EdgeYOLO来袭 | Xaiver超实时,精度和速度完美超越YOLOX、v4、v5、v6

EdgeYOLO来袭 | Xaiver超实时,精度和速度完美超越YOLOX、v4、v5、v6

集智书童公众号
发布于 2023-02-26 14:07:23
发布于 2023-02-26 14:07:23

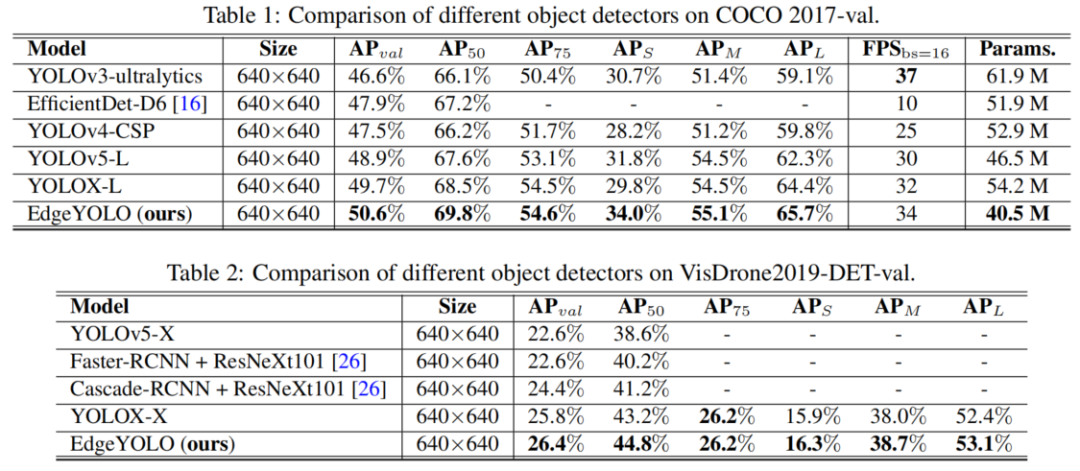
本文提出了一种基于最先进YOLO框架的高效、低复杂度和Anchor-Free的目标检测器,该检测器可以在边缘计算平台上实时实现。 本文开发了一种增强的数据增强方法,以有效抑制训练过程中的过拟合问题,并设计了一种混合随机损失函数,以提高小目标的检测精度。 受FCOS的启发,提出了一种更轻、更有效的Decoupled-Head,其推理速度得到了提高,精度损失很小。 本文的基线模型在MS COCO2017数据集中可以达到50.6% AP50:95和69.8% AP50的精度,在VisDrone2019 DET数据集中达到26.4% AP50:95、44.8% AP50,并且在边缘计算设备Nvidia Jetson AGX Xavier上满足实时要求(FPS≥30)。
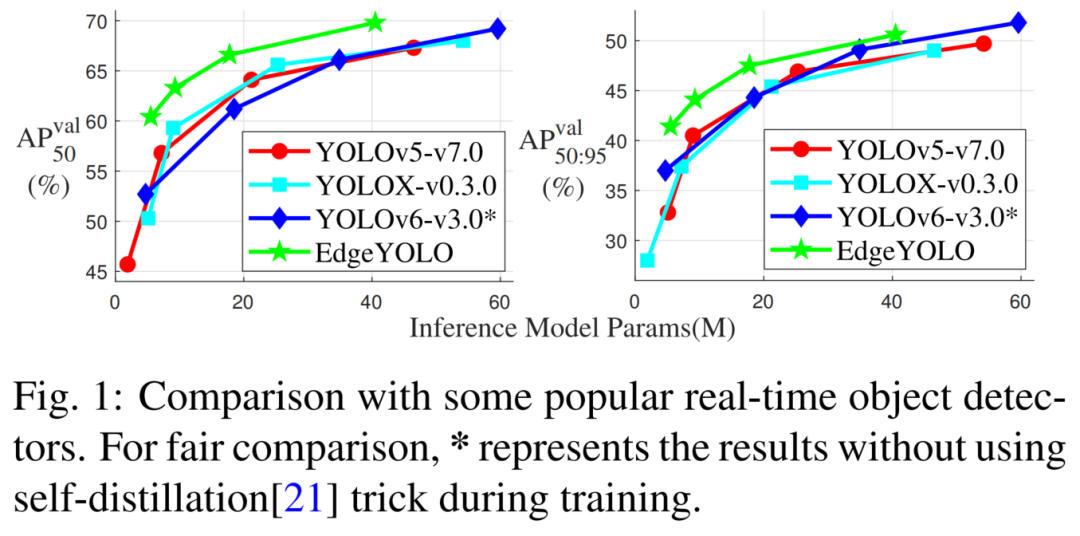
如图1所示,还为具有较低计算能力的边缘计算设备设计了参数较少的轻量化模型,这也显示了更好的性能。 github:https://github.com/LSH9832/edgeyolo
1、简介
随着计算硬件性能的不断提高,基于深度神经网络的计算机视觉技术在过去十年中迅速发展,其中目标检测是自主智能系统中应用的重要组件。目前,有两种主流的目标检测策略。一种是以R-CNN系列为代表的两阶段策略,另一种是一阶段策略,YOLO是最流行的框架之一。
- 对于两阶段策略,在第一阶段使用启发式方法或区域建议生成方法来获得多个候选框,然后在第二阶段对这些候选框进行筛选、分类和回归。
- 单阶段策略以端到端的方式给出结果,其中目标检测问题被转化为全局回归问题。全局回归不仅能够将位置和类别同时分配给多个候选框,而且能够使模型在目标和背景之间获得更清晰的分离。
在常见的目标检测数据集(如MS COCO2017)上,使用两阶段策略的模型比使用一阶段策略的更好。然而,由于两阶段框架的内在局限性,它远远不能满足传统计算设备上的实时要求,并且在大多数高性能计算平台上可能面临同样的情况。
相比之下,单阶段目标检测器可以在实时指示器和性能之间保持平衡。因此,更受研究人员的关注,YOLO系列算法以高速迭代更新。YOLOv1到YOLOv3的更新主要是对底层框架结构的改进,YOLO的大多数后期主流版本都侧重于提高精度和推理速度。
此外,他们的优化测试平台主要是具有高性能GPU的大型工作站。然而,他们最先进的模型通常在这些边缘计算设备上以令人不满意的低FPS运行。出于这个原因,一些研究人员提出了参数更少、结构更轻的网络结构,如MobileNet和ShuffleNet,以取代原有的骨干网络,从而可以在移动设备和边缘设备上实现更好的实时性能,但要牺牲一定的精度。
本文的目标是设计一种具有良好精度并且能够在边缘设备上实时运行的目标检测器。
本文的贡献总结如下:
- 设计了一种Anchor-Free目标检测器,该检测器可以在MS COCO2017数据集中实时运行在边缘设备上,准确率为50.6%AP;
- 提出了一种更强大的数据增强方法,进一步确保了训练数据的数量和有效性;
- 本文的模型中使用了可重参化的结构,以减少推理时间;
- 设计了一个损失函数,以提高小目标的精度。
2、相关方法
2.1、Anchor-free检测器
自YOLOv1问世以来,YOLO系列在实时目标检测领域一直处于领先地位。还有一些其他优秀的检测器,如SSD、FCOS等。当在目标检测任务中测试FPS时,大多数先前的研究只计算模型推断的时间成本,而完整的目标检测任务包含3个部分:预处理、模型推理和后处理。
由于预处理可以在视频流期间完成,因此在计算目标检测的FPS时应包括后处理时间成本。在高性能GPU工作站或服务器上,预处理和后处理只占一小部分时间,而在边缘计算设备上,所需的延迟甚至是其十倍以上。
因此,减少后处理计算可以显著提高边缘计算设备的速度。当使用Anchor-Base的策略时,后处理的时间延迟几乎与每个网格单元的Anchor数量成比例。Anchor-Base的YOLO系列通常为每个网格单元分配3个Anchor。与那些Anchor-Base的框架相比,Anchor-Free检测器可以在后处理部分节省一半以上的时间。
为了确保检测器在边缘计算设备上的实时性能,本文选择Anchor-Free策略构建目标检测器。目前有2种主要类型的Anchor-Free目标检测器,一种是基于Anchor point的,另一种是关键点的。在本文中采用了基于Anchor point的范式。
2.2、数据增强
数据增强是神经网络训练中必不可少的数据处理步骤。合理使用数据扩充方法可以有效缓解模型的过度拟合。
对于图像数据集,几何增强(随机裁剪、旋转、镜像、缩放等)和光度增强(HSV和亮度调整)通常应用于单个图像。这些基本的增强方法通常在多图像混合和拼接之前或之后使用。
目前,主流的数据增强技术,如Mosaic、Mixup、CopyPaste等,通过不同的方法将多张图片的像素信息放在同一张图片中,以丰富图像信息并降低过度拟合的概率。

如图2(b)所示,本文设计了一种更加灵活和强大的组合增强方法,这进一步确保了输入数据的丰富性和有效性。
2.3、Model Reduction
通过模型缩放,降低了计算成本,可以有效提高模型推理速度。模型缩放方法可分为两类:有损缩放和无损缩放。
有损缩放通常通过减少网络层和通道的数量来构建更小的网络。无损缩放集成并耦合多个分支模块,通过重参化技术构建更精简的等效模块。模型参数量的降低是通过牺牲精度来实现更快的速度,并且由于耦合结构倾向于降低训练效率,因此通常在模型训练完成后使用重参化方法进行推理。
通过结合有损和无损缩减方法,本文构建了几个不同大小的模型(如图1所示),以适应具有不同计算能力的边缘设备,并加快模型推理过程。
2.4、Decoupled Regression
从YOLOv1到YOLOv5,对于每个具有不同尺度的特征图,获取目标的位置、类别和置信度的回归使用了一组统一的卷积核。一般来说,如果不同的任务密切相关,则使用相同的卷积核。然而,在数值逻辑中,目标的位置、置信度和类别之间的关系还不够接近。
此外,相关实验证明,与直接处理所有任务的单一回归检测头相比,使用解耦回归检测头可以获得更好的结果,并加速损失收敛。
尽管如此,一个被解耦的头却会带来额外的推理成本。作为改进,本文作者设计了一个较轻的解耦头,并共同考虑了模型的推理速度和精度。
2.5、Small Object Detecting Optimization
自目标检测研究开始以来,小目标检测问题一直受到广泛关注。随着图像中对象的比例减少,用于表示目标的像素信息减少。与小目标相比,大目标通常占据数十倍甚至数百倍的信息,小目标的检测精度通常明显低于大目标。
此外,位图图像的属性无法消除这种差距。此外,研究人员发现,在训练过程中,小目标在总损失中所占的比例始终较小。
为了提高小目标的检测效果,先前的研究提出了以下方法:
- 复制小目标并将其随机放置在图像的其他位置,以在数据增强过程中增加小目标的训练数据样本,这被称为复制增强;
- 图像被缩放和拼接,原始图像中的一些较大目标被缩放为小目标;
- 损失函数旨在通过增加小目标损失的比例来更加关注小目标。
由于使用方法1处理的图像中存在尺度失配和背景失配的问题,本文只参考方法2和2来优化训练过程。
本文的数据增强中包括缩放和拼接方法,并重新设计了损失函数,这可以有效地提高中小目标的检测和模型整体精度。
3、本文方法
3.1、数据增强的改进
许多实时目标检测器在训练期间使用Mosaic+Mixeup策略进行数据增强,这可以有效缓解训练期间的过度拟合情况。
如图3(a)和(b)所示,有两种常见的组合方法,当数据集中的单个图像具有相对足够的标签时,它们表现良好。由于数据论证中的随机过程,当图3(a)中的标签空间中存在响应时,数据加载器可能会提供没有有效目标的图像。这种情况的概率随着每个原始图像中标签数量的减少而增加。
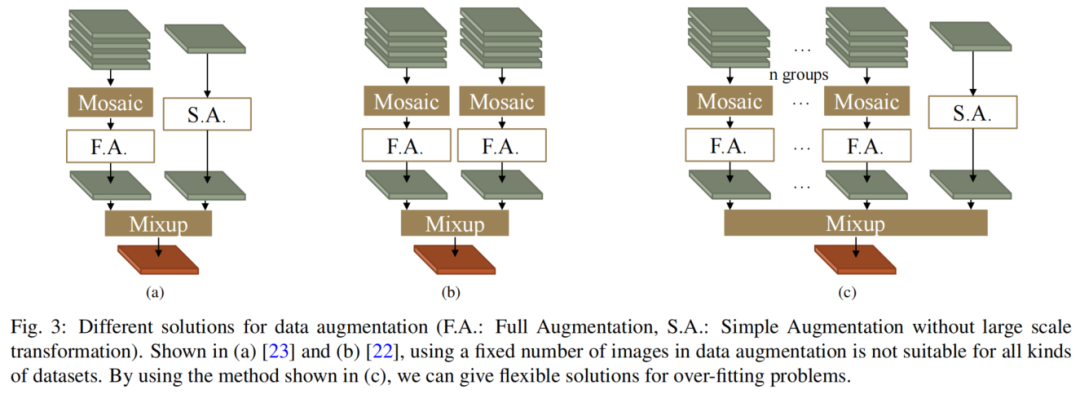
因此作者设计了图3(c)中的数据增强结构:
- 首先,对多组图像使用Mosaic方法,因此可以根据数据集中单个图片中标签的平均数量的丰富程度来设置组数。
- 然后,通过Mixup方法将最后一个简单处理的图像与Mosaic处理的图像混合。
在这些步骤中,最后一幅图像的原始图像边界在变换后的最终输出图像的边界内。这种数据增强方法有效地增加了图像的丰富性以减轻过度拟合,并确保输出图像必须包含足够的有效信息。
3.2、Lite-Decoupled Head
图4中的解耦头首先在FCOS中提出,然后用于其他Anchor-Free目标检测器,如YOLOX。证实了在最后几个网络层使用解耦结构可以加速网络收敛并提高回归性能。
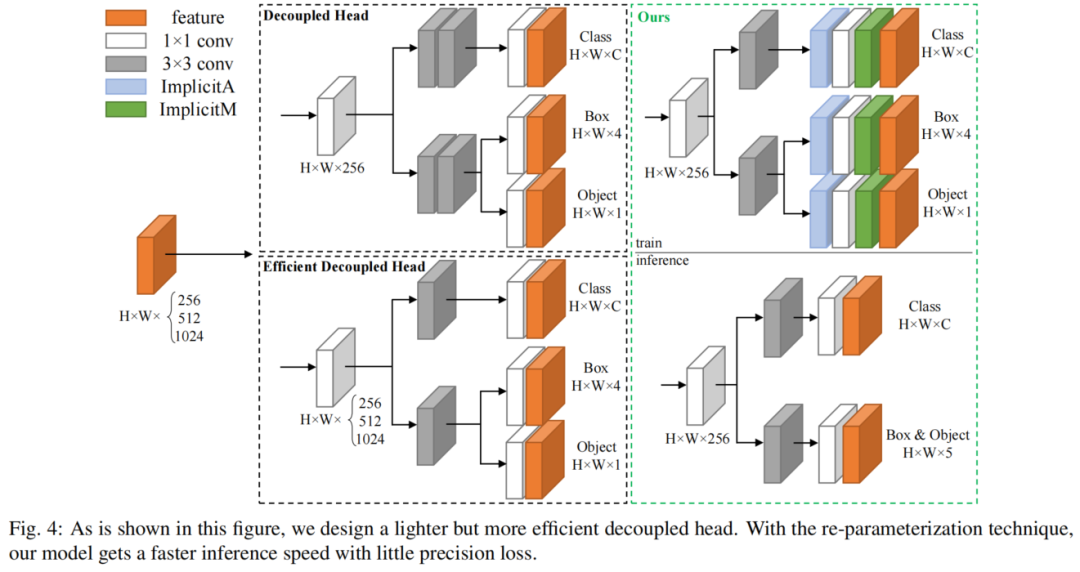
由于解耦头采用了导致额外推理成本的分支结构,因此提出了具有更快推理速度的高效解耦头,这将中间3×3卷积层的数量减少到仅一层,同时保持与输入特征图相同的更大数量的通道。
然而,在实验测试中,这种额外的推理成本随着通道和输入大小的增加而变得更加明显。因此,设计了一个更轻的解耦头,具有更少的通道和卷积层。
此外,将隐式表示层添加到所有最后的卷积层,以获得更好的回归性能。通过重参化的方法,隐式表示层被集成到卷积层中,以降低推理成本。框和置信度回归的最后卷积层也被合并,使得模型可以进行高并行计算的推断。
3.3、损失函数的改进
对于目标检测,损失函数一般可以写成如下:
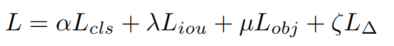
其中
、
、
和
表示分类损失、IOU损失、目标损失和调节损失,
为超参数。在实验中将训练过程分为三个阶段。
在第一阶段,采用最常见的损失函数配置之一:GIOU损失用于IOU损失,平衡交叉熵损失用于分类损失和目标损失,调节损失设置为零。在最后几个Epoch数据扩充的Epoch,训练过程进入第二阶段。分类损失和目标损失的损失函数由混合随机损失代替:
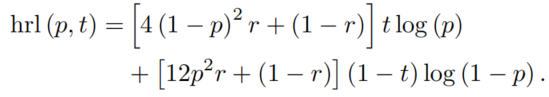
其中p表示预测结果,t表示GT值,r是0到1之间的随机数。对于一张图像中的所有结果,都有这个结果:
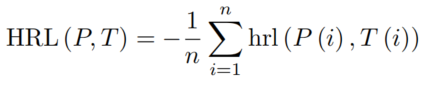
这表明在小目标的精度和总精度之间有较好的平衡。在第三阶段,关闭数据扩充,将L1损失设为调节损失,用cIOU损失代替gIOU损失。
4、实验
4.1、消融实验
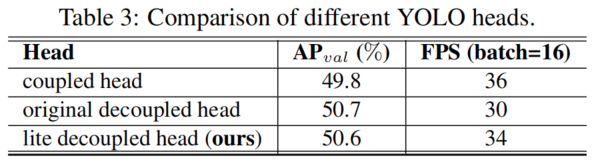
1、Decoupled head
2、Segmentation labels (poor effect)
当在数据增强期间处理旋转的标签时,在没有分割信息的情况下,在旋转后获得原始标签框的四个坐标角点,并绘制一个不倾斜并穿过四个点的框作为要使用的标签。这可能包含更多无效的背景信息。
因此,当在MS COCO2017上训练模型时,尝试通过使用分割标签来生成边界框,以便图像旋转后的标签仍然保持高精度。当启用数据扩充并且损失进入稳定下降阶段时,使用分段标签可以显著增加2%-3%AP。
由于数据扩充在训练的最后阶段被设置为禁用,因此所有标签都变得更加准确。此外,即使不使用分割标签,最终精度也仅降低约0.04%AP。
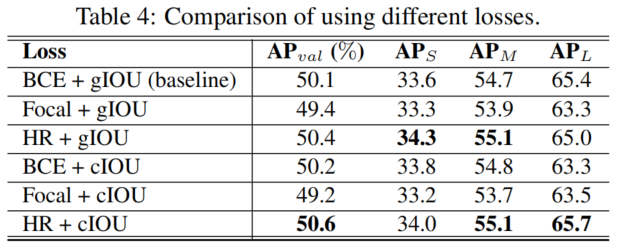
3、损失函数
4.2 为边缘计算设备设计的技巧
1、Input size adaptation
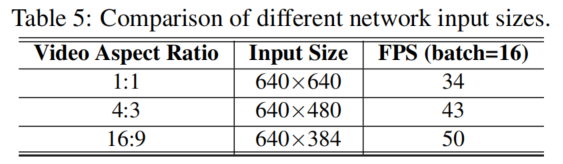
2、多进程和多线程的计算体系结构
作为一个包含预处理、模型输入和后处理的整体检测过程,这三个部分可以在实际部署中拆分,并分配给多个进程和线程进行计算。在测试中,使用拆分架构可以实现大约8%-14%的FPS增长。
4.3、SOTA对比
4.4、总结
本文提出了一种边缘实时和Anchor-Free单阶段检测器EdgeYOLO,其一些代表性结果如图5和图6所示。如实验所示,EdgeYOLO可以在边缘设备上以高精度实时运行,其检测小目标的能力得到了进一步提高。


由于EdgeYOLO使用Anchor-Free结构,因此设计复杂性和计算复杂性降低,并且在边缘设备上的部署更加友好。
此外,作者相信该框架可以扩展到其他像素级识别任务,例如实例分割。在未来的工作中,将进一步提高框架对小目标的检测精度,并进行有效优化的探索。
5、参考
[1].EdgeYOLO: An Edge-Real-Time Object Detector.
免责声明
凡本公众号注明“来源:XXX(非集智书童)”的作品,均转载自其它媒体,版权归原作者所有,如有侵权请联系我们删除,谢谢。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-02-17,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号