哔哩哔哩大数据平台建设之路—数据安全篇

哔哩哔哩大数据平台建设之路—数据安全篇

从大数据到人工智能
发布于 2023-03-13 12:32:33
发布于 2023-03-13 12:32:33
本期作者

李昌海
哔哩哔哩资深开发工程师
韩志华
大数据平台工具负责人

1.序言
Berserker是B站一站式数据开发及治理平台,基于常用大数据生态组件构建,满足公司内数据查询、数据分析、日常报表、数据集成、数据开发、实时计算和数据治理等各种业务场景。在B站,我们一般将Berserker简写为BSK。
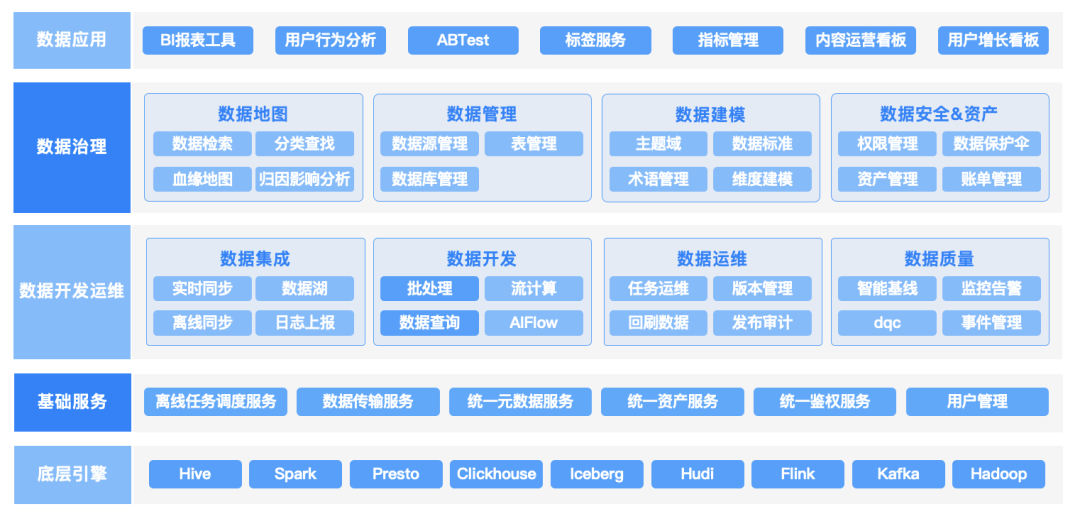
图1. Berserker的整体架构
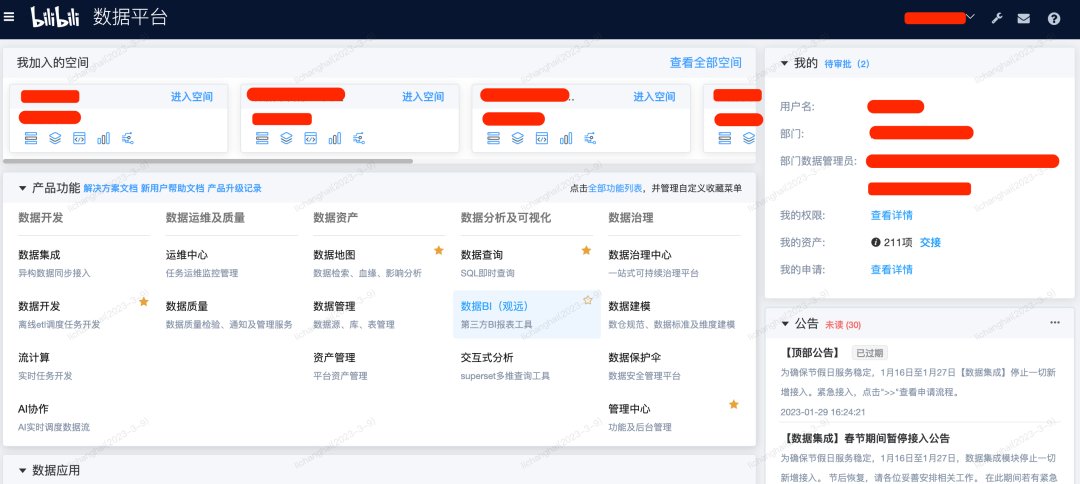
图2. Berserker主页
其中,数据安全是Berserker平台中重要的一部分,它将为公司内部 Hive、Kafka、ClickHouse、ETL任务等各种资产进行统一的数据安全管理,并为数据平台部内部的数据开发、数据分析、数据报表、数据治理等各种数据类产品进行统一的功能安全管控。
本文将重点介绍Berserker数据安全的建设过程。
2.数据安全建设
2.1 安全目标
我们安全建设的目标是:保障信息资产的保密性(Confidentiality)、完整性(Integrity)、可用性(Availability):
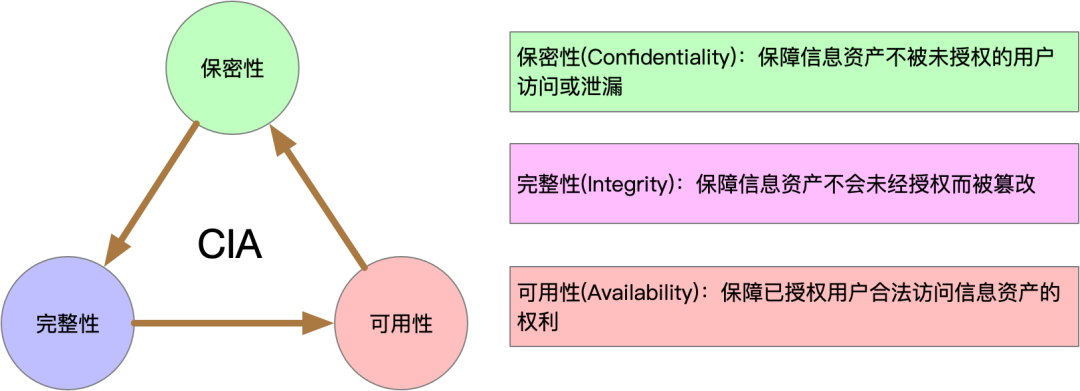
图3. CIA三要素
2.2 5A方法论
我们将根据数据安全5A方法论,打造一个完整的安全产品,并在每个主要流程都分别提供了相应的产品和服务,实现安全闭环。
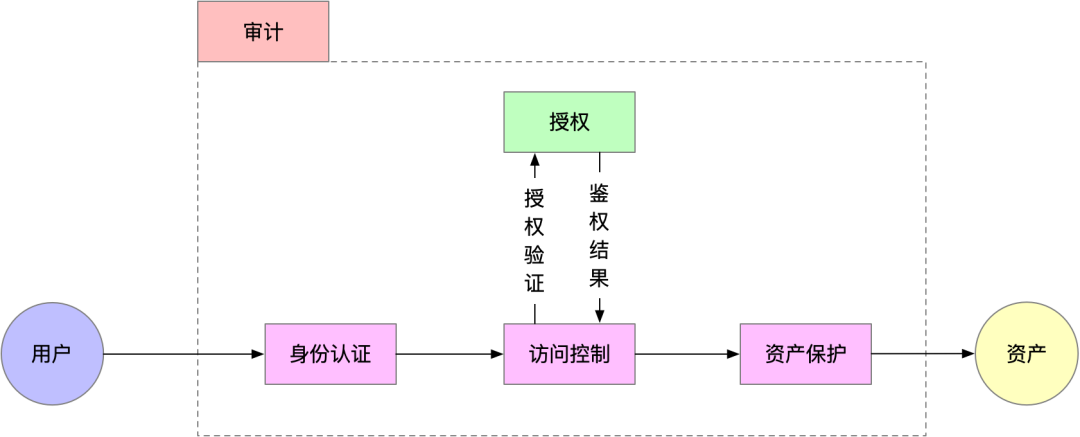
图4. 数据安全5A方法论
其中:
- 身份认证(Authentication):用户主体是谁
- 授权(Authorization):授予某些用户主体允许或拒绝访问客体的权限
- 访问控制(Access Control):控制措施以及是否放行的执行者
- 资产保护(Asset Protection):资产的保密性、完整性、可用性保障
- 可审计(Auditable):形成可供追溯的操作日志
2.3 数据安全架构

图5. 整体框架
其中:
- 身份认证
Berserker接入了公司统一身份认证,在新建账号时,将同步账号到公司AD域控管理,大数据组件通过Kerberos进行身份认证。
- 授权
一般用户在Berserker平台进行数据安全变更操作(如:权限申请),授权结果记录在数据安全。数据安全将授权结果同步到Ranger和ClickHouse等。
- 访问控制
Berserker、数据开发等服务通过数据安全服务进行鉴权。
Hive、Spark、Flink等计算引擎通过Ranger进行鉴权。
- 资产保护
我们按不同的数据安全等级制定不同的数据保护策略,并采取下载限制、数据脱敏、安全水印、溯源等多种措施现在数据保护
- 审计
记录用户或系统的操作,并用于事件追溯。BSK系统中多数据服务已经接入审计,同时也通过HDFS元仓(基于FsImage和HDFS AuditLog构建)进行数据访问分析。
2.4 里程碑
2020年7月数据安全的第一个服务权限系统从Berserker平台独立出,2022年7月,数据安全升级到2.0,中间经历了几次重大变更。

图6. 主要时间节点
数据安全2.0于2021年8月开始规划,2021年11月开始前期开发工作,于2022年7月上线,其最大的变化为有两点:
- 重新设计了一套权限管理系统
- 产品形态上引入了工作空间
3.遇到的问题
3.1 权限变更
本质上,权限主要包含三个部分:账号、资源和权限类型。相比于1.0,权限2.0对这三块在设计上较大改变,主要体现在:
- 简化了账号体系
- 标准化了资源模型
- 丰富了权限类型
3.1.1 权限1.0
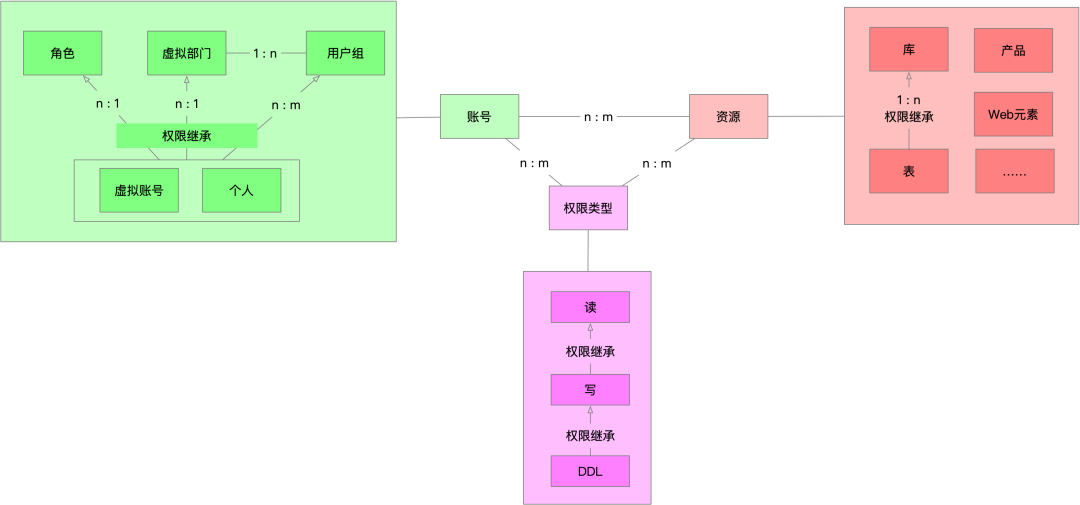
图7. 权限1.0模型图
权限系统1.0有以下特点:
- 权限系统基于用户进行权限管理
- 并没有区分数据权限和产品功能权限
- 有各种不同的账号类型,权限可以来自于个人、部门、用户组和角色等
- ETL任务是以个人身份运行
- 权限只有读、写、DDL三种,而且存在包含关系
- Hive表可以继承Hive库权限
由此带来了很多问题:
- 权限来源过于丰富,账号、资源、权限类型三者都存在继承或包含关系,以至在多数情况下难以定位某用户为何拥有某个资源的某一权限
- 部门变更困难,因个人继承了部门权限,用户变更部门可能会造成其负责的任务无法正常运行
- 权限类型太少,且难以扩展,已经不能满足各种不同的业务场景
- 数据级权限和功能级权限没有分离,难以做到精细化运营。如管理员应该只拥有功能权限,但却拥有所有的数据权限
我们对上述问题进行了详细评估,确认在原有权限体系下都很难解决,于是设计了一套新权限体系。
3.1.2 权限2.0
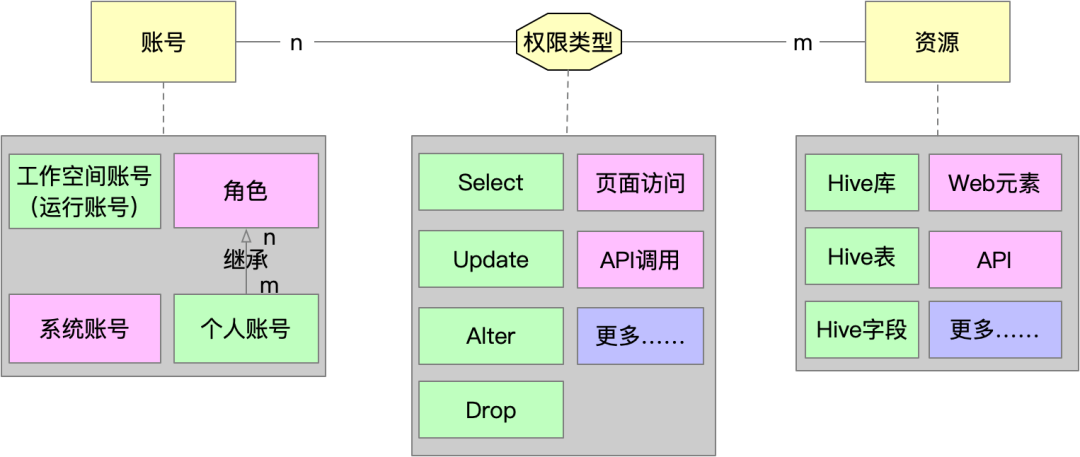
图8. 权限模型
相比于1.0,权限2.0的做了较大调整:
- 进行了账号调整,并拆分三种账号类型以满足多种场景
- 个人账号:认证公司员工,可以获取资源权限
- 系统账号:对接服务平台,不可获取资源权限
- 工作空间账号:ETL任务的运行账号,可以获得资源权限
- 功能权限和数据权限进行了分离
- 数据权限没有继承关系
- 功能权限只能来自于角色,个人继承角色权限,角色间没有包含关系
- 删除了用户组,删除了部门权限
- 扩展了权限类型,并可按不资源类型的不可设置不同的权限类型
如:Hive表为:hive:select、hive:update、hive:alter、hive:drop等权限
- 统一了资源定义,并在berserker各子业务间通用
3.1.3 升级过程
因为权限2.0和权限1.0存在较地差异,升级过程中,为保证稳定性,减少用户体验上的差异,我们主要采取了如下推进措施:
- 前期小范围验证
在权限2.0大规模推广前我们先进行了小范围的验证,以保证系统的稳定可靠:
- 实现2.0-alpha版,并接入项目的协作管理,但该版本的设计存在一些缺陷,与最终版本存在较大的差异,但为后续改进提供了宝贵的经验。目前项目的协作管理已经按最终方案进行了调整
- 实现2.0-beta版,并接入ClickHouse表权限管理。该版本为权限2.0的原型
- 基于2.0-beta进行完善,小步快跑,多次迭代,形成完善的权限系统
- 权限系统的兼容
数据安全是berserker的基础服务,为大量的服务提供安全支持。同时数据安全改造无法做到一蹴而就,在推进过程中,存在部分业务使用1.0,部分业务使用2.0,为此我们需要保证系统能够兼容:
- 保留并维护权限1.0数据,并实现权限数据双写,如:用户账户、资源等数据需要实现双写,权限2.0的数据同步写回1.0中
- 保留权限1.0相关接口,但不维护该接口,并标志该接口为废弃,业务调用时将打印调用方信息,通过收集调用日志,找到推动调用方使用新接口
- 保留权限1.0数据入仓,以兼容原有数仓业务,同时推动数仓相关业务使用新权限数据
- 数据的迁移
数据迁移包括历史全量数据迁移和增量数据迁移,在下面会讲到。
3.2 权限迁移
3.2.1 背景
为减少用户困扰,保证业务的正确运行,我们需要做到无缝权限数据迁移,包含:数据权限迁移和功能权限迁移。
在做数据迁移时也遇到了一些问题,尤其是Hive表的权限数据迁移。
3.2.2 Hive表迁移
需要全量迁移的数据权限有:Hive表、Hive库、数据源、Topic、ETL任务等。以下我们将重点介绍Hive表权限数据迁移过程。
我们原计划将部门、角色、用户组等Hive表权限全部展开个人,但通过计算发现,如将所有权限全部展开,最后权限记录将超过2亿条,这明显存在问题:
- 权限不合理
- 部门拥有数据权限也不合理,一个部门内可能仅有少数同学使用BSK平台,而其他同学可能都不知道BSK是什么
- 系统管理员可能只是用来审批或管理某些功能,并不使用数据,但依然拥有所有表的权限
- 存在技术问题
- 数据量太大,很难同步到Ranger
- 权限系统和Ranger数据库在不调整结构的情况也无法存储如此大的数据量
- 获取有权限的Hive表列表较常见的功能也难以实现
- 权限系统内部也难以加载并处理如此多的数据。
在引入工作空间后,任务将以工作空间账号运行,也必须为工作空间账号添加正确的权限。
最后我们放弃了将原权限全部展开到个人的方案,而是采用分析HDFS元仓,通过用户的历史访问行为来添加相应权限。
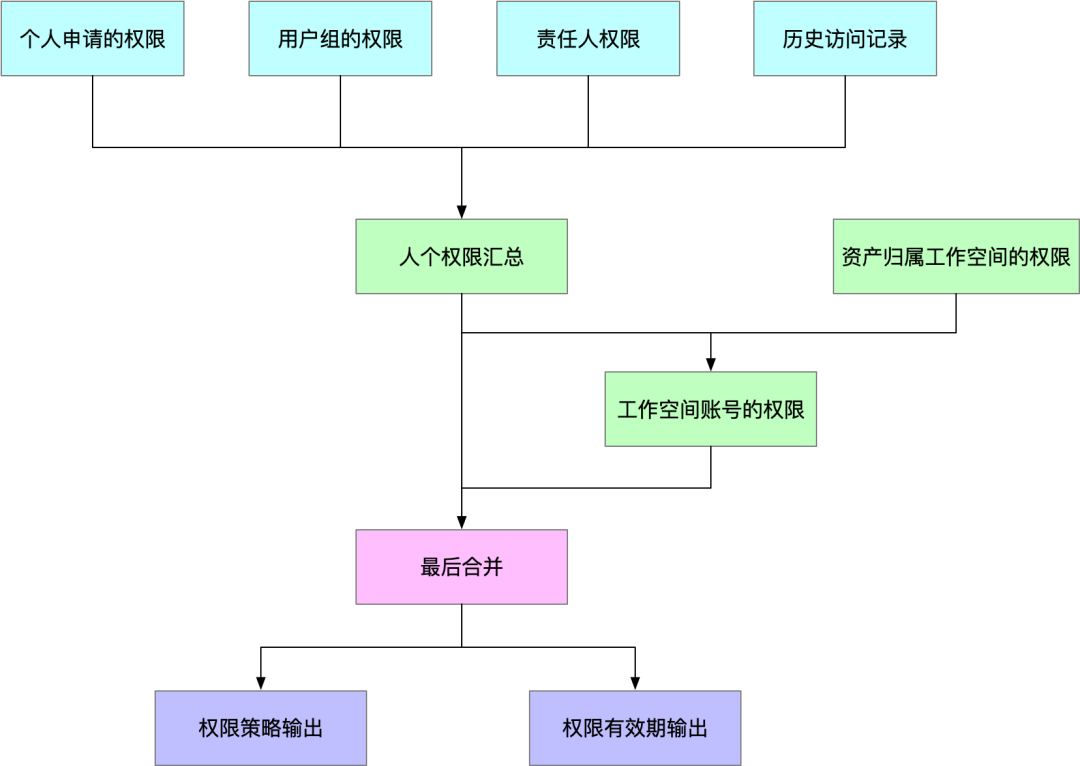
图9. Hive表权限同步流程
我们通过ETL任务来实现Hive表全量数据迁移,主要流程有:
- 通过查询近半年的HDFS 元仓数据,获取用户Hive表使用记录,并根据操作类型的不同为使用添加读或写的权限
- 表的责任人为授权 select、update、alter权限
- 个人申请的权限,新系统依然保留该权限
- 用户组的权限展开到个人
- 表归属工作空间授予该表Select、update、alter权限
- 表的产出任务所在工作空间授予该表Select、update、alter权限
通过上述大幅度的降低了权限策略数。同时权限2.0上线后,也未发现因Hive表迁移而产生的权限问题。
3.2.3 不足
Hive表权限依然存在一些不足,需要后期运营处理:
- 只通过近半年的元仓数据,可能会遗漏部分年任务的访问记录,造成相关权限缺失
- 用户权限存在扩大风险,用户申请的权限过期后,因为有访问记录,因此权限0中依然会给到权限,但考虑到多数情况下个人账号并不运行ETL任务,风险可控
- 部分用户依然保有写权限。主要为兼容部分第三方任务(非BSK平台上提交的任务),该任务可能未及时改用工作空间账号、而依旧使用个人账号运行
3.3 工作空间推进
3.3.1 背景
数据平台的用户的增长及业务的丰富,基于用户的数据安全模型体系难以支撑各种灵活多变业务需求,主要体现在:

图10. 基于用户的安全体系存在的问题
我们重新规划数据安全体系,并参考了业内的主流方案,引入工作空间,并将其作为管理资产、任务、成员、角色和权限管理的基本组织单元。
3.3.2 工作空间模型

图11. 工作空间模型
可以看到:
- 一个空间只能属于一个部门,一个部门可以拥有多个空间
- 用户可以加入到多个工作空间
- 数据资产归属于工作空间
- 空间内的角色只对当前空间有效
引入工作空间将涉及到各方改造,包括而不限于:数据安全、数据开发、数据集成、数据质量、数据治理、数仓以及各类数据应用等。为此,我们制定严格的推进策略
3.3.3 推进过程
工作空间整体推进改造过程主要分为四个阶段:
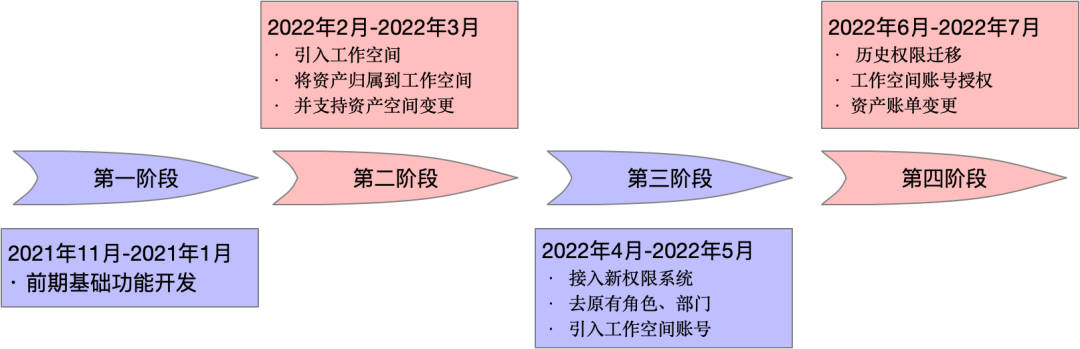
图12. 工作空间推进过程
工作空间后续工作则按项目正常迭代进行。
引入工作空间后,不管是功能层面还是技术层面都有较大的改造,为减少用户的理解成本,我们在推进过程中采用了一些策略:
- 不向用户暴露工作空间账号,而是先个人申请权限,提交ETL任务时,通过ETL任务的血缘将个人权限授予工作空间账号
- 因为改动较大、涉及涉及业务方较多,也为了减少升级引起的不确定性,我们选择在周六进行统一升级,减少对用户的打扰
- 为每个一级部门引入默认工作空间,同时每个部门成员将默认加入到该空间,保证推进过程中用户无需要做任何操作依然可以工作空间内的功能
- ETL任务归属空间后,该ETL的Owner及拥有该任务协作权限的用户也将作为工作空间的开发加入到该空间,以保证用户操作的一致性
3.4 Casbin优化
3.4.1 背景
Casbin 是一个强大的、高效的开源访问控制框架,其权限管理机制支持多种访问控制模型。权限系统内部使用Casbin进行权限管理。
Taishan是一款B站自研的分布KV数据库。
权限系统使用Taishan缓存权限策略,以减少服务和数据库的压力,权限系统内部处理流程如下:
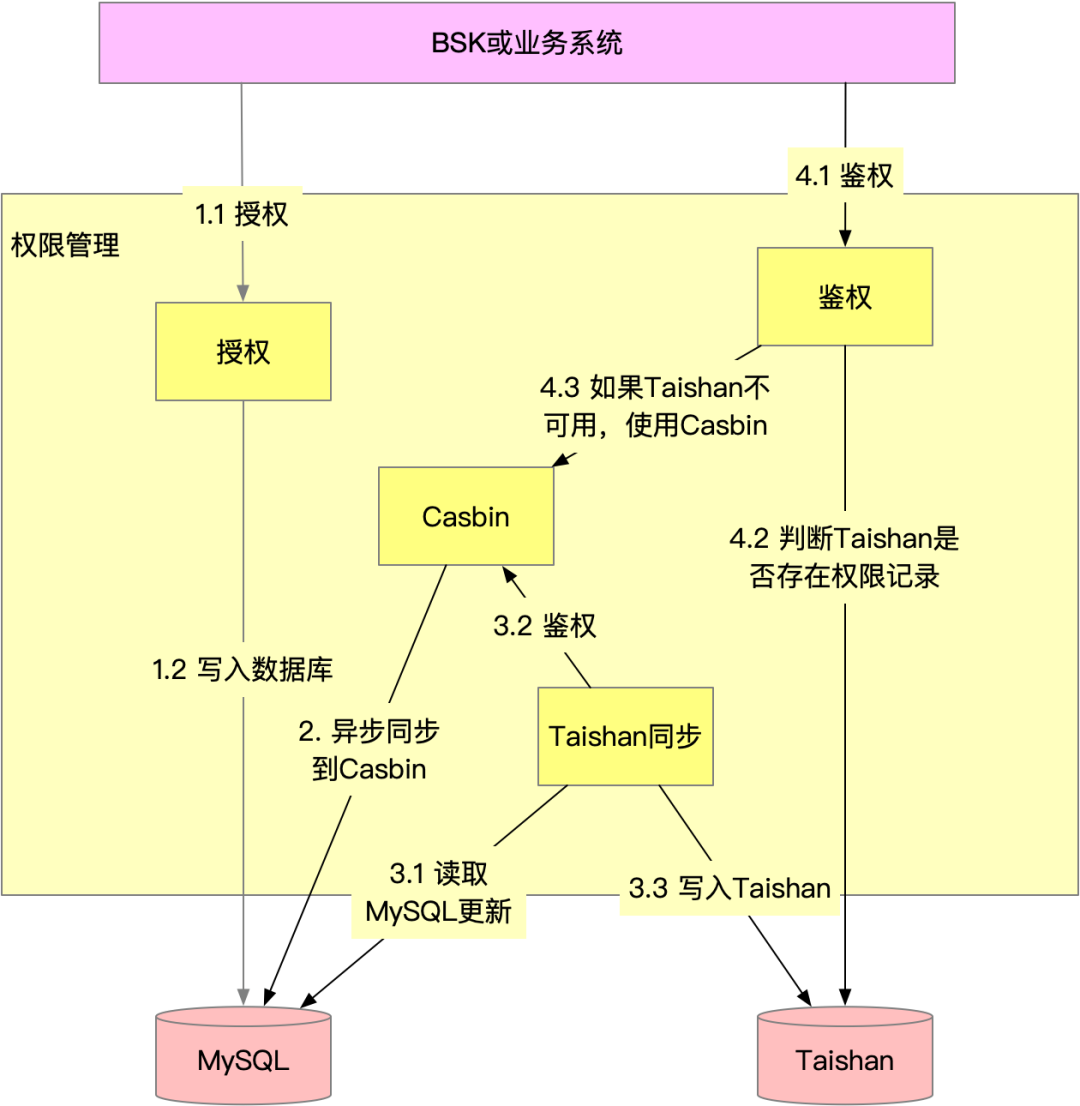
图13. 权限系统内部授权/鉴权流程
可以看到,权限系统内部处理的主要流程:
- 授权:用户授权操作直接写入数据库
- 同步Casbin:通过监听数据库最后修改时间,异步同步权限策略到Casbin
- 同步Taishan:通过消息队列异步同步权限策略到Taishan,期间使用Casbin进行鉴权
- 鉴权:正常情况下都将使用Taishan进行鉴权,但当Taishan数据异常时将降级到使用Casbin鉴权。
我们在实施过程中也发现了一些问题:
- 时间时延。Casbin是采用异步加载的方式,难以保证顺序一致。我们要求权限策略表延时5秒加载,以保证资产元数据处理完成。
- Taishan记录最后一次数据修改时间,内存中也记录最后一次数据修改时间,当两时间超时30秒,表示Taishan时间不可用
- Casbin的性能问题
3.4.2 Casbin添加权限性能调优
我们做权限迁移时,需要在Casbin中加载所有的权限策略,我们发现,Casbin加载性能很低,通过Debug后将问题定位在hasPolicy的实现上。
下面是hasPolicy和policy的实现:
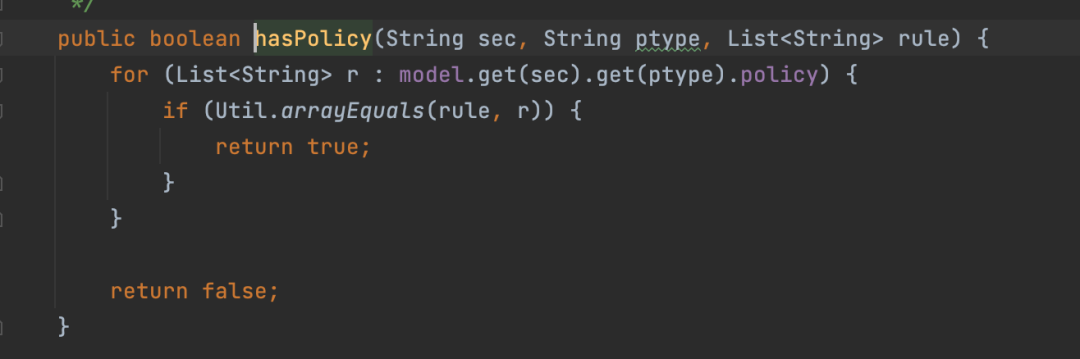
图14. Casbin判断策略是否存在的源码
图15. policy定义源码
hasPolicy函数判断相同策略是否已经存在,并且每次添加新策略时都将调用该函数进行判断,其时间复杂度为O(n^2),其中策略条数为n,当策略到达一定规模后,性能急剧下降。
我们对Casbin做了优化,添加一个Set集合(SetpolicySet)用于记录已经加载过的策略,hasPolicy中判断该Set中是否包含该策略,性能得到了大幅度提供。
值得一提的事,Casbin 1.25.0之后的版本修复该BUG。相应地,我们也恢复使用开源版本。
Casbin 1.25.0中的实现:
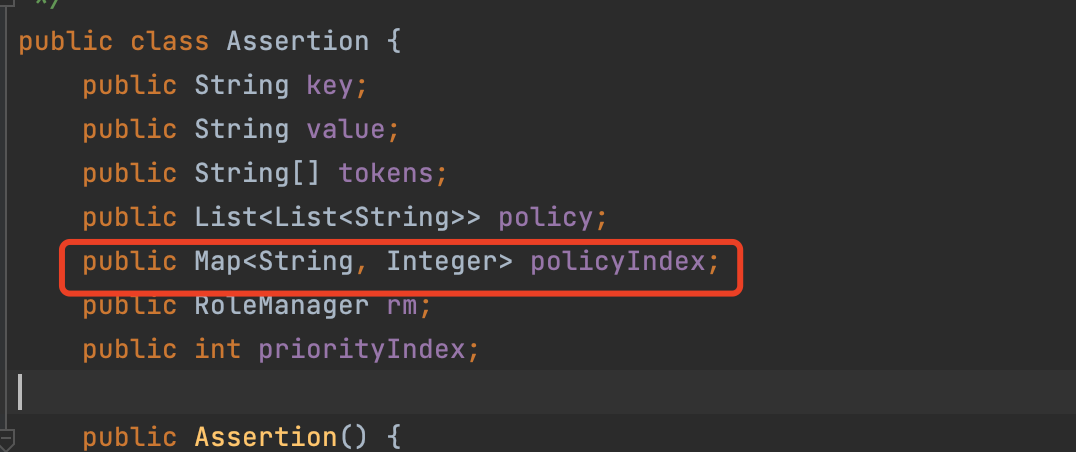
图16. Casbin添加策略的优化
可以看到Casbin1.25.0之后的版本中添加了policyIndex用于优化hasPolicy。
3.4.3 Casbin回收权限性能调优
权限大量回收操作较少见,主要发生在如下场景:
- 资源治理,做批量Hive表删除,需要删除相应的权限策略
- BSK平台的重度用户转岗或离职,需要做资产交接,进而删除其权限
- 工作空间治理,下线工作空间,需要删除工作空间账号的权限
在大批量的回收权限时,Casbin也会出现卡死,通过Debug后将问题定位在policy和policyIndex的维护上。
下面是Casbin删除权限策略的源码:
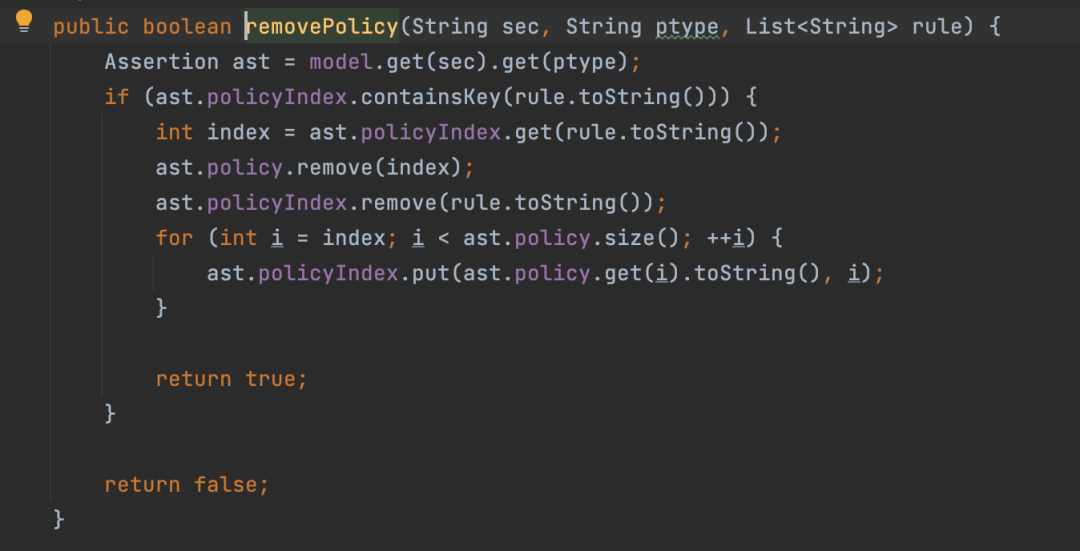
图17. Casbin策略删除的源码
可以看到,Casbin删除权限策略的步骤如下:
- 通过policyIndex找到权限对应的index
- 通过调用remove删除policy中的元素
- 重新更新受影响的policyIndex
Casbin回收权限的时间复杂度也为O(n^2),性能较低。
处理该问题时,我们没有直接修改Casbin源码,而是类似于数据库,引入了标志删除:
- 在权限策略中添加deleted标志,标记该策略是否已删除, 鉴权时添加deleted判断
- 回收权限时将删除改为更新操作权限策略中deleted标志的值
- 使用双缓存,定期清理过期权限
即定时创建新Casbin模型,并加载未删除的权限策略,完成后替换原Casbin模型,从而实现对回收权限的清理。
目前Casbin的删除性能也得到了极大的提升
3.5 更多问题
除了上面所提到的问题,我们在数据安全建设过程中还有很多问题,如:
- HDFS路径的权限问题,包括路径权限的继承问题
- 使用Flink CDC或Hudi的任务中间表的归属及权限问题
- 如何预防工作空间账号权限一直扩大的问题
- 非分区Hive表全量更新时删除Hive表所在目录的问题
4.未来展望
在Berserker数据安全建设过程中,我们参考了很多公司和商业产品对于的最佳实践,同时也确认我们的产品还属于较初级阶段,依然有大量功能需要去完善。
未来我们的建设路线将主要在几个方面:覆盖全生命周期的数据安全保障,更精细化的权限管理,敏感数据保护及风险评估等方面。
本文为从大数据到人工智能博主「jellyfin」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号