternalRow]]): RDD[InternalRow] = {
streamed.execute().mapPartitionsInternal { streamedIter =>
val buildRows = relation.value
val joinedRow = new JoinedRow
streamedIter.flatMap { streamedRow =>
val joinedRows = buildRows.iterator.map(r => joinedRow(streamedRow, r))
if (condition.isDefined) {
joinedRows.filter(boundCondition)
} else {
joinedRows
}
}
}
这种策略的性能也会非常糟糕。
2、非等值连接
只有两种策略支持非等值连接:Cartesian Product Join和Broadcast Nested Loop Join。
如果在连接查询中指定了连接提示,请根据连接提示选择相应的连接策略。否则,如果数据集的一侧或两侧小到可以广播,则选择Broadcast Nested Loop Join策略并广播较小的数据集。如果没有足够小的数据集可以广播,则检查JointType是否为InnerLike,如果是,则选择Cartesian Product Join策略,否则就选择Broadcast Nested Loop Join策略作为最终方案。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-02-19,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号