OpenSpec 最佳实战:3 条命令跑通规范驱动开发全流程(实战版)
原创
OpenSpec 最佳实战:3 条命令跑通规范驱动开发全流程(实战版)
原创
运维有术
发布于 2026-05-01 23:37:19
发布于 2026-05-01 23:37:19
🚩 2026 年「术哥无界」系列实战文档 X 篇原创计划 第 92 篇,AI 编程最佳实战「2026」系列第 22 篇
大家好,欢迎来到 术哥无界 | ShugeX | 运维有术。
我是术哥,一名专注于 AI 编程、AI 智能体、Agent Skills、MCP、云原生、AIOps、Milvus 向量数据库的技术实践者与开源布道者!
Talk is cheap, let's explore。无界探索,有术而行。
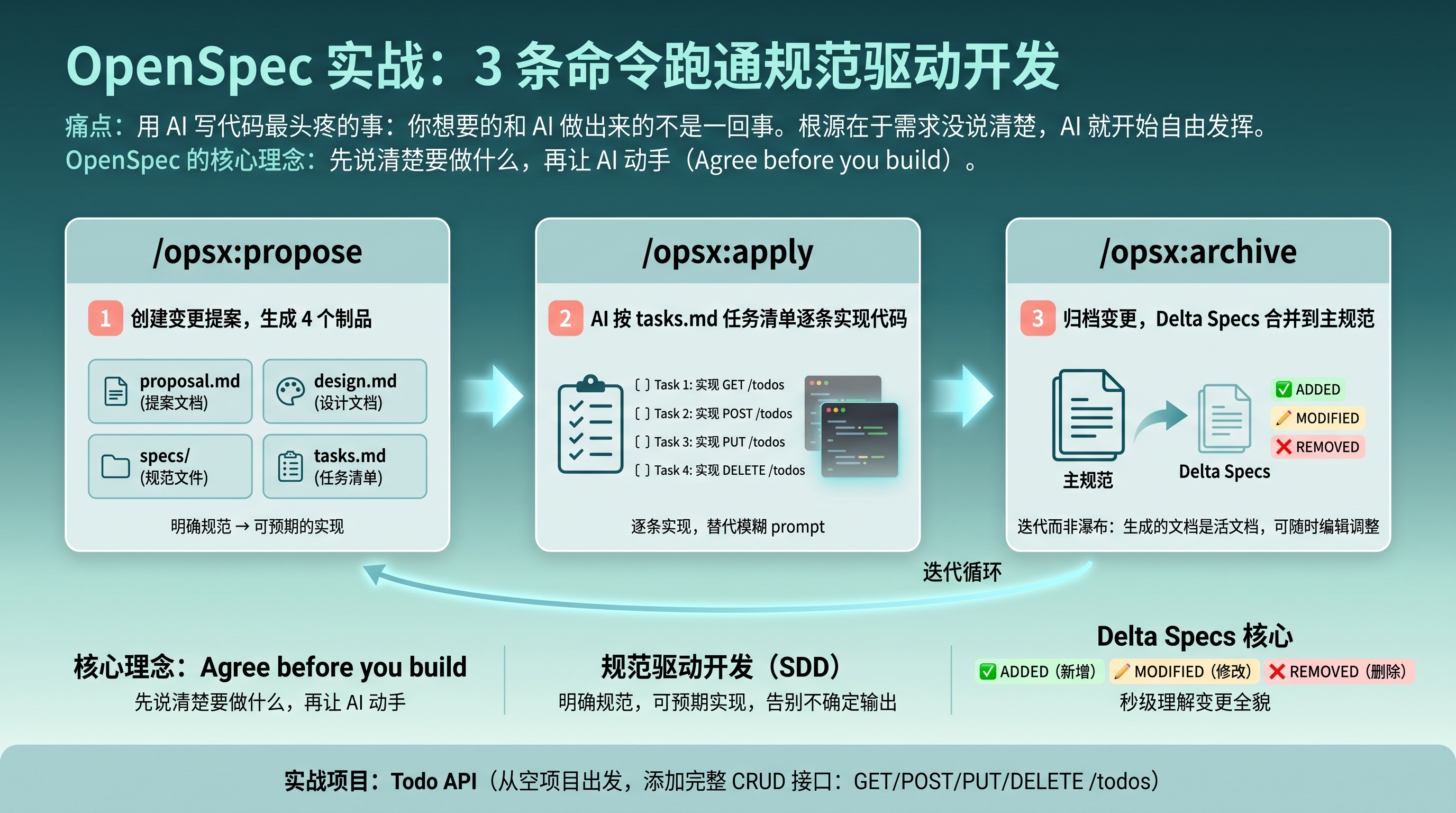
OpenSpec 工作流程概览
图 1:OpenSpec 核心工作流概览
用 AI 写代码让人头疼的事,不是工具不好用,而是你想要的和 AI 做出来的,压根不是一回事。
你让它加个登录功能,它给你整了一套 OAuth2 + JWT + 微服务架构。你让它改个按钮颜色,它把整个样式系统重构了。这种事情反复发生,耗掉的时间比你自己写还多。
社区的反馈也很直接 - CSDN 上有篇帖子说得挺到位:AI 开发的核心问题是幻觉,生成的代码经常不符合需求、违反项目规范。根源在于需求没说清楚,AI 就开始自由发挥。
OpenSpec 就是来解决这个问题的。它的核心理念很简单:先说清楚要做什么,再让 AI 动手。官方的说法叫 Agree before you build。
这篇教程带你从零开始,用一个 Todo API 项目,完整走一遍 OpenSpec 的核心工作流。5 分钟上手,3 条命令跑通。
你将完成什么
- ✅ 安装 OpenSpec CLI 并在一个新项目中完成初始化
- ✅ 用
/opsx:propose创建一个完整的变更提案(包含 4 个制品) - ✅ 用
/opsx:apply让 AI 按照任务清单实现代码 - ✅ 用
/opsx:archive归档变更,理解 OpenSpec 的变更管理机制
环境准备
你需要准备
- Node.js >= 20.19.0(建议 v24,官方推荐)
- 一个 AI 编程助手(Claude Code、Cursor、Windsurf 等都可以)
- 稳定的网络连接
- 一个空的项目目录(后面会创建)
预计时间
⏱️ 完成本实战大约需要 15-20 分钟
难度等级
⭐⭐ 入门偏实战 - 需要基本的命令行操作经验
Step 1:安装 OpenSpec CLI 并初始化项目
1.1 安装 CLI
打开终端,运行安装命令:
# 全局安装 OpenSpec CLI
npm install -g @fission-ai/openspec@latest安装完成后,验证一下:
openspec --version预期输出类似:
1.x.x如果你看到类似 1.3.1 这样的版本号,说明安装成功了。版本号会随更新变化,不用纠结具体数字。
1.2 创建项目目录
# 创建一个 Todo API 项目
mkdir todo-api && cd todo-api1.3 初始化 OpenSpec
这一步是关键 - openspec init 会在项目中创建 OpenSpec 的目录结构和配置文件。
如果你想快速初始化(非交互式),直接指定工具:
# 以 Claude Code 为例,非交互式初始化
openspec init --tools claude如果你想让你 OpenSpec 支持所有 AI 工具:
openspec init --tools all如果不用 --tools 参数,会进入交互式选择:
openspec init
# 交互式选择你要用的 AI 工具1.4 看看初始化后的目录结构
初始化完成后,项目里会多出几个东西。先看 openspec/ 目录:
tree openspec/预期输出:
openspec/
├── changes/
│ └── archive/
└── specs/没错,刚初始化完就是空的。specs/ 用来存放项目规范,changes/ 用来管理变更提案。规范内容会在后续 propose → archive 的过程中逐步积累起来。
再看 .claude/ 目录(如果你用的是 Claude Code):
.claude/
├── commands/
│ └── opsx/
│ ├── apply.md
│ ├── archive.md
│ ├── explore.md
│ └── propose.md
└── skills/
├── openspec-apply-change/SKILL.md
├── openspec-archive-change/SKILL.md
├── openspec-explore/SKILL.md
└── openspec-propose/SKILL.md这里生成了 4 个斜杠命令,对应 OpenSpec 的核心操作:
命令 | 作用 |
|---|---|
| 创建变更提案,生成 4 个制品 |
| 按任务清单实现代码 |
| 归档已完成的变更 |
| 纯思考模式,不写代码,用于探索想法、调查问题 |
commands/ 目录下的是斜杠命令定义文件,skills/ 目录下的是技能文件 - 简单理解,就是告诉 AI 怎么执行这些命令的详细指令。
验证点
✅ openspec --version 能正常输出版本号
✅ 项目根目录下出现了 openspec/ 文件夹
✅ openspec/specs/ 和 openspec/changes/ 目录存在
✅ .claude/commands/opsx/ 下有 4 个斜杠命令文件
到这里,基础环境就算搭好了。接下来就是核心操作。

初始化后的目录结构
图 2:OpenSpec 初始化后的目录结构和命令对照
Step 2:用 /opsx:propose 创建第一个变更
这一步是 OpenSpec 工作流的核心 - 在写代码之前,先把需求说清楚。
打开你的 AI 编程助手(以 Claude Code 为例),在对话中输入:
/opsx:propose然后告诉 AI 你想做什么。比如我们的场景是给 Todo API 添加 CRUD 接口:
给这个 Todo API 项目添加完整的 CRUD 接口,包括:
- GET /todos - 获取所有待办事项
- POST /todos - 创建新待办事项
- PUT /todos/:id - 更新待办事项
- DELETE /todos/:id - 删除待办事项AI 会花几秒钟生成变更提案。预期输出类似:
Change **add-todo-crud** created at `openspec/changes/add-todo-crud/`
Artifacts created:
- **proposal.md** — What & why: adding REST CRUD API for todo items
- **design.md** — Technical design: endpoints, data model, HTTP status codes
- **specs/todo-crud-api/spec.md** — Detailed requirements with scenarios
- **tasks.md** — Implementation checklist
All artifacts created! Ready for implementation.看到了吗?一条命令,生成了 4 个制品。来逐个看看它们是什么。
2.1 proposal.md - 变更提案
这个文件回答两个问题:为什么要做这个变更,以及改变了什么。
通常包含:
- 变更的背景和动机
- 变更的范围和影响
- 相关的上下文信息
2.2 specs/ - 需求规范(Delta Specs)
这是 OpenSpec 的精华所在。changes/add-todo-crud/specs/ 目录下的文件,以 Delta 格式描述这次变更涉及的需求变化。
Delta Specs 的格式长这样:
## ADDED Requirements
### Requirement: Todo CRUD API
The system MUST provide RESTful endpoints for...
## MODIFIED Requirements
### Requirement: API Response Format
- BEFORE: ...
- AFTER: ...
## REMOVED Requirements
### Requirement: ...三种操作,语义清晰:
类型 | 含义 |
|---|---|
ADDED | 新增的需求,归档时会追加到主规范 |
MODIFIED | 修改已有需求,归档时会替换 |
REMOVED | 删除的需求,归档时从主规范移除 |
这种方式的好处是:你不需要读完整的主规范,只需要看 Delta 就能理解这次变更的全貌。官方的说法叫 Review proposals in seconds。
注意:对于全新项目的首次变更,通常只会出现 ADDED Requirements。MODIFIED 和 REMOVED 会在后续迭代中修改已有需求时才出现。
2.3 design.md - 技术方案
描述怎么实现。包括技术选型、架构设计、关键决策等。
2.4 tasks.md - 任务清单
这是 AI 后续实现代码的待办清单。每个任务都有编号,具体内容由 AI 根据项目情况动态生成,格式类似:
1.1 Create Todo data model
1.2 Set up storage layer
2.1 Implement POST /todos
2.2 Implement GET /todos
...验证点
✅ openspec/changes/add-todo-crud/ 目录存在
✅ 目录下包含 proposal.md、design.md、tasks.md 和 specs/ 四个制品
✅ Delta Specs 文件中有 ADDED Requirements 段落
你可以随时编辑这些文件。觉得 AI 生成的方案有问题?直接改 design.md。觉得需求描述不够精确?改 specs/ 下的文件。这不是一次性生成不可变的文档,而是可以随时调整的活文档。
这也是 OpenSpec 和其他重型规范框架的区别 - 社区里有人评价说:OpenSpec 像一位敏捷的工程师,追求快速迭代和极简主义,和 Spec-Kit 那种严谨架构师风格不太一样。
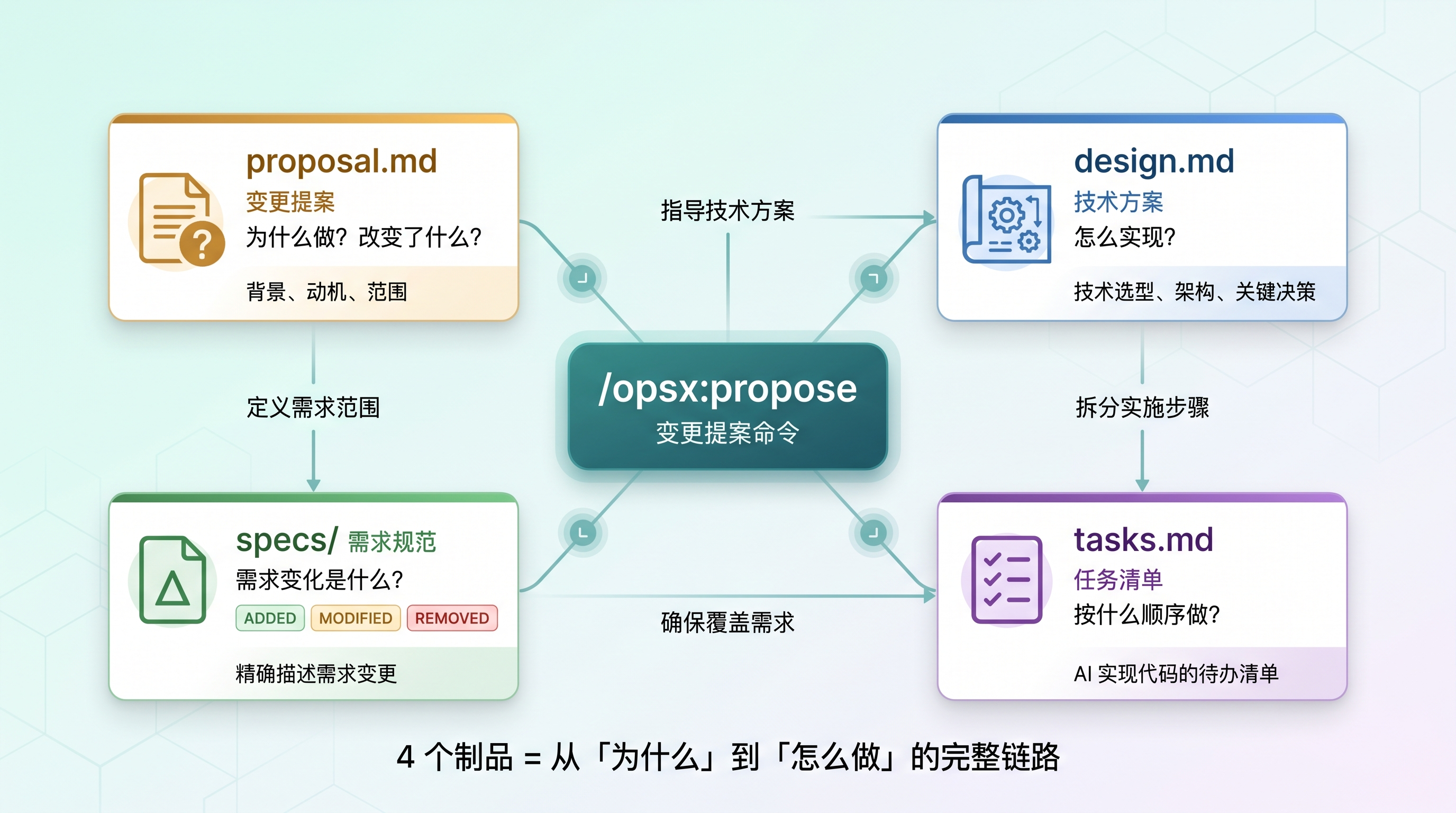
propose 生成的 4 个制品及其关系
图 3:/opsx:propose 生成的 4 个制品关系图
Step 3:用 /opsx:apply 实现任务
需求对齐了,方案也审过了,接下来就是让 AI 动手写代码。
在 AI 编程助手中输入:
/opsx:applyAI 会按照 tasks.md 里的任务清单,逐个执行。完成后会输出一个汇总报告:
## Implementation Complete
**Change:** add-todo-crud
**Schema:** spec-driven
**Progress:** 12/12 tasks complete ✓
### Files Created
src/
├── todo.js # Todo model + createTodo + isValidTitle
├── store.js # In-memory Map store
├── app.js # HTTP server with CRUD endpoints
└── test.js # Integration tests
### Completed This Session
- [x] 1.1 Create Todo data model
...
All tasks complete! You can archive this change with `/opsx:archive`.这里有个值得注意的点:AI 是按照 tasks.md 的顺序执行的。所以在上一步审查 tasks.md 的时候,如果发现任务拆分不合理或者顺序有问题,一定要提前调整。
另外注意看 Files Created 部分 - 因为我们的项目是空的,AI 没有用 Express,而是直接用 Node.js 的 http 模块实现了 CRUD。具体用什么技术栈,取决于项目当前的上下文。如果你的项目已经有 Express,生成的代码自然会基于 Express。
从社区实战案例来看,Cursor 用户在使用 OpenSpec 时的反馈是:这些文档都可以编辑和 AI 再次改动,当认为改动计划没问题后,可以执行 apply 指令。这就是 OpenSpec iterative not waterfall 的体现 - 你可以反复调整方案,满意了再动手。
验证点
✅ 项目中出现了实际的代码文件(具体文件名由 AI 根据项目上下文生成)
✅ tasks.md 中列出的功能都有对应的代码实现
✅ 代码实现了 proposal.md 中描述的变更范围
如果实现过程中遇到问题,别慌。你可以:
- 手动修改 AI 生成的代码
- 重新运行
/opsx:apply让 AI 继续未完成的任务 - 回到
/opsx:propose阶段,修改 tasks.md 重新规划
你在用 AI 编程时遇到过类似的问题吗?比如 AI 生成的代码和预期不符,欢迎在评论区聊聊你的经验。
Step 4:用 /opsx:archive 归档变更
代码写完了,验证也没问题,最后一步是归档。
归档做了两件事:
- 把变更目录移到归档文件夹(
openspec/changes/archive/) - 如果 Delta Specs 有内容可合并,会同步到主规范(
openspec/specs/)
需要说明的是,对于全新项目的首次变更,归档主要是做 mv 移动。主规范的积累是一个渐进过程 - 随着后续变更不断归档,你的 openspec/specs/ 会越来越完整。
执行归档:
/opsx:archive预期输出:
## Archive Complete
**Change:** add-todo-crud
**Schema:** spec-driven
**Archived to:** `openspec/changes/archive/2026-04-23-add-todo-crud/`
**Specs:** No delta specs
All 12 tasks complete. All 4 artifacts done.归档后发生了什么
先看 openspec/changes/ 目录:
归档前:
openspec/changes/
└── add-todo-crud/ ← 活跃变更归档后:
openspec/changes/
└── archive/
└── 2026-04-23-add-todo-crud/ ← 已归档变更目录被移到了 archive/ 下面,命名格式是 YYYY-MM-DD-<change-name>。
再看 openspec/specs/ 目录:对于首次变更,归档输出 Specs: No delta specs,意味着 specs/ 可能不会立即有内容。别担心,这是正常的 - 主规范会在后续迭代中逐步积累。每次新的变更归档时,如果有 Delta Specs 需要合并,OpenSpec 会自动处理。
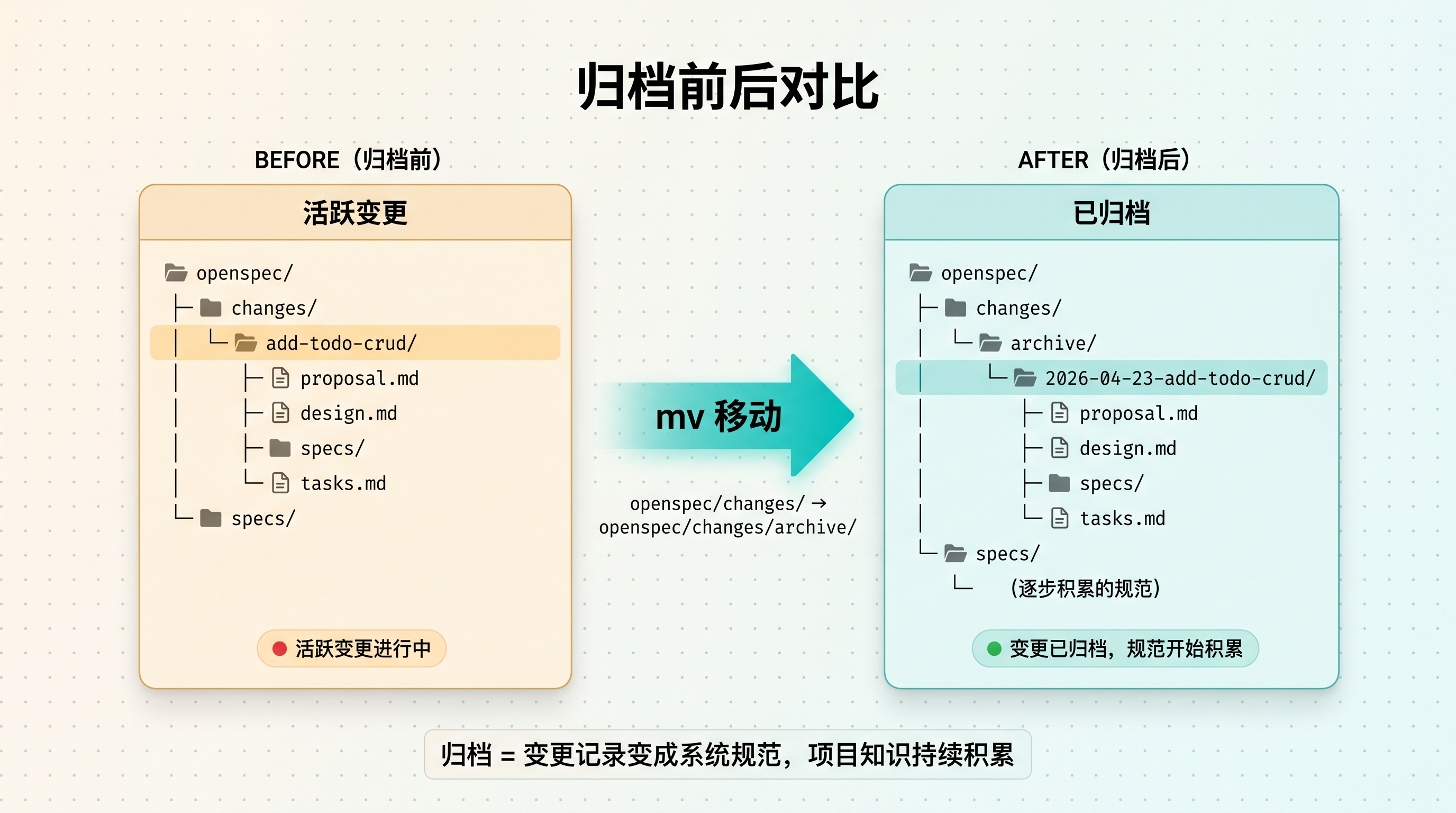
归档前后目录结构对比
图 5:归档前后目录结构对比
为什么归档很重要
归档的本质是把变更记录变成系统规范。
随着项目迭代,你的 openspec/specs/ 目录会越来越完整。每次新开一个会话,AI 读到 specs 就知道项目当前的状态 - 有哪些 API、用的是什么架构、遵循什么规范。
CSDN 上有个实战用户说得挺好:这个项目很有价值的应该是功能增强和多人协作开发,尤其是大型项目很多都是基于原有项目扩展和改造。之前由于模型上下文的问题导致很多企业级项目以及一些老旧项目升级改造 AI 就变得难以搞定。
验证点
✅ openspec/changes/add-todo-crud/ 已移到 archive/ 目录下
✅ 归档目录名包含日期前缀,格式为 YYYY-MM-DD-<change-name>
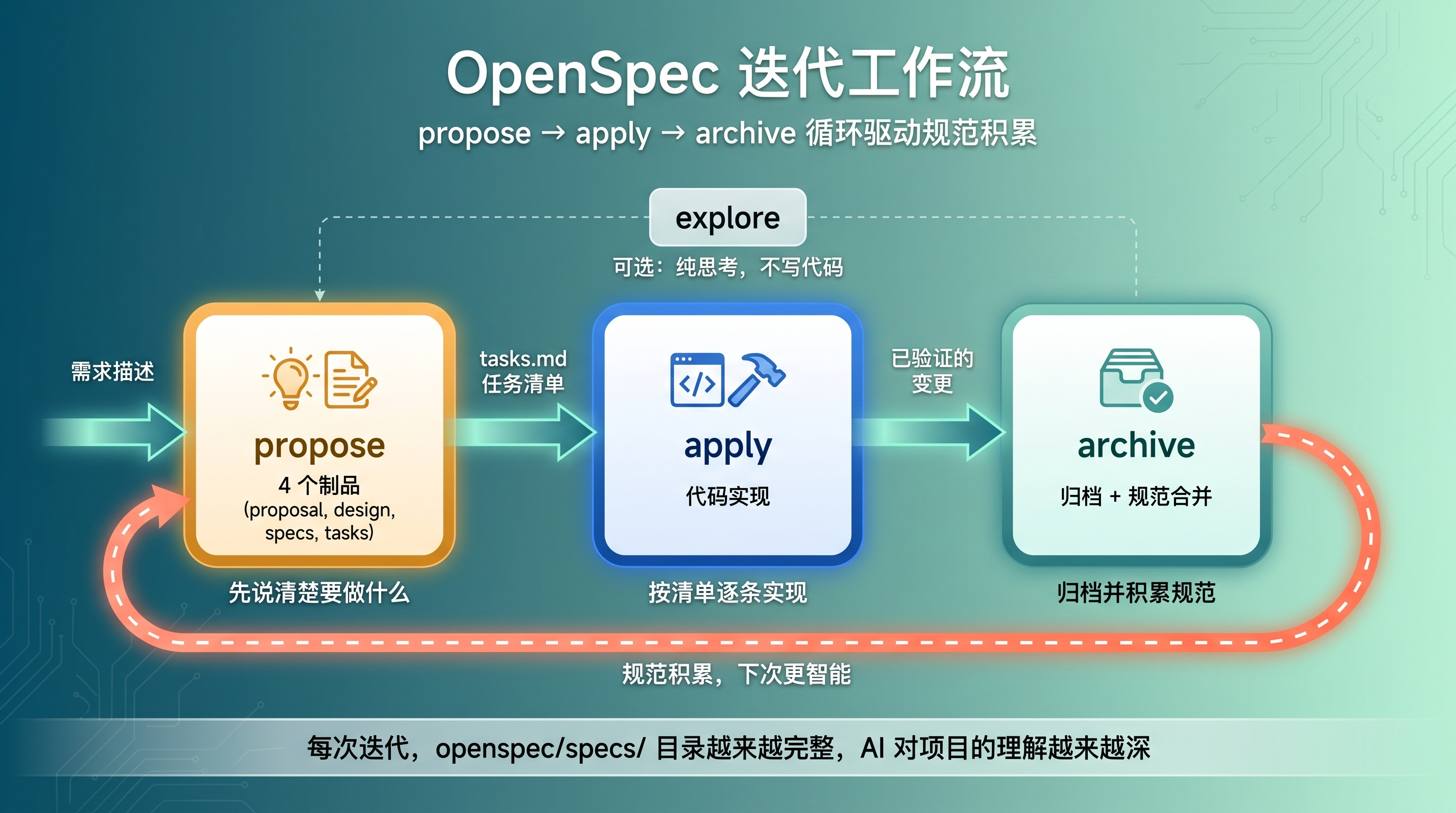
OpenSpec 迭代工作流
图 4:OpenSpec 迭代工作流循环
完整流程回顾
来,把刚才做的事情串一遍:
# 1. 安装
npm install -g @fission-ai/openspec@latest
# 2. 初始化项目
mkdir todo-api && cd todo-api
openspec init --tools claude
# 3.(可选)先探索一下思路
/opsx:explore → 纯思考,不写代码
# 4. 创建变更提案
/opsx:propose → 生成 4 个制品
# 5. 实现代码
/opsx:apply → 按 tasks.md 逐条执行
# 6. 归档变更
/opsx:archive → 变更归档到 archive/ 目录核心流程就是三条命令:propose → apply → archive。如果你在 propose 之前想先理清思路,可以用 /opsx:explore 做一轮纯思考 - 不写代码,只探索方案。
整个流程没有复杂的概念,没有陡峭的学习曲线。这也是为什么官方说自己的上手时间大概是 5 分钟,而同类工具 Spec-Kit 大概需要 30 分钟。
进阶技巧
技巧一:用 config.yaml 定制规范模板
交互式 openspec init 会自动生成 openspec/config.yaml。如果你用的是非交互式初始化(--tools claude),可以手动创建此文件。
config.yaml 可以配置项目级别的规范规则。比如:
schema: spec-driven
context: |
Tech stack: TypeScript, Express, PostgreSQL
API conventions: RESTful, JSON responses
rules:
proposal:
- Include rollback plan
specs:
- Use Given/When/Then format for scenarios这样每次 propose 的时候,AI 会自动遵循这些规则。你不用每次都在 prompt 里重复说用 TypeScript、用 RESTful 风格。
技巧二:CLI 命令速查
除了斜杠命令,OpenSpec 还提供了一些 CLI 命令:
openspec list # 列出活跃变更
openspec list --specs # 列出所有规范
openspec show <name> # 查看变更详情
openspec status --change <name> # 查看制品进度
openspec validate # 验证格式
openspec view # 交互式仪表盘
openspec config profile # 切换工作流模式
openspec update # 升级后更新指令文件其中 openspec view 比较有意思,它会打开一个交互式仪表盘,可以浏览所有变更和规范的状态。
技巧三:扩展工作流
如果你觉得 Core 工作流(propose → apply → archive)不够用,可以切换到 Expanded Profile:
openspec config profile
# 选择 expanded 模式Expanded 模式额外提供:
命令 | 作用 |
|---|---|
| 创建变更脚手架(不自动生成文档) |
| 继续未完成的变更 |
|
|
| 验证实现是否符合规范 |
| 批量归档多个变更 |
另外,前面提到的 /opsx:explore 也是一个值得关注的命令 - 它是纯思考模式,不产生文件变更,适合在 propose 之前用来梳理需求、探索技术方案。
常见问题
Q1:openspec init 报错 Node.js version not supported
A:OpenSpec 要求 Node.js >= 20.19.0。运行 node --version 检查你的版本。如果版本过低,去 Node.js 官网下载 LTS 版本更新。
Q2:/opsx:propose 生成的文档不准确怎么办?
A:直接编辑这些文件。OpenSpec 的理念是 iterative not waterfall,生成的文档不是定稿,你可以随时修改 proposal、design、tasks 里的内容,改完再 apply。
Q3:归档后想修改已归档的变更怎么办?
A:重新 /opsx:propose 一个新变更就行。每次变更都是增量的,你不需要撤销之前的归档。这是 Delta Specs 的设计初衷 - 变更永远是增量的。
Q4:支持哪些 AI 编程助手?
A:OpenSpec 支持 20+ AI 编码助手,包括 Claude Code、Cursor、Copilot、Windsurf、RooCode、Cline、Amazon Q、Codex 等。初始化时用 openspec init --tools all 可以配置所有工具的支持。
总结
回顾一下我们做了什么:
- 用
npm install安装了 OpenSpec CLI - 用
openspec init初始化了项目的规范目录 - 用
/opsx:propose生成了包含 4 个制品的变更提案 - 用
/opsx:apply让 AI 按任务清单实现了代码 - 用
/opsx:archive把变更归档到 archive 目录
说到底,OpenSpec 解决的核心问题是:让 AI 编程从模糊 prompt → 不确定输出变成明确规范 → 可预期的实现。
下一步,你可以继续用 /opsx:propose 给这个 Todo API 项目添加认证、数据库、错误处理等功能。每次变更归档后,项目规范会逐步积累。AI 读到这些规范,生成的代码质量也会越来越好。
这就是规范驱动开发的正循环。
建议收藏这篇教程,下次给项目接入 OpenSpec 的时候翻出来跟着做一遍。
GitHub 仓库:https://github.com/Fission-AI/OpenSpec
安装指南:https://github.com/Fission-AI/OpenSpec/blob/main/docs/getting-started.md
好啦,谢谢你观看我的文章,如果喜欢可以点赞转发给需要的朋友,我们下一期再见!敬请期待!
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号