传统日志工具 ELK、Loki 已过时!高性能、更轻量、更适合现代运维架构的替代利器来了

传统日志工具 ELK、Loki 已过时!高性能、更轻量、更适合现代运维架构的替代利器来了

民工哥
发布于 2026-03-24 17:25:59
发布于 2026-03-24 17:25:59
— 特色专栏 —
大家好,我民工哥!
在云原生时代,传统日志工具(如 ELK Stack、Splunk 等)面临的技术挑战与架构瓶颈日益凸显,主要源于容器化、动态编排、分布式架构等核心特性的冲击。
比如:传统工具依赖静态主机或固定路径收集日志,而 Kubernetes 中 Pod 可能随时被销毁/重建,IP 和路径动态变化。
集中式收集的瓶颈,日志集中通过 Sidecar 或 Node Agent 收集,但云原生场景下日志源数量可能暴增(如数千个微服务实例),导致单点性能崩溃。
传统工具缺乏细粒度的访问控制,难以满足云原生中多团队共享日志系统的需求(如不同 Namespace 的日志隔离)。
解决企业实际的痛点就是需求,有需求就会有解决方案。
今天,就给大家带来专门为了解决上述云原生时代日志收集、分析而产生的痛点的产物:VictoriaLogs。
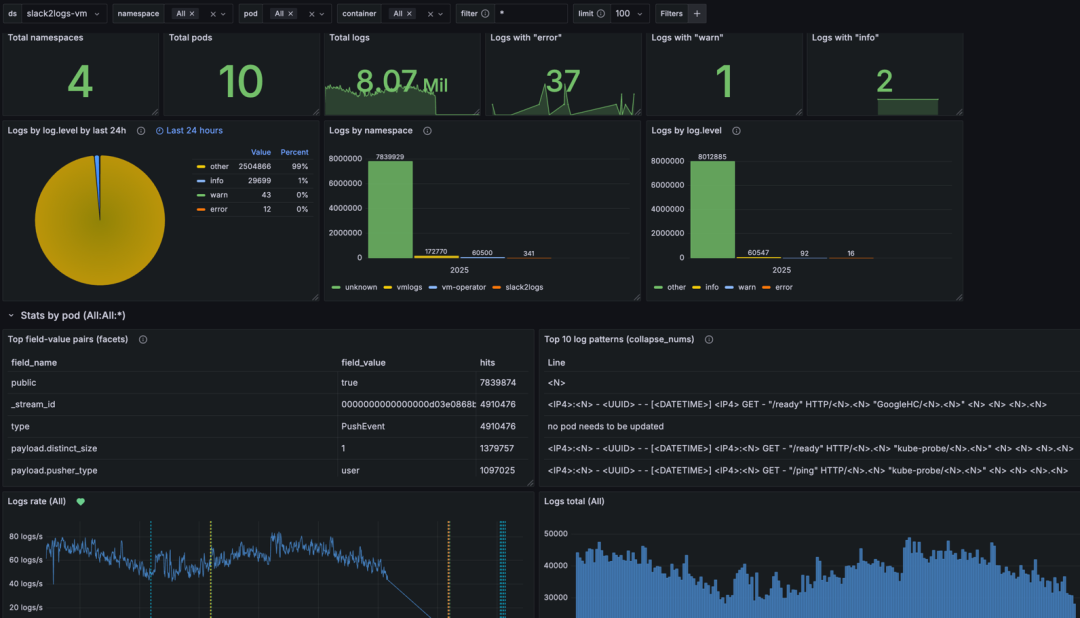
VictoriaLogs 简介
VictoriaLogs 是 VictoriaMetrics 团队推出的新一代高性能日志管理系统,专为云原生环境设计,以轻量化架构、极致存储效率和强大查询能力为核心,旨在解决传统日志工具在动态环境中的性能、成本与运维复杂度问题。

VictoriaLogs 核心优势
独立架构,轻量化设计
虽与 VictoriaMetrics 同属一个团队,但 VictoriaLogs 是独立项目,不依赖 VictoriaMetrics 构建。其架构更轻量,支持作为独立日志系统或命令行工具(类似 grep)使用。
资源占用极低:相比 Elasticsearch,RAM 使用量低 30 倍,磁盘空间占用少 15 倍,单节点可处理数百 TB 日志。
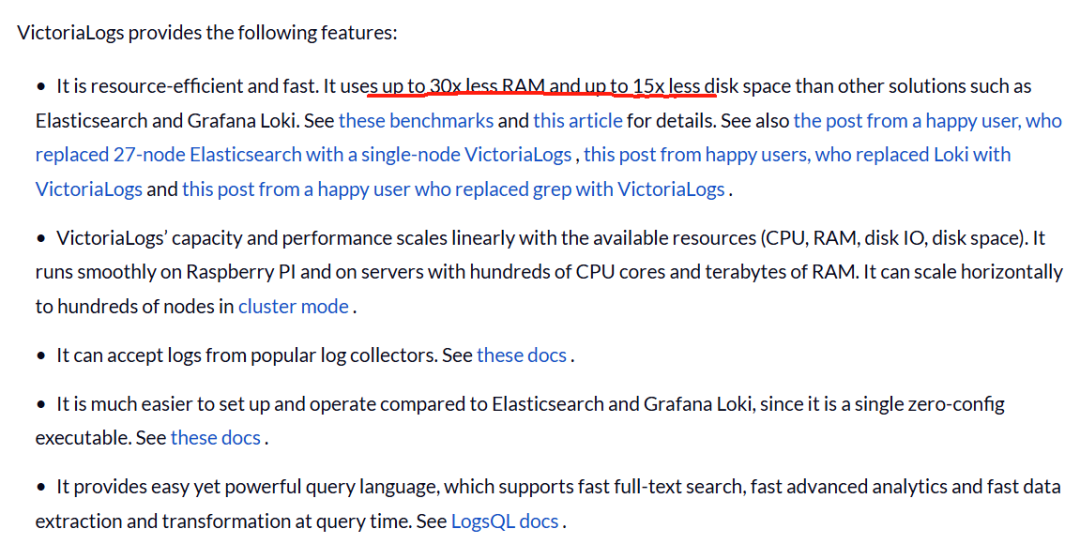
极致存储效率
自适应压缩算法:根据日志生成频率动态调整压缩策略,空闲时段启用更高压缩比,存储成本降低 60-80%。
数据块优化:将同一字段值存储到独立数据块,查询时仅读取所需字段,减少磁盘 I/O。例如,多个日志条目中的 level 字段值存储在单个块中,查询时无需扫描整个日志。
高性能查询
LogsQL 查询语言:采用 Pipe 风格,支持复合查询(如 app="nginx" | regexp "error" | avg_over_time(duration)),实现亚秒级全局搜索(99% 查询响应时间 < 500ms)。
并行处理:查询期间数据块在所有可用 CPU 内核上并行处理,性能随核心数线性扩展。
交互式命令行工具:内置 vlogscli 工具,支持与 grep、less、sort 等传统日志分析工具无缝结合。
高兼容性与易集成
Elasticsearch 接口兼容:直接支持 Elasticsearch Bulk API,可无缝对接现有日志采集工具(如 Fluentd、Logstash、Filebeat),无需修改采集端配置。
多日志源支持:兼容结构化、非结构化及混合日志,自动处理嵌套 JSON(扁平化为单层 JSON,字段通过 . 连接,如 host.os.version)。
Grafana 插件:支持通过 Grafana 数据源插件和内建 UI 进行日志查询与可视化。
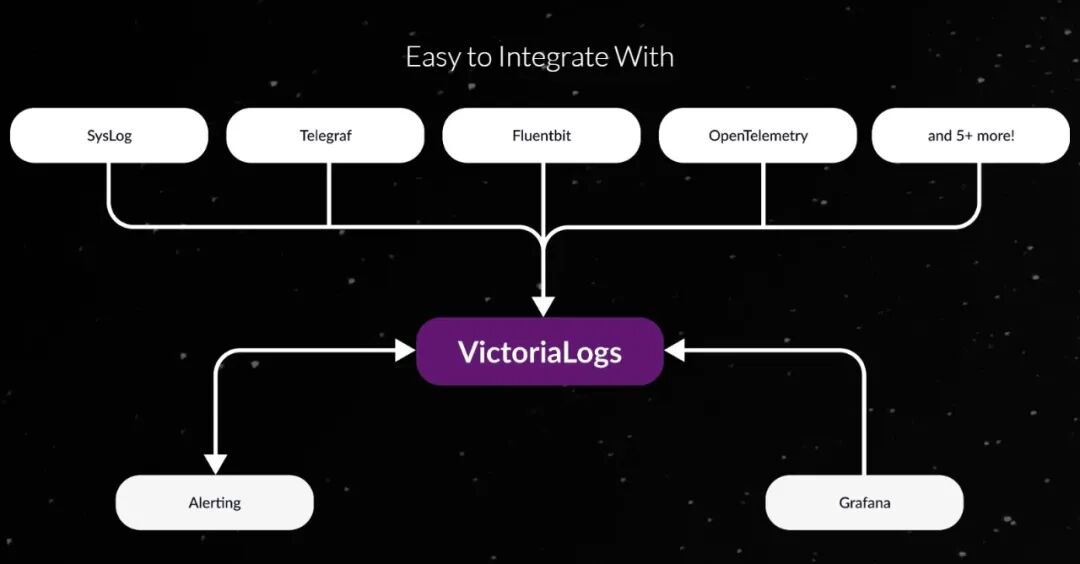
灵活扩展性
单节点与集群模式:当前版本支持单节点部署,预计 2025 年初推出集群模式,可横向扩展以应对大规模日志需求。
多租户支持:满足多用户、多环境下的日志隔离与管理需求。
VictoriaLogs 核心功能组件
日志流(Log Stream)管理
日志流表示应用(服务)的日志实例,粒度可自定义(如按 Pod、服务名等)。例如,app_name="kernel", hostname="ubuntu-linux-22-04-desktop" 定义一个日志流。
同一日志流的标签(如 host、app)不变,普通标签(如 level、traceId)可变,减少数据冗余,提升压缩比。
数据模型
字段结构:
_msg:日志内容字段。_time:时间字段。_stream:流标签字段(如host="host-123",app="my-app")。- 普通标签:可变字段(如
level="error")。
通过流标签实现日志隔离,满足云原生中多团队共享日志系统的需求。
VictoriaLogs 技术实现与架构
存储引擎
列式存储:基于倒排索引的时序数据优化,支持高效压缩与快速检索。
数据块合并:小数据块在后台合并为较大块,数据块大小有限制,超过则分割,确保查询性能。
查询处理
原子化处理:查询期间以数据块为单位,若块包含需处理的值,则立即解包并读取整个块。
无序日志摄取:支持回填(backfill),即无序日志的实时跟踪与处理。
扩展性
单节点与集群模式:当前支持单节点部署,预计 2025 年初支持集群模式,满足大规模日志存储需求。
弹性扩展:性能随硬件资源(CPU、RAM、磁盘 I/O)线性扩展,可在 Raspberry Pi 或数百 CPU 核心的服务器上流畅运行。
VictoriaLogs 部署
支持二进制、Docker、Kubernetes 等部署方式。
安装部署
- 单机部署(测试/临时环境)
从 GitHub Releases 获取最新版本,下载二进制文件。
启动服务,直接运行二进制文件即可。
curl -L -O https://github.com/VictoriaMetrics/VictoriaLogs/releases/download/v1.39.0/victoria-logs-linux-amd64-v1.39.0.tar.gz
tar xzf victoria-logs-linux-amd64-v1.39.0.tar.gz
./victoria-logs-prod -storageDataPath=victoria-logs-data
通过命令行参数指定存储路径、监听端口、日志保留期等。例如:
./victoria-logs -storageDataPath=/path/to/data -httpListenAddr=:9428 -retentionPeriod=30d
- Docker 部署
#创建数据目录
mkdir -p ./victoria-logs-data
#运行容器
docker run -d --restart always \
-p 9428:9428 \
-v ./victoria-logs-data:/victoria-logs-data \
--name victoria-logs \
victoriametrics/victoria-logs:latest \
--retentionPeriod=30d
验证部署:访问 http://localhost:9428,或通过 docker ps 查看容器状态。
- Kubernetes 部署
#添加 Helm 仓库
helm repo add vm https://victoriametrics.github.io/helm-charts/
helm repo update
#部署集群版
helm install victoria-logs vm/victoria-logs-cluster -n victoria-logs --create-namespace
#验证集群状态
kubectl get pods -n victoria-logs
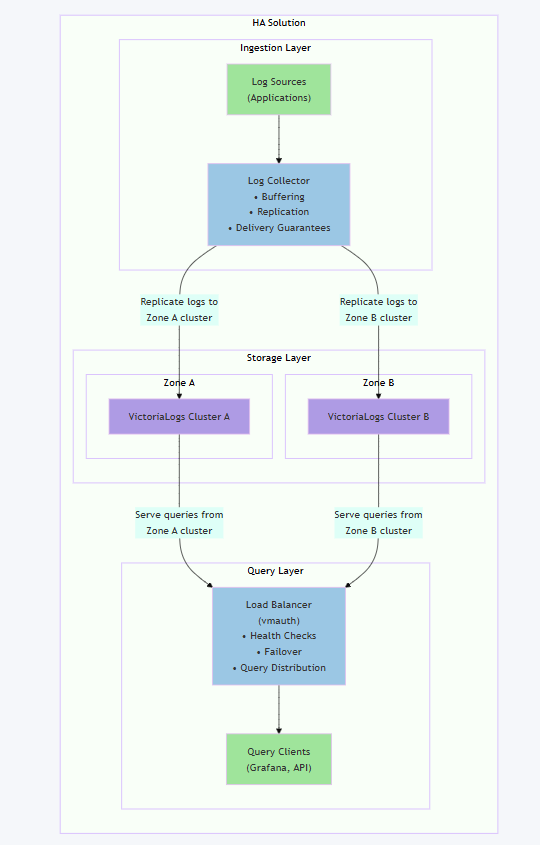
高可用架构:
- 多节点集群:通过多个实例实现数据冗余和负载均衡。
- vmauth 组件:作为负载均衡器和安全认证中心,确保数据访问的平衡与冗余。
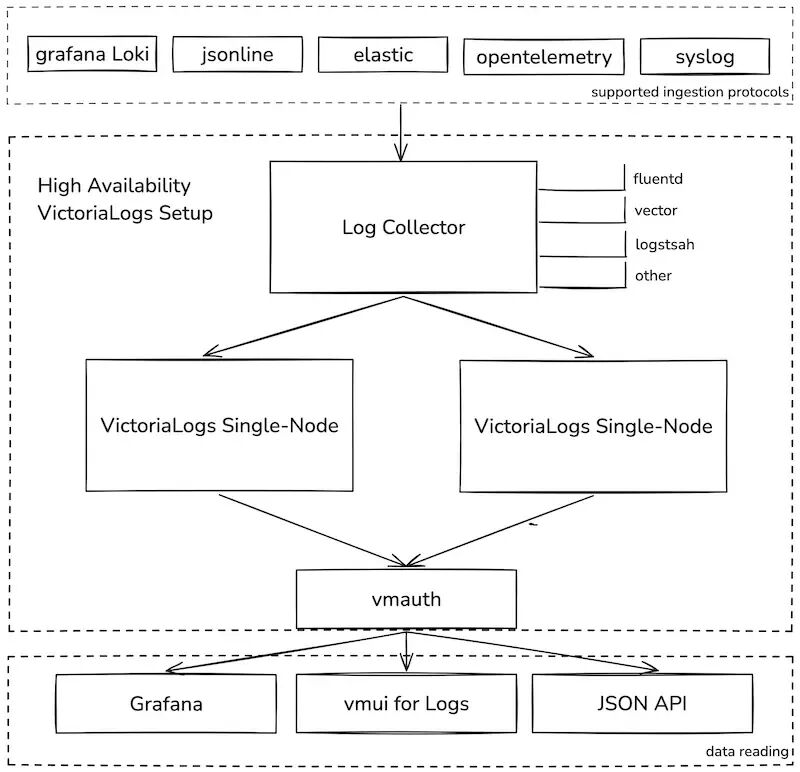
核心配置参数
-storageDataPath #指定日志数据存储路径(如 /path/to/data)
-httpListenAddr #设置 HTTP 服务监听地址(如 :9428)。
-retentionPeriod #配置日志保留期限(如 30d 表示 30 天)。
-syslog.listenAddr.tcp #监听 syslog 数据的 TCP 端口(如 :29514)。
-storage.compressionLevel #调整数据压缩级别(默认启用 ZSTD 压缩)。
集群模式介绍
集群模式下的 VictoriaLogs 由三个主要组件组成:vlinsert、vlselect 和 vlstorage。
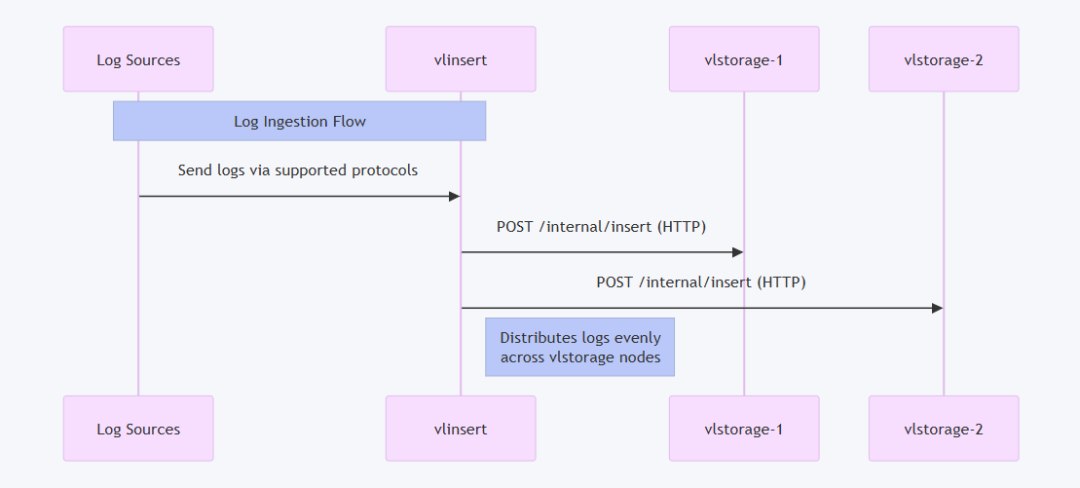
数据采集流程
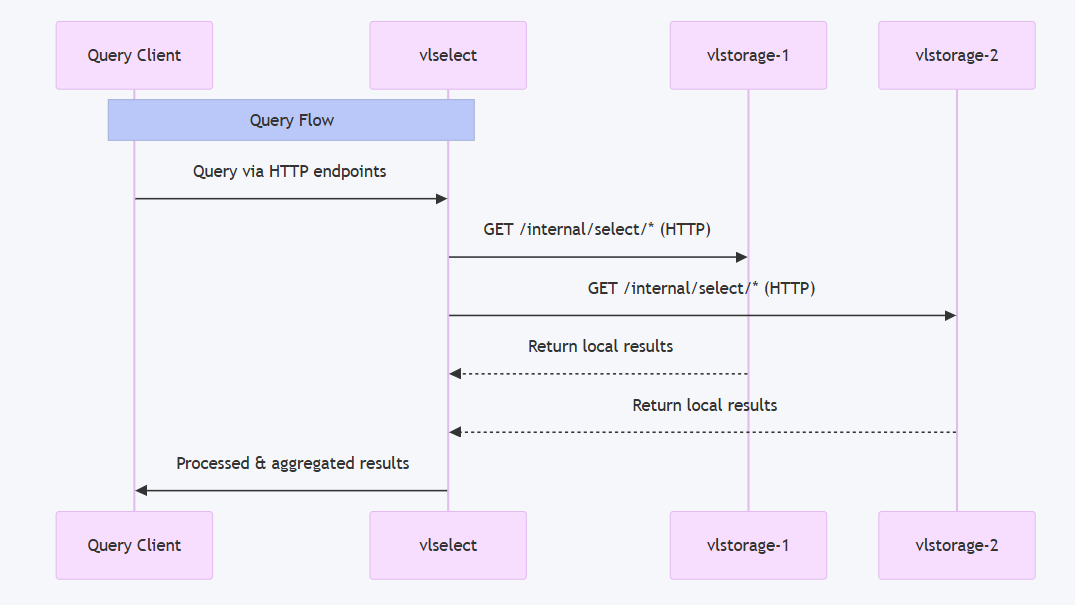
数据查询流程
集群高可用
VictoriaLogs 使用
VictoriaLogs 的使用主要涉及 日志采集、存储、查询、可视化四个核心环节。
日志采集与存储
支持的日志格式
- 文本日志:纯文本格式日志。
- JSON 日志:结构化 JSON 日志,支持嵌套字段。
- Syslog 日志:标准 syslog 协议日志。
Filebeat 配置示例
filebeat.inputs:
- type: log
paths: ["/var/log/*.log"]
fields:
job: "nginx"
level: "error"
output.logstash:
hosts: ["victoria-logs:9428"]
Fluentd 配置示例
<match **>
@type http
endpoint http://victoria-logs:9428/api/v1/logs
<format>
@type json
</format>
</match>
Promtail(Loki 客户端):适配 VictoriaLogs 的 API 格式即可。
日志查询与分析
LogsQL 查询语法
基础查询:
{job="nginx", level="error"} | line=~"timeout"
查询 job 为 nginx 且 level 为 error 的日志,并筛选包含 timeout 的日志行。
时间范围过滤:
{job="nginx"} | _time:[now-1h, now]
查询 job 为 nginx 且时间范围在最近 1 小时内的日志。
聚合统计:
{job="nginx"} | count() by level
按 level 字段统计日志数量。
Web UI 使用
访问方式:通过 http://<VictoriaLogs-IP>:9428 访问内置 Web UI。
功能:
- 日志检索:支持 LogsQL 语法查询日志。
- 可视化展示:与 Grafana 集成,构建仪表盘。
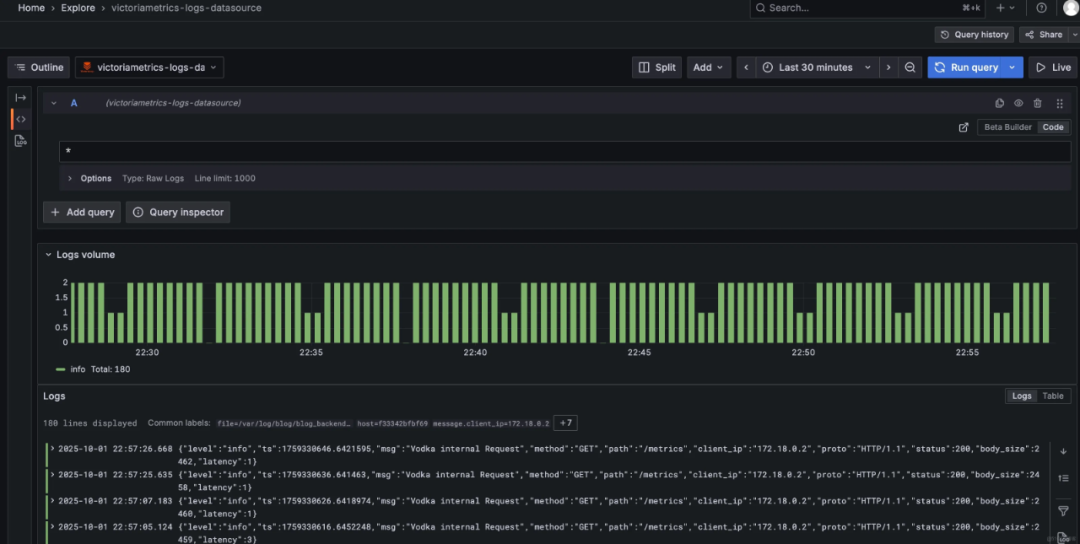
Grafana 集成
配置数据源:
- 在 Grafana 中添加 VictoriaLogs 数据源,URL 为
http://victoria-logs:9428。 - 使用
Explore功能查询日志,或构建仪表盘展示关键指标。
与竞品对比
特性 | VictoriaLogs | Loki | ELK |
|---|---|---|---|
存储效率 | ★★★★★ | ★★★☆☆ | ★★☆☆☆ |
查询延迟 | <500ms (99%) | 1-3s | 5-10s |
部署复杂度 | 单二进制 | 需 Cortex 集群 | 5+组件协同 |
成本(TCO) | 最低 | 中等 | 最高 |
总结
VictoriaLogs 通过轻量化架构、极致存储效率和强大查询能力,重新定义了云原生时代的日志管理标准。
其设计理念(如日志流优化、数据块并行处理)为日志系统提供了新的性能与成本平衡方案。
随着 2025 年集群模式的发布,VictoriaLogs 有望成为大规模日志存储与分析的首选工具,特别适合追求极致效率的云原生环境。
都看到这里了,觉得不错的话,随手点个赞👍 、推荐
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-12-08,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号