Python 爬虫之 Request +re


什么是爬虫?
它是指向网站发起请求,获取资源后分析并提取有用数据的程序;
爬虫的步骤:

1、发起请求
使用http库向目标站点发起请求,即发送一个Request
Request包含:请求头、请求体等
2、获取响应内容
如果服务器能正常响应,则会得到一个Response
Response包含:html,json,图片,视频等
3、解析内容
解析html数据:正则表达式(RE模块),第三方解析库如Beautifulsoup,pyquery等
解析json数据:json模块
解析二进制数据:以wb的方式写入文件
4、保存数据
数据库(MySQL,Mongdb、Redis)文件
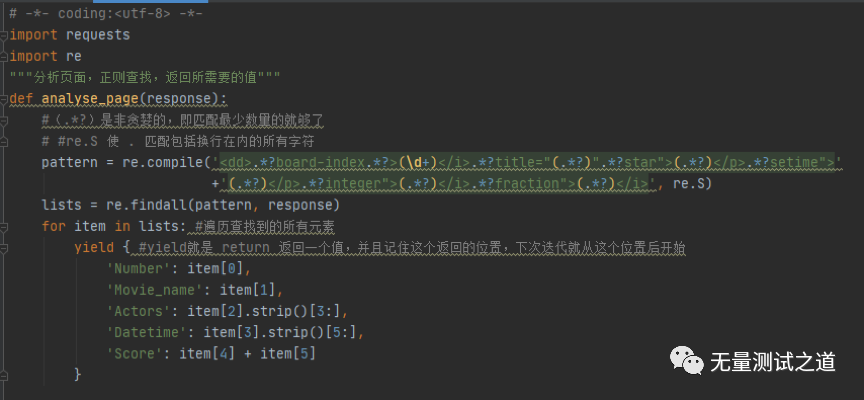
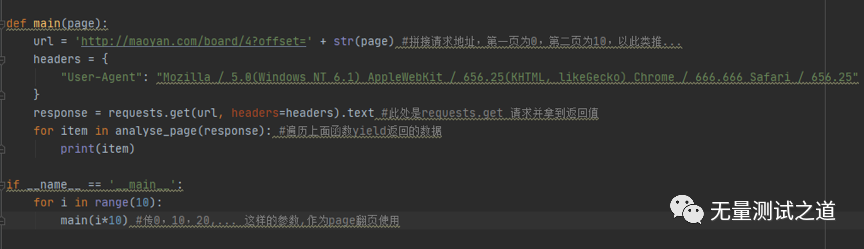
废话不多说,直接上代码截图(本文以抓取猫眼网站电影数据为示例):
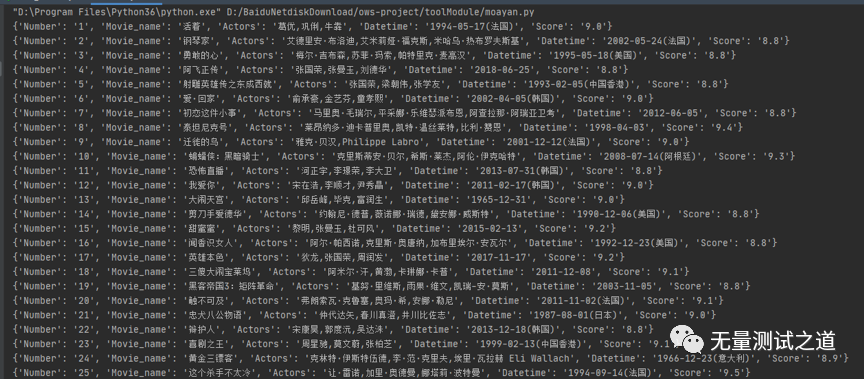
以下是执行后输出的结果:
备注:代码截图中有详细的注释信息,所以不在文中再来说明代码中的用法。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-08-18,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号