AI应用开发基础教程_借助LangChain来调用ChatGPT_API

AI应用开发基础教程_借助LangChain来调用ChatGPT_API

yeedomliu
发布于 2023-10-20 14:11:30
发布于 2023-10-20 14:11:30
思维导图

引言
代码:
- https://github.com/langchain-ai/langchain
- https://github.com/hwchase17/langchain
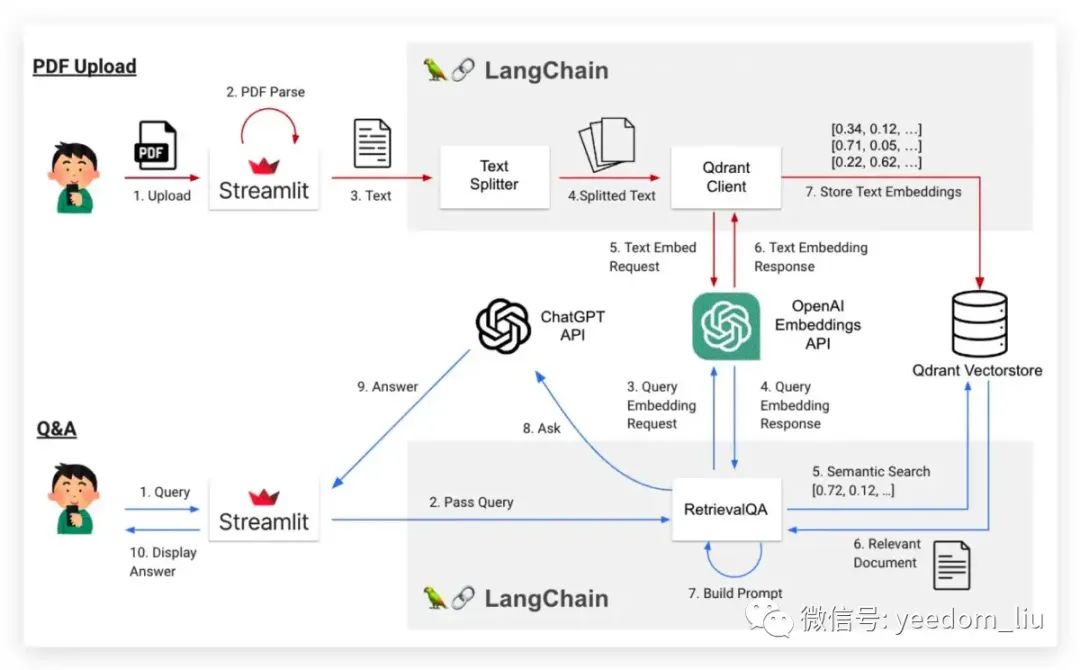
一个允许用户上传PDF并提问的应用程序的概览图
主题
- 图像生成和声音生成
- 详细的用户界面实现
- 聊天GPT插件的利用
- 聊天GPT最新功能的利用(例如:函数调用)
章节结构
- 逐步创建一个 AI 聊天机器人,创建一个简单的摘要 AI 应用程序,然后创建一个更高级的 AI 应用程序,使用 Embedding 和 Vector DB
- 依次解释 ChatGPT、Streamlit 和 LangChain 等工具的设置和使用方法
- 结束LLM开发实际的 AI 应用程序
让我们开始环境设置
Python
- LangChain (0.0.225):Python >=3.8.1, <4.0
- Streamlit (1.24.0):Python >=3.8, !=3.9.7
- OpenA! (0.27.8):Python >=3.7.1
ChatGPT API 可用的主要模型
模型名称 | 描述 | 令牌上限 | 输入成本 (每1000令牌) | 输出成本 (每1000令牌) |
|---|---|---|---|---|
gpt-3.5-turbo | ChatGPT的基础模型。快速且经济。 | 4096 | $0.0015 | $0.002 |
gpt-3.5-turbo-16k | gpt-3.5-turbo的变种。能处理非常长的指令。 | 16385 | $0.003 | $0.004 |
gpt-4 | 7月23日起,全球最强大的LLM。非常智能,但速度慢且昂贵。 | 8192 | $0.03 | $0.06 |
令牌计数:一个非常重要的概念。ChatGPT使用称为令牌的单位处理句子。按照输入指令(提示)和输出响应中的令牌数量计费。模型还确定了可以处理的令牌数量。
import tiktoken
encoding = tiktoken.encoding_for_model('gpt-3.5-turbo')
text = "This is a test for tiktoken."
tokens = encoding.encode(text)
print(len(text)) # 28
print(tokens) # [2028, 374, 264, 1296, 369, 87272, 5963, 13]
print(len(tokens)) # 8最准确的模型text-embedding-ada-002可以非常便宜地使用,所以我认为您很少会使用其他模型。(费用为每1000个标记0.0001美元,几乎是免费的)
免费使用gpt-4方法:https://platform.openai.com/playground?model=gpt-4
创建您的第一个AI聊天应用
让我们创建一个ChatGPT克隆应用
我们将开发的AI聊天机器人操作流程
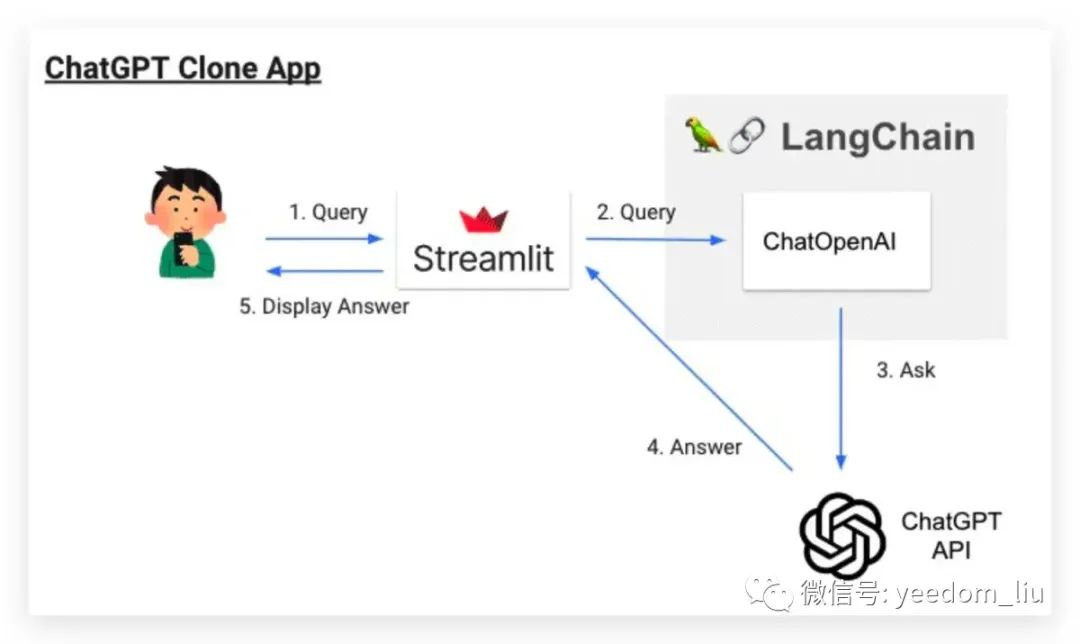
让我们创建一个简单的AI聊天应用
https://github.com/naotaka1128/ai_app_book/blob/main/chapter_03.py
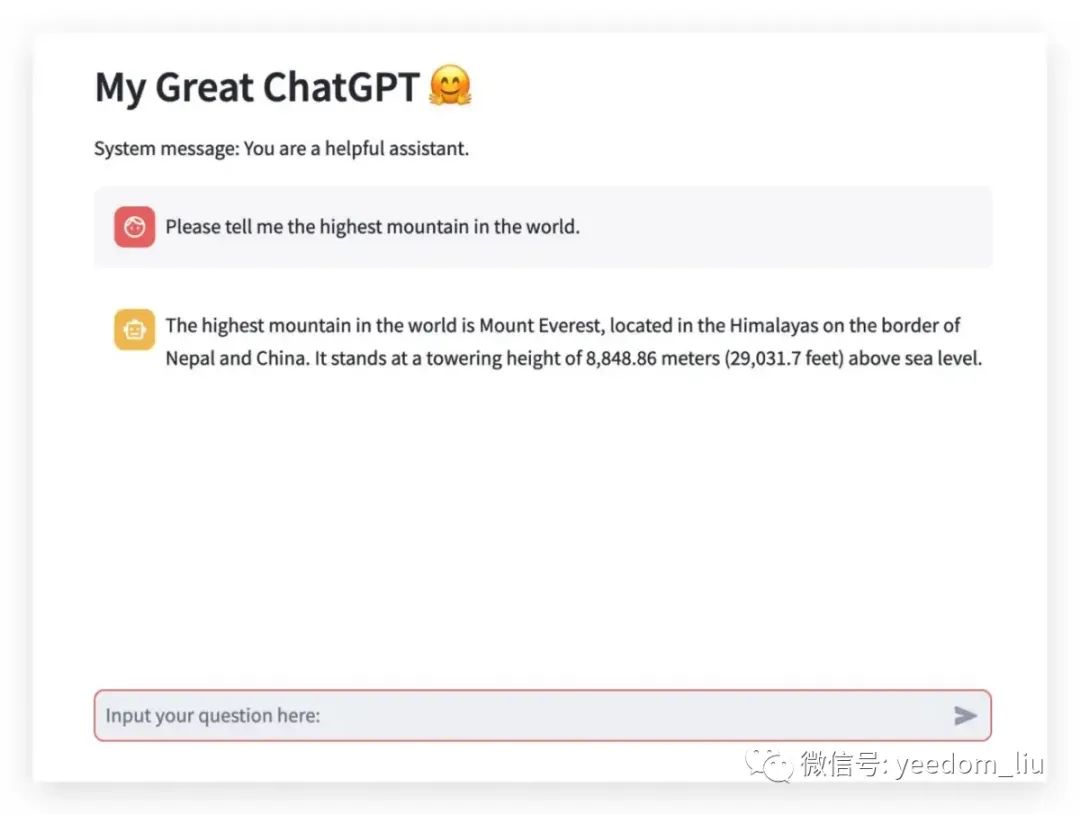
import streamlit as st
from langchain.chat_models import ChatOpenAI
from langchain.schema import (SystemMessage, HumanMessage, AIMessage)
def main():
llm = ChatOpenAI(temperature=0)
st.set_page_config(
page_title="My Great ChatGPT",
page_icon="🤗"
)
st.header("My Great ChatGPT 🤗")
# Initialize chat history
if "messages" not in st.session_state:
st.session_state.messages = [
SystemMessage(content="You are a helpful assistant.")
]
# Monitor user input
if user_input := st.chat_input("Input your question here:"):
st.session_state.messages.append(HumanMessage(content=user_input))
with st.spinner("ChatGPT is typing ..."):
response = llm(st.session_state.messages)
st.session_state.messages.append(AIMessage(content=response.content))
# Display chat history
messages = st.session_state.get('messages', [])
for message in messages:
if isinstance(message, AIMessage):
with st.chat_message('assistant'):
st.markdown(message.content)
elif isinstance(message, HumanMessage):
with st.chat_message('user'):
st.markdown(message.content)
else: # isinstance(message, SystemMessage):
st.write(f"System message: {message.content}")
if __name__ == '__main__':
main()应用结构非常简单,只有一个函数。随着AI应用变得更加复杂,我们将把它们分成多个函数(和类)。
- st.set_page_config()函数用于配置网页。在这里,页面标题设置为“我的ChatGPT” ,页面图标设置为“”表情符号。
- 使用st.container()为小部件(允许与用户交互的元素)创建一个容器。容器用于将多个小部件放置在页面的特定部分。
- st.form()函数创建一个表单,用户可以在其中输入信息。在此表单中,使用st.text_area()创建一个文本区域,并使用st.form_submit_button()创建一个提交按钮
修改后的代码
import streamlit as st
from langchain.chat_models import ChatOpenAI
from langchain.schema import (SystemMessage, HumanMessage, AIMessage)
def main():
llm = ChatOpenAI(temperature=0)
st.set_page_config(
page_title="我的伟大的ChatGPT",
page_icon="🤗"
)
st.header("我的伟大的ChatGPT 🤗")
# 初始化聊天历史
if "messages" not in st.session_state:
st.session_state.messages = [
SystemMessage(content="你是一个有用的助手。")
]
container = st.container()
with container:
with st.form(key='my_form', clear_on_submit=True):
user_input = st.text_area(label='Message: ', key='input', height=100)
submit_button = st.form_submit_button(label='Send')
if submit_button and user_input:
st.session_state.messages.append(HumanMessage(content=user_input))
with st.spinner("ChatGPT正在输入..."):
response = llm(st.session_state.messages)
st.session_state.messages.append(AIMessage(content=response.content))
# 显示聊天历史
messages = st.session_state.get('messages', [])
for message in messages:
if isinstance(message, AIMessage):
with st.chat_message('assistant'):
st.markdown(message.content)
elif isinstance(message, HumanMessage):
with st.chat_message('user'):
st.markdown(message.content)
else: # isinstance(message, SystemMessage):
st.write(f"系统消息:{message.content}")
if __name__ == '__main__':
main()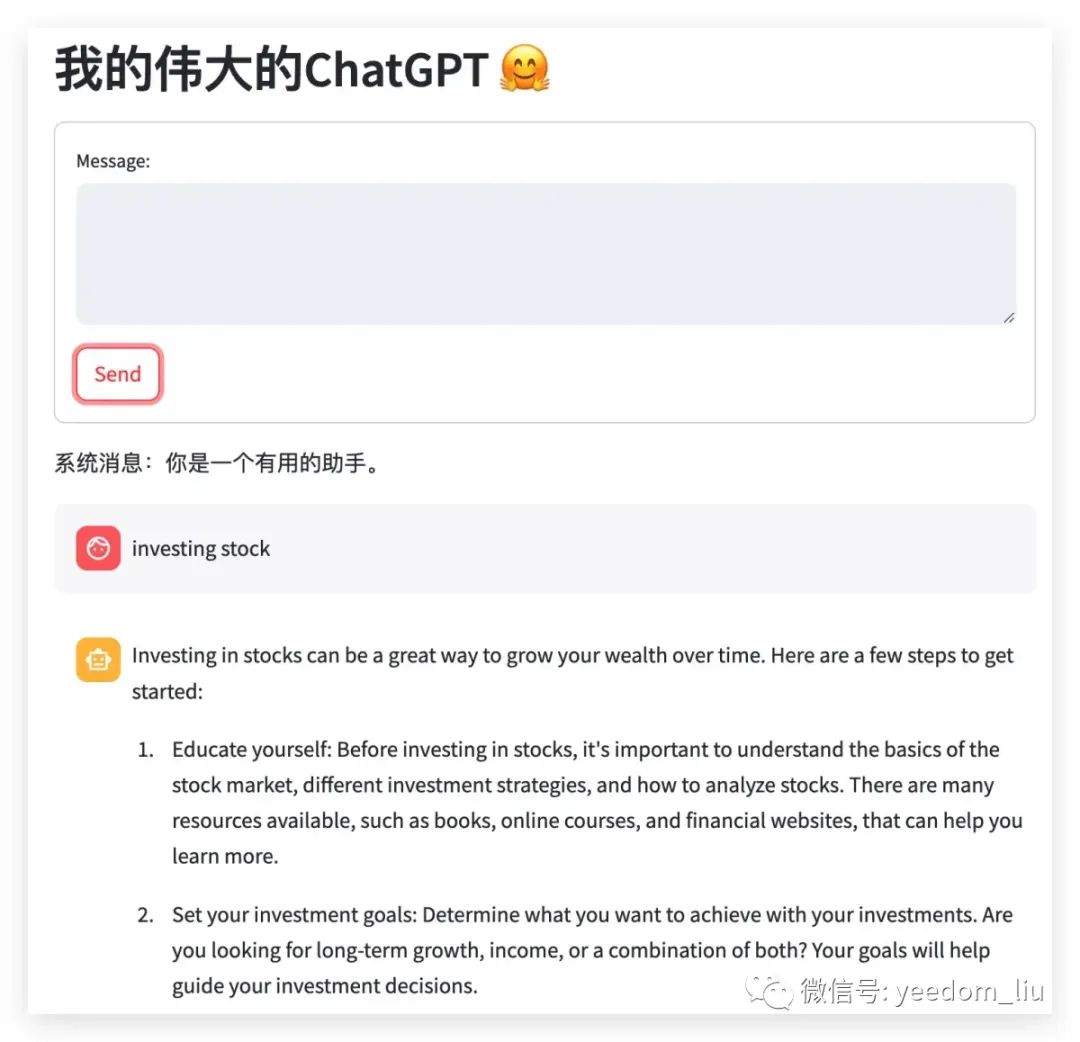
调用ChatGPT API
from langchain.chat_models import ChatOpenAI
from langchain.schema import (
SystemMessage, # System message
HumanMessage, # Human question
AIMessage # ChatGPT's response
)
llm = ChatOpenAI() # Feature that calls the ChatGPT API
message = "Hi, ChatGPT!" # Write your question here
messages = [
SystemMessage(content="You are a helpful assistant."),
HumanMessage(content=message)
]
response = llm(messages)
print(response)角色设定
message = "Hi, ChatGPT!" # Write your question here
messages = [
SystemMessage(content="Please Reply in Japanese"),
HumanMessage(content=message)
]
response = llm(messages)
print(response)
# content='こんにちは、何かお⼿伝いできますか?' additional_kwargs={} example=False温度参数
message = "Writing a book about creating an AI app with ChatGPT and Streamlit. Let's come up with one
title."
messages = [
SystemMessage(content="You are a helpful assistant."),
HumanMessage(content=message)
]
for temperature in [0, 1, 2]:
print(f'==== temp: {temperature}')
llm = ChatOpenAI(temperature=temperature)
for i in range(3):
print(llm(messages).content)
使用session_state
- Streamlit的session_state是一个用于管理应用程序状态的功能。它用于在应用程序的不同部分之间共享数据,或者基于用户交互保留信息。
- 当用户重新加载页面后,你希望保留先前的状态时,session_state也是很有用的。session_state是一个类似于字典的对象,存储键值对。
# Initialize chat history
if "messages" not in st.session_state:
st.session_state.messages = [
SystemMessage(content="You are a helpful assistant.")
]
# ...
# Monitor user input
if user_input := st.chat_input("Input your question here:"):
st.session_state.messages.append(HumanMessage(content=user_input))
with st.spinner("ChatGPT is typing ..."):
response = llm(st.session_state.messages)
st.session_state.messages.append(AIMessage(content=response.content))
# Display chat history
messages = st.session_state.get('messages', [])
for message in messages:
... # Code for displaying chat history显示聊天记录
使用st.chat_message函数轻松显示内容。在识别了三种消息类型之后,它们将被显示出来。在Streamlit中,您可以使用st.markdown轻松使用Markdown标记
messages = st.session_state.get('messages', [])
for message in messages:
if isinstance(message, AIMessage):
with st.chat_message('assistant'):
st.markdown(message.content)
elif isinstance(message, HumanMessage):
with st.chat_message('user'):
st.markdown(message.content)
else: # isinstance(message, SystemMessage):
st.write(f"系统消息:{message.content}")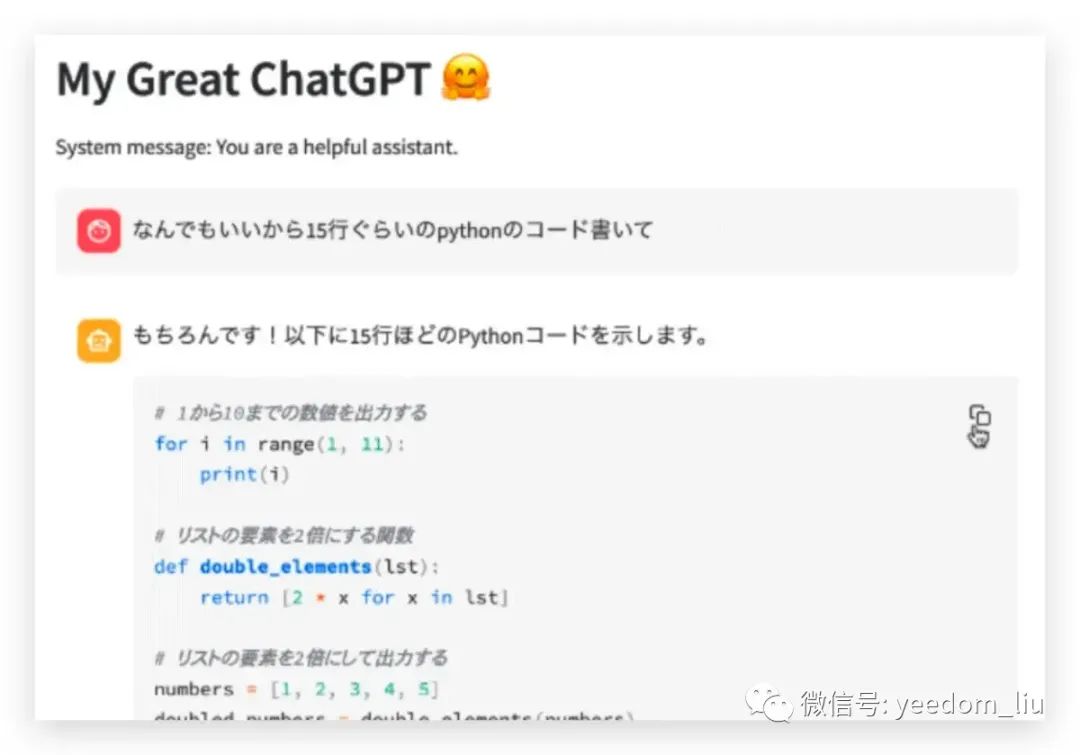
提升您的AI聊天应用
https://github.com/naotaka1128/ai_app_book/blob/main/chapter_04.py
本章您将学到什么
- 如何在Streamlit中创建带有侧边栏的屏幕
- Streamlit中的各种小部件(滑块和单选按钮)
- LangChain的有用回调功能
import streamlit as st
from langchain.chat_models import ChatOpenAI
from langchain.schema import (
SystemMessage,
HumanMessage,
AIMessage
)
from langchain.callbacks import get_openai_callback
def init_page():
st.set_page_config(
page_title="My Great ChatGPT",
page_icon="🤗"
)
st.header("My Great ChatGPT 🤗")
st.sidebar.title("Options")
def init_messages():
clear_button = st.sidebar.button("Clear Conversation", key="clear")
if clear_button or "messages" not in st.session_state:
st.session_state.messages = [
SystemMessage(content="You are a helpful assistant.")
]
st.session_state.costs = []
def select_model():
model = st.sidebar.radio("Choose a model:", ("GPT-3.5", "GPT-4"))
if model == "GPT-3.5":
model_name = "gpt-3.5-turbo"
else:
model_name = "gpt-4"
# Add a slider to allow users to select the temperature from 0 to 2.
# The initial value should be 0.0, with an increment of 0.01.
temperature = st.sidebar.slider("Temperature:", min_value=0.0, max_value=2.0, value=0.0, step=0.01)
return ChatOpenAI(temperature=temperature, model_name=model_name)
def get_answer(llm, messages):
with get_openai_callback() as cb:
answer = llm(messages)
return answer.content, cb.total_cost
def main():
init_page()
llm = select_model()
init_messages()
# Monitor user input
if user_input := st.chat_input("Input your question here:"):
st.session_state.messages.append(HumanMessage(content=user_input))
with st.spinner("ChatGPT is typing ..."):
answer, cost = get_answer(llm, st.session_state.messages)
st.session_state.messages.append(AIMessage(content=answer))
st.session_state.costs.append(cost)
messages = st.session_state.get('messages', [])
for message in messages:
if isinstance(message, AIMessage):
with st.chat_message('assistant'):
st.markdown(message.content)
elif isinstance(message, HumanMessage):
with st.chat_message('user'):
st.markdown(message.content)
else: # isinstance(message, SystemMessage):
st.write(f"System message: {message.content}")
costs = st.session_state.get('costs', [])
st.sidebar.markdown("## Costs")
st.sidebar.markdown(f"**Total cost: ${sum(costs):.5f}**")
for cost in costs:
st.sidebar.markdown(f"- ${cost:.5f}")
if __name__ == '__main__':
main()让我们学习如何使用各种选项
在侧边栏中显示各种内容
从st.sidebar开始编写来将元素放置在侧边栏中
# 导入相关类库
import streamlit as st
# 在侧边栏显示标题
st.sidebar.title("Options")
# 在侧边栏添加选项按钮
model = st.sidebar.radio("Choose a model:", ("GPT-3.5", "GPT-4"))
# 在侧边栏添加一个按钮
clear_button = st.sidebar.button("Clear Conversation", key="clear")
# 在侧边栏添加一个滑块以从0到2选择温度
# 初始值设为0.0,增量为0.1
temperature = st.sidebar.slider("Temperature:", min_value=0.0, max_value=2.0, value=0.0, step=0.1)
# Streamlit将以HTML形式显示markdown内容
# (你也可以在主窗口中使用它)
st.sidebar.markdown("## Costs")
st.sidebar.markdown("**Total cost**")
for i in range(3):
st.sidebar.markdown(f"- ${i+0.01}") # dummy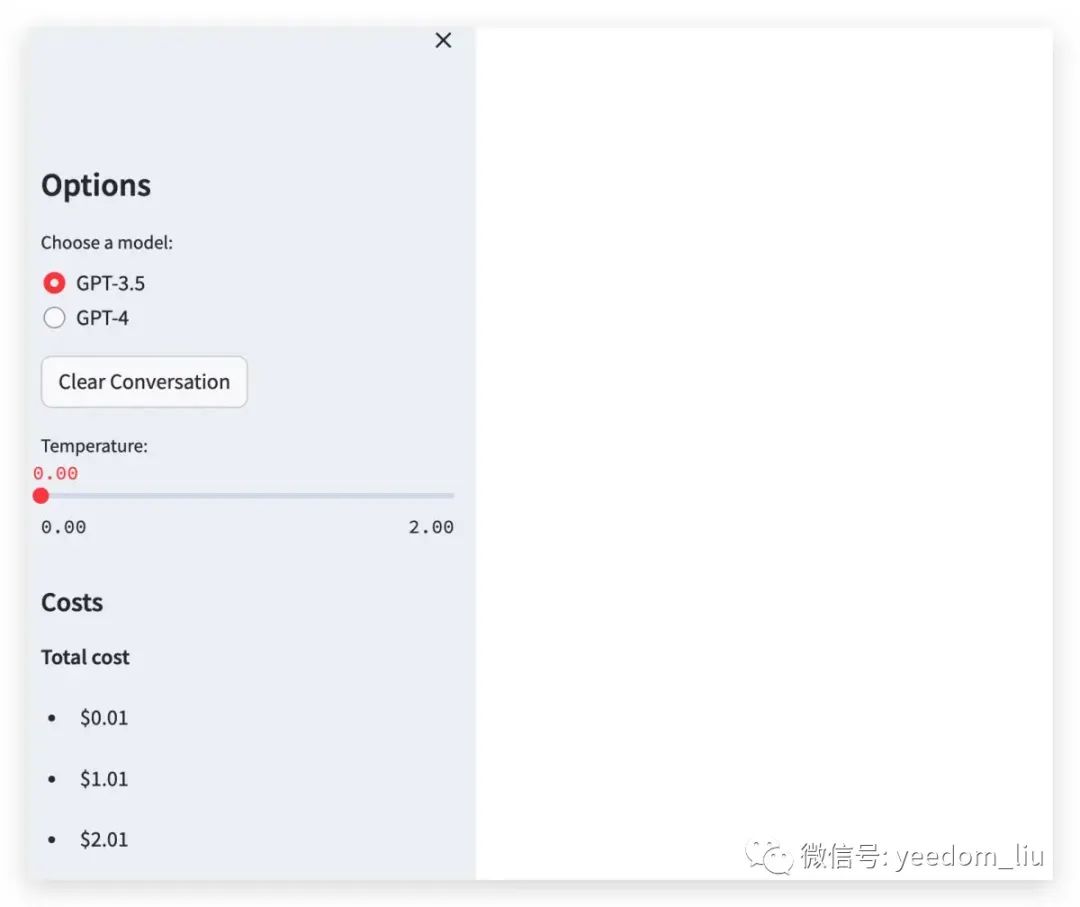
使用滑块
def select_model():
model = st.sidebar.radio("Choose a model:", ("GPT-3.5", "GPT-4"))
if model == "GPT-3.5":
model_name = "gpt-3.5-turbo"
else:
model_name = "gpt-4"
# Add a slider to allow users to select the temperature from 0 to 2.
# The initial value should be 0.0, with an increment of 0.01.
temperature = st.sidebar.slider("Temperature:", min_value=0.0, max_value=2.0, value=0.0, step=0.01)
return ChatOpenAI(temperature=temperature, model_name=model_name)清除历史记录
def init_messages():
clear_button = st.sidebar.button("清除对话", key="clear")
if clear_button or "messages" not in st.session_state:
st.session_state.messages = [SystemMessage(content="您是一个有用的助手。")]
st.session_state.costs = []
def main():
init_page()
Ilm = select_model()
init_messages()学习LangChain的有用功能
检索API调用产生费用
您可能会想知道已经花费了多少。通过使用LangChain的get_openai_callback上下文管理器,可以轻松实现此目标。在此上下文管理器中执行的所有操作都将被跟踪,您可以检索使用情况和令牌的费用。由于OpenAI偶尔会更改其API的价格,使用此上下文管理器可以说是获取最新信息的最简洁方式。
from langchain.llms import OpenAI
from langchain.callbacks import get_openai_callback
llm = OpenAI(model_name="text-davinci-002")
with get_openai_callback() as cb:
result = llm("Tell me a joke")
print(cb)
print(cb.total_cost)
print(cb.total_tokens)
print(cb.prompt_tokens)
print(cb.completion_tokens)Tokens Used: 23
Prompt Tokens: 4
Completion Tokens: 19
Successful Requests: 1
Total Cost (USD): $0.00046
0.00046
23
4
19流式显示
通过使用一个名为StreamlitCallbackHandler的回调函数,可以实现流式显示(逐个字符显示ChatGPT的回复)。不过,由于需要将过去的历史显示和要流式传输的最新交流分开显示,实现起来有些复杂。
# The past history will be displayed normally.
messages = st.session_state.get('messages', [])
for message in messages:
if isinstance(message, AIMessage):
with st.chat_message('assistant'):
st.markdown(message.content)
elif isinstance(message, HumanMessage):
with st.chat_message('user'):
st.markdown(message.content)
else: # isinstance(message, SystemMessage):
st.write(f"System message: {message.content}")
# Display the latest exchange separately (a bit more complex).
if user_input := st.chat_input("Input your question here:"):
st.session_state.messages.append(
HumanMessage(content=user_input))
st.chat_message("user").markdown(user_input)
with st.chat_message("assistant"):
st_callback = StreamlitCallbackHandler(
st.container())
response = llm(messages, callbacks=[st_callback])
st.session_state.messages.append(
AIMessage(content=response.content))部署您的AI聊天应用
本章您将学到什么
- 了解Streamlit社区云是什么
- 学习如何在Streamlit社区云上部署应用程序
- 学习如何使用Streamlit的配置文件自定义
Streamlit Cloud
方法 | 描述 |
|---|---|
Pipfile (pipenv)、environment.yml (conda)、pyproject.toml (poetry) 文件 | 这些文件用于指定项目的依赖项,通常包括Python包和版本信息。 |
packages.txt (Linux) | 用于在Linux系统中列出应用程序的依赖项的文本文件,可以使用包管理工具来安装这些依赖项。 |
requirements.txt 文件 | 包含Python项目的依赖项清单的文本文件,通常使用pip命令来安装这些依赖项。 |
config.toml 文件 | 用于配置应用程序的设置文件,例如,可以指定应用程序的主题为“dark”,并在此文件中进行其他自定义设置。 |
- 使用 Pipfile (pipenv)、environment.yml (conda)、pyproject.toml (poetry) 等文件来指定依赖项。
- linux依赖:packages.txt
- Python 依赖项:requirements.txt 文件
- config.toml 文件,您可以进行各种设置。例如,如果应用程序位于名为 my-app 的存储库中,则要添加一个名为 my-app/.streamlit/config.toml 的文件。如果要将应用程序的主题设置为“dark”,则可以在 config.toml 中编写以下内容
[theme]
base="dark"详细配置文件
英文属性 | 描述 | 解释 |
|---|---|---|
primaryColor | 定义应用中最常使用的重点色彩,例如复选框、滑块和焦点文本输入字段使用的颜色。 | 主要颜色 |
backgroundColor | 定义应用主内容区域使用的背景颜色。 | 背景颜色 |
secondaryBackgroundColor | 定义需要额外对比度时使用的次要背景颜色,特别是作为侧边栏和大多数交互式小部件的背景颜色。 | 次要背景颜色 |
textColor | 控制应用中大部分文本的颜色。 | 文本颜色 |
font | 选择应用中使用的字体。如果未设置或设置了无效值,则默认为“无衬线”。 | 字体 |
base | 基于现有的Streamlit主题(“亮”或“暗”)定义自定义主题。你可以从基础主题继承设置并仅更改其中的一些设置。 | 基础主题 |
自定义设置
配置项 | 描述 |
|---|---|
server.port | 设置服务器等待浏览器连接的端口。 |
browser.gatherUsageStats | 设置Streamlit是否收集使用统计。 |
runner.magicEnabled | 设置是否启用该功能,该功能仅通过在Python代码中用一行描述它们就可以在应用中显示变量或字符串。 |
client.displayEnabled | 设置Streamlit脚本是否在Streamlit应用中呈现。 |
server.headless | 设置是否在启动时打开浏览器窗口。 |
server.enableCORS | 设置是否启用跨来源请求共享(CORS)保护。 |
server.maxUploadSize | 设置可以使用文件上传器上传的最大文件大小(MB)。 |
创建您的第一个AI应用程序 - 网站摘要
您将在本章学习什么
- 学会如何从网站检索内容并传递给ChatGPT API
- 学会如何总结网站的内容
网站摘要应用程序
应用程序中操作概览图
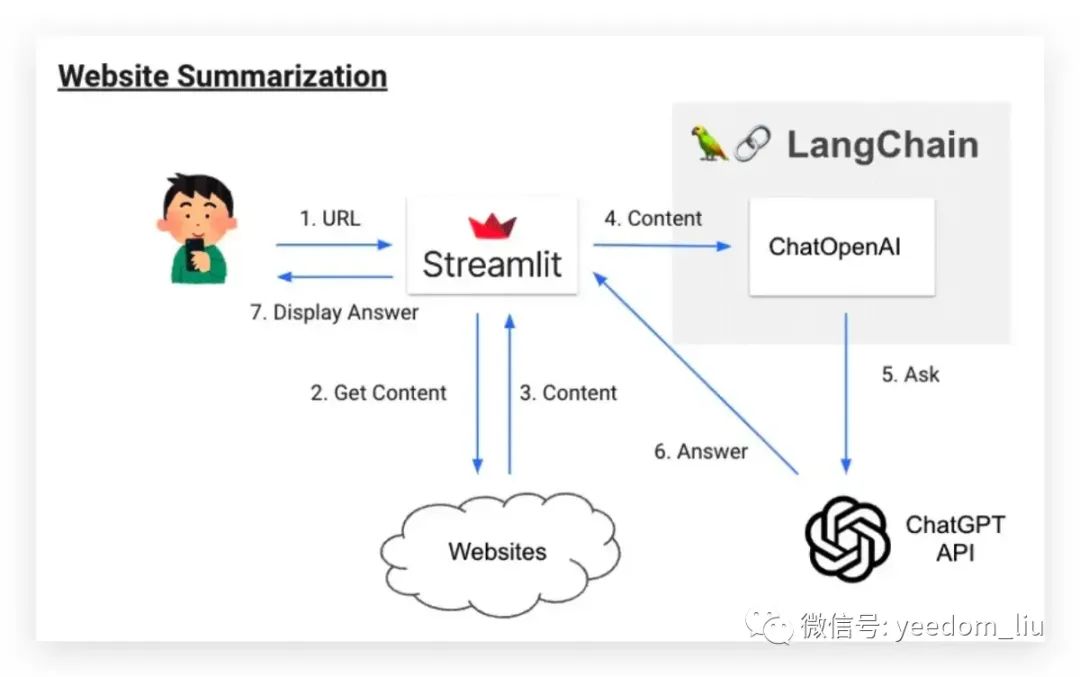
输入一个 URL 时,ChatGPT 会读取该页面的内容并创建一个摘要。
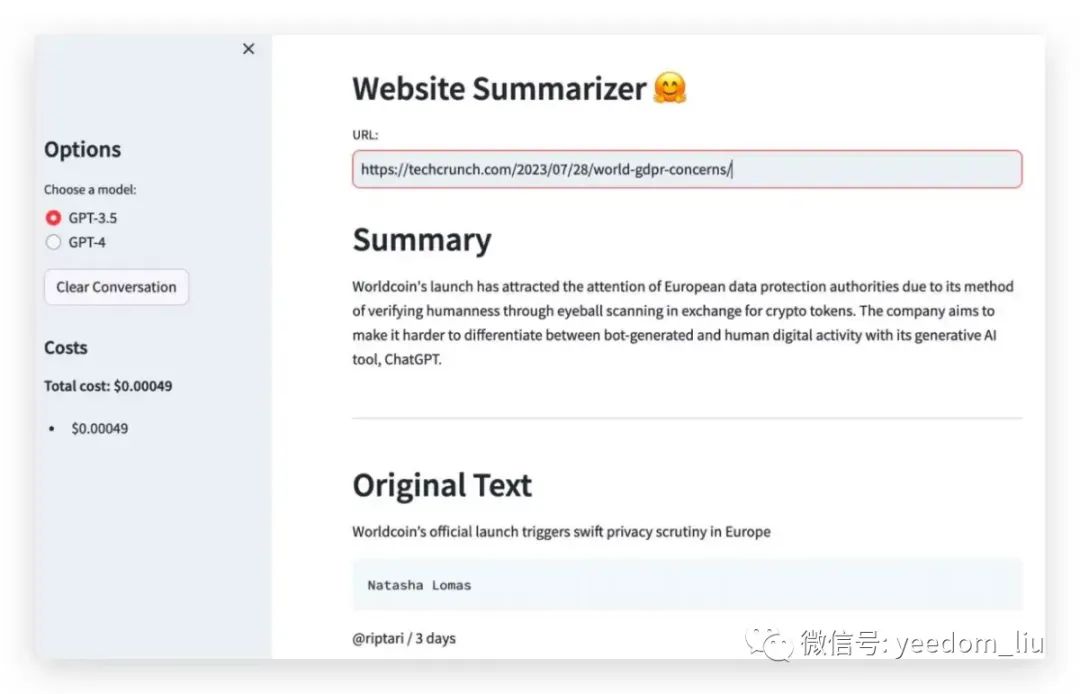
解释
获取页面内容
尝试获取像main或article这样的标签,以尽可能获取主要文本,这是我们使用的一种技巧
def get_content(url):
try:
with st.spinner("Fetching Content ..."):
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# fetch text from main (change the below code to filter page)
if soup.main:
return soup.main.get_text()
elif soup.article:
return soup.article.get_text()
else:
return soup.body.get_text()
except:
st.write('something wrong')
return None构建摘要指令提示
使用build_prompt函数创建摘要指令提示,并将其传递给后续过程中的ChatGPT API(get_answer函数) 检索到的页面内容嵌入在这里。如果内容很长,我们会使用前1000个字符并相应地缩写。虽然有很多更好的实现,比如“使用页面的前500个字符和最后500个字符”或者“使用tiktoken库计算内容中的标记数量”,但我们目前实现的还比较粗糙。
def build_prompt(content, n_chars=300):
return f"""Here is the content of a web page. Please provide a concise summary of around {n_chars} characters.
========
{content[:1000]}
"""
def get_answer(llm, messages):
with get_openai_callback() as cb:
answer = llm(messages)
return answer.content, cb.total_cost显示摘要
with response_container:
st.markdown("## Summary")
st.write(answer)
st.markdown("---")
st.markdown("## Original Text")
st.write(content)向PDF提问(第1部分:PDF上传和嵌入)
您将在本章学习什么
- 如何在Streamlit中切换页面
- 理解Streamlit的文件上传器(可以上传什么类型的数据?详细设置中可以设置什么?)
- 如何在不使用文档加载器的情况下将内容加载到LangChain中
- 如何将在LangChain中加载的内容转换为嵌入式内容
一种向PDF提问的机制
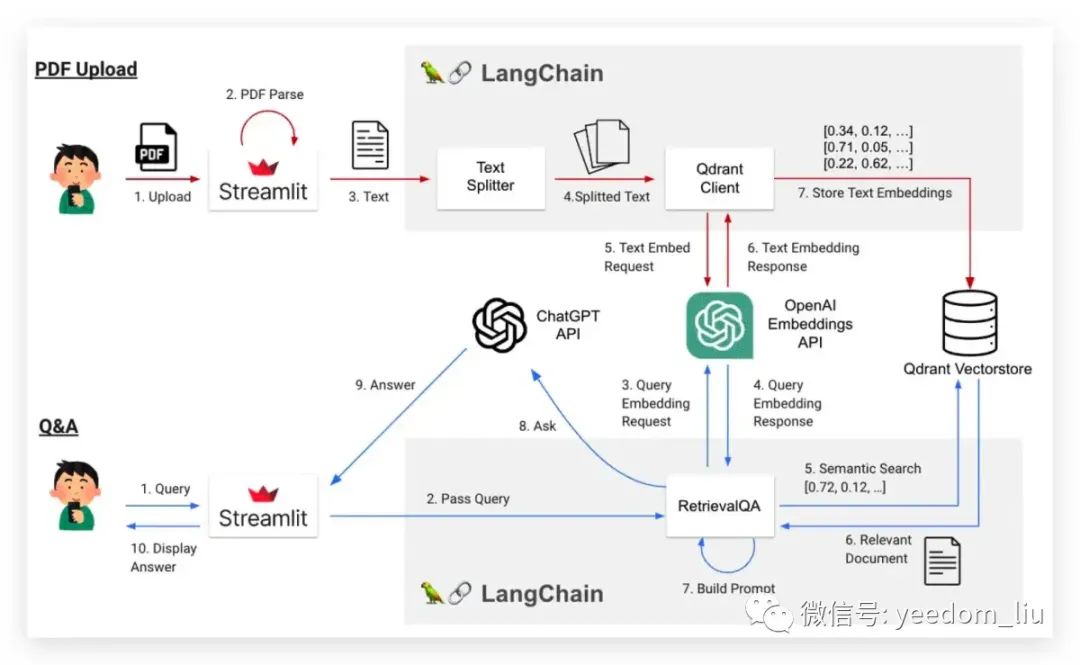
通过将 PDF 数据存储在数据库中,并从中提取与问题相关的内容,使得 ChatGPT 能够使用 Prompt 中嵌入的知识来回答问题,如下图所示的流程。
提问流程
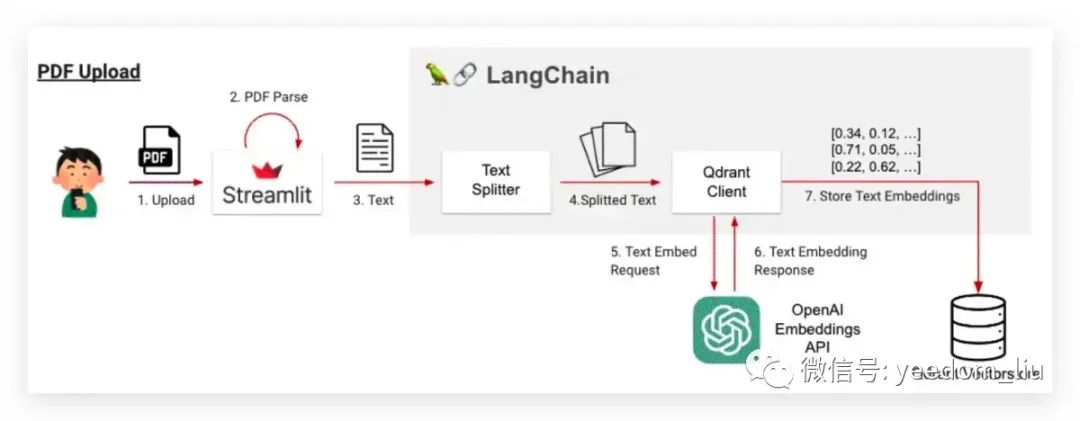
- 从 Streamlit 上传 PDF
- Streamlit 检索 PDF 内的文本
- 将文本传递给 LangChain
- 使用文本分割器进行分割
- 将每个分块传递给 OpenAI 嵌入 API
- 每个块作为一个嵌入列表返回
- 保存嵌入到Qdrant Vectorstore(向量数据库)
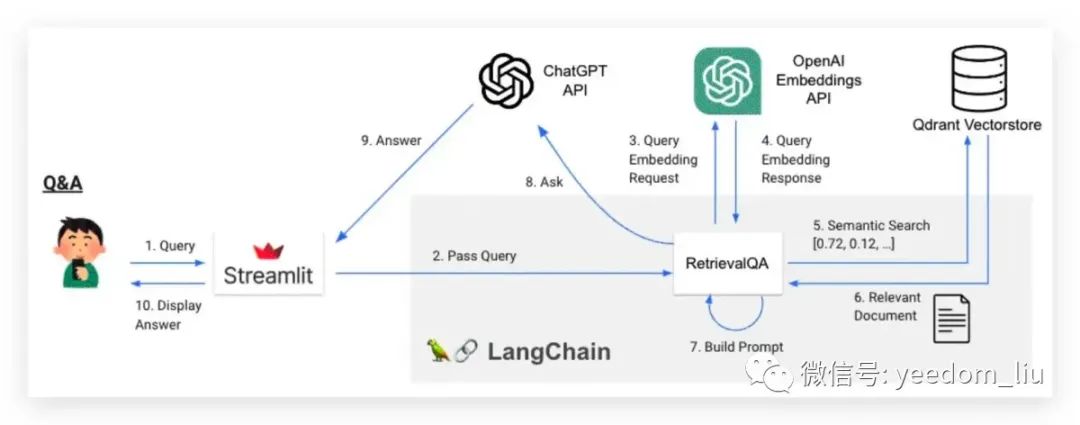
问答:Q&A
- 用户在Streamlit中编写问题(查询)。
- Streamlit将问题传递给LangChain。
- 问题被传递给OpenAI嵌入API。
- 问题作为嵌入返回。
- 根据步骤4中获得的嵌入,从Vector DB中搜索相似的文档(块)(这也等同于根据相关上下文执行语义搜索)。
- 相似文档从Vector DB返回。
- 在Prompt中替换步骤6中获得的内容,创建一个Prompt。
- 将Prompt发送到ChatGPT API以提问。
- ChatGPT API返回一个答案。
- 答案在Streamlit中显示。
prompt_template = f"""
Using the following background knowledge, please answer the user's questions.
=====
Background knowledge
・{Related knowledge fetched from DB-1}
・{Related knowledge fetched from DB-2}
・{Related knowledge fetched from DB-3}
=====
User's question
・{Question from the user}
"""
# Example of the prompt
prompt_example = f"""
Using the following background knowledge, please answer the user's questions.
=====
Background knowledge
・As of June 23, 2023, Shohei Ohtani has hit 24 home runs
・As of June 23, 2023, Shohei Ohtani has achieved 6 wins
・Shohei Ohtani's height is 193cm
=====
User's question
・Please tell me about Shohei Ohtani's player performance in 2023
"""
# >> "As a batter, Shohei Ohtani has hit 24 home runs, and as a pitcher, he has achieved 6 wins."准备一个向量数据库和实施问答流程可能会很具挑战性。然而,使用LangChain只需非常少的代码行数就可以实现
语义搜索
英文名词/描述 | 详细说明 |
|---|---|
余弦相似度 | 用于计算查询和文档嵌入之间的相似性 |
在LLM中的应用 | 语义搜索经常在基于LLM的应用程序中使用 |
对嵌入的依赖性 | 感知到的过度依赖嵌入 |
为“普通搜索”辩护 | 建议传统搜索和语义搜索应该结合使用 |
提示
英文名词/描述 | 详细说明 |
|---|---|
构建提示 | 描述了如何为ChatGPT构建答案提示 |
用日语表示提示的“形象” | 为了说明目的而使用 |
使用英文提示的实践 | 实际上使用的是英文版本的提示 |
让我们创建一个PDF上传页面
启用多页面切换 首先,让我们创建一个页面来上传PDF文件。在这个页面上,您可以上传一个PDF文件,然后转到问我的PDF页面来提问。

上传PDF并阅读
- 上传PDF
- 使用PyPDF2库的PdfReader读取PDF文件
- 根据标记数量使用RecursiveCharacterTextSplitter拆分成块
from PyPDF2 import PdfReader
def get_pdf_text():
uploaded_file = st.file_uploader(
label='Upload your PDF here😇',
type='pdf'
)
if uploaded_file:
pdf_reader = PdfReader(uploaded_file)
text = '\n\n'.join([page.extract_text() for page in pdf_reader.pages])
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
model_name=st.session_state.emb_model_name,
chunk_size=250,
chunk_overlap=0,
)
return text_splitter.split_text(text)
else:
return Nonefile_uploader的行为可以通过Streamlit官方文档中列出的参数进行控制。值得记住的参数有type,它允许您指定可以上传的扩展名,和accept_multiple_files,它允许上传多个文件。
属性名称 | 描述 |
|---|---|
label | 用于解释上传器的文件标签的简短标签。标签可以包含Markdown和表情符号。 |
type | 允许的扩展名数组。默认值为None,允许所有扩展名。 |
accept_multiple_files | 如果为True,则用户可以同时上传多个文件。 |
key | 要用作小部件唯一键的任何字符串或整数。 |
help | 在文件上传器旁边显示的工具提示。 |
on_change | 当文件上传器的值更改时调用的可选回调函数。 |
disabled | 禁用文件上传器的可选布尔值。默认值为False。 |
label_visibility | 如果隐藏,则标签label_visibility不会显示,但小部件上方将保留一个空白空间。默认为可见。 |
嵌入摘要文本
什么是嵌入
嵌入是将单词或短语表示为数字向量(连续数字列表)的过程。英语中的“embedding”一词意味着“嵌入”。
将单词或短语转换为数值并将其嵌入向量中在语义上等同于将它们“嵌入”到高维空间中。
Word2Vec是一种相对较新的方法,还有一种更原始的嵌入方法称为BoW(词袋模型)
使用OpenAI Embeddings API进行文本嵌入
利用LangChain的OpenAIEmbeddings模型
from langchain.embeddings import OpenAIEmbeddings
emb_model = OpenAIEmbeddings()
text = "Hello World!"
result = emb_model.embed_documents([text])
print(f'Embedding dimentions: {len(result[0])}')
print(result[0][:5])保存嵌入文本到向量数据库
当进行某个文本的嵌入时,可以快速搜索到相似的嵌入(即相似的文档)。
名称 | 简要描述 | 作者的印象 |
|---|---|---|
Faiss | 由Meta (Facebook)制造的向量数据库。在IT/WEB行业中被广泛使用。 | 搜索性能良好,但由于其简洁性,可能对初学者来说有点难以掌握。缺乏显著的托管服务。 |
Pinecone | 常在LangChain的嵌入示例中使用的向量数据库。有很多样本可用。 | 代码简单且易于操作,但只能在云服务上使用,这使得UI操作变得有些麻烦。 |
Chromia | 一个快速增长的向量数据库,并常与Pinecone一同出现在样本应用中。 | 截至2023年7月,尚无云服务,因此可能难以托管。云服务已列入开发路线图。 |
Qdrant | 在所提供的上下文中将要使用的向量数据库。 | 未指定。 |
转换为嵌入并保存
两个步骤的代码
- load_qdrant函数:准备一个操作向量数据库的客户端
- build_vector_store函数:将PDF的文本转换为嵌入并保存在向量数据库中
from qdrant_client import QdrantClient
from langchain.vectorstores import Qdrant
from langchain.embeddings.openai import OpenAIEmbeddings
QDRANT_PATH = "./local_qdrant"
COLLECTION_NAME = "my_collection"
def load_qdrant():
client = QdrantClient(path=QDRANT_PATH)
# Get all collection names.
collections = client.get_collections().collections
collection_names = [collection.name for collection in collections]
# If the collection does not exist, create it.
if COLLECTION_NAME not in collection_names:
client.create_collection(
collection_name=COLLECTION_NAME,
vectors_config=VectorParams(size=1536, distance=Distance.COSINE),
)
print('collection created')
return Qdrant(
client=client,
collection_name=COLLECTION_NAME,
embeddings=OpenAIEmbeddings()
)
def build_vector_store(pdf_text):
qdrant = load_qdrant()
qdrant.add_texts(pdf_text)
def page_pdf_upload_and_build_vector_db():
st.title("PDF Upload")
container = st.container()
with container:
# The one we made earlier.
pdf_text = get_pdf_text()
if pdf_text:
with st.spinner("Loading PDF ..."):
build_vector_store(pdf_text)
page_pdf_upload_and_build_vector_db()准备客户端以操作Vector数据库
使用qdrant_client库准备一个客户端以操作Vector数据库。
from qdrant_client import QdrantClient
# Saving to local storage
client = QdrantClient(path="./local_qdrant")
# Saving to qdrant cloud (we'll discuss it in detail in the next chapter).
client = QdrantClient(
url="https://my-qdrant-db.us-east-1-0.aws.cloud.qdrant.io:6333",
api_key="api-key-hoge123fuga456"
)将数据保存到本地文件系统并进行操作验证。如果一个集合(类似于数据库表)尚不存在,它将被创建
# Get all collection names.
collections = client.get_collections().collections
collection_names = [collection.name for collection in collections]
# If the collection does not exist, create it.
if COLLECTION_NAME not in collection_names:
client.create_collection(
collection_name=COLLECTION_NAME,
vectors_config=VectorParams(size=1536, distance=Distance.COSINE),
)
print('collection created')配置Qdrant
- 使用embeddings中提供的模型,将给定的文本或文档内容转换为嵌入向量
- 使用向量数据库客户端(client),将生成的嵌入向量存储在向量数据库的collection_name中
def load_qdrant():
return Qdrant(
client=client,
collection_name=COLLECTION_NAME,
embeddings=OpenAlEmbeddings()
)
def build_vector_store(pdf_text):
qdrant = load_qdrant()嵌入PDF文本并保存到向量数据库的方法
def build_vector_store(pdf_text):
qdrant = load_qdrant()
qdrant.add_texts(pdf_text) 如果您使用LangChain文档加载器
Qdrant.from_texts(
pdf_text,
OpenAIEmbeddings(),
path="./local_qdrant",
collection_name="my_documents",
)确认已存储在向量数据库
% sqlite3 collection/my_documents/storage.sqlite
SQLite version 3.38.2 2022-03-26 13:51:10
Enter ".help" for usage hints.
sqlite> .tables
points
sqlite> .schema points
CREATE TABLE points (id TEXT PRIMARY KEY, point BLOB);
sqlite> select * from points;
gASVJAAAAAAAAACMIDNkYmExYjYwZTJiYjQzMGM5NmI0YzJjNWJlMTBlMDU4lC4=|V8
gASVJAAAAAAAAACMIDY4NjdmMzY5MDYxNjQ2NzJhNGRmNTVkNDY1NThjNjNmlC4=|9
gASVJAAAAAAAAACMIDY5OWYzZWRhODc3YjRlZTJhYTNlZDQ2YzVjODUxMzQ4lC4=|8
sqlite> select count(*) from points;
235import qdrant_client
from langchain.vectorstores import Qdrant
from langchain.embeddings.openai import OpenAIEmbeddings
client = qdrant_client.QdrantClient(path="./local_qdrant")
qdrant = Qdrant(
client=client,
collection_name="my_collection",
embeddings=OpenAIEmbeddings()
)
query = "Regarding Toyota's financial results."
docs = qdrant.similarity_search(query=query, k=2)
for i in docs:
print({"content": i.page_content, "metadata": i.metadata})向PDF提问(第2部分:检索问答)
您将在本章学习什么
- 如何向PDF(LangChain RetrievalQa)提问
- 如何在云端创建向量数据库
从提问到PDF的过程
从提问到生成PDF的过程
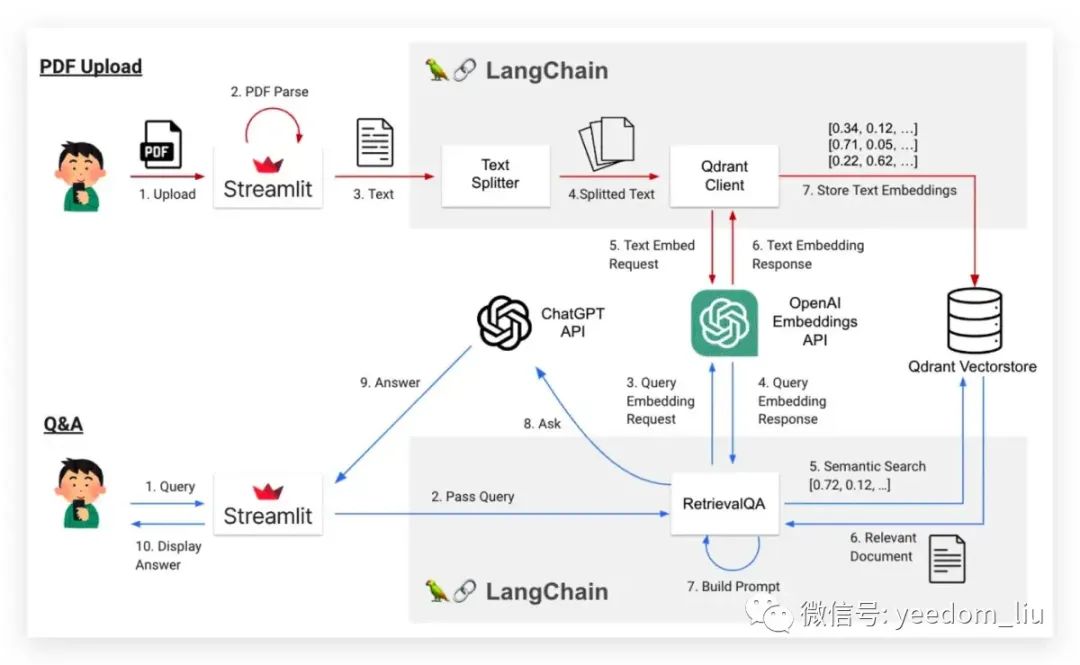
- 用户在Streamlit中编写一个问题(查询)。
- Streamlit将问题传递给LangChain。
- 该问题被传递到OpenAI Embeddings API。
- 问题以嵌入形式返回。
- 基于第4步获得的嵌入,从向量数据库中搜索相似的文档(块)(这与语义地搜索相关上下文相似)。
- 从向量数据库返回相似的文档。
- 第6步获得的内容被替换为提示以创建一个提示。
- 提示被传递给ChatGPT API以提出一个问题。
- ChatGPT API返回一个答案。
- 答案在Streamlit中显示。
实现问题和回答
- load_qdrant函数:准备操作向量数据库的客户端(与我们在上一章中创建的相同)。
- build_qa_model函数:调用LangChain特性(RetrievalQA),使用向量数据库进行问答。
- ask函数:使用RetrievalQA执行问答。
from qdrant_client import QdrantClient
from langchain.vectorstores import Qdrant
from langchain.embeddings.openai import OpenAIEmbeddings
QDRANT_PATH = "./local_qdrant"
COLLECTION_NAME = "my_collection"
def load_qdrant():
"""
它与上一章创建的内容完全相同,所以我将省略它.
client = QdrantClient()
...
def build_qa_model(Ilm):
qdrant = load_qdrant()
...
)
def ask(qa, query):
with get_openai_callback() as cb:
...功能描述 | 详细内容 |
|---|---|
RetrievalQA的核心角色 | 利用附加的上下文信息进行问答 |
检索上下文信息 | 1. 从数据库中检索与用户问题相关的文本。 <br> 2. 语义搜索用于从数据库中检索上下文信息。 |
具体操作 | 1. 嵌入用户的问题(图中的3/4步骤)。 <br> 2. 搜索并检索与该嵌入接近的文本(图中的5/6步骤)。 <br> 3. 将检索到的上下文信息嵌入到提示中以生成提示(图中的7步骤)。 |
检索方法的调整 | 可以通过retriever选项进行调整 |
调整生成响应的方法 | 使用chain_type参数。例如,将其设置为map_reduce或类似方法时,可以考虑甚至非常长的上下文。 |
def build_qa_model(llm):
qdrant = load_qdrant()
retriever = qdrant.as_retriever(
# There are also "mmr," "similarity_score_threshold," and others.
search_type="similarity",
# How many documents to retrieve? (default: 4)
search_kwargs={"k":10}
)
return RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever,
return_source_documents=True,
verbose=True
)
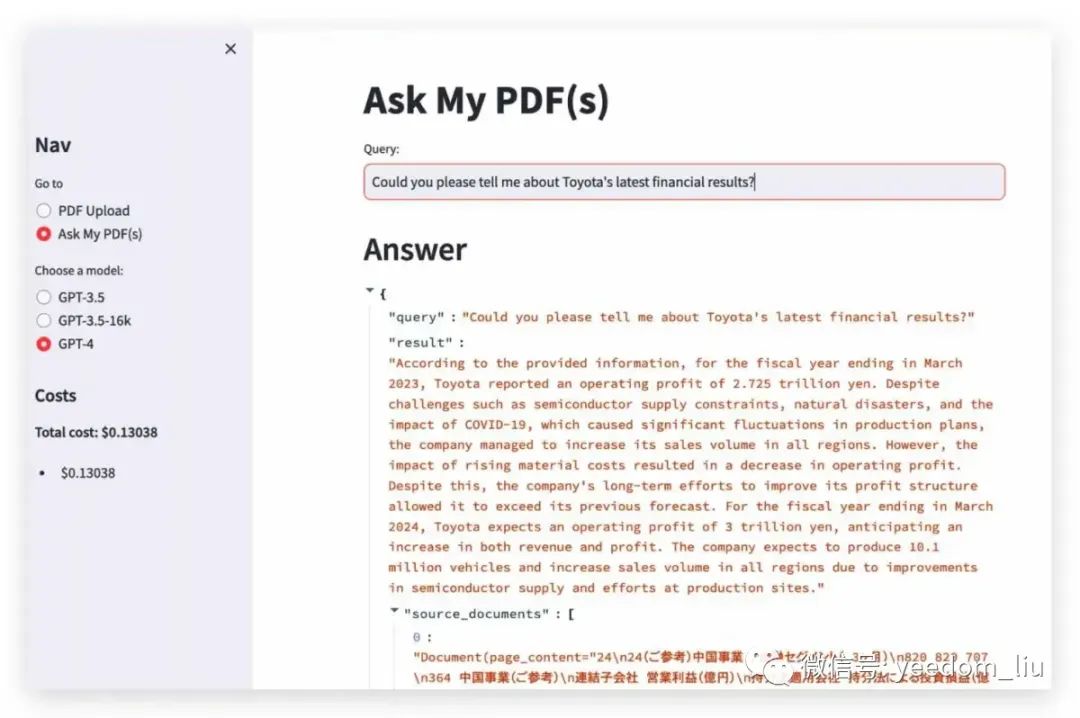
query = "Let me briefly tell you about Toyota's latest financial results."
qa = build_qa_model(llm)
answer = qa.run(query)用检索器选项调整搜索方法
搜索类型: 调整搜索方法
# Here's an example of using the similarity_score_threshold.
retriever = db.as_retriever(
search_type="similarity_score_threshold",
search_kwargs={"score_threshold": .5}
)
# Here's an example of limiting the context of retrieval using filters.
retriever = db.as_retriever(
search_kwargs={
"filter": {"company": "toyota"}
}
)参数名称 | 描述 | 详细说明 |
|---|---|---|
mmr | 使用最大边际相关性(Maximum Marginal Relevance) | 为了尽量避免重复的响应。如果响应中有相似的上下文信息,它将被适度地稀释。详细信息可以通过Google或ChatGPT等搜索“最大边际相关性”来获得。 |
similarity_score_threshold | 设置一个相似性阈值 | 如果相似性低于此阈值,它将不被使用。该参数需要与后面提到的similarity_score_threshold一同使用。 |
各种参数设置
参数名称 | 描述 | 详细说明 |
|---|---|---|
k | 指定搜索时要命中的文档数量 | 默认值:4(在本书中设置为10) |
score_threshold | 当在search_type中选择similarity_score_threshold时使用 | 设置相似性分数的阈值 |
filter | 在Qdrant中,如果在创建向量DB时为每条记录设置了元数据,你可以使用它来调整要检索的上下文 | 请另行检查在其他向量DBs中的兼容性 |
在RetrievalQA中使用的提示
#
https://github.com/hwchase17/langchain/blob/master/langchain/chains/question_answering/stuff_prompt.py
prompt_template = """Use the following pieces of context to answer the question at the end.
If you don't know the answer, just say that you don't know,
don't try to make up an answer.
{context}
Question: {question}
Helpful Answer:"""如果您想调整问题回答的方式或确保以其他语言给出回答,设置提示可以是一种有效的方法。
我们对PromptTemplate进行了轻微修改
prompt_template = """Use the following pieces of context ... Answer in Italian:"""
PROMPT = PromptTemplate(
template=prompt_template, input_variables=["context", "question"]
)
qa = RetrievalQA.from_chain_type(
llm=llm
chain_type="stuff",
retriever=qdrant.as_retriever(),
# Specify here
chain_type_kwargs={"prompt": PROMPT}
)
query = "What did the president say about Ketanji Brown Jackson"
qa.run(query)
" Il presidente ha detto che Ketanji Brown Jackson è una delle menti legali più importanti del paese, che
continuerà l'eccellenza di Justice Breyer e che ha ricevuto un ampio sostegno, da Fraternal Order of Police
a ex giudici nominati da democratici e repubblicani."load_qa_chain提供了最常见的问答接口,并且在 Retrievalqa 内部也使用它。但是,因为它没有Retrieval函数(), 所以需要使用整个给定的文档进行问答。
共享向量数据库(Qdrant Cloud)
https://cloud.qdrant.io/
云向量数据库
curl \
-X GET 'https://xxxxxxx-xxxx-xxxx-xxxx-434eab336aa0.us-east4-0.gcp.cloud.qdrant.io:6333' \
--header 'api-key: xxxxxxxxxxxxxxxxxxxxxxxxx'def load_qdrant():
# This is what I had written before.: client = QdrantClient(path=QDRANT_PATH)
# Get url, api_key from Qdrant Cloud dashboard
client = QdrantClient(
url="https://hogehogehogehoge.us-east-1-0.aws.cloud.qdrant.io:6333",
api_key="api-key-hogehogehogehoge"
)设置成环境变量
def load_qdrant():
client = QdrantClient(
url=os.environment['QDRANT_CLOUD_ENDPOINT'],
api_key=os.environment['QDRANT_CLOUD_API_KEY']
)结论
有用的特性
特性 | 描述 |
|---|---|
Agent | LangChain允许使用AI代理来解决任务,可能创建自主代理,但要使其智能行动具有挑战性。 |
Function Calling | 提供JSON格式的ChatGPT API响应,便于与其他功能集成,因此受到开发人员的欢迎。 |
Zapier Integration | 与Zapier集成允许执行基于触发器的自动化任务,如检查电子邮件并起草回复。 |
ChatGPT Plugin Integration | 提供将ChatGPT插件集成为代理工具的选项,扩展了可能任务的范围。 |
Asynchronous Processing | LangChain支持异步处理,调用ChatGPT API时有用,适用于希望更多控制和透明度的解决方案。 |
Caching | LangChain包括各种缓存机制,用于存储和检索先前的答案,对于提高响应时间至关重要,特别是对于经常使用的服务。 |
BigQuery Integration | 与BigQuery的集成是可能的,适用于数据分析师。LangChain可以使用表模式和示例记录有效地编写SQL查询。 |
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-10-15,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号