13-Rollout训练系统里的推理服务

13-Rollout训练系统里的推理服务

anzhsoft
发布于 2026-07-03 17:13:57
发布于 2026-07-03 17:13:57
上一篇导读把第三组的问题定住了:当数据、reward 和算法合同都成立后,下一步要看 response 是怎么被生产出来的。本文先回答最基础的问题:rollout 在一轮 RL 训练里到底扮演什么角色?
本文的核心判断是:rollout 不是训练代码里的一次本地生成调用,而是训练系统内嵌的推理服务。它把 prompt batch 扩展成生成请求,把推理后端的 token output 翻译回 DataProto,并把吞吐压力集中到 fanout、response length、server capacity、KV cache 和权重同步上。
先看它在一轮 PPO/GRPO step 里的位置。读这张图时重点看中间三步:trainer 先把训练 batch 变成 generation batch,再按 rollout.n扩展请求,最后把 rollout output 并回原 batch。

rollout 在一轮 PPO step 中的位置
这张图对应 RayPPOTrainer.fit()的生成段:batch_dict先被包成 DataProto,trainer 写入 temperature 和 uid,再通过 _get_gen_batch()取出 generation batch;随后按 rollout.n做 repeat,调用 self.async_rollout_manager.generate_sequences(combined_gen_batch),最后 batch.repeat(...).union(gen_batch_output)并补 response_mask(verl/trainer/ppo/ray_trainer.py:1343-1409)。
1. rollout 首先改变 batch 的形状
很多人把 rollout 理解成“给每个 prompt 生成一个 answer”。在 RL 里,这个说法太弱了。rollout.n会把一个 prompt 扩展成多条 response,GRPO、Dr. GRPO 等方法正是依赖这种同 prompt 多样本来计算相对优势。源码里,trainer 在生成前执行 gen_batch.repeat(repeat_times=rollout_n, interleave=True),生成后也要把原始 batch 按同样倍数 repeat,才能和生成结果对齐(verl/trainer/ppo/ray_trainer.py:1351-1406)。
_get_gen_batch()还说明了 rollout 不是拿到完整训练样本就直接生成。它会保留 data_source、reward_model、extra_info、uid这些 reward 相关非 tensor 字段,把其他不需要传给 generation 的非 tensor 字段弹掉,然后再把 reward keys 补回 generation batch(verl/trainer/ppo/ray_trainer.py:488-502)。这保证了生成阶段既不过度携带训练侧对象,又不丢后面 reward 需要的上下文。
2. rollout 的边界是服务合同
下面这张图补上图一没有展开的服务边界。看图时注意:进入 server 的不是“一个字符串”,而是一组 token、采样参数、request id、多模态对象和 reward 上下文;出来的也不是普通文本,而是能重新变成训练字段的 token output。
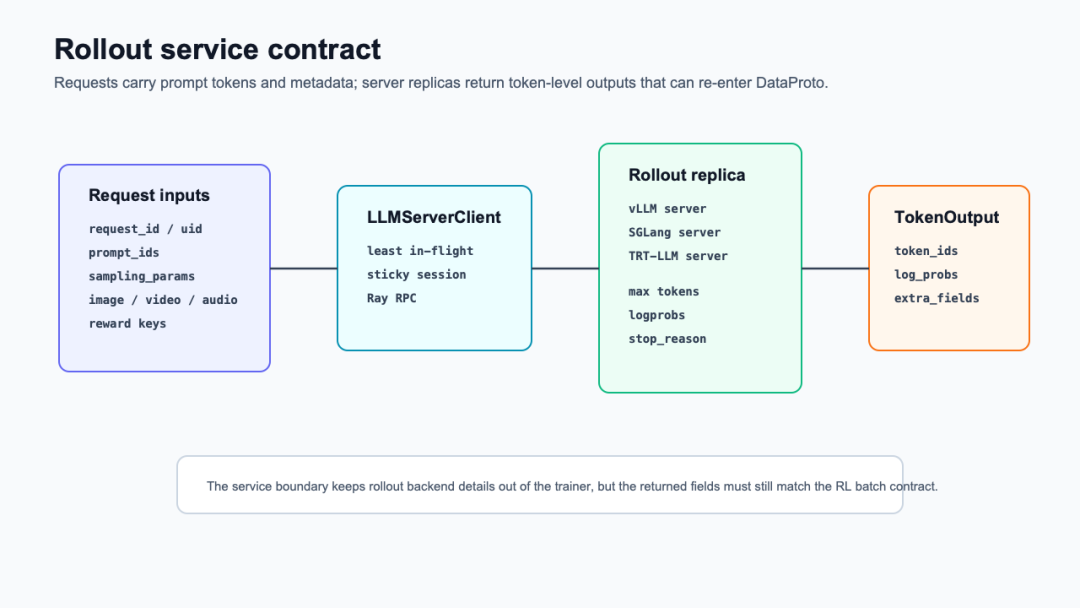
rollout 推理服务合同
这个边界在 async rollout 里更明显。AsyncRolloutRequest保存 request_id、messages、多模态数据、tool schemas、input_ids、prompt_ids、response_ids、mask、position ids、reward scores 和最大长度等字段,并在初始化时用 chat template 生成 tokenized prompt、attention mask、position ids 和多模态 inputs(verl/workers/rollout/schemas.py:81-214,verl/workers/rollout/schemas.py:246-279)。
真正发给后端 server 的一层在 LLMServerClient.generate()。它先从全局 load balancer 里按 request id 获取 server,再把 prompt_ids、sampling_params、image/video/audio、mm_processor_kwargs转发给 server 的 generate.remote(),最后释放 server(verl/workers/rollout/llm_server.py:146-220)。这就是为什么 rollout 更像训练系统内嵌的推理服务,而不是一个 Python 函数调用。
3. 生成阶段为什么常常决定吞吐
rollout 的吞吐不是单个后端的 “tokens/s” 就能解释。下面这张图把压力拆成四类:fanout、token budget、server capacity 和内存状态切换。它们共同决定 marked_timer("gen")里的时间,也决定后面的 reward、logprob 和 update 能不能及时开始。
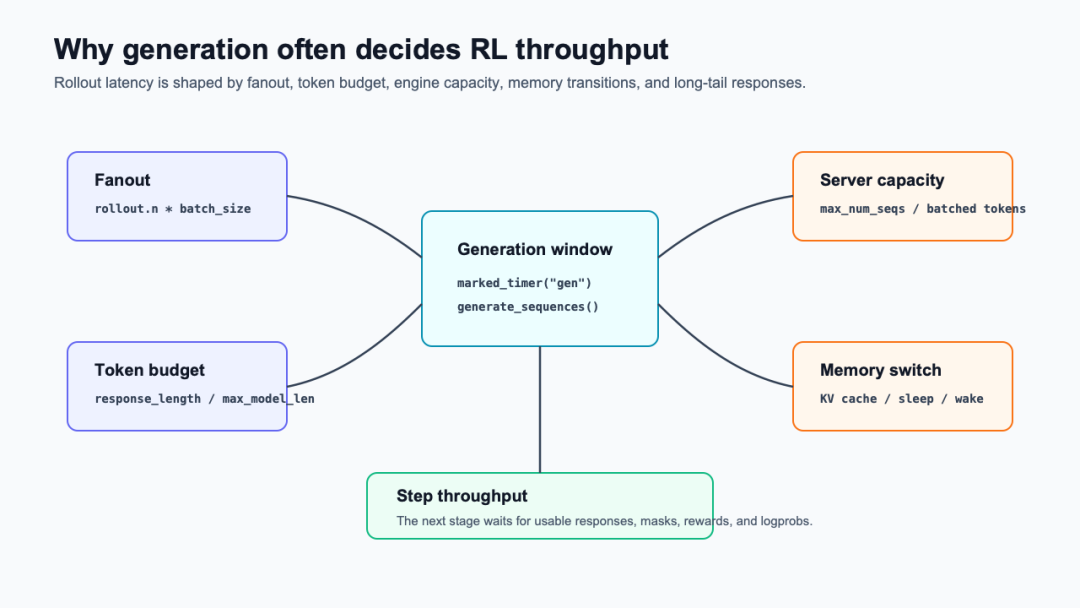
rollout 吞吐瓶颈地图
配置层能直接看到这些压力。rollout.yaml里,temperature/top_k/top_p定义采样,prompt_length/response_length定义 token budget,gpu_memory_utilization指向 KV cache 显存比例,free_cache_engine控制生成后是否释放 engine KV cache,tensor_model_parallel_size/data_parallel_size/pipeline_model_parallel_size决定 rollout 并行形状,max_num_batched_tokens和 max_num_seqs限制 server 批处理容量,n控制每个 prompt 的 response 数(verl/trainer/config/rollout/rollout.yaml:16-119)。
over_sample_rate也暴露了长尾生成的工程事实:当部分请求已经完成到一定比例时,系统可以选择提前终止剩余训练 rollout,以减少尾部等待(verl/trainer/config/rollout/rollout.yaml:121-123)。所以 rollout 性能不是单点优化问题,而是算法样本数、响应长度、server 批处理和尾部延迟之间的折中。
4. rollout 还连接训练权重和推理状态
生成服务不能只追求快,还要追求“用的是该用的权重”。下面这张图把训练和推理状态放成一个循环:actor 更新出新权重,rollout 需要同步或恢复权重与 KV 状态,然后生成下一批 response,再把结果交回 reward/logprob/advantage 路径。
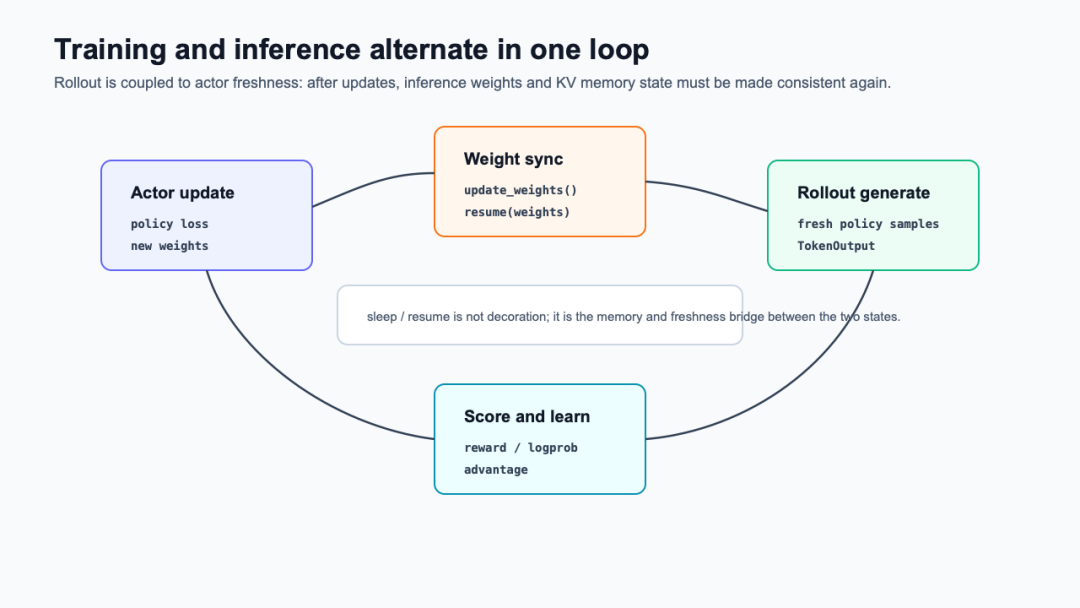
训练和推理状态循环
这张图对应两个源码点。第一,trainer 在生成结束后调用 self.checkpoint_manager.sleep_replicas(),说明生成结束和后续训练之间存在 rollout replica 状态切换(verl/trainer/ppo/ray_trainer.py:1373-1384)。第二,ActorRolloutRefWorker.update_weights()把权重同步拆成 naive 路径和 checkpoint engine 路径;naive 路径会在 free_cache_engine开启时先 resume(tags=["weights"]),更新 rollout weights,再恢复 KV cache(verl/workers/engine_workers.py:663-740)。
这也是后面要单独写 KV cache 和 sleep/resume 的原因:rollout 吞吐不仅来自推理引擎本身,还来自训练和推理在同一组 GPU 资源上的状态切换成本。
小结:rollout 是 RL step 的推理服务边界
本文把 rollout 从“生成 answer”重新放回训练系统。它在源码里至少承担四件事:
扩展 prompt batch
-> 调用推理服务生成 token output
-> 把 response/mask/position 信息并回 DataProto
-> 在 actor 更新后处理权重和推理状态
读到这里,读者应该能从 RayPPOTrainer.fit()的生成段继续追踪 rollout:不是问“后端是不是 vLLM”,而是先问 batch 如何扩展、request 如何构造、server 如何被调度、output 如何回到训练数据结构。下一篇会继续拆开这个服务边界,说明 vLLM、SGLang、TRT-LLM 在 verl 里如何被统一抽象,又在哪些地方保留差异。
本文源码索引
verl/trainer/ppo/ray_trainer.py:488-502:_get_gen_batch()保留 reward 相关非 tensor 字段。verl/trainer/ppo/ray_trainer.py:1343-1409:主循环中 rollout batch 构造、repeat、generate、union 和response_mask。verl/workers/rollout/schemas.py:81-214:AsyncRolloutRequest的字段和初始化逻辑。verl/workers/rollout/schemas.py:246-279:chat template、tokenizer/processor 和多模态输入处理。verl/workers/rollout/llm_server.py:146-220:LLMServerClient的 server acquire、generate 和 release。verl/trainer/config/rollout/rollout.yaml:16-119:采样、长度、KV cache、并行、batch 和rollout.n配置。verl/trainer/config/rollout/rollout.yaml:121-140:over_sample_rate、SGLang wake-up 和 backend engine kwargs。verl/workers/engine_workers.py:663-740:actor 权重同步到 rollout 的路径。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-29,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号