从小数据到大数据,架构经历了怎样的演变
原创

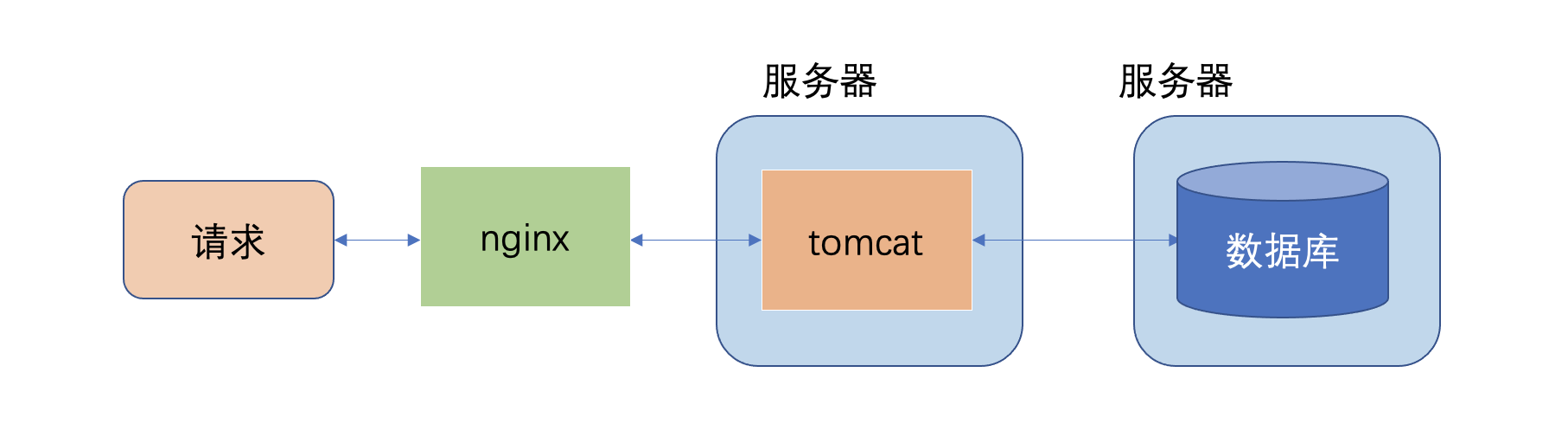
小数据时代
- 数据量较小,可以在单机上进行处理
- 使用关系型数据库如MySQL存储和处理数据
- 对数据量和处理时延要求不高
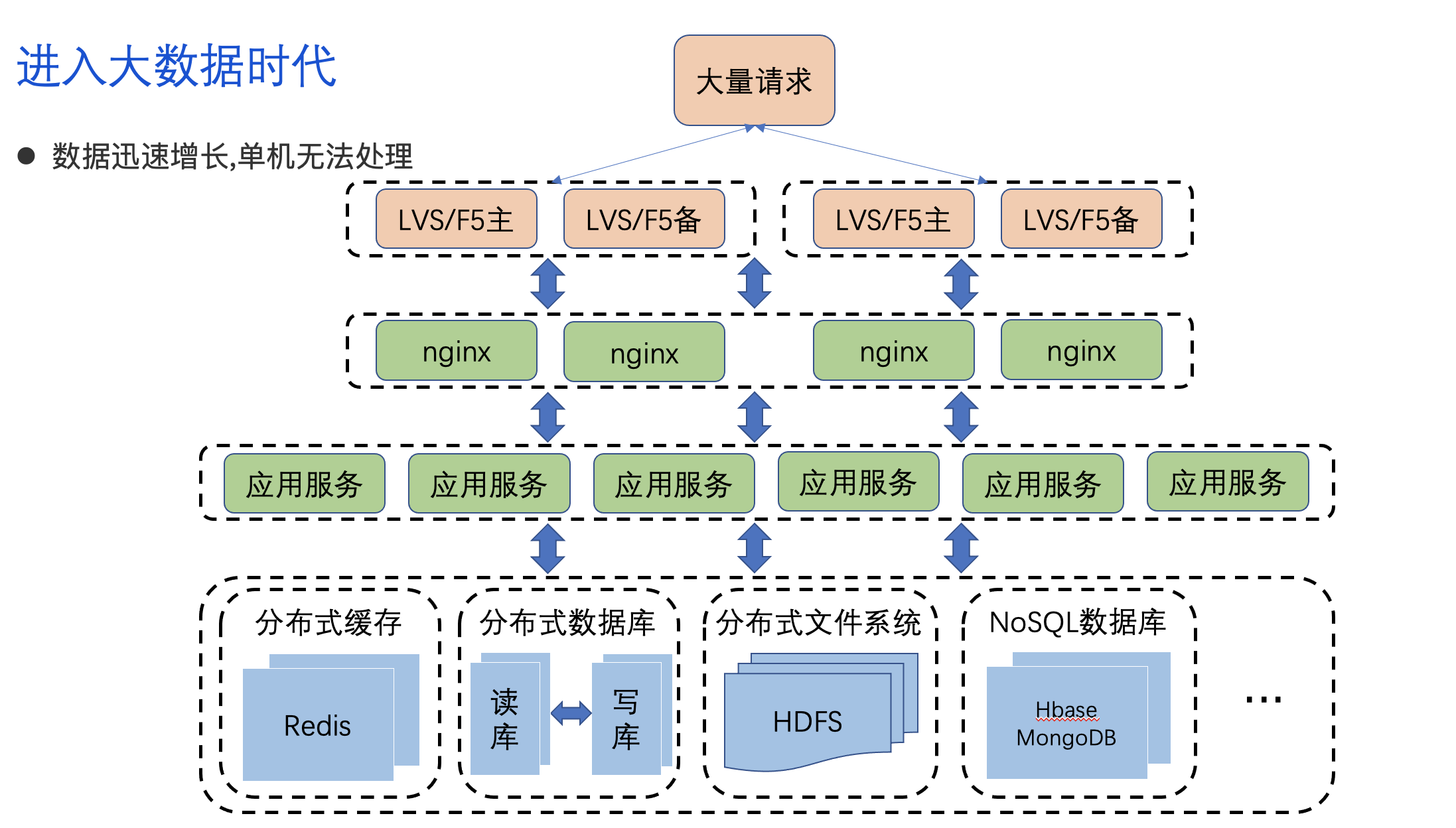
进入大数据时代
- 数据迅速增长,单机无法处理
- 使用Hadoop/Spark进行分布式数据存储和处理
- 利用MapReduce批处理流程分析数据
实时计算的需求
- 对数据分析时效性要求提高
- 需要在秒级甚至毫秒级进行数据处理
- 实时计算框架Storm、Spark Streaming诞生
复杂业务处理的需求
- 需对数据进行复杂转换和多源关联分析
- 批处理引擎具备更强大的处理能力
- 但批处理难以做到实时
复杂业务处理的典型需求包括:
多源异构数据关联分析
- 需要关联数据库、日志、文本、多媒体等多种格式、多来源的数据
- 对各类数据进行清洗、转换、关联,得到关联视图
- 例如用户行为数据与商品数据的关联
海量数据聚合计算
- 对大量数据进行分组、排序、聚合等算子运算
- 比如对用户行为按地区分组统计
- 需要高吞吐量和低延迟来处理大量数据
流式计算和窗口分析
- 对实时数据流进行窗口化分析运算
- 如每5分钟统计一次指标,或每日用户活跃计算
- 需要支持流式数据并行处理
迭代机器学习算法
- 运行机器学习迭代算法,如PageRank等
- 每次迭代需扫描全量数据,需高效处理
交互式分析和数据挖掘
- 交互式查询和多次迭代分析
- 用户进行数据挖掘和模型调优的迭代过程
- 需要低延迟迭代计算
离线深度学习模型训练
- 在大数据集上进行深度学习模型的训练
- 计算量巨大,需要分布式训练加速
- 但对训练准确率要求较高
lambda架构如何解决痛点
以上各阶段大数据平台的痛点:
- 实时计算与批处理分离,两套系统维护困难
- 只能进行简单实时计算,无法应对复杂业务需求
- 数据不一致,实时处理的数据可靠性差
lambda架构如何解决这些痛点:
- 统一的架构包含实时和批处理两部分
- 实时层保证低延迟数据处理
- 批处理层提供精确可靠的计算
- 两层结果统一,兼顾时效性和正确性
lambda架构的优缺点
优点:
- 统一处理实时和离线数据
- 兼顾低延迟和高吞吐量
- 结果精确可靠,容错性高
缺点:
- 维护两个层的计算引擎,复杂度高
- 批处理层重复处理实时层数据
- 增加了端到端延迟
lambda架构的优缺点导致它逐步演化出kappa架构
lambda架构需要维护两套计算引擎,运维复杂度高
- 实时层和批处理层需要各自构建计算集群,代码维护不易扩展
- 数据需要从实时层传输到批处理层,工程实现复杂
批处理层重复处理实时层数据,资源利用率低
- 实时层数据已处理,但还要投入批处理层重新计算
- 大量重复计算导致计算资源和时间成本高
增加了端到端的处理延迟
- 需等待批处理层完成才能得到最终结果
- 无法实现完全实时化的数据处理
针对上述痛点,kappa架构进行了改进:
- 只保留统一的实时处理流程,不再有批处理层
- 利用更强大的实时处理引擎兼顾吞吐量和延迟指标
- 通过重演机制重新计算和纠正实时处理的错误
- 简化了架构,降低维护成本,减少重复计算
但kappa也存在一些新的痛点和限制:
重演开销大
- kappa架构依赖重演机制来纠正错误,但重演整个数据集非常消耗资源。
- 重演越频繁,导致资源利用率下降。
难以处理超大数据量
- 批处理层拥有处理超大规模数据的能力。
- 单纯依赖实时计算进行重演,面对巨大数据时资源压力巨大。
计算精度难于批处理
- Spark等实时引擎精度不如离线 MapReduce。
- 对结果精度要求极高的场景难以实现。
无法访问历史数据
- 没有批处理层的历史数据存储。
- 无法像Hadoop那样访问历史数据。
技术栈单一依赖实时计算
- 整个处理流程过于依赖实时计算引擎。
- 如果实时计算框架发生故障,整个系统可用性受影响。
根据lambda和kappa架构各自的特点,不同的场景可以选择使用不同的架构:
适合使用lambda架构的场景:
- 对结果正确性要求极高,需要进行重复计算来保证精度
- 需要进行大规模复杂分析,如机器学习等
- 同时需要实时化和批量计算能力
- 需要访问很久以前的历史数据
- 允许端到端延迟相对较高
适合使用kappa架构的场景:
- 对实时性要求较高,需要毫秒或秒级延迟
- 数据规模较小或中等,不需要进行超大规模计算
- 业务需求稳定,不常有新的复杂计算需求
- 能接受偶尔的计算错误
- 只需要访问最近一段时间的数据
综合来说:
- 如果需要同时兼顾批处理和实时计算,以及强调结果的正确性,lambda架构更合适。
- 如果仅需要实时处理,以及追求最小化延迟,kappa架构更合适。
- 在选择时还需要结合具体业务场景,技术栈等因素进行区别评估。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号