说到做到的redo日志


大家好,我是热心的大肚皮,皮哥。
Mini-Transaction
首先说下Mini-Transaction,对底层页面进行一次原子访问的过程叫Mini-Transaction(MTR)。一个事务包含多条语句,一条语句包含多个MTR,每个MTR包含多条redo日志。如下所示:
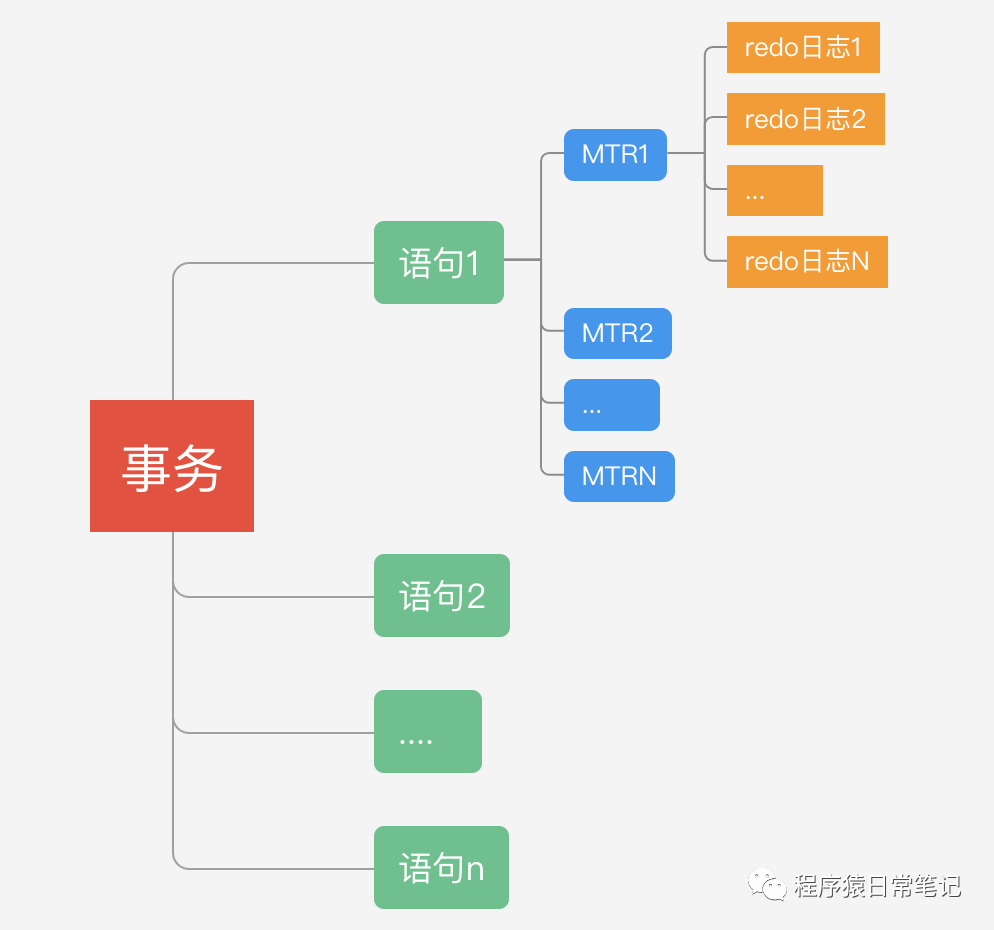
redo日志的写入
redo log block
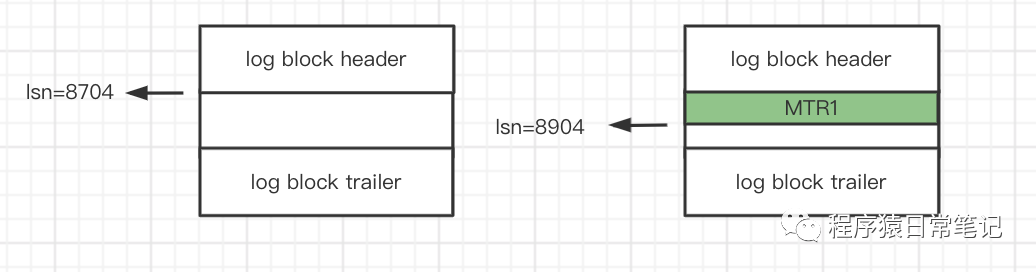
为了更好的管理,MTR生成的redo日志都在大小为512字节的页中,也叫block,具体如下图:
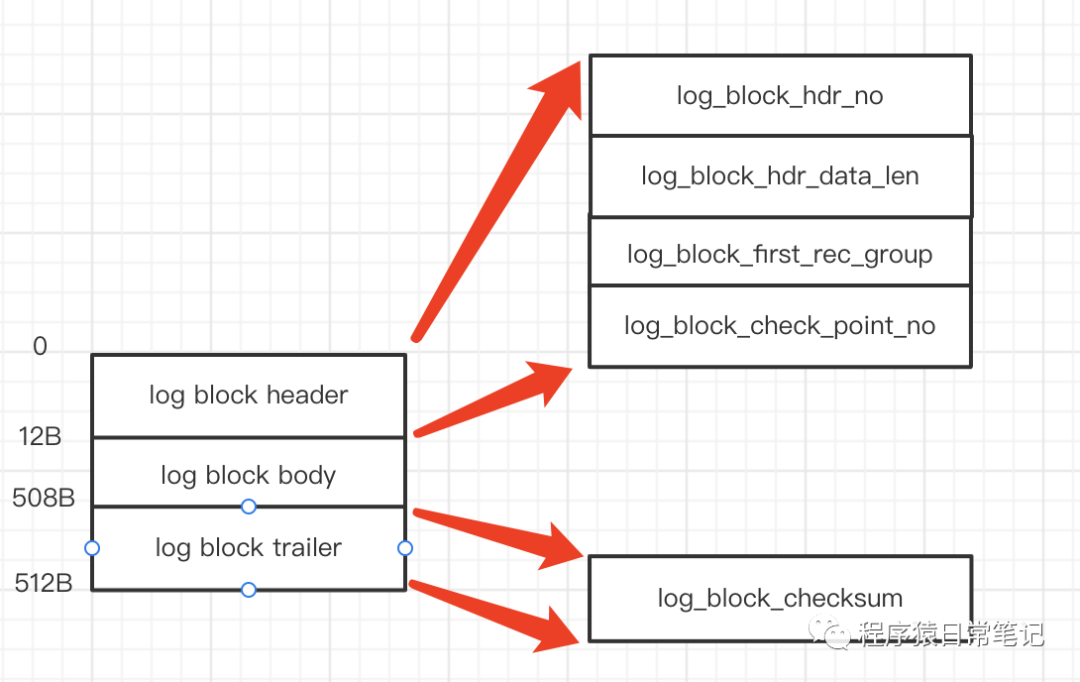
log block header:block头信息,包含以下几个字段。
- log_block_hdr_no:block编号。
- log_block_hdr_data_len:已使用的字节数。
- log_block_first_rec_group:每个MTR生成的redo日志叫一个redo日志记录组,这个属性代表该block中第一个MTR生成的redo日志记录组的偏移量,也就是这个block中第一个MTR生成的第一条redo日志的偏移量。
- log_block_check_point_no:checkpoint序号。
log block body:redo日志存储的地方。
log block trailer:block尾信息。
- log_block_checksum:block的校验值。
redo log 日志缓冲区
前面说过为了提高性能引入了Buffer Pool。同理,写redo日志时也是申请了一大片内存空间称为redo log buffer(redo日志缓冲区)也叫log buffer。
redo log 刷盘时机
- redo log buffer空间不足时。log buffer使用了50%时,就会进行刷盘。
- 事务提交时。
- 后台线程,每秒一次的频率刷redo日志。
- 正常关闭服务器。
- 做checkpoint时。
redo 日志文件格式
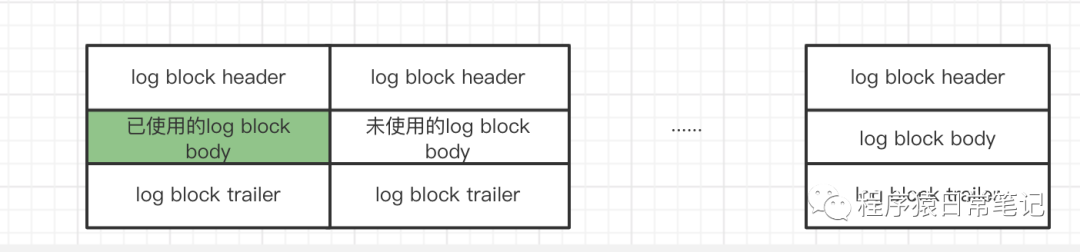
redo log buffer是若干个512字节的block,redo日志文件也是多个512字节大小的block组成,redo日志文件是循环利用的,也就是说最后一个写完,会在写第一个文件。5.7.22的版本默认的大小是48MB。在redo日志文件组中,每个文件的大小格式都一样。分别是:
- 前2048个字节存储管理信息。
- 从2048往后存储log buffer中的block镜像。
log buffer中的block镜像就不过多介绍了。这里只介绍每个redo日志文件的前2048个字节。如图。
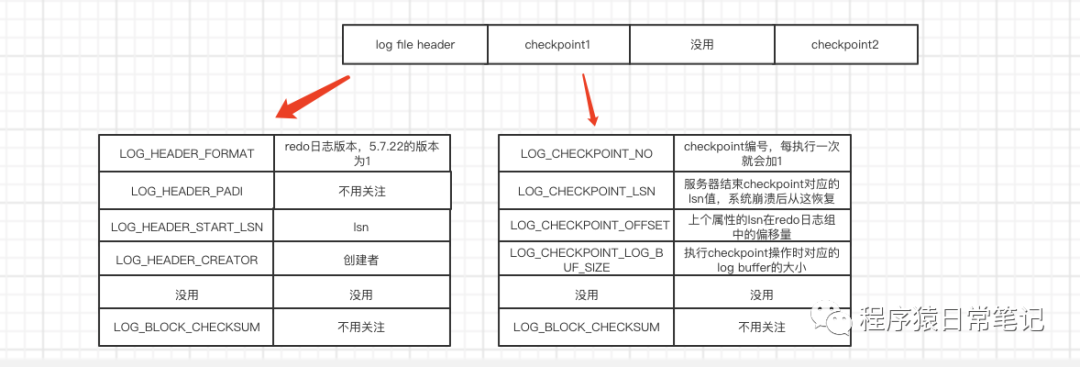
log sequence number
全局变量log sequence number简称lsn,用来记录总共写入的redo日志量,默认值8704。向log buffer中写入redo日志时是以MTR生成的一组redo日志为单位写入。
flushed_to_disk_lsn
上面说过,lsn是记录写入缓冲区的全局变量,而flushed_to_disk_lsn是记录写入磁盘的全局变量,初始值也是8704。大家还记得之前说过的buffer pool中的flush链表吗?修改后,flush链表中的节点会用oldest_modification与newest_modification分别存储此次修改的flushed_to_disk_lsn开始值与结束值,而且flush链表最后修改的脏页会放到链表头部。
checkpoint
redo日志文件组的容量是有限的,所以不得不循环使用,那么如果发生追尾怎么办呢?为了复用,如果mtr_1的redo日志被刷到了磁盘上,那么这个redo日志就可以被覆盖,同时增加一个checkpoint_lsn的操作,这个过程叫执行一次checkpoint。具体的步骤如下。
- 计算可以被覆盖的redo日志对应的lsn最大是多少。通过flush链表中的最早修改的脏页的oldest_modification,来判断刷新到了哪里,把oldest_modification写到checkpoint_lsn。
- 将checkpoint_lsn与对应的redo日志文件组的偏移量以及checkpoint编号写到文件的管理信息中,也就是checkpoint1与checkpoint2,checkpoint_no是偶数时写checkpoint1中,反之checkpoint2中。
崩溃的话如何恢复呢?
服务器正常的情况下,redo基本上没什么作用,但是一旦数据库出现问题,在重启时redo日志可以将页面恢复到系统崩溃前的状态。
- 确定恢复的起点
lsn不小于checkpoint中checkpoint_lsn的redo日志,这以后的redo日志不确定是否刷盘,通过比较checkpoint1与checkpoint2的checkpoint_no大小来获取checkpoint_lsn与checkpoint_offset,以此定位从哪里开始。
- 确定恢复的终点
前面说过redo日志是顺序写入的,log block header有个LOG_BLOCK_HDR_DATA_LEN的属性,如果当前block填满了,则为512,反之不为512,所以终点也就是不为512的block。
- 怎么恢复
首先使用哈希表,根据redo日志中的space ID 和page number属性计算出哈希值,将同一个space ID 和page number的日志放到同一个槽中,如果出现哈希冲突的话,使用链表链接起来,根据生成的先后顺序连接。
如果遇到已经刷新过的页面,则跳过,判断方式是根据页面中File Header中FIL_PAGE_LSN的属性。FIL_PAGE_LSN记录了最近一次修改页面时对应的lsn值(也就是页面控制块的newest_modification)
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2022-02-16,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号