asio调度器实现 - 总览篇


导语: 因为网络相关的抽象和实现确实做得非常棒, 很多时候我们都将asio视为一个网络库, 而忽略了它其实一直做得非常好的通用任务调度这部分的功能. 而本系列文章我们将区别于大部分asio的学习资料, 我们将暂时抛开asio外围的平台相关网络实现等内容, 对它的任务调度部分的实现做详细的剥析. 系列文章的大部分内容最开始是作为executions系列文章中, 对比executions稍显薄弱的scehduler实现而存在的背景资料. 但通过一段时间的executions实践, 介于它本身并未正式通过标准, 依赖的concepts等内容compiler的报错等支持都暂未很好的跟上, 我们将目光转向了更容易落地的asio通用任务调度, 已经被标准和各大编译器良好支持的coroutine特性, 作为本阶段重点推进的异步调度实现基础, 感觉这部分可挖掘的实际价值和潜力都比较大, 所以将asio调度器系列的资料重新整理, 理清自己思路的同时, 也希望对大家有所帮助.
1. ASIO版本现状简介
ASIO是一个久经迭代的库, 所以版本比较多, 不同版本的差异也比较大, 在开始具体的讲述前, 我们先来看一下ASIO的版本情况, 也方便大家知道我们所选用的ASIO版本, 以及它与最新的版本的差异所在.
ASIO从1.17(2020)开始尝试向当时的executions提案靠拢, 当时的executions提案从最原始的Api数量爆炸的版本, 转向了通过引入property对api复杂度进行简化的版本, 众所周知的, 引入property的executions提案依然表现不尽如人意,现在的executions提案已经彻底抛弃了基于property的这套提案, 但 asio 的作者作为executions提案的发起者之一, 还是在按相关提案的思路在迭代整体的asio库, 所以代码中大量存在了property相关的设施和使用, 这里简单列出一些相关的示例代码:
asio::static_thread_pool pool(1);
auto ex1 = ctx.get_executor();
// Get the number of available threads in the pool.
std::size_t n = asio::query(ex1, asio::execution::occupancy);
// Require an executor with blocking.never property.
auto ex2 = asio::require(ex1, asio::execution::blocking.never);
asio::execution::execute(ex2, []{ /*...*/ });
// Prefer an executor that uses a custom allocator.
auto ex3 = asio::prefer(ex2, asio::execution::allocator(my_allocator));
asio::execution::execute(ex3, []{ /*...*/ });如上面的代码所示, property主要通过三个模板函数来工作: 1. query(): 查询某属性的值 2. require(): 获取满足对应属性的对象 3. prefer(): 获取包含定制内容的对象
对于系统本身特别复杂, 需要适应的场景特别多的情况 , 这种设计本身确实会简化部分业务侧的使用理解复杂度, 原来对多种不同Api的记忆, 变成了property的选择.
但其实对于库本身的实现来说, 我们也容易看到, 利用property对多种并发泛式进行约束的方式, 本身就具备一定的复杂度, 尤其是对于asio本身来说, 我们会发现原来的实现变得更难理解了. 对于库的构建来说, 很难说它提供的是一个简单易扩展的机制.
这点从tag_invoke提案中拿自身跟property对比的相关示例也能看得出来两者表达能力上的落差. 个人认为, 同样是对库的定制和对泛型的支持的目的, 基于cpo的tag invoke本身应该是更值得选择的, 而property本身我感觉比cpo的理解成本要更高, 用于构建库代码, 也会导致库代码本身的复杂度变高, 在它没有成为C++标准的一部分之前, 这种复杂度的引入肯定是不那么合适的.
这种复杂度的增加我们从当前asio 1.22代码仓库可以比较容易看出, 主体功能变化不大(对比1.16版本), 但引入了相当多的代码用于在兼容低版本c++的情况下对property等基础功能进行支持, 导致整体代码复杂度剧增, 但实际带来的便利性基本看不到. 如果抛开对新特性的预研本身, 这些调整对asio的版本迭代来说, 可以说跟优雅本身相去甚远的.
对比向早期execution的靠拢, asio 对c++20 coroutine的支持还是可圈可点的, 这个从作者近期的实例代码讲解中也能感受到, 像awaitable的"||" "&&"等支持, 很好的扩展了协程中多任务处理的语义, 更容易用更少的代码实现出简单易理解, 易维护的异步代码.
回到scheduler本身, 我们本篇的重点是asio的scheduler部分实现, 这部分在asio加入property机制前后其实变化不大, 但由于加入property后, 相关的scheduler部分耦合了大量的property相关的机制和代码, 带来了比较高的复杂度, 本文我们直接选择不包含property的asio1.16的代码进行展开, 方便以更低的复杂度分析相关的实现.
2. asio对通用任务的支持
尽管我们通常将ASIO作为网络库使用,但实际上,它在支持通用任务调度方面也表现出色。借助C++11引入的lambda和函数对象,我们可以将通用任务包装成lambda,然后使用post()方法将其提交到某个io_context上, 整个任务派发的过程也是现在众多游戏引擎所使用的lambda post式的异步任务派发机制。大体的过程如下图所示:
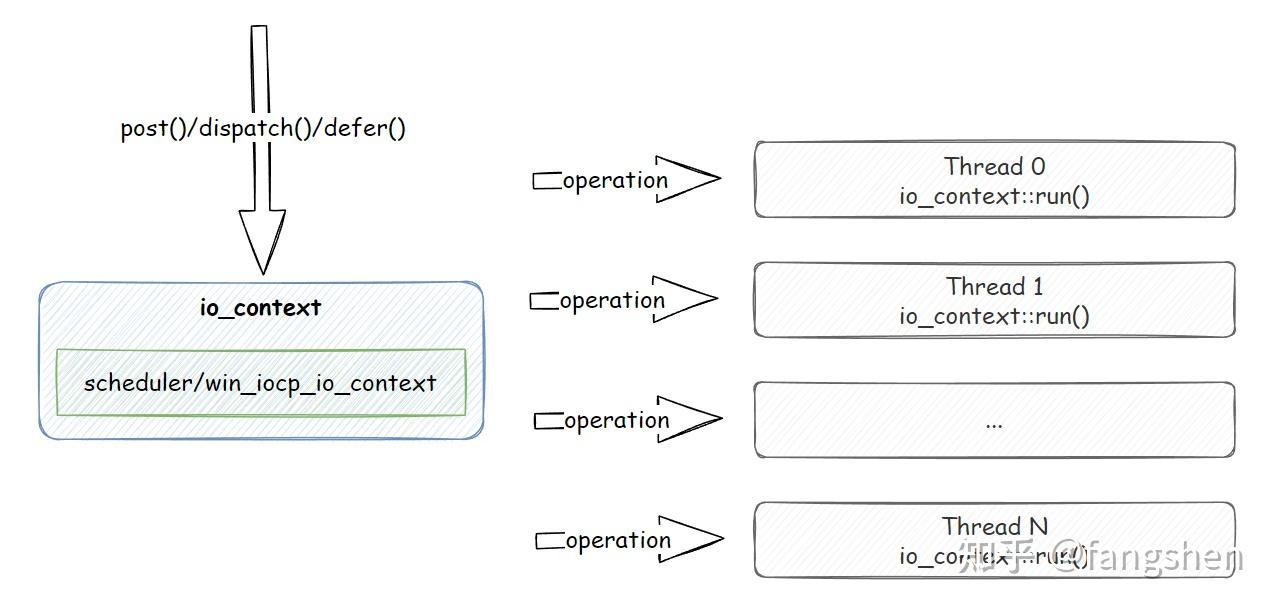
我们一般是通过io_context内的scheduler impl的post(), dispatch(), defer()这三个方法之一将业务侧的lambda传递给asio, asio会将对应的lambda存储为一个operation, 也就是一个任务, 而具体的operation最后会被执行io_context::run()的线程所执行.
[!hint] 需要注意的是
asio没有使用句柄式的方式对operation进行管理, 在需要返回值的情况下, 是通过额外的async_result的模板来完成异步传值等操作的. 下文中我们会对async_result做简单的介绍.
2.1 项目应用实例简介
ASIO所使用调度器本身就是一个很通用的lambda post机制, 所以将ASIO作为通用的并发框架当然也是切实可行的。实际上,网易的许多项目都采用了这种方法。最初是他们的服务器将ASIO作为底层并发框架,后来知名度较高的Messiah引擎也借鉴和发扬了这种方式,将ASIO作为底层基础的并发框架。
当然, 实际项目的使用中一般会将ASIO作简单的包装, 为了方便大家的理解, 这里直接以笔者所在的CrossEngine项目举例(CrossEngine是一个游戏引擎, 下文我们简称CE), 方便大家理解如何将ASIO用作通用的异步调度器的.
2.1.1 隔离式的ASIO使用
游戏引擎中一般会涉及到多个线程之间的任务调度, 下图是CE框架层中的asio::io_context与线程的关系和分组:
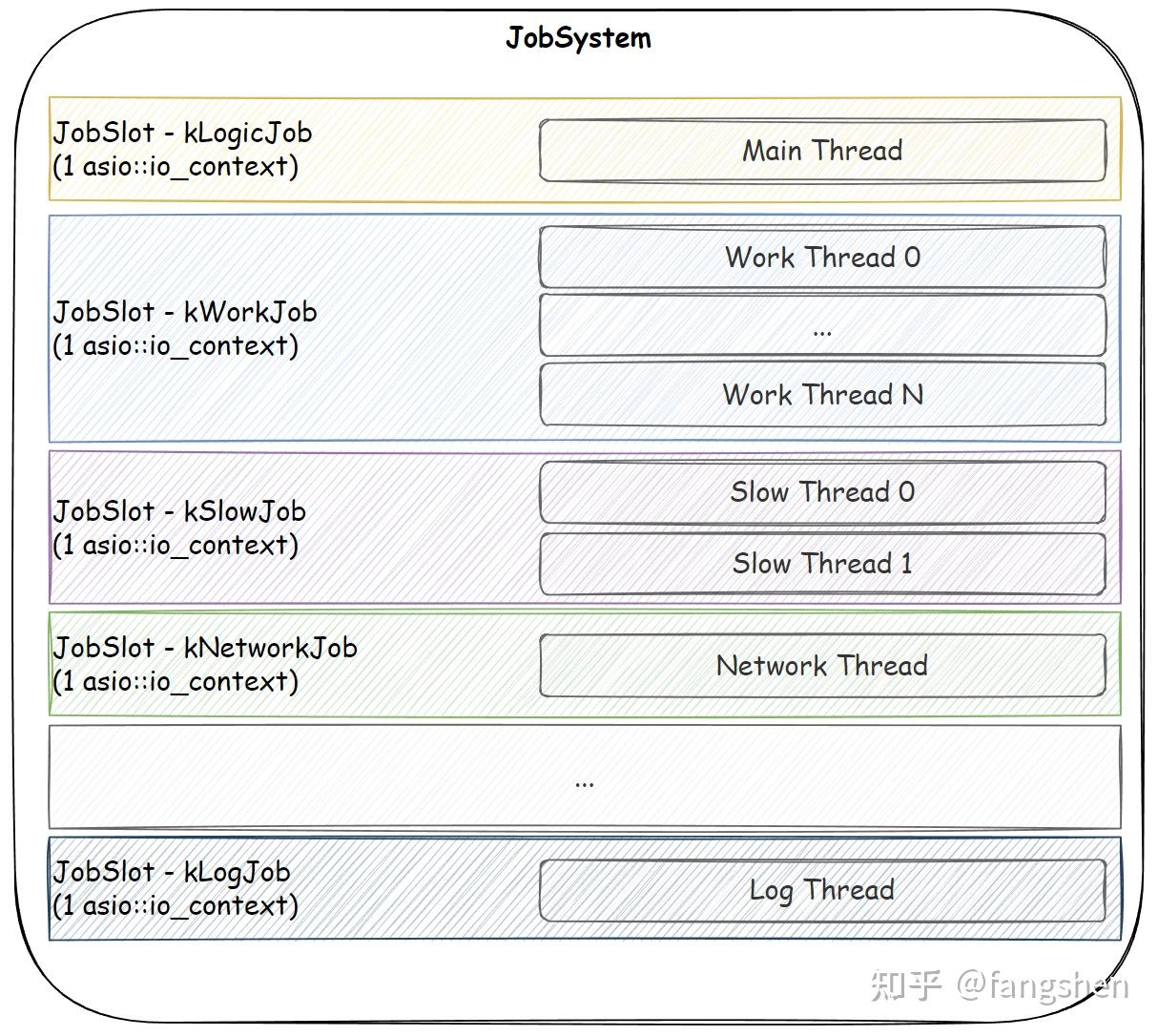
JobSystem图
整体的封装是比较简洁的: 1. 外围的JobSystem负责对所有的JobSlot进行管理 2. 每个JobSlot一一对应一个asio::context 3. 每个JobSlot会创建一组线程池用于其关联的asio::io_context的任务的调度, 也就是每个线程调用io_context::run()来执行投递来的任务. 4. 主线程(逻辑线程)是比较特殊的存在, 我们一般是使用手动驱动其工作的模式. 5. 业务侧使用JobType枚举来选择对应的asio::io_context来进行任务的投递, 这样就对业务侧适当隔离了asio本身, 枚举也易于记忆和使用.
2.1.2 JobType 简介
JobType 本身也是一种业务侧对任务进行分组的方式, 不同的 JobType 对应的是某一类粒度或者业务特性相近的任务, 如 kWorkJob, 对应的是一组工作线程, 我们希望在其上执行的任务粒度都是非常小的, 这样在有很多任务被投递到工作线程上的时候, 它们可以很好的并发, 而不是出现长时间等待另外一个任务完成后才能被调度的情况.
具体在CE框架层中对应JobType的定义如下:
enum class JobType : int {
kLogicJob = 0, // logic thread(main thread)
kWorkJob, // work thread
kSlowJob, // slow work thread(run io or other slow job)
kNetworkJob, // add a separate thread for network
kNetworkConnectJob, // extra connect thread for network
kLogJob, // log thread
kNotifyExternalJob, // use external process to report something, 1 thread only~~
kTotalJobTypes,
};JobType的具体使用是: - kLogicJob - 主线程(逻辑线程)执行任务 - kWorkJob - Work Thread线程池执行任务(多个), 一般是计算量可控的小任务 - kSlowJob - IO专用线程池, IO相关的任务投递到本线程池 - kNetworkJob - 目前tbuspp专用的处理线程 - kNetworkConnectJob - 专用的网络连接线程, tbuspp模式下不需要 - kLogJob - 日志专用线程, 目前日志模块是自己起的线程, 可以归并到此处管理 - kNotifyExternalJob** - 专用的通知线程, 如lua error的上报, 使用该类型
2.1.3 一个简单的文件异步读取示例
对于一个简单的异步任务, 它可能的执行状态是先在某个线程上做阻塞式的执行, 然后再回归主线程进行回调, 如下图所示:
sequenceDiagram
Logic Job ->>+Work Job: calculate task
Work Job ->>-Logic Job: calculate result这里我们给出CE中的异步文件读取代码为例:
auto ticket = GJobSystem->RequestTicket();
auto fullPath = GetFullPath(relPath);
GJobSystem->Post(
[this, ticket, relPath, fullPath, loadFunc]() {
ByteBufferPtr outBuf;
try {
std::ifstream f;
f.open(fullPath, std::ios_base::binary | std::ios_base::in);
f.seekg(0, std::ios_base::end);
size_t totalSize = (size_t)f.tellg();
f.seekg(0, std::ios_base::beg);
outBuf = std::make_shared<ByteBuffer>(totalSize + 1);
f.read((char*)outBuf->WritePtr(), totalSize);
outBuf->WritePtr()[totalSize] = 0;
outBuf->WritePosition(totalSize);
f.close();
} catch (std::exception& ex) {
ERR_DEF("Read file failed, name:%s, err:%s", fullPath.c_str(), ex.what());
}
GJobSystem->Post(
[outBuf, ticket, relPath, loadFunc]() {
if (ticket) {
loadFunc(ticket, relPath, "", outBuf);
}
},
JobType::kLogicJob);
},
JobType::kSlowJob);
return ticket;我们用两次Post()完成了文件的异步读取: 1. 第一次Post()后的任务会在kSlowJob上执行, 最后会被投递到JobSystem图上的两个Slow Thread之一进行执行. 2. 在完成文件的IO后, 会进行第二次的Post(), 将文件读取的结果投递给主线程, 在主线程回调相关的callback.
2.1.4 流水线式任务的示例
在CE中, 结合对asio::strand的封装, 对于下图中的流水线式任务:
sequenceDiagram
participant L as Logic Job
participant W1 as Work Job1
participant W2 as Work Job2
participant W3 as Work Job3
L ->>W1: part 1
activate W1
W1 ->>W2: part 2
deactivate W1
activate W2
W2 ->>W3: part 3
deactivate W2
activate W3
W3 ->>W2: part 4
deactivate W3
activate W2
W2 ->>L: return
deactivate W2我们直接使用代码:
auto strand = GJobSystem->request_strand(gbf::JobType::kWorkJob);
starnd.post([](){
//part1~
// ...
});
starnd.post([](){
//part2~
// ...
});
starnd.post([](){
//part3~
// ...
});
starnd.post([](){
//part4~
// ...
});
starnd.post([](){
GJobSystem->post([](){
//return code here
// ...
}, gbf::JobType::kLogicJob);
});就完成了这类链式任务的实现, 这样也能避免让具体的业务关注过于底层的复杂设计.
2.1.5 lambda post小议
对于lambda post类型的JobSystem实现来说, 整体设计上都是大同小异的, 可能差别比较多的地方主要体现在这两处: 1. 线程池的表达, 像CE这种是比较简约的设计, 某个线程创建后, 它对应执行的任务类型就被固定下来了, 但部分引擎如Halo, 使用的是更具公用性的线程, 一个线程可以对某几类任务进行调度. 后者的设计实现更紧凑, 间接可以实现减少总线程数, 那肯定也意味着更低的thread context switch了, 但底层的任务获取也会相对更复杂一些. 2. 依赖asio::strand这类设施, 我们能够补齐多工作线程上的线性表达能力, 但对于更复杂的DAG类型的组合任务表达, 每个引擎可能都会有自己差异化的实现. 本系列主要关注的是asio本身, 这部分暂时不进行展开了.
3. ASIO不同平台下的调度器实现
ASIO原本的设计是针对网络任务为主的, 区别于主流的Reactor模型, ASIO本身的设计和架构使用了Proactor模型.
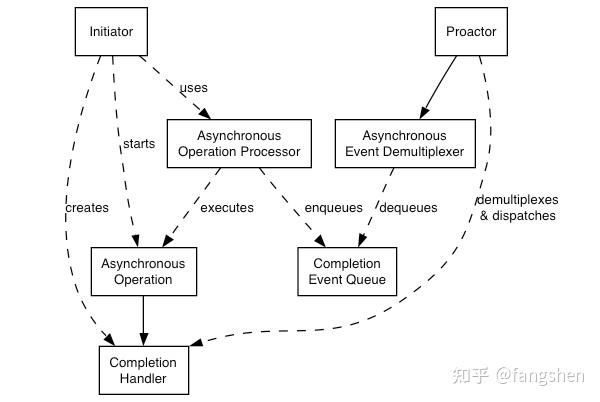
[!note] 这张图可以说完全就是IOCP的一个工作情况了, Linux新出的io_uring, 概念上与此略有出入, 目前看到的最新版的1.22的实现中, io_uring的实现本身依然还是使用了跨平台的scheduler, 并没有像iocp一样, 利用操作系统本身提供的API完成整个scheduler的实现.
之所以是这种设计,也是有一定的历史原因的, 很长一段时间里, 真正比较完整的实现了高效的操作系统级的AysncIO, 并被大家接受使用的, 也就只有Windows平台的IOCP了.
当然, 这种情况最近几年得到了改善, linux平台的新秀io_uring, 也被越来越多的人关注和使用起来, 不过此处我们选的是1.16的版本, 并未包含io_uring的实现, 我们先暂时不考虑它的存在.
操作系统级别是否原生支持async io, 制约了asio本身Proactor模型的跨平台实现, 相关的异步任务调度, 也自然的分裂成了多套实现:
- Windows: 因为IOCP的存在, ASIO 的 Proactor 模型本身可以完全使用 IOCP 本身来很好的进行实现, 对应的异步调度器也是使用 win_iocp_io_context来实现的.
- 其它平台: 只能选用妥协的方式, 使用Reactor + 外围跨平台的 scheduler 结合的模式, 来模拟Proactor模型, 最终实现一个业务层与IOCP使用体验完全一致的跨平台的Proactor模型.
对于CE所在的项目来说, 跨平台的一致性和维护的简洁性具备更高优先级, 所以我们主要使用的是第2种方法中的 scheduler. 而这个不依赖操作系统特性, 跨平台的 scheduler 这也是本文分析的重点, 感兴趣的读者可以在熟悉跨平台的 scheduler 实现后再来阅读 win_iocp_io_context 的实现, 对完成端口熟悉度比较高的话, 结合对scheduler 的理解, 相关的代码是比较好熟悉的.
另外 reactor 本身的实现也跟 scheduler 的工作是解耦的, 所以本文我们的分析中选择直接略过 reactor 部分, 集中精力关注 scheduler 本身的实现机制.
[!tip] 因为本篇我们主要关注 ASIO 的调度器设计部分, 本章网络模型相关的只是简单给出相关的概念, 了解它背后的实现思路, 方便大家更好的理解整个调度器的设计和实现思路.
4. 调度的基础 - operation 和 async_result 简述
在前面看到的ASIO调度图中:
我们知道任务在投递至ASIO后, 每个任务会被包装为一个 operation 对象, 最后再在具体的线程上被调度执行.
另外, 很多时候我们处理异步任务的时候, 是有具体的返回值预期的. 所以ASIO也需要提供相应的定制点, 方便业务扩展相关的异步设施.
为此, ASIO专门设计了async_result<CompletionTocken, Signature>模板类, 我们根据使用场景对async_result进行特化, 特化相关的类型和函数实现, ASIO即可利用相关的特化完成我们预期的抽象了, 一个符合条件的async_result<>特化需要实现以下这些内容:
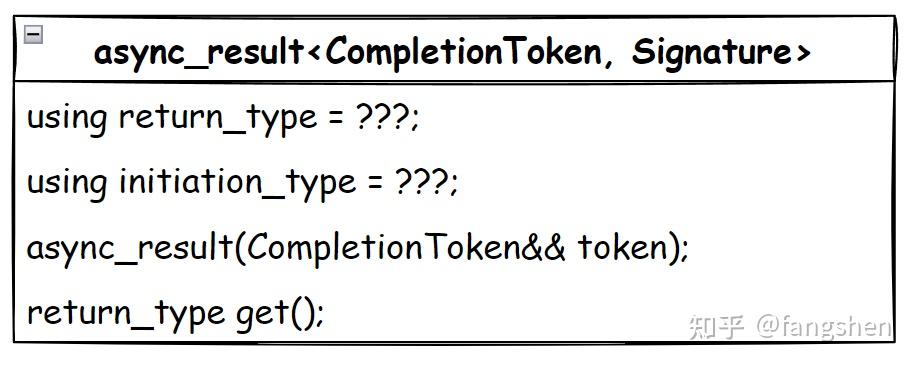
对于简单的类型来说, 这种定制点机制能够很好的发挥作用, 增加的复杂度是比较可控的. 但对于 coroutine 来说, 在后续<<coroutine实现详解>>篇中, 我们可以看到, 依托于async_result对 croutine 进行抽象, coroutine 本身的复杂度与 async_result 特化的复杂度叠加, 再加上协程本身的调用栈也需要框架进行维护, 很快整体实现复杂度就飙升了, 这对于业务来说就是巨大的理解成本了, 相关代码的问题需要定位和维护时, 都会有比较高的心智负担.
此处主要是对 operation 和 async_result 作简单的介绍, 在 <<opertion调度详解>> 篇中, 我们会详细对相关的实现进行展开和分析.
5. 扩展部分简介
5.1 strand
ASIO 用于强化自己线性任务表达的设施, 在 Coroutine 出现前, 这种设施对于补齐Lambda Post 系统的线性表达能力还是非常重要的, 同时它的设计也是很巧妙的, 我们将在<<strand实现详解>>中对其实现进行展开.
5.2 timer 实现
调度本身经常会遇到周期性任务, 超时等的支持, 这个时候我们需要有专门的timer_service来完成对各类定时器的良好支持, 在<<timer实现详解>> 中对其实现进行展开.
5.3 coroutine 实现
ASIO 的 coroutine 实现其实包括了早期基于boost::context的有栈协程版本, 以及后面C++20发布后, 基于C++20 stackless coroutine的实现, 考虑到使用场景的匹配度, 我们直接选择后者, 在 <<coroutine实现详解>> 中对其实现进行具体的展开.
6. 总结
Asio作为广为人知的网络库, 单就的 scheduler 部分来说, 使用比较现代化的c++特性, 整体围绕 operation 进行组织, 提供了可以执行任意任务的 scheduler , 又在此基础上实现了可以在业务层尽量避免直接使用同步原语来支持线性表达的 strand, 然后又提供了相对高效的 timer 实现, 整体的性能, 易用性, 完成度可以说都达到了一个比较完美的程度, 首先它自己对各种网络 API 的支持, 其次上面说到的一些工业项目对其 scheduler 部分的成功使用, 都说明它是一个成熟度相当高, 泛用性非常好的一个库, 很长一段时间应该都会被广泛使用了.
7. 参考
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2023-04-22,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号