Linux 与 PCIe:深入理解PCIe在内核中的实现

Linux 与 PCIe:深入理解PCIe在内核中的实现

霞姐聊IT
发布于 2026-05-14 18:15:23
发布于 2026-05-14 18:15:23
在现代计算机和服务器中,无论是显卡、NVMe 存储、高速网卡,还是 AI 加速器,它们的极致性能发挥,都离不开 PCIe 提供的高速、低延迟数据通道。
PCIe早已成为高速互连的核心标准,更是支撑数据中心、AI 集群高效运行的“隐形基石”。
Linux 内核对 PCIe 提供了全方位、深层次的支持,从设备发现、资源分配,到驱动适配、错误处理,再到虚拟化、功耗优化,每一个环节都有成熟的内核机制支撑。
本文将为你深入解析Linux 内核中 PCIe 的具体实现细节,带你看懂内核是如何“驾驭”这一高速互连技术的。
一、PCIe 设备发现与资源管理:内核如何“识别”并“分配”设备?
在Linux 内核中,PCIe 设备通过 Root Complex构建完整的总线拓扑,涵盖 Switch、Endpoint和桥接器。
此阶段内核的核心工作的是完成设备枚举、资源分配与地址映射,为后续驱动运行打下基础。
1. 设备枚举(Enumeration):内核的“设备扫描”流程
系统启动阶段,Linux 内核会对 PCIe 总线层级进行递归枚举,扫描 Root Complex 下所有 PCIe Function 设备,其核心过程是访问设备的配置空间Configuration Space。
Configuration Space是设备的标准化硬件描述接口,用于向操作系统暴露身份与资源信息,包含下面这些关键硬件属性:
lVendor ID / Device ID
lClass Code
lHeader Type
lBAR(Base Address Register)
lCapability List
lMSI/MSI-X Capability
lPCIe Capability
lExtended Capability
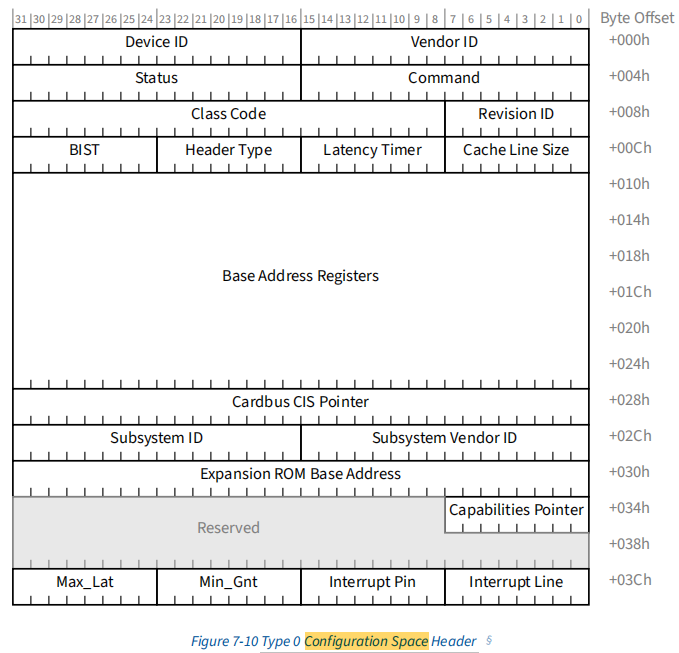
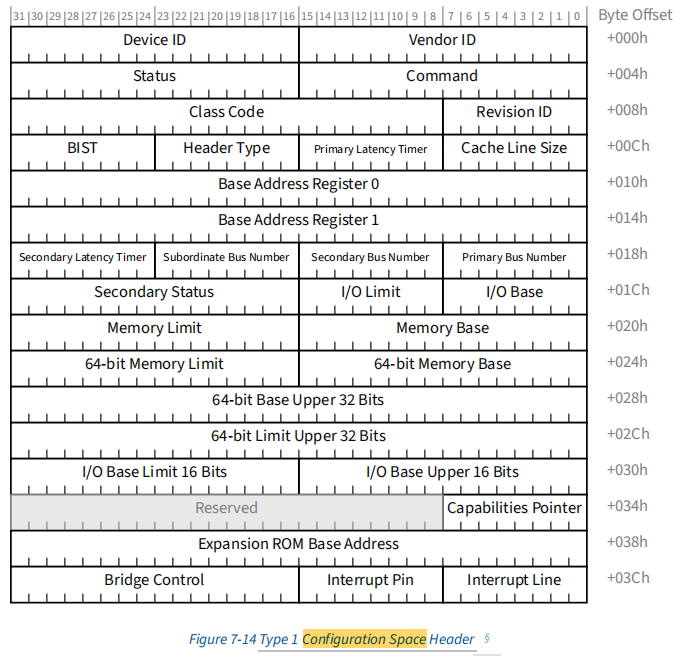
配置空间访问与PCIe 总线枚举由 Linux PCI Core 联合 Host Bridge 驱动统一完成。 内核在启动阶段会遍历PCIe 拓扑结构:
首先读取配置空间起始字段以识别设备存在性与功能类型,
随后解析标准PCI Configuration Header(64 Bytes),完成设备身份识别、BAR 资源探测、Capability 链表解析及总线拓扑构建。
完成设备枚举后,内核会为每个Function 实例化创建struct pci_dev对象,
并将其注册到Linux 通用设备模型struct device中。
从而纳入Linux Driver Model,实现 PCIe 设备的统一拓扑组织、资源管理、热插拔支持以及全生命周期管理。

后续设备驱动加载时,无需直接操作底层PCIe配置事务,只需基于内核已创建的struct pci_dev句柄,通过:
pci_read_config_dword()、pci_write_config_dword()、pci_find_capability()
等标准PCI Core API,即可按需访问配置空间寄存器、解析设备能力结构并完成硬件初始化。
2. 资源分配:给设备“分配专属资源”
设备枚举完成后,内核需为PCIe 设备分配并规划底层硬件资源,保障设备正常寻址与收发数据,核心包含地址资源分配与中断资源配置两部分:
(1)地址资源分配
内核初始化阶段会通过pci_assign_resource() 完成设备资源分配:
依据设备配置空间中BAR 寄存器信息,统一分配MMIO或传统I/O端口地址资源;
分配后的资源信息会挂载存入struct pci_dev 资源链表,由内核统一做地址域管理,从根源避免多设备硬件资源冲突。

(2)中断资源配置
PCIe 设备原生支持 MSI/MSI-X(Message Signaled Interrupts)机制,可通过内存写事务替代传统 INTx 引脚中断,从而避免共享中断线带来的中断争用、虚假共享及电平触发冲突等问题。 相比传统基于PIC/IOAPIC 的引脚中断架构,MSI/MSI-X 依托 APIC 中断路由体系实现中断消息投递,支持中断向量独立分配与多队列并行处理中断,能够显著提升高并发场景下的中断吞吐能力、CPU 亲和性管理能力以及中断响应实时性。
在Linux 内核 PCIe 子系统初始化阶段,内核已完成 PCIe 中断域(IRQ Domain)、中断向量空间及 MSI 路由资源的统一管理与分配。 设备驱动在初始化过程中仅需调用:
pci_alloc_irq_vectors()、pci_enable_msi()、pci_enable_msix()
等标准PCI 接口申请 MSI/MSI-X 中断向量,并结合 request_irq() 完成中断服务例程(ISR)注册,即可实现多队列中断绑定与 CPU affinity 优化,满足网卡、NVMe SSD、高速 FPGA、AI 加速器等高性能 PCIe 设备的高并发业务处理需求。
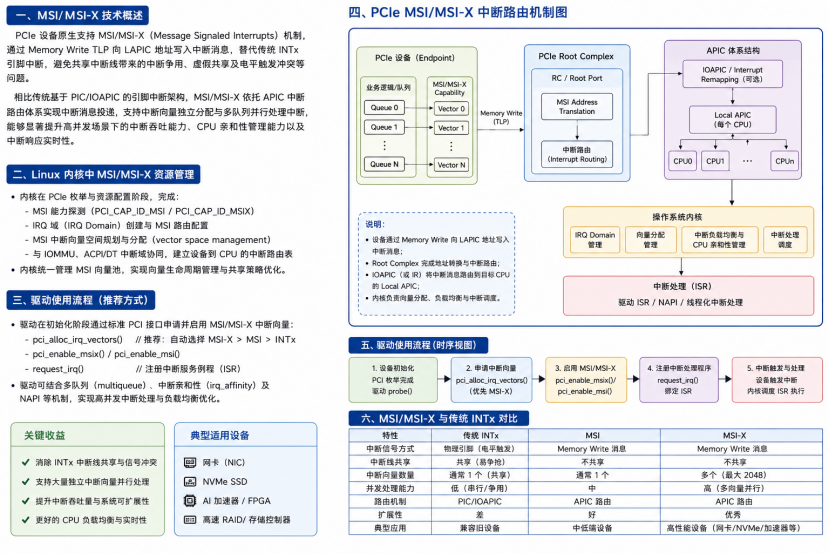
3. BAR 映射:打通 CPU 与设备的“通信通道”
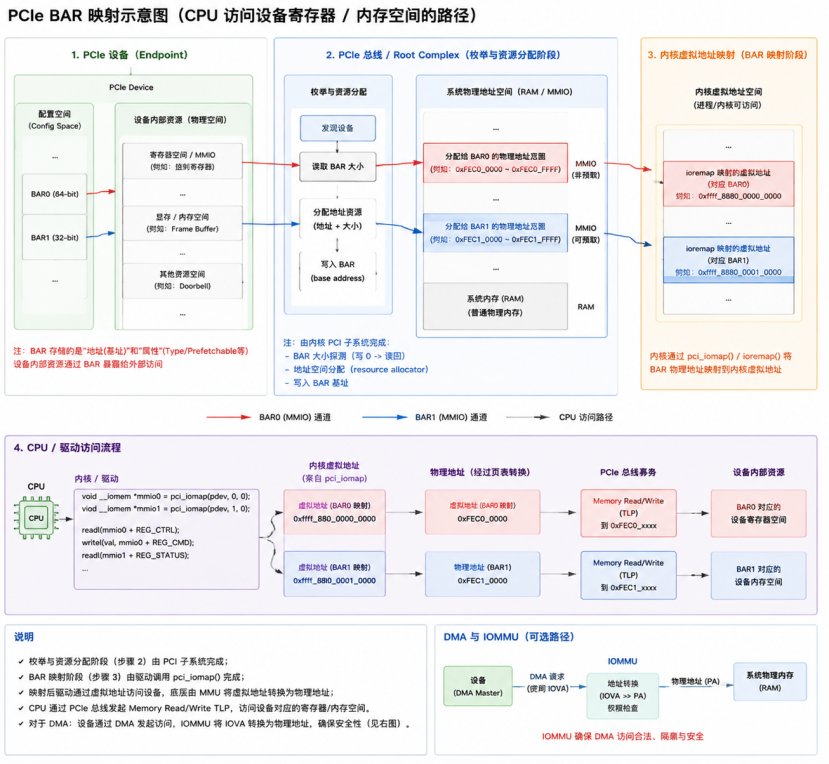
BAR(Base Address Register,基地址寄存器)是 PCIe 设备用于暴露寄存器、显存或 I/O 资源的核心寄存器集合。
通过BAR,设备的物理资源可以被映射到 CPU 地址空间,使驱动程序能够直接访问这些资源。
在Linux 内核中,驱动可使用 pci_iomap()将设备的 MMIO BAR 映射到内核虚拟地址空间。
映射完成后,驱动无需关心物理地址,可直接通过虚拟地址访问设备寄存器,简化开发流程。
对于支持DMA 的设备,内核配合 IOMMU 将内存映射到设备 DMA 地址空间,确保 DMA 传输安全且不会越界。
二、驱动接口与DMA 实现:内核如何“对接”设备并实现高速传输?
PCIe 设备业务功能的正常运转,依赖设备驱动与 Linux 内核的深度协同;
而DMA是支撑 PCIe 设备高速批量数据传输的核心能力。
内核不仅提供标准化的PCIe 驱动注册框架,还封装了完备的 DMA 寻址、地址映射与传输管理机制,大幅屏蔽了底层硬件差异,使驱动开发者可快速完成各类 PCIe 外设的适配与高速业务开发。
1. PCI/PCIe 驱动注册:内核与驱动的“对接桥梁”
Linux 内核为 PCIe 设备驱动提供了标准化开发与注册框架。
驱动开发者只需定义并填充struct pci_driver 结构体,再调用内核标准接口完成注册,即可接入内核PCI Core 子系统,实现设备匹配与生命周期管理。
驱动通过pci_register_driver(&my_driver)接口完成注册。
struct pci_driver 核心关键字段包含:
lname:驱动名称标识
lid_table:PCI 设备厂商号 / 设备号匹配表,用于内核自动匹配对应硬件
lprobe:设备匹配成功后的初始化回调函数
lremove:设备移除或驱动卸载时的资源回收回调函数
回调函数核心职责:
probe () 回调:内核枚举到与id_table 匹配的 PCIe 设备后,会自动触发执行 probe(),是驱动设备初始化的核心入口,典型工作流程:
l调用pci_enable_device() 激活 PCIe 设备、使能总线资源;
l通过pci_iomap() 完成 BAR 空间内核虚拟地址映射,建立寄存器访问通道;
l调用dma_set_mask() 设置设备 DMA 寻址能力与地址属性;
l申请并注册中断服务例程(request_irq() 或 MSI/MSI-X 相关接口);
l初始化设备私有寄存器、业务数据结构与软硬件工作环境。
remove () 回调:设备热插拔下线、驱动卸载时内核自动调用remove(),负责反向资源清理,避免资源泄露与系统异常:
l注销已注册的中断资源(free_irq());
l调用pci_iounmap() 释放 BAR 虚拟地址映射;
l通过pci_disable_device() 禁用 PCIe 设备;
l释放驱动运行过程中申请的内存、设备上下文等各类软硬件资源。
2. DMA 与 P2P 支持:实现高速无CPU干预传输
DMA的核心作用是让 PCIe 设备无需 CPU 干预,直接与系统内存进行数据传输,彻底解放 CPU 算力,极大提升设备数据吞吐效率。
Linux 内核针对 DMA 传输提供了完善的 API 与机制支持,覆盖不同传输场景,具体如下:
(1)连续一致性内存分配
内核通过dma_alloc_coherent() 函数,为 DMA 设备分配物理连续、cache coherent 的内存区域,保证高速、稳定的传输,避免因内存不连续导致 DMA 访问复杂化或性能下降。
(2)P2P(Peer-to-Peer)DMA 设备间直接传输
P2PDMA 允许两个 PCIe 设备直接访问彼此的内存。
Linux 内核通过 IOMMU 配置映射表,实现设备间直接数据传输,无需经过 CPU 或系统内存中转,有效降低延迟、提升吞吐效率。
(3)散布/聚集(SG List)映射
对于非连续内存区域,驱动可通过dma_map_page() 或 dma_map_sg() 将这些页面映射到设备可直接访问的 DMA 地址空间,设备可按 scatter-gather table 顺序读取,适用于大尺寸、分散式数据传输。
3. 链路训练与速率管理:平衡性能与功耗
PCIe 链路速率(Link Speed)与通道宽度(Link Width)是决定设备传输带宽与整体性能的核心因素。
Linux 内核提供了完善的 PCIe 链路管理接口,支持驱动依据业务负载与性能诉求,动态配置和调优链路参数。
(1) 链路参数配置
l驱动可通过pci_set_max_link_speed()、pci_set_link_width() 等内核接口,设定链路协商的最大速率(PCIe 4.0/5.0 等)与通道宽度(x1/x4/x8/x16)。
l链路配置需满足本端设备、上游Port、PCIe 交换机均兼容对应速率与宽度,否则配置无法生效。
l合理整定链路参数,可在传输性能与功耗开销之间实现最优平衡。
(2)高速链路稳定性优化
l针对PCIe 5.0 及以上高速链路,内核与 PHY 驱动协同完成链路均衡(Equalization)调校与误码率(BER)实时监控,保障高速信号完整性。
l驱动可按需触发链路重训练(Link Retraining),动态修复链路信号质量,降低传输误码率,维持高速链路稳定运行。
l配合PCIe 链路电源管理(LSPM)机制,可在高性能全速模式与低功耗休眠状态之间动态切换,兼顾性能与节能。
三、可靠性与容错:内核如何“应对”设备故障?
在服务器、数据中心等关键场景中,PCIe 设备的可靠性至关重要。Linux 内核提供完善的容错机制,可及时检测和处理设备错误,避免故障扩散,保障系统稳定运行:
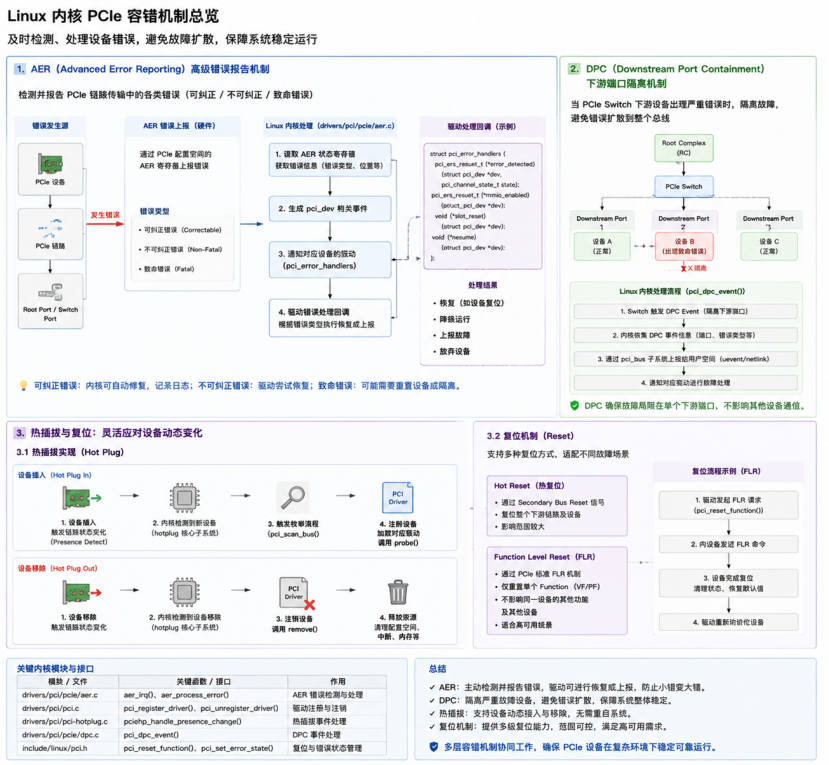
1. AER(Advanced Error Reporting)
(1)PCIe 标准定义的高级错误报告机制,支持可纠正(Correctable)、不可纠正(Uncorrectable)和致命错误(Fatal)三类错误。
(2)当设备出现错误时,会通过AER 配置空间寄存器上报,触发中断。
(3)内核AER 子系统(drivers/pci/pcie/aer.c)检测错误后,生成事件,并调用驱动注册的回调(`struct pci_driver.aer_error_detected`)。
(4)驱动可根据错误类型执行恢复操作(如功能重置、Hot Reset 或上报用户态)。
2. DPC(Downstream Port Containment)
(1)当PCIe Switch 下游设备出现严重错误时,Switch 硬件触发 DPC,将故障设备隔离,防止错误蔓延到整条总线。
(2)内核通过`pci_dpc_event()` 收集 DPC 事件,并通过 `pci_bus` 子系统上报给用户空间,同时通知驱动进行处理。
3. 热插拔与复位
(1)热插拔:内核hotplug 核心子系统实时监控 PCIe 链路变化,检测到新设备插入时自动触发枚举、注册设备并加载驱动;设备移除时自动注销并释放资源,无需重启。
(2)复位机制:
①Hot Reset:复位设备功能块,可能影响多功能设备
②Function Level Reset (FLR):仅复位单功能,不干扰其他设备功能
(3)内核通过`pci_reset_fn()` 或 `pci_reset_device()` 执行复位操作,实现高可用场景下的灵活容错。
四、虚拟化支持:内核如何“共享”PCIe 设备?
在虚拟化场景中,多个虚拟机可能需要共享或独占PCIe 设备。
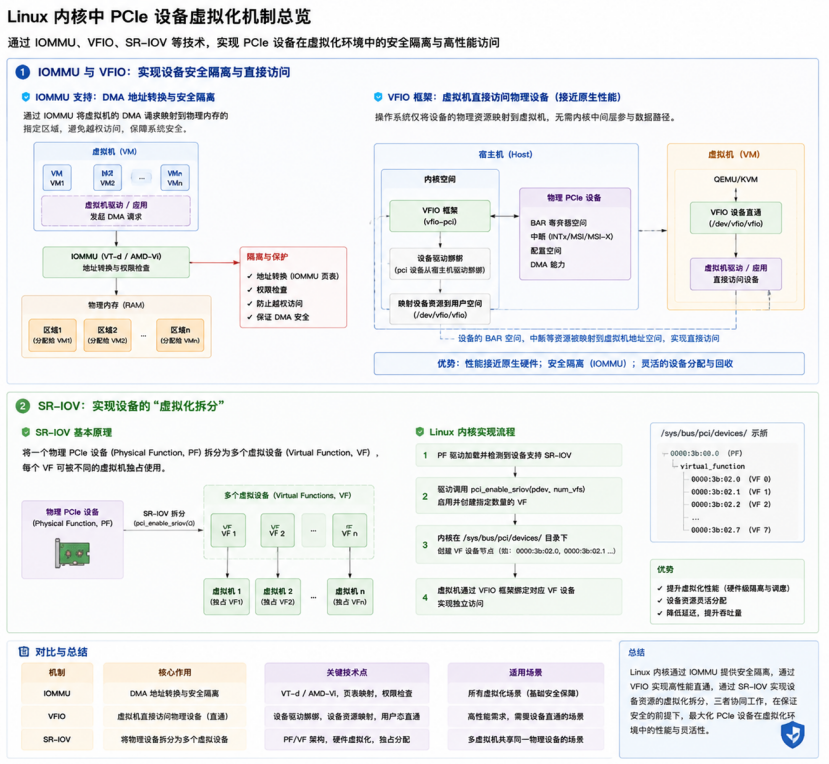
Linux 内核通过 IOMMU、VFIO、SR-IOV 等机制,实现 PCIe 设备虚拟化,兼顾性能与安全性:
1. IOMMU 与 VFIO:实现安全隔离与直接访问
(1)IOMMU(Intel VT-d / AMD-Vi)将虚拟机的 DMA 地址(IOVA)映射到物理内存(PA),确保 DMA 访问合法,防止越权访问其他虚拟机或内核内存。
(2)VFIO 框架提供用户态驱动接口,使虚拟机可以通过 VFIO 将物理设备的 BAR、MSI/MSI-X 等资源映射到虚拟机地址空间,实现接近原生性能的设备直通访问。
2. SR-IOV(Single Root I/O Virtualization):实现设备虚拟化拆分
(1)SR-IOV允许将一个物理 PCIe 设备(PF,Physical Function)拆分为多个虚拟设备(VF,Virtual Function)。
(2)内核驱动通过`pci_enable_sriov()` 创建 VF 设备节点,虚拟机可通过 VFIO 绑定 VF,实现独立访问。
(3)每个VF 拥有独立 BAR 和 DMA 通道,可提供虚拟机独占的高性能通路,同时支持灵活的资源分配。
五、链路与功耗管理:内核如何“节能”并优化性能?
Linux 内核对 PCIe 链路功耗管理进行了深度适配与优化,原生支持多级低功耗链路状态,并结合动态链路功耗管理(dLPM)机制,在不影响业务性能的前提下最大限度降低整机功耗,可适配移动终端、服务器等各类应用场景。
1. 多级低功耗链路状态(ASPM / dLPM)
内核实现文件:drivers/pci/pcie/aspm.c
核心结构体:
struct pcie_link_state:维护链路状态、ASPM 能力、延迟参数
struct aspm_latency:记录 L0s/L1 退出延迟
初始化:
l`pcie_aspm_init_link()` 读取设备与根端口PCI_EXP_LNKCAP/PCI_EXP_LNKCTL寄存器
l协商启用L0s/L1/L1.1 功能
l`calc_l0s_acceptable()/calc_l1_acceptable()` 计算系统可接受退出延迟,避免性能影响
运行时:
lL0s:轻量级空闲省电,由 LTSSM 自主切换,退出延迟 <1μs,适合短时空闲
lL1/L1.1:中级休眠,内核通过 `pcie_aspm_enter_l1()` 触发,关闭部分时钟与电路,退出延迟 ~5μs,适合长空闲
lL2:深度休眠,由 `pci_save_state()/pci_restore_state()` 配合系统 S3/S4 管理,关闭参考时钟与 PLL,仅保留辅助电源,退出需链路重训练
dLPM:动态调整链路状态,实现性能与功耗平衡
2. 链路快速恢复
l当设备有数据传输时,内核调用`pcie_aspm_exit_l1()`,LTSSM 快速切换回 L0 全速工作态
l保证低延迟与高性能并兼顾节能
3. 休眠与唤醒接口
l驱动可通过`pci_save_state()` / `pci_restore_state()` 配合系统休眠流程,完整保存与恢复 PCIe 配置空间和链路状态
l保证设备休眠后可正常唤醒,链路和业务稳定运行

六、调试与诊断工具:内核提供的“排查利器”
为了方便开发者调试PCIe 设备和内核实现,Linux 提供了多种实用工具,可快速查看设备状态、排查故障、分析性能瓶颈:
1. lspci -vv 常用 PCIe 设备查看工具
显示配置空间信息、BAR 映射、链路速率、MSI/MSI-X 向量、能力链表等
可结合驱动绑定状态快速定位硬件问题
`lspci -vvv` 可显示更详细能力链表与内核启用状态
2. setpci 低级调试工具,可直接读写 PCIe 配置寄存器
用于调试链路参数、验证设备配置
注意:操作不当可能导致设备不可用,一般仅在开发/验证阶段使用
3. dmesg 查看内核日志
获取AER 错误、热插拔事件、链路状态变化、驱动加载状态
可配合`dmesg | grep pci` 快速过滤 PCIe 相关事件
结合`/sys/bus/pci/devices/` 可查看内核 PCIe 设备状态
4. perf / trace-cmd性能分析工具
监控PCIe 总线 DMA 事务、传输延迟、吞吐瓶颈
示例:
`perf record` / `perf report` 分析 DMA 调用或中断响应
`trace-cmd record -e pci` 或 `-e pci:dma` 记录内核层 PCIe 活动
有助于优化驱动和应用程序性能
七、总结:Linux 内核如何“驾驭”PCIe 高速互连?
Linux 内核对 PCIe 的支持,已形成覆盖“发现 → 配置 → 传输 → 容错 → 虚拟化 → 节能 → 调试”的完整体系,核心如下:
1. 设备发现与资源管理
- 通过 PCIe 枚举扫描 Bus/Device/Function,生成 `struct pci_dev`
- 统一分配 MMIO、中断等资源,构建规范化设备管理模型
2. 驱动与 DMA 实现
- 提供标准化驱动接口(`struct pci_driver`)
- 支持 DMA 和 P2P 传输,结合 IOMMU 实现安全高效数据访问
3. 可靠性与容错
- 内核支持 AER、DPC、热插拔、FLR 等机制
- 可主动检测错误、隔离故障并恢复设备,保障系统稳定
4. 虚拟化支持
- 支持 SR-IOV PF/VF 拆分
- VFIO 驱动实现虚拟机直通访问
- IOMMU 提供 DMA 隔离,实现安全共享
5. 功耗管理与链路优化
- 多级 ASPM / dLPM 低功耗状态管理
- 动态调节链路速率与通道数,平衡性能与功耗
- 适配移动终端、服务器及数据中心等场景
6. 调试与性能分析工具
- 提供 lspci、setpci、dmesg、perf、trace-cmd 等工具
- 覆盖硬件状态、内核事件及性能分析,全链路排查和优化能力
正是这些完善的机制,使Linux 内核能够充分发挥 PCIe 的高速、低延迟和可扩展特性,支撑 PC、服务器、数据中心以及 AI/云计算集群等多种应用场景,成为现代高速计算平台的核心基石。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-12,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号