如何在分布式系统中确定先后?


在数据系统中,时钟(clocks)和时间(time)都很重要。应用程序会以很多种形式依赖时钟,举例来说:
- 某个请求是否超时?
- 该服务的 99 分位的响应时间是多少?
- 该服务过去五分钟的平均 QPS 是多少?
- 用户在我们网站上花了多长时间?
- 这篇文章什么时候发布的?
- 提醒邮件什么时刻发出?
- 该缓存条目何时超时?
- 日志中这条错误消息的时间戳是什么?
例子 1-4 测量的是时间间隔(durations),例子 5-8 描述的是时间点(points in time)。在分布式系统中,时间是一个棘手的问题。因为两个机器间的通信不是瞬时完成的,虽然我们知道一条消息的接收时间一定小于发送时间,但由于通信延迟的不确定性,我们无法知道具体晚了多久。因此,发生在分布式系统内多个机器的事件,很难准确地确定其先后顺序。
更进一步,网络中的每个机器都有自己的系统时钟,通常是用石英振荡器做成的特殊硬件计时的,并且通常是独立供电的,即使系统宕机、断电也能持续运转。但这种时钟通常不是非常准确,即有的机器可能走地稍微快一些,有的可能就慢一些。因此,实践中,常通过 NTP(网络时间协议)对机器进行自动校准。其大致原理是,首先使用更精确时钟(如 GPS 接收器)构建一组可信服务器作为时钟源(比如阿里云的源),然后再利用这组服务器通过网络校准其他机器。
单调时钟和日历时钟
当代的计算机通常支持两类时钟:日历时钟(time-of-day clock)和单调时钟(monotonic clock),他们之间有些区别,其实分别和该小节最初提出的需求相对应:前者常用于时间点需求,后者常用于计算时间间隔。
日历时钟
该时钟和我们日常生活中的时钟关联,也称为挂钟时间(wall-clock time),通常会返回当前日期和时间。如:Linux 上的 clock_gettime(CLOCK_REALTIME) 和 Java 里的 System.currentTimeMillis() ,他们都会返回基于格里历(Gregorian calendar)1970 年 1 月 1 日 00:00:00 时刻以来的秒数(或者毫秒数),不包括闰秒。当然,一些系统可能会用其他时刻作为计时起点。
日历时钟常常使用 NTP 进行同步,以使得不同机器上时间戳能够同步。但之后会提到,日历时钟有诸多不确定性。这里值得一提的是,如果某个机器时间大大领先于 NTP 服务器,则其日历时钟会被重置,从而让该机器上的时间看起来倒流了一样。时钟回拨、跳过闰秒等等问题,使得日历时钟不能用于精确计算一个时间间隔。
此外,历史上,日历时钟还使用过粗粒度的计时方案,如老版的 Windows 系统的时钟最小粒度是 10 ms。当然,在最近的系统里,这不再是问题。
单调时钟
单调时钟主用于取两个时间点的差值来测量时间间隔,如服务器的超时间隔和响应时间。Linux 上的 clock_gettime(CLOCK_MONOTONIC)和 Java 中的 System.nanoTime()都是单调时钟。顾名思义,单调时钟不会像日历时钟一样由于同步而进行回拨,可以保证一直单调向前。也正因为如此,用其计算时间间隔才更加准确。
在具有多个 CPU 的服务中,每个 CPU 可能会有一个单独的计时器,且不同 CPU 之间不一定同步。但操作系统会试图屏蔽其间差异,对应用层保证单调递增。这样,即使一个线程被调度到不同 CPU 上去,也仍能保证单调。当然,最保险的办法是不严格依赖此单调性。
如果检测到本地石英钟和 NTP 服务器不一致,NTP 会相应调整单调时钟的频率,但是幅度不能超过 0.05%。换句话说,NTP 可以调整单调时钟频率,但不能直接往前或者往后跳拨单调时钟。因此,多数机器上单调时钟的置信度通常都很好,能达到毫秒级甚至更细粒度。即,单调时钟会通过调整频率来和 NTP 时间对齐,而非像挂历时钟那样直接跳拨。
在分布式系统中,使用单调时钟计算时间间隔很合适,因为时间间隔既不关心多机间进行时钟同步,也对时间精度不是很敏感。
时钟同步和精度问题
单调时钟不太需要关心多机同步问题。但是对于日历时钟来说,由于自身石英钟计时不够精确,为了能够正常使用,需要定时与 NTP 服务器或者其他可信时钟源进行同步。想象你家老式的电子挂钟,就得定时手动与新闻开始时的北京时间进行校准,不然会越走越快或者越走越慢。
在计算机系统中,其本身的硬件时钟以及用于校准的 NTP 服务都不是完全可靠的:
- 单机的硬件时钟都不是很精确,会发生漂移(drift,走的快或者慢),当然本质上是一个相对问题,如果我们认为世界上只有一种时间速率是正常的,则其他的速率都是有问题的。有多种因素会造成时钟漂移,如所在机器的温度。谷歌认为其服务器时钟为 200ppm(parts per million),也即每 30s 漂移 6ms、每天漂移 17s,这种漂移限制了时钟的精确度上限。
- 如果计算机时钟和 NTP 服务器相差太多,该计算机会拒绝同步或强制同步。如果强制同步,应用层在会在同步前后看到一个时钟的跳变。
- 如果一个节点通过偶然的设置把 NTP 服务器给墙了,并且没有留意到这个问题,则可能会造成这段时间内时钟不同步,实践中确实发生过类似问题。
- NTP 同步受限于网络的延迟,因此在延迟不稳定的拥塞网络中,其精度会受到影响。有实验表明通过互联网进行时钟同步,可以实现最小 35ms 的时钟误差。尽管网络中偶有将近 1s 延迟尖刺,但可以通过合理配置来忽略尖刺对应的同步。
- 润秒的存在会导致一分钟可能有 59s 或者 61s,如果系统在做设计时没有考虑这种特殊情况,就有可能在运行时遇到问题,很多大型系统都因此而宕机。处理闰秒最好的办法是,让 NTP 服务器在一天中逐渐调整,摊平闰秒(也称为:拖尾,_smearing_),不过在实际中,NTP 服务器处理闰秒的行为不尽相同。
- 在虚拟机中,其物理时钟是虚拟化出来的,从而给运行其上并依赖精确计时的应用带来额外挑战。由于一个 CPU 内核是被多个 VM 所共享的,当一个 VM 运行时,其他 VM 就得让出内核几十毫秒。在 VM 恢复运行后,从应用代码的视角,其时钟就是毫无征兆的突然往前跳变了一段。
- 如果你的软件将会运行在不受控的设备上,如智能手机或者嵌入式设备,则你不能完全相信设备系统时钟。因为用户可能会由于一些原因(比如绕开游戏时间限制),故意将其硬件时钟设置成一个错误的日期和时间,从而引起系统时钟的跳变。
当然,如果不计代价,我们是能够获得足够精确的时钟的。例如针对金融机构的欧洲法案:MIFID II,要求所有高频交易的基金需要和 UTC 的误差不超过 100 微秒,以便调试如“闪崩”之类的市场异常,并帮助检测市场操纵行文。
可以通过组合使用 GPS 接收机、PTP 协议(Precision Time Protocol),并进行小心部署和监控,来获取此类高精度时钟。然而,这需要非常多的专业知识和精力投入,且仍有很多问题会引起时钟不同步:NTP 服务器配置错误、防火墙错误组织了 NTP 流量。
依赖同步时钟
如前所述,尽管看起来简单易用,但时钟却有一些严重的问题:
- 一天可能没有精确的 86400 秒
- 日历时钟可能有时候会回跳
- 不同节点的时钟可能相差巨大
前面讨论过,虽然网络丢包和不固定延迟不常发生,但在做设计时,仍要考虑这些极端情况。对于时钟也是如此:虽然大部分时间,时钟都能如我们预期一样工作,但在设计系统时,仍要考虑最坏可能,否则一旦出现故障时,通常难以定位。
时钟问题造成的影响往往不容易被发现。如果 CPU、内存或者网络故障,可能系统会立即出现很严重的问题;但如果不正确的依赖了时钟,可能系统仍然能在表面上看起来正常运转,比如时钟漂移是慢慢累加的,可能到第一程度才会出现问题。
因此,如果你的系统依赖(或者假设)所有参与的机器时钟同步(synchronized clocks),就必须通过一定的机制来检测系统内节点间的时钟偏移,如果某个节点系统时钟与其他相差过大,就及时将其从系统内移除,以此来规避时钟相差太大所造成的不可挽回的问题。
时间戳以定序
考虑一种危险的依赖时钟的情况:使用节点的本地时钟来给跨节点的事件定序。举个具体例子,如果两个客户端同时写入同一个分布式数据库,谁居前?谁靠后?
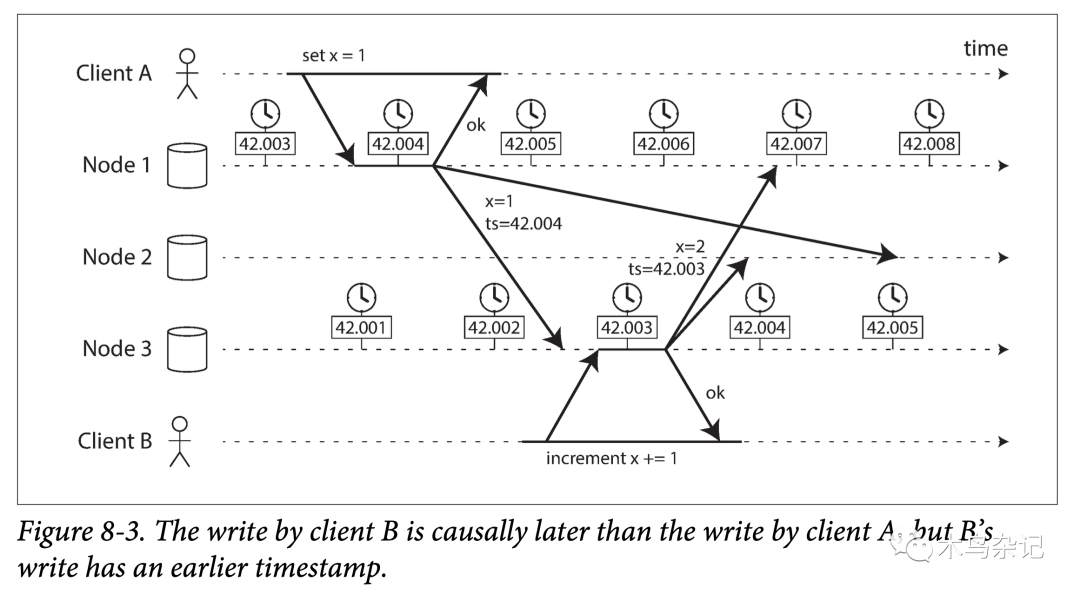
分布式系统中事件的后发先到
如上图,Client A 向节点 1 写入 x = 1,然后该写入被复制到节点 3 上;Client B 在节点上将 x 增加 1,得到 x = 2;最终上述两个写入都被复制到节点 2。
在图中所有待同步的数据都会被打上一个时间戳,接收到同步来数据的节点会根据时间戳对所有写入应用到本地。那么如何使用时间戳呢?所有节点只会通过时间戳递增的顺序接受同步过来的写入请求,如果某个写请求时间戳小于上一个写请求的,则丢弃。
另外,节点 1 和节点 3 的时钟相差小于 3 ms,这在日常中是一个很小的偏差,算是时钟同步的很好了。但在这个例子中,却仍然出现了顺序问题,写请求 x = 1 的时间戳是 42.004,写请求 x = 2 的时间戳是 42.001,小于 x = 1 的写请求,但我们知道,写请求 x = 2 应该发生在后面。于是当节点 2 收到第二个写请求 x = 2 时,发现其时间戳小于上一个写时间戳,于是将其丢掉。于是,客户端 B 的自增操作在节点 2 上被错误的丢弃了。
后者胜(Last write win,LWW)作为一种冲突解决策略,在多副本(无论是多主还是无主)架构中被广泛使用,比如 Cassandra 和 Riak。有一些实现是在客户端侧而非服务侧产生时间戳,但这仍不能解决 LWW 固有问题:
- 写入谜之丢失。一个具有落后时钟的节点产生的写入数据,无法覆盖一个具有超前时钟节点先前写入的数据,造成后写入的数据反而被没有任何提醒的丢弃。
- 无法区分先后和并行。两者主要区别在于,一个是有明显的依赖关系,如上图中自增依赖于之前的初始化;另一个是相关的几个操作互相并不关心。为了解决这个问题,需要引入额外的时间戳机制进行因果关系追踪,如 version vector(一种逻辑时钟)。
- 两个独立节点可能会产生相同时间戳的事件。尤其是在时钟精读不太够的情况下(比如最低只能给到毫秒),可以使用额外的随机数来对其进一步区分,但这样也会导致一些时间上的因果问题。
因此,在使用后者胜策略解决冲突,并丢弃被覆盖更新时,需特别注意如何判定哪个事件更近(most recent),因为其定序可能依赖于不同机器的本地时钟。即使使用紧密同步的 NTP 时钟,仍然可能发生:在 100 ms 时(发送方本地时钟)发出一个数据包,而在 99ms 时(接收方本地时钟)收到该数据包,就好像时光倒流一样,但这明显不可能。
使用 NTP 进行时钟同步有可能做到足够精确,以避免网络中对事件错误的排序吗?不可能。因为 NTP 本身就是通过网络进行同步的,其精度则必受限于同步两侧的往返延迟,更遑论叠加其他误差,比如石英钟的漂移(quartz drift)。换句话说,为了处理网络误差以正确定序,我们需要使用更精确的手段,而非网络本身(NTP)。
逻辑时钟和物理时钟的区别。所谓的逻辑时钟(logical clocks),使用了自增的计数器,而非石英晶振(oscillating quartz crystal)。逻辑时钟不会追踪自然时间或者耗时间隔,而仅用来确定的系统中事件发生的先后顺序。与之相对,挂历时钟(time-of-day)和单调时钟(monotonic clocks)用于追踪时间流逝,被称为物理时钟。
时钟读数的置信区间
尽管你可以从机器上读取以微秒(microsecond)甚至纳秒(nanosecond)为单位的日历时间戳(time-of-day),但这并不意味你可以得到具有这样精度的绝对时间。如前所述,误差来自于几方面:
- 石英晶振漂移。如果你直接从本地石英钟读取时间戳,其偏移很容易就可以累积数毫秒。
- NTP 同步误差。如果你想定时通过 NTP 来同步,比如每分钟同步一次。但 NTP 协议是走网络的,而网络通信最快做到毫秒级延迟,偶有拥塞,延迟便能冲到数百毫秒。
总结来说,使用普通硬件,你无论如何都难以得到真正“准确”的时间戳。
因此,将时钟的读数视为一个时间点意义不大,准确来说,其读数应该是一个具有置信区间的时间范围。比如,一个系统有 95% 的信心保证当前时刻落在该分钟过 10.3 到 10.5 秒,但除此以外,不能提供任何一进步的保证。在 +/– 100 ms 的置信区间内,时间戳的微秒零头毫无意义。
时钟的误差区间可以通过你的时钟源进行计算:
- 高精度硬件。如果你的机器使用了 GPS 接收器或者铯原子钟,则硬件制造商会提供误差范围。
- 其他服务器。如果你通过 NTP 服务从其他服务器获取时间。则误差区间是几种因素叠加:该 NTP 服务器的误差范围、服务器间的往返延迟、同步后石英晶振漂移等等。
但不幸,大多数服务器的时钟系统 API 在给出时间点时,并不会一并给出对应的不确定区间。例如,你使用 clock_gettime() 系统调用获取时间戳时,返回值并不包括其置信区间,因此你无法知道这个时间点的误差是 5 毫秒还是 5 年。
一个有趣的反例是谷歌在 Spanner 系统中使用的 TrueTime API,会显式的给出置信区间。当你向 TrueTime 系统询问当前时钟时,会得到两个值,或者说一个区间:[earliest, latest],前者是最早可能的时间戳。后者是最迟可能的时间错。通过该不确定预估,我们可以确定准确时间点就在该时钟范围内。此时,区间的大小取决于,上一次同步过后本地石英钟的漂移多少。
用于快照的时钟同步
在“快照隔离和可重复读”一小节,本书讨论过快照隔离。当数据库想同时支持短时、较小的读写负载以及长时、很大的只读负载(如数据分析、备份)时,快照隔离很有用。快照隔离能让只读事务在不阻塞正常读写事务的情况下,看到数据库某个时间点之前的一致性视图。
快照隔离的实现通常需要一个全局自增的事务 ID。如果一个写入发生在快照 S 之后,则基于快照 S 的事务看不到该写入的内容。对于单机数据库,简单的使用一个全局自增计数器,就能够充当事务 ID 的来源。
然而,当数据库横跨多个机器,甚至多个数据库中心时,一个可用于事务全局自增 ID 并不容易实现,因为需要进行多机协作。事务 ID 必须要反应因果性:如当事务 B 读到事务 A 写的内容时,事务 B 的事务 ID 就需要比事务 A 大。非如此,快照不能维持一致。另外,如果系统中存在大量短小事务,分配事务 ID 可能会成为分布式系统中的一个瓶颈。这其实就是分布式事务中常说的 TSO 方案(Timestamp Oracle,统一中心授时),这种方案通常会有性能瓶颈;尤其在跨数据中心的数据库里,会延迟很高,实践中也有很多优化方案。
那么,我们可以用机器的挂历时钟的时间戳作为事物的 ID 吗?如果我们能让系统中的多台机器时钟保持严格同步,则其可以满足要求:后面的事务会具有较大的时间戳,即较大的事务 ID。但现实中,由于时钟同步的不确定性,用这种方法产生事务 ID 是不太靠谱的。
但 Spanner 就使用了物理时钟实现了快照隔离,它是如何做到可用的呢?Spanner 在设计 TrueTime 的 API 时,让其返回一个置信区间,而非一个时间点,来代表一个时间戳。假如现在你有两个时间戳 A 和 B(_A_ = [Aearliest, Alatest] and B = [Bearliest, Blatest]),且这两个时间戳对应的区间没有交集(例如,_Aearliest_ < Alatest < Bearliest < _Blatest_),则我们可以确信时间戳 B 发生于 A 之后。但如果两个区间有交集,我们则不能确定 A 和 B 的相对顺序。
为了保证这种时间戳能够用作事务 ID,相邻生成的两个时间戳最好要间隔一个置信区间,以保证其没有交集。为此,Spanner 在索要时间戳时(比如提交事务),会等待一个置信区间。因此置信区间越小,这种方案的性能也就越好。为此,谷歌在每个数据中心使用了专门的硬件做为时钟源,比如原子钟和 GPS 接收器,以保证时钟的置信区间不超过 7 ms。
在分布式事务中使用时钟同步,是一个比较活跃的研究领域(在书出版时,大概 2017),很多观点都很有趣,但在谷歌之外,还没有人再实现过。
- 但 HLC 感觉也算类似的实现,我去翻了下,HLC 论文是 2014 年,不知道作者为什么不算?
进程停顿
现在我们来看另外一种分布式系统中使用时钟的危险情况。假设你的数据库有多分片,每个分片多副本单主,只有主副本可以接受写入。那么一个很直接的问题就是:对于每个主副本来说,为了保证安全的接受写入,我们需要确定它仍是事实上的主副本。那我们如何确定呢?毕竟有时他会自认为是主副本,但事实上不是(比如其他副本和他产生了网络隔离,已经重新选出了主)?
一种解决方案是使用租约(lease)。该机制(注意和 Raft 中 Leader 的租约区分)类似于具有超时的锁:任意时刻只有一个副本可以持有改租约。因此,一旦某副本获取到租约,它就获取到了一段时间的领导权,直到租约过期;为了持续掌握领导权,该副本需要定期续租,且续租间隔要小于租期时间。如果该副本宕机,自然就会停止续约,其他副本就可以上位。
用代码表示,续租大概长这样:
while (true) {
request = getIncomingRequest();
// Ensure that the lease always has at least 10 seconds remaining
if (lease.expiryTimeMillis - System.currentTimeMillis() < 10000) {
lease = lease.renew();
}
if (lease.isValid()) {
process(request);
}
}
这段代码有什么问题呢?
- 依赖时钟同步。租期的过期时间点是在另外的机器 M 上被设置的,比如说设置为 M 接到续租请求时的当前时间加上 30 秒。然后该时间戳会和副本本地时间戳比较,如果两个机器时钟偏差过大,就会出现一些奇怪的事情(比如租约过晚过期,其他人续租成功,导致同一时刻有两个副本持有租约)。也就是说,比较不同机器上的时间戳是不靠谱的。
- 语句执行间隔的假设。即使我们都用同一机器上的单调时钟,上述代码仍然可能有问题。我们很自然的以为在测试完租约是否仍然宽裕(
lease.expiryTimeMillis - System.currentTimeMillis() < 10000)后,会立即进行请求处理:process(request);。一般来说的确是这样。
但如果在程序执行期间,发生了意外的停顿会怎么样?比如说,在 lease.isValid() 语句前线程停顿了 15 秒,这种情况下,在执行到真正处理请求的语句时,租约就可能会过期,此时,其他副本就有可能接下领导权限。但对于这个线程来说,并没有其他手段可以限制它继续执行,于是,就有可能发生一些不安全的处理事件。
程序在执行的时候真可能停顿这么长时间吗?还真有可能,原因有很多:
- 一些编程语言的运行时(如 JVM),都会有垃圾回收器(GC)。垃圾回收器有时候会暂停所有运行中的线程(以进行垃圾回收),这个全暂停(stop-the-world)时间有时甚至能到达数分钟!即便号称可以并发 GC 的最新 GC 算法(如 Hotpot JVM 的 CMS 算法),也不能真正的和用户线程并行,仍会时不时的暂停,只不过这个时间缩短了很多。另外,我们也可通过修改内存分配模式和进行 GC 参数调优来进一步降低 GC 影响。但即便如此,如果我们想真正的提供足够鲁棒的程序,就不能对 GC 所造成的停顿时间做最坏假设。
- 在虚拟化环境中,一个虚拟机可能会在任意时间点被挂起(suspended,暂停所有正在运行的进程,并将其上下文从内存中保存到磁盘)和恢复(resumed,将上下文恢复到内存中并且继续执行暂停的进程),挂起到恢复的间隔可能持续任意长时间。有时该功能也被称为虚机的在线迁移(live migration),此时虚机暂停的时间取决于上下文的迁移速率。
- 哪怕像在笔记本这样的用户终端上,程序的运行也有可能被随时挂起和恢复。如,用户合上笔记本。
- 当操作系统做上下文切换,将线程切走时;当管控程序(hypervisor)切到一个新的虚拟机时,当前正在执行的线程可能会停在代码中的任意位置。在虚拟机环境中,其他虚拟机占用 CPU 的时间也被称为被窃时间(_steal time_)。在物理机负载很重时,比如调度队列中有大量线程在等待时间片,某个被暂停的线程可能要好久才能重新执行。
- 如果操作系统配置了允许换页(swapping to disk, paging),则有时候一个简单的内存访问也可能引起缺页错误,这时我们就需要从磁盘中加载一个页到内存。在进行此 IO 时,线程多会挂起,让出 CPU。如果内存吃紧,缺页换页可能会非常频繁。在极端情况下,操作系统可能会将大部分时间都浪费在换页上,而非正经工作上(也被称为颠簸,thrashing)。为了避免此问题,服务器上的允许换页的配置项一般不打开。当然,你也可以点杀一部分进程来释放内存,避免换页,这就是 trade off 了。
- 在 Unix 操作系统中,可以通过向进程发送 SIGSTOP 信号来让其暂停。如,用户对执行的进程在 Shell 中按下 Ctrl-Z。该信号会阻止进程再获取 CPU 的时间片,直到我们使用 SIGCONT 将其再度唤起。你自己的环境中可能不怎么使用 SIGSTOP,但是运维人员偶尔还是会用的。
所有上述情景都会在任意时刻中断(_preempt_)正在运行的线程,并在之后某个时刻将其重新唤醒,而线程本身对这个过程是不感知的。类似的情形还有单机多线程编程:你不能对多个线程代码的相对执行顺序有任何假设,因为上下文切换和并发执行可能会在任何时间以任何形式发生。
在单机我们有很多手段可以对多线程的执行进行协调,使之线程安全。如锁、信号量、原子计数器、无锁数据结构、阻塞队列等等。但不幸的是,分布式系统中我们没有对应的手段。因为在多机间不能共享内存,只能依靠消息同步,而且是要经过不可靠网络的消息!
分布式系统中的节点可能在任意时刻的任意代码位置停顿任何时长,而在此间,系统的其他节点仍在正常往前执行,甚至由于该节点不响应而将其标记为死亡。最终,该停顿节点可能会继续执行,但此时代码逻辑本身(也就是你写分布式系统逻辑时)并不能知道发生了什么,直到其再次检查机器时钟时(虽然这也不太准)。
响应时间保证
如前所述,在很多语言和操作系统中,进程和线程都可能停顿任意时间,我们将其称之为无界(unbounded)时延。但如果我们付出足够代价,上述造成停顿的原因都可以被消除。
在某些环境中的软件,如果不在一定时间内给响应,可能会造成严重问题。如飞机、火箭、机器人、车辆和其他一些需要对传感器输入信号进行即时反应的物理实体。在这些系统中,软件的响应延迟都需要控制在某个时限(deadline)内,超出了这个时限,整个系统可能会出现重大故障,这就所谓的强实时系统(hard real-time system,与之相对的有 soft real-time system)。
举个例子,如果你正在驾车,传感器检测到车祸,你肯定不希望你的车载系统此时正在进行 GC 而不能及时处理该信号吧。
实时系统真的实时吗?
在嵌入式系统里,实时意味着需要通过设计、测试等多层面来让系统在延迟上提供某种保证。其在 Web 中也有实时系统(real-time)的叫法,但更多的侧重于服务器会流式的处理客户端请求,并将数据发回客户端,但对响应时间并没有严苛的要求。
我们需要在全软件栈进行优化才能提供实时保证:
- 在操作系统上,需要能提供指定所需 CPU 时间片的实时操作系统(_real-time operating system_,RTOS)。
- 在依赖库中,所有的函数都需要注释其运行时间的上界。
- 在内存分配上,要限制甚至禁止动态内存分配(会有实时 GC 器,但不会占用太多时间)。
- 在观测和测试上,需要进行详尽的衡量和测试,以保证满足实时要求。
上述要求极大的限制了编程语言、依赖库和工具的可选范围,从而使得开发实时系统代价极为高昂。也因此,这种系统通常被用在对安全性有严苛要求的嵌入式设备里。这里需要说明的是,实时不意味着高性能。并且通常相反,实时系统都具有很低的吞吐,因为实时系统会把对时延的优化放在第一位,比如需要尽量消除并行所带来的运行的不可预测性,自然就降低了效率。
对于一般的服务端的数据处理系统来说,这种严苛的实时保证通常既不经济也不必要。也就是说,我们在设计服务端的数据系统时,还是要老老实实考虑由于任意停顿和不准确时钟所带来的问题。
限制 GC 的影响
我们有一些手段可以用来减轻进程停顿现象,且不必借助代价高昂的强实时系统。比如垃圾回收器(GC 进程)可以实时追踪对象分配速率和剩余可利用内存,利用这些信息,GC 进程可以给应用程序提供一些信号。然后我们在构造系统时捕获这些信号,然后拒绝服务一段时间,等待 GC 结束。就跟临时故障或者下线的节点一样,别的节点会来接管请求。一些对延迟比较敏感的系统,如交易系统,就是用了类似的方法。
另一个相似的想法是,阉割一下 GC,只用其对短时对象进行快速回收。对于生命周期较长的对象,通过通过定期重启来回收。在重启期间,该节点上的流量可以暂时切走,就像滚动升级一样。
这些手段虽然不能治本,但能一定程度上缓解 GC 对应用进程造成的影响。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-10-28,如有侵权请联系 cloudcommunity@tencent.com 删除
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号